
- 1Unity2D学习笔记Day13:添加音效Audio_unity增加个吃金币的声音
- 2echarts 社区网站
- 3Drv8434s芯片两相步进电机驱动程序+硬件解决方案
- 4查询oracle序列当前值和最大值,修改最大值_oracle修改序列的最大值
- 5吴恩达深度学习网课 通俗版笔记——(05.序列模型)第二周 自然语言处理与词嵌入_词嵌入做迁移学习
- 6Python制作自动化脚本通用版教程_python编写自动化挂机脚本
- 7ChatGLM3-6B部署_chatglm3 6b最低部署要求
- 8HashMap源码解析
- 9elementUI upload上传文件时携带token_el-upload 携带token
- 10兴业数金测开一面面经_兴业数金 测试 面经
【从零开始学架构 架构基础】二 架构设计的复杂度来源:高性能复杂度来源
赞
踩
架构设计的复杂度来源其实就是架构设计要解决的问题,主要有如下几个:高性能、高可用、可扩展、低成本、安全、规模。复杂度的关键,就是新旧技术之间不是完全的替代关系,有交叉,有各自的特点,所以才需要具体问题具体分析,基于各方考虑设计合适的架构,存在合适的架构,不存在最好的架构。这篇主要讨论高性能问题
复杂度来源
软件系统中高性能带来的复杂度主要体现在两方面,一方面是单台计算机内部为了高性能带来的复杂度;另一方面是多台计算机集群为了高性能带来的复杂度
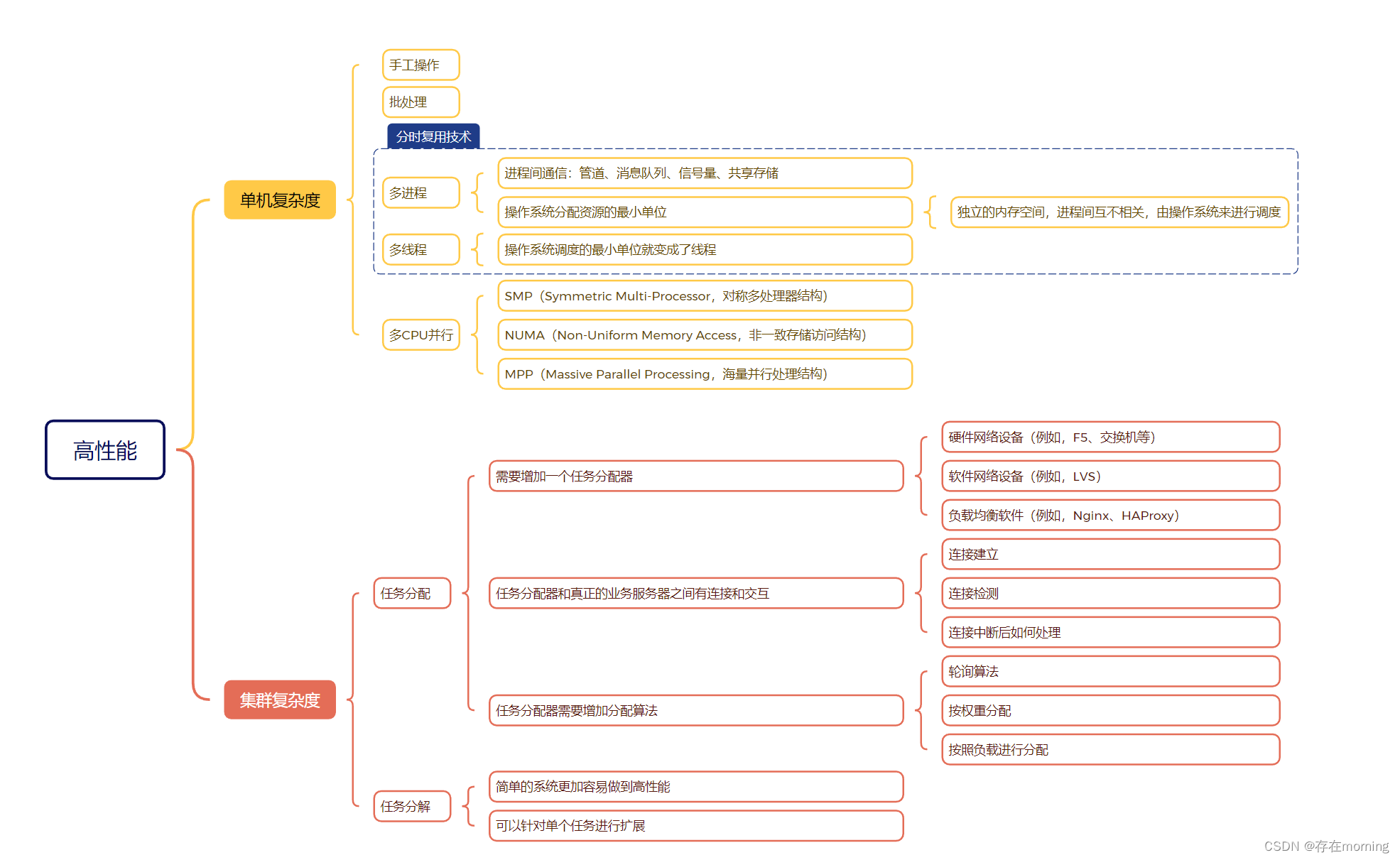
单机复杂度
单机的性能是基于操作系统体现的。提升单机性能的过程就是不断升级迭代操作系统能力的过程,操作系统和性能最相关的就是进程和线程
- 批处理生成指令清单解决手工操作输入慢的问题,但批处理任务在IO时CPU仍然空闲
- 多进程解决CPU分时复用处理任务的问题,但进程内的任务仍然串行,而实际上很多进程内部的子任务并不要求是严格按照时间顺序来执行的
- 多线程解决进程内任务并发问题,但仍然不是真正意义上的并行操作,本质仍然是分时复用
单机性能在设计升级中得到了提升,但同时也增加了系统的复杂度,例如为了支撑多进程多线程,需要设计互斥、锁、进程通信等策略
单机情况下要完成一个高性能的软件系统,需要考虑如多进程、多线程、进程间通信、多线程并发等技术点,而且这些技术并不是最新的就是最好的,也不是非此即彼的选择。这些技术的出现也是为了不断提升性能过程中解决实际问题发生的
集群复杂度
进入互联网时代后,业务的发展速度远远超过了硬件的发展速度,当单机的性能无法支撑时,必须采用机器集群的方式来达到高性能。但是机器集群又并不是简单的堆机器。
任务分配
任务分配的意思是指每台机器都可以处理完整的业务任务,不同的任务分配到不同的机器上执行
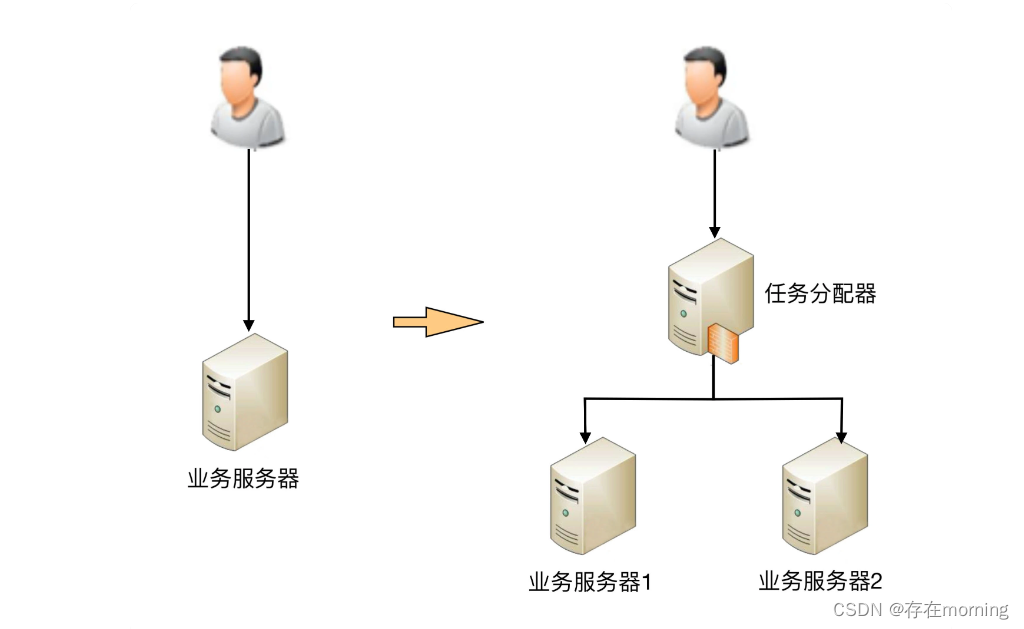
从图中可以看到,1 台服务器演变为 2 台服务器后,架构上明显要复杂多了,主要体现在:
- 需要增加一个任务分配器,这个分配器可能是硬件网络设备(例如,F5、交换机等),可能是软件网络设备(例如,LVS),也可能是负载均衡软件(例如,Nginx、HAProxy),还可能是自己开发的系统。选择合适的任务分配器也是一件复杂的事情,需要综合考虑性能、成本、可维护性、可用性等各方面的因素。 需要引入任务分配器
- 任务分配器和真正的业务服务器之间有连接和交互(即图中任务分配器到业务服务器的连接线),需要选择合适的连接方式,并且对连接进行管理。例如,连接建立、连接检测、连接中断后如何处理等。 需要对任务分配器与业务服务器进行连接管理
- 任务分配器需要增加分配算法。例如,是采用轮询算法,还是按权重分配,又或者按照负载进行分配。如果按照服务器的负载进行分配,则业务服务器还要能够上报自己的状态给任务分配器。 需要设计任务分配器的算法
如果我们的性能要求继续提高,并不是单纯加业务服务器就能解决问题,因为随着性能的增加,任务分配器本身又会成为性能瓶颈,单台任务分配器也不够用了,任务分配器本身也需要扩展为多台机器
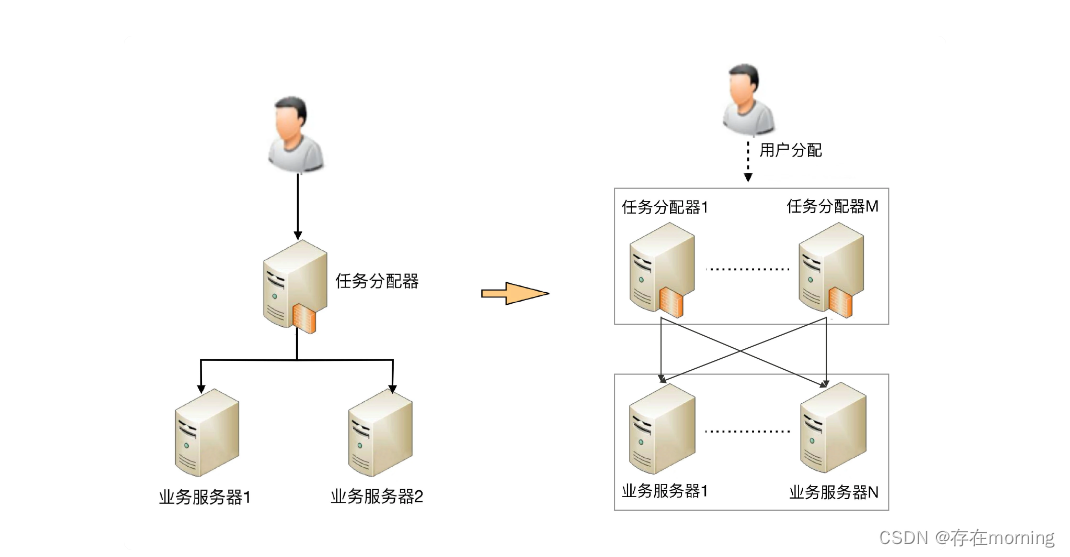
这样复杂度也进一步升级
- 任务分配器从 1 台变成了多台, 这个变化带来的复杂度就是需要将不同的用户分配到不同的任务分配器上,常见的方法包括 DNS 轮询、智能 DNS、CDN(Content Delivery Network,内容分发网络)、GSLB 设备(Global Server Load Balance,全局负载均衡)等 复杂度升级:任务分配器之上还需进行用户分配
- 任务分配器和业务服务器的连接从简单的“1 对多”(1 台任务分配器连接多台业务服务器)变成了“多对多”(多台任务分配器连接多台业务服务器)的网状结构。 复杂度升级:任务分配器与业务服务器网状连接,连接管理难度升级
- 机器数量从 3 台扩展到 30 台(一般任务分配器数量比业务服务器要少,假设业务服务器为 25 台,任务分配器为 5 台),状态管理、故障处理复杂度也大大增加。 复杂度升级:机器增加,分配算法复杂度升级
这个任务可以指很多场景的任务,例如“存储”“运算”“缓存”等都可以作为一项任务,因此存储系统、运算系统、缓存系统都可以按照任务分配的方式来搭建架构。此外,任务分配器也并不一定只能是物理上存在的机器或者一个独立运行的程序,也可以是嵌入在其他程序中的算法。 例如kafka集群(zk集群作为任务分配器)、Redis集群(哨兵集群作为任务分配器),ES集群(候选主节点+协调节点+逻辑主节点联合作为任务分配器),都能抽象为类似的设计。
任务分解
通过任务分配的方式,我们能够突破单台机器处理性能的瓶颈,通过增加更多的机器来满足业务的性能需求,但如果业务本身也越来越复杂,单纯只通过任务分配的方式来扩展性能,收益会越来越低。 水平扩容解决系统性能瓶颈的能力随着业务复杂度边际收益逐渐降低 ,这个时候需要任务分解
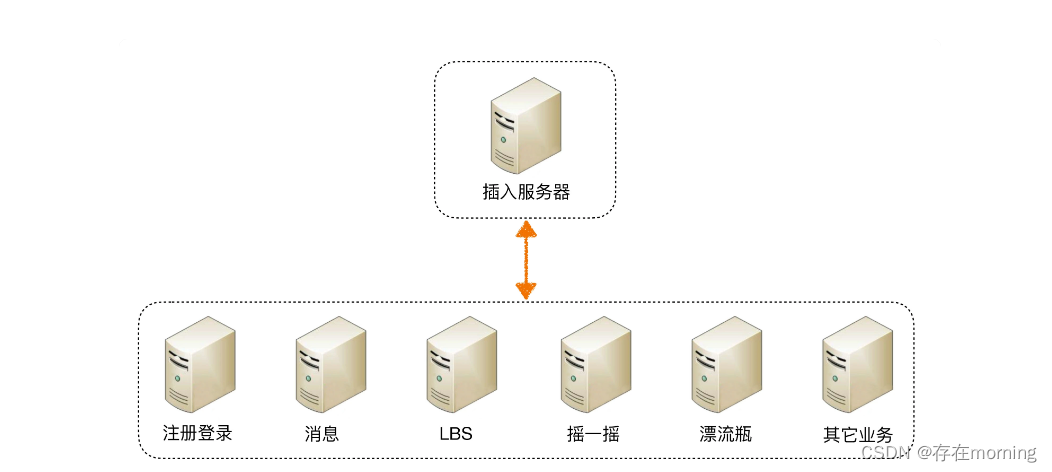
通过这种任务分解的方式,能够把原来大一统但复杂的业务系统,拆分成小而简单但需要多个系统配合的业务系统。从业务的角度来看,任务分解既不会减少功能,也不会减少代码量(事实上代码量可能还会增加,因为从代码内部调用改为通过服务器之间的接口调用),其提升性能的优势体现在:
- 简单的系统更加容易做到高性能,系统的功能越简单,影响性能的点就越少,就更加容易进行有针对性的优化
- 可以针对单个任务进行扩展,当各个逻辑任务分解到独立的子系统后,整个系统的性能瓶颈更加容易发现,而且发现后只需要针对有瓶颈的子系统进行性能优化或者提升,不需要改动整个系统,风险会小很多
总而言之就是 按业务逻辑进行任务隔离,精细化进行任务性能提升,性能瓶颈更容易被发现,优化和扩展更加容易,改动也不会影响其它模块,降低系统风险
但也不是越细越好,任务分解带来的性能收益是有一个度的,并不是任务分解越细越好
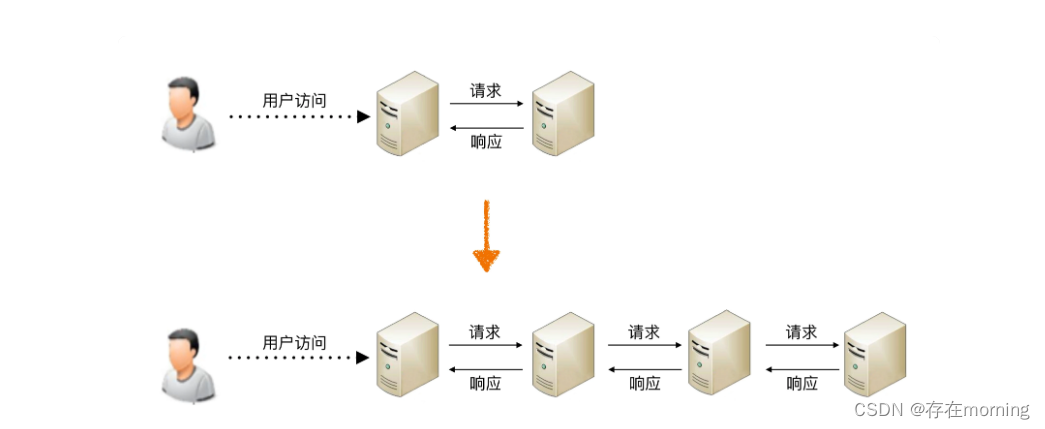
最主要的原因是如果系统拆分得太细,为了完成某个业务,系统间的调用次数会呈指数级别上升,而系统间的调用通道目前都是通过网络传输的方式,性能远比系统内的函数调用要低得多
总结一下
性能差-》提升设计复杂度解决性能问题-》掌握如何编码和集群架构cover复杂的设计。高性能复杂度有单机和集群来源。单机主要通过操作系统(多进程、多线程)设计来压榨机器CPU进而提升性能,其设计复杂度体现在需要实现互斥、锁、进程通信等策略,所以要掌握并发编程技术。集群主要是搭建机器集群来扛住大的业务增量,其设计复杂度体现在任务分配(任务分配器、任务分配器与业务服务器连接管理、任务分配算法,其解决系统性能瓶颈的能力随着业务复杂度边际收益逐渐降低)和任务分解(业务逻辑垂直拆分,单项扩展或升级,其系统拆分带来的收益会随着系统间调用延迟边际降低),所以要掌握任务分配和任务分解的最佳实现模式。架构设计是取舍,是对度的把握。
相关概念
关于学习笔记中的相关知识补充
进程之间通信方式 管道、消息队列、信号量、共享存储
进程间通信(Inter-Process Communication,IPC)是在不同进程之间交换数据的机制。这对于多任务操作系统中的进程协作是非常重要的。常见的进程间通信方式包括管道、消息队列、信号量和共享存储,每种方式都有其特点和适用场景:
-
管道(Pipes):
- 管道是最早的UNIX IPC形式之一,主要用于有血缘关系的进程(如父子进程)之间的通信。它是单向的,数据只能单向流动。如果需要双向通信,则需使用两个管道。
- 管道分为匿名管道和命名管道(FIFO)。匿名管道在进程间临时创建,不能用于没有共同祖先的进程间;而命名管道可以在文件系统中以文件形式存在,支持没有关联的进程间通信。
-
消息队列(Message Queues):
- 消息队列允许一个或多个进程向其发送消息,并由一个或多个进程读取。消息队列具有存储消息的能力,直到它们被接收。
- 与管道不同,消息队列不需要以流的形式进行通信,而是以消息为单位发送接收,这有助于避免数据的边界问题。
-
信号量(Semaphores):
- 信号量主要用于同步多个进程的执行,而不是直接的数据交换。它可以防止多个进程同时访问共享资源。
- 信号量包括二值信号量(也称为互斥锁)和计数信号量。二值信号量用于实现互斥,即在任意时刻只允许一个进程访问资源;计数信号量则允许多个进程同时访问资源的某个固定数量的实例。
-
共享存储(Shared Memory):
- 共享存储允许多个进程访问同一块内存区域。它是最快的IPC方式,因为数据不需要在进程间复制,直接在内存中共享。
- 使用共享内存时,通常需要结合信号量来同步对共享内存的访问,以避免竞态条件和数据不一致。
根据应用程序的特定需求和上下文,开发者可以选择最合适的进程间通信方式。例如,对于需要大量数据快速传输的应用,共享内存可能是最佳选择;而对于需要跨机器或模块化通信的系统,消息队列或命名管道可能更适用。
SMP、NUMA和MPP
SMP(Symmetric Multi-Processor,对称多处理器结构)、NUMA(Non-Uniform Memory Access,非一致存储访问结构)和MPP(Massive Parallel Processing,海量并行处理结构)是三种不同的计算机体系结构,它们都旨在通过使用多个处理器来提高性能,但各有其特点和应用领域:
-
SMP(Symmetric Multi-Processor,对称多处理器结构):
- 在SMP架构中,两个或更多的处理器共享同一主内存和I/O总线等资源。这种结构的处理器对于内存和其他资源具有平等的访问权,处理能力基本对等。
- SMP架构简化了数据的共享,因为所有处理器都直接访问同一内存。它通常用于通用服务器和多任务处理,适合执行多线程程序。
-
NUMA(Non-Uniform Memory Access,非一致存储访问结构):
- 在NUMA架构中,每个处理器或处理器组都有自己的本地内存,处理器访问本地内存的速度要快于访问远程(其他处理器的本地)内存。
- NUMA能够扩展更多处理器,是解决SMP扩展性限制的一种方案。适用于内存访问模式较为复杂的大型多处理器系统,如大型数据库系统。
-
MPP(Massive Parallel Processing,海量并行处理结构):
- MPP是一种分布式内存架构,每个节点(处理器)都有自己的操作系统和内存,节点间通常通过高速网络互联。
- 这种架构适用于处理大量计算密集型任务,如大数据分析和科学计算。MPP可以实现极高的并行度和扩展性,但程序需要特别设计来管理数据分割和任务分配。
各种架构的选择取决于应用需求、性能要求和成本考量。在处理并行计算和复杂数据处理任务时,理解这些基础架构对于设计和优化系统至关重要。
硬件网络设备:F5和交换机
"F5"和"交换机"都是网络设备,但它们的功能和应用场景有所不同。二者的区别
- 功能焦点:F5主要关注于应用层面的负载均衡和安全,而交换机主要关注于网络内部的数据传输和连接。
- 应用层次:F5设备一般工作在更高的网络层次(第4层至第7层),提供针对应用数据的智能处理;交换机通常在第2层,简单地处理数据帧的转发。
- 企业应用:F5更多出现在需要高度网络安全和应用性能的企业级应用中,交换机则是任何网络环境中不可或缺的基础设备。
根据网络设计的需求和特定的功能需求选择合适的设备非常重要。F5设备在确保应用交付和安全方面非常有效,而交换机则是实现网络互联的基础。

