
- 1python中shape[0]与shape[1]
- 2记录我下载/同步chromium源码过程中遇到的报错及解决方案_error: command 'cipd ensure -log-level error -root
- 3云原生时代业务架构的变革:从单体迈向Serverless
- 4sqlmap使用之-post注入、head注入(ua、cookie、referer)
- 5区块链的控制反转
- 6区块链基本概念_1ghz每秒能做多少次哈希运算
- 7tsnode debug
- 8毕业设计:图书数据分析可视化系统 python爬虫 Flask框架 当当网 (源码)✅
- 9基于Licheepi 4A的YOLOv5-Lite的部署_荔枝派4a应用
- 10ElasticSearch - 分布式搜索引擎底层实现——倒排索引_elasticsearch 倒排索引
技术动态 | GraphRAG:设计模式,挑战和落地指南
赞
踩
转载公众号 | 知识图谱科技

GraphRAG (基于知识图谱检索增强生成) 通过将知识图谱 (KGs) 或图形数据库与大型语言模型 (LLMs) 集成,增强了传统的检索增强生成 (RAG) 方法。它利用图形数据库的结构化特性,将数据组织为节点和关系,以更高效准确地检索相关信息,并为生成响应提供更好的上下文,使LLMs感知到更多的信息。
通过将知识图谱作为结构化的、领域特定的上下文或事实信息的来源,GraphRAG使LLMs能够对问题提供更精确、上下文感知和相关的答案,特别是对于需要全面理解大量数据集合或单个大型文档中概括语义概念的复杂查询。
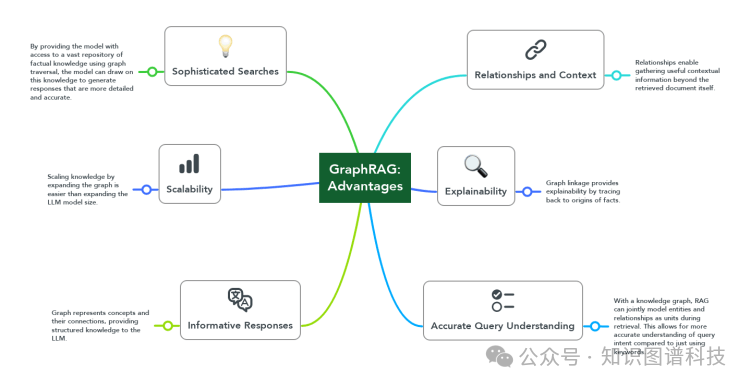
传统的向量搜索方法注重使用高维向量来处理非结构化数据,而GraphRAG借助知识图谱实现了对相互关联、异构信息的更细致理解和检索。这种结构化的方法提升了检索信息的上下文与深度,从而能够更准确、更相关地回答用户的查询,尤其在复杂或领域特定的主题上。
常见GraphRAG架构
尽管GraphRAG利用知识图谱的结构特性相对传统RAG有优势,但其实施面临独特的挑战。缺乏将知识图谱整合到RAG流程中的标准化方法导致存在多种实现方式,每种方式都有其自身的优势和考虑因素。此外,还需要一个已有的知识图谱,这增加了另一层复杂性。
以下是一些常见的GraphRAG架构:
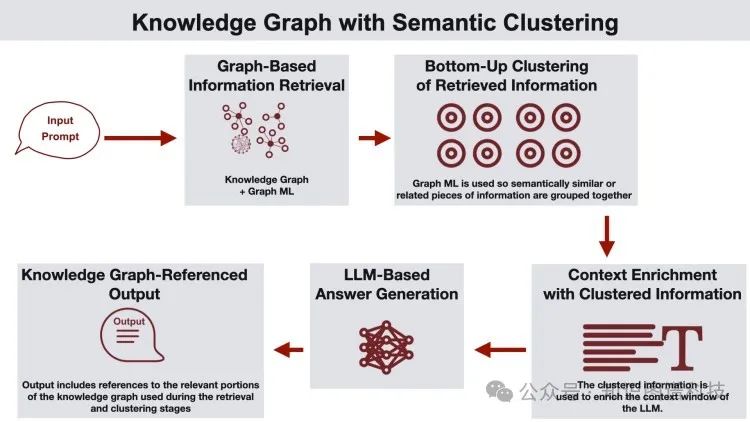
语义聚类的知识图谱
知识图谱提供了数据的结构化表示,并使整个数据集具备推理能力。该流程从搜索用户查询开始,系统利用知识图谱和图结构机器学习模型获取相关信息。然后,通过基于知识图谱的聚类方法对获取的信息进行语义聚类。这些聚类信息丰富了LLM(语言模型)上下文窗口中的数据,使得LLM可以利用这个丰富的上下文生成回答。
最终的回答包括与知识图谱相关的引用,适用于数据分析、知识发现和研究应用。
知识图谱和向量数据库集成
此方法利用知识图谱和向量数据库来收集相关信息。知识图谱以捕捉向量块之间的关系为基础构建,包括文档层次结构。知识图谱在向量搜索结果中的检索块附近提供结构化实体信息,使提示得到有价值的附加背景信息。这个丰富的提示被输入到LLM进行处理,LLM生成一个回答。
最后,生成的答案返回给用户。此架构适用于客户支持、语义搜索和个性化推荐等用例。

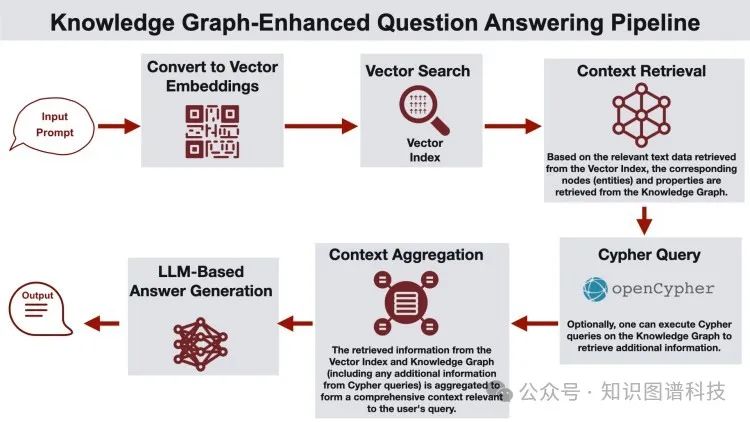
知识图谱增强的问题回答流程
在这个架构中,知识图谱在向量检索之后用于增强响应,提供额外的事实。流程始于用户提供查询,接着计算查询嵌入。然后,在向量索引上进行向量相似度搜索,以识别知识图谱中相关实体。系统从图数据库中检索相关节点和属性,(如果找到)执行Cypher查询以检索关于这些实体的附加信息。检索到的信息被聚合成一个综合的上下文,传递给LLM生成响应。这种方法在医疗或法律环境中非常有益,其中始终会基于响应中的实体包括一个标准响应。
知识图谱增强的混合检索
这个GraphRAG架构采用了混合方法,将向量搜索、关键词搜索和专用图查询相结合,以便高效准确地检索相关信息。请注意,这里所说的“混合”不是常用的将向量和基于关键词的检索结合的定义,它还包括一个知识图检索步骤。
流程始于用户提交查询,然后进行混合检索过程,整合来自非结构化数据搜索和图数据搜索的结果。从向量和关键词索引的检索可以通过重新排名或排名融合技术进行初始增强。来自三种形式检索的结果会结合在一起,为LLM(语言模型)提供上下文,并将生成的回答提供给用户。
这个架构适用于企业搜索、文档检索和知识发现等用例。

基于知识图谱的检索增强和生成
在执行向量搜索之前,该架构利用知识图谱遍历和检索相关节点和边缘,丰富LLM的上下文窗口。
第一阶段是查询增强,LLM对用户的查询进行处理,提取关键实体和关系。对知识图谱中的节点属性进行向量搜索,以缩小所感兴趣的相关节点范围。
下一步是查询重写,通过检索到的子图生成Cypher查询,进一步缩小图中相关结构化信息的范围。从图遍历中检索到的数据用于丰富LLM的上下文窗口。
最后,LLM根据丰富的上下文生成响应。该架构适用于产品查找或财务报告生成等需要关注实体之间关系的场景。

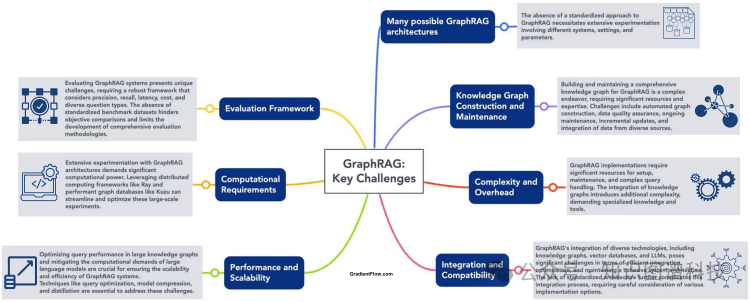
主要挑战
构建一个全面准确的知识图谱需要对领域有深入的理解和图形建模的专业知识,这是一个复杂且资源密集型的过程。使用LLM自动化此过程仍处于早期阶段,可能具有困难和/或容易出错的特点。确保数据的质量、相关性和完整性至关重要。保持最新知识图谱的要求包括专业知识、资源和不断适应不断演化的数据。将来自多个来源的数据集成到具有不同模式和质量水平的知识图谱中,增加了完成此任务所需的复杂性和时间。
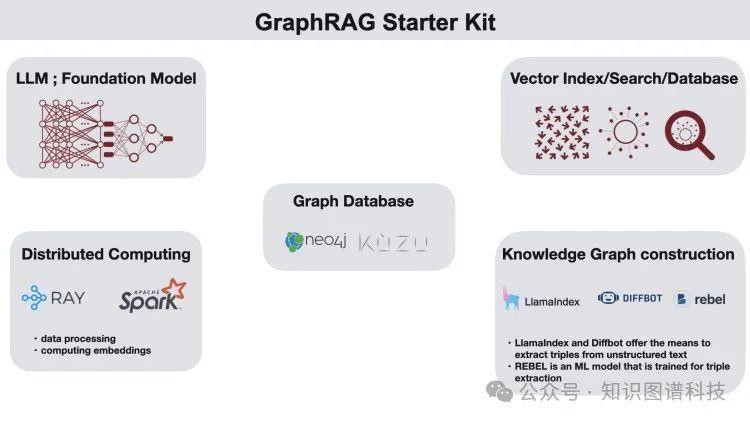
正如我们在之前的帖子中提到的那样,RAG 本身需要进行计算密集的实验来确定最佳的信息提取、分块、嵌入、检索和排序策略。对于探索不同的 GraphRAG 结构、设置和参数的计算密集型实验,也需要大量的资源。利用像 Ray 这样的分布式计算框架进行数据处理和嵌入计算,再加上一种高效且易于集成的图数据库,比如 Kuzu,可以促进大规模实验和系统优化。
GraphRAG的未来:洞察和建议
我们认为GraphRAG将会长期存在,并且已经成为RAG的自然延伸。使用知识图谱提供了另一种获得结构化信息的方式,这可以增强LLM在生成阶段使用的提示。以下是一些关于在组织中开始实施GraphRAG的建议:
首先,要熟悉“Naive”RAG(使用分块的矢量检索)。还应当精通运行实验并制定评估策略(在你的领域,什么样的结果被认为是“好的”?)。
努力获取用于知识图谱的数据源,这些数据源可以是现有的结构化数据,也可以是可以转换为知识图谱的非结构化文本。
熟悉图形数据库,了解如何将数据加载到其中,以及如何进行查询(Kuzu是一种易于设置的选项)。
从一个小的知识图谱开始,尝试将查询结果从图形传递给LLM作为上下文,并将其性能与你的天真RAG设置进行比较。
不要过早优化你的知识图谱。首先确定一个可以实现的GraphRAG架构。只有当你拥有完整的GraphRAG设置和评估流程后,你才能开始改进你的KG和数据模型。
将你的GraphRAG流程端到端运行,并确信结果确实比仅使用矢量或仅使用图形的方法好。
不要立即追求构建完美的GraphRAG应用。从一个更简单的设计开始有助于更好地量化与基准相比的检索结果,并且你可以通过添加更复杂的路由器和代理进行逐步改进。
随着你的GraphRAG计划的发展和需求的增长,你可能会发现自己需要能够处理更大数据量的复杂体系结构。为确保平稳过渡,明智的做法是选择能够与你的项目一起扩展的工具。工具应当灵活且具有成本效益,以适应对你的GraphRAG设置和设计的改进,从而使你能够根据需要进行调整和优化你的系统。
不少团队正在建设GraphRAG系统的早期阶段,在探索性阶段的进程中。我们需要了解已经实施的生产部署案例,这些案例能够评估提供真正的商业价值。
为了达到目标,我们需要更多为了适应GraphRAG系统而设计的基准数据集和评估方法,以帮助团队更好地衡量性能。像FinanceBench这样的基准数据集(https://arxiv.org/pdf/2311.11944),专门用于开放式问题回答,提供了一种有希望的研究手段,用于研究GraphRAG系统在生成回答中减少错误和提高事实准确性的能力。
参考文献:
GraphRAG: Design Patterns, Challenges, Recommendations - Gradient Flow
https://gradientflow.com/graphrag-design-patterns-challenges-recommendations/
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。



