
- 12024年计算机网络与互联网技术国际会议(ICCNIT 2024)_iccnit官网
- 2Mybatis的特性详解——四大操作标签_mybatis insert select
- 3【RK3568】编译error记录_rk3568 error:no found parameter!
- 4Python桌面应用程序的布局和设计_python桌面系统
- 5docker拉取镜像的时候超时_docker拉取镜像超时
- 6Python 安装 Selenium 报错解决方案:全方位排错指南_安装selenium报错
- 7python每日一题——16除自身以外数组的乘积_python 除自身以外数组的乘积
- 8rsa加密算法详解_rsa加密算法详细步骤
- 9能把进程和线程讲的这么透彻的,没有20年功夫还真不行【0基础也能看懂】
- 10软件测试工程师面试——接口测试话术_测试工程师常用话术
kafka(三)springboot集成kafka(1)介绍(1)_spring-boot kafka expiring 1 record(s) fo
赞
踩
3.2、 buffer.memory
指定了producer端用于缓冲消息的缓冲区大小,单位是字节。
3.3、compression.type
producer是否压缩消息。
3.4、batch.size
二、ProducerRecord
1、介绍
发送给Kafka Broker的key/value 值对,producer将待发送的消息封装进ProducerRecord实例类。
2、发送消息分区策略
(1)指定了分区:
当发送时指定了partition就使用该partition。即kafka生产者发送的消息ProducerRecord(String topic, Integer partition, K key, V value)指定了发送到哪个具体的分区。

(2)轮询
如果kafka生产者发送的消息ProducerRecord(String topic, Integer partition, K key, V value)没有指定发送到哪个具体的分区,即partition=null(并且key也为空时,如果此时key不为空的话就会采用另一种分区策略key哈希分区策略),并且使用了默认的分区器,那么消息将被随机的发送到主题的各个可用分区上,分区器使用轮询的算法将消息均衡的分布到各个分区。

(3)key哈希分区策略
根据消息的key进行哈希计算,并将消息发送到对应的分区。保证相同key的消息始终被发送到同一个分区,确保消息的顺序性。

(4)自定义分区策略(即自定义Partitioner)
用户可以根据自己的需求实现自定义的分区策略,通过实现org.apache.kafka.clients.producer.Partitioner接口来自定义分区选择逻辑。
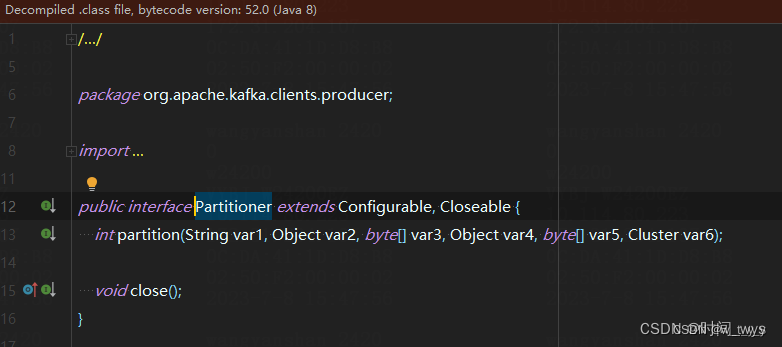
二、 KafkaConsumer
三、生产者发送消息应用
1、同步发送消息
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回 ack。 由于 send 方法返回的是一个 Future 对象,根据 Futrue 对象的特点,我们也可以实现同 步发送的效果,只需在调用 Future 对象的 get 方发即可。
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; import java.util.concurrent.ExecutionException; public class CustomProducerSync { public static void main(String[] args) throws ExecutionException, InterruptedException { // 1. 创建kafka生产者的配置对象 Properties properties = new Properties(); // 2. 给kafka配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value序列化(必须): properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 3. 创建kafka生产者对象 KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties); // 4. 调用send方法,发送消息 for (int i = 0; i < 10; i++) { // 默认为异步发送 kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i)); // 末尾加get为同步发送 kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i)).get(); } // 5. 关闭资源 kafkaProducer.close(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2、异步发送消息
2.1、普通异步
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class CustomProducer { public static void main(String[] args) { // 1. 创建kafka生产者的配置对象 Properties properties = new Properties(); // 2. 给kafka配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value序列化(必须): properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 3. 创建kafka生产者对象 KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties); // 4. 调用send方法,发送消息 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>("first", "wtyy")); } // 5. 关闭资源 kafkaProducer.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2.2、带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是 RecordMetadata 和 Exception,如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
import org.apache.kafka.clients.producer.*; import java.util.Properties; public class CustomProducerCallBack { public static void main(String[] args) { // 1. 创建kafka生产者的配置对象 Properties properties = new Properties(); // 2. 给kafka配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value序列化(必须): // 序列化器的serialization是一个接口,找到他的实现类 // 我们一般都是使用String properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 3. 创建kafka生产者对象 KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties); // 4. 调用send方法,发送消息 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { //(1)消息发送成功 exception == null 接受到服务端ack消息 调用该方法 //(2)消息发送失败 exception != null 也会调用该方法 if (exception == null) { System.out.println(metadata);//使用打印演示 }else{ exception.printStackTrace();//打印异常信息 } } }); } // 5. 关闭资源 kafkaProducer.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
四、消费者接收消息应用
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.ArrayList; import java.util.Properties; public class CustomConsumer { public static void main(String[] args) { // 1. 创建消费者配置对象 Properties properties = new Properties(); // 2. 给消费者配置对象添加参数(不同于生产者,消费者有 4个必要的配置参数) // broker的ip地址 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // 配置 反序列化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

