- 1【云原生】3.5 RuoYi-Cloud部署实战(下)
- 2论文笔记——Influence Maximization on Undirected Graphs: Toward closing the (1 − 1/e) Gap_im问题最大度启发式算法
- 3LeetCode 674. 最长连续递增序列_leetcode 674.最长连续递增序列
- 4Sublime Text内运行javascript(ES6)及代码检查_sublime text能不能运行js代码?
- 5Linux Ubuntu系统版本通过Crontab设置定时任务的执行_ubuntu系统中执行crontab -e就能编辑添加定时任务
- 6LeetCode-347. 前K个高频元素 Python3版本_python前k个高频元素 给定一个非空的整数数组,返回其中出现频率前k高的元素。例如
- 7Nodejs入门详解 --- 使用(Express + MySQL + Nodejs)编写接口,附带接口实战项目_node+mysql
- 8wwwxxx域名选择(www.xxx.com或者.cn)
- 9django的auth模块_django admin 关闭auth
- 10遥感图像识别(标注)软件实现
(转)匹配追踪算法(MP)简介_匹配追踪点乘
赞
踩
图像的稀疏表征
分割原始图像为若干个
n√×n√n×n
的块. 这些图像块就是样本集合中的单个样本y=Rny=Rn. 在固定的字典上稀疏分解yy后,得到一个稀疏向量. 将所有的样本进行表征一户,可得原始图像的稀疏矩阵. 重建样本y=Rny=Rn时,通过原子集合即字典D={di}ki=1∈Rn×m(n<m)D={di}i=1k∈Rn×m(n<m)中少量元素进行线性组合即可:
y=Dxy=Dx
其中,x={x1,x2,⋯,xm}∈Rmx={x1,x2,⋯,xm}∈Rm是yy在DD上的分解系数,也称为稀疏系数.
字典矩阵中的各个列向量被称为原子(Atom). 当字典矩阵中的行数小于甚至远小于列数时,即m⩽nm⩽n,字典DD是冗余的。所谓完备字典是指原子可以张成nn纬欧式空间y=Rny=Rn. 如果在某一样本在一过完备字典上稀疏分解所得的稀疏矩阵含有大量的零元素,那么该样本就可以被稀疏表征,即具有稀疏性。一般用l0l0范数作为稀疏度量函数,图像的稀疏表征数学模型如下:
minx||x||0,s.t.y=Dxminx||x||0,s.t.y=Dx
稀疏表征不仅具有过完备性,还应该具有稀疏性。对于一个过完备字典DD,为了可以分解出更合适且稀疏的稀疏表征,应当含有更多的原子。
在稀疏表征理论方面的研究主要可分为两个方面:字典的构建和稀疏编码.
稀疏编码的目标就是在满足一定的稀疏条件下,通过优化目标函数,获取信号的稀疏系数. 经典的算法有匹配追踪(Matching Pursuit,MP)、正交匹配追踪(Orthogonal Matching Pursuit,OMP)、基追踪(Basis Pursuit,BP)算法等.
MP算法是稀疏表征中用于稀疏求解的最基本方法之一. 我在学习过程中参考网上一些资料,觉得大部分写得比较理论化,看起来稍微吃力一些. 阅读了Koredianto Usman的Introduction to Matching Pursuit(MP)一文,我觉得这篇文章写得很不错,从实例出发,很好接. 这篇博文是我对该文章翻译的基础上而写的.
注:
- 原文中有一些小错误,我在译文中进行了修改. 有对照原文阅读的同学,若发现有不一致,请不要奇怪.
- 所有计算结果都保留两位小数.
问题提出
考虑下面一个简单例子:
给定稀疏信号
x=(−1.210)x=(−1.210)
字典矩阵A为:
A=(−0.7070.7070.80.60−1)A=(−0.7070.800.7070.6−1)
(注:原文中称AA为measurement matrix)
所以,y=A⋅x=(1.65−0.25)y=A⋅x=(1.65−0.25)
现在,给定y=(1.65−0.25)y=(1.65−0.25)和A=(−0.7070.7070.80.60−1)A=(−0.7070.800.7070.6−1),
如何求得xx呢?
匹配追踪
在上面的列子中AA中的列向量称之为Basis(基)或者Atoms(原子). 所以,我们有如下原子:
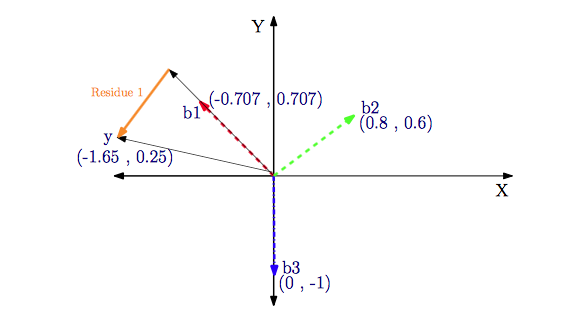
b1=(−0.7070.707)b2=(0.80.6)b3=(0−1)b1=(−0.7070.707)b2=(0.80.6)b3=(0−1)
因为A=[b1b2b3]A=[b1b2b3],如果我们令x=[abc]x=[abc],则A⋅x=a⋅b1+b⋅b2+c⋅b3A⋅x=a⋅b1+b⋅b2+c⋅b3.
A⋅xA⋅x是原子b1b1,b2b2,b3b3的线性组合
A⋅x=(−0.7070.7070.80.60−1)⋅(−1.210)=−1.2⋅(−0.7070.707)+1⋅(−0.80.6)+0⋅(0−1)=y=(−1.650.25)A⋅x=(−0.7070.800.7070.6−1)⋅(−1.210)=−1.2⋅(−0.7070.707)+1⋅(−0.80.6)+0⋅(0−1)=y=(−1.650.25)
从上面的方程可以看出,b1b1对yy值的贡献最大,然后是b2b2,最后是b3b3. 匹配追踪算法刚好逆方向进行计算:我们首先从b1b1,b2b2,b3b3中选出对yy值贡献最大的,然后从差值(residual)中选出贡献次大的,以此类推.
而贡献值的计算通过内积(点积)进行计算,MP算法步骤如下:
- 选择对yy值贡献最大的原子pi=maxj<bj,y>pi=maxj<bj,y>
- 计算差值ri=ri−1−pi⋅<ri−1,pi>ri=ri−1−pi⋅<ri−1,pi> (注:该公式在原文中稍微有点问题,这里做了修正. 对于r0=yr0=y)
- 选择剩余原子中与riri内积最大的
- 重复步骤2和3,直到差值小于给定的阈值(稀疏度)
下面进行实例计算:
首先,分别计算yy和b1b1,b2b2,b3b3的内积:
<y,b1>=−1.34,<y,b2>=1.17,<y,b3>=0.25<y,b1>=−1.34,<y,b2>=1.17,<y,b3>=0.25
取绝对值以后,我们可以发现b1b1与yy得到最大的内积值. 然后,在第一步中我们选择b1b1. 接下来计算差值:
r1=y−b1⋅<y,bi>=(1.65−0.25)−(−1.34)⋅(−0.7070.707)=(0.700.70)r1=y−b1⋅<y,bi>=(1.65−0.25)−(−1.34)⋅(−0.7070.707)=(0.700.70)
接来下,计算差值和b2b2,b3b3的内积:
<r1,b2>=0.98<r1,b3>=−0.70<r1,b2>=0.98<r1,b3>=−0.70
取绝对值以后,b2b2对yy值的贡献最大。
接下来,计算差值r2=r1−b2⋅<r1,b2>=(0.70.7)−(0.80.6)⋅0.98=(−0.080.11)r2=r1−b2⋅<r1,b2>=(0.70.7)−(0.80.6)⋅0.98=(−0.080.11)
最后,计算r2r2与b3b3的内积:<r2,b3>=−0.11<r2,b3>=−0.11
所以,最后的三个稀疏稀疏是(−1.340.98−0.11)(−1.340.98−0.11)
这和准确的系数(−1.210)(−1.210)很接近
反酸回去,和给定的yy也很接近.
A⋅x=(−0.7070.7070.80.60−1)⋅(−1.340.98−0.11)=(1.73−0.25)A⋅x=(−0.7070.800.7070.6−1)⋅(−1.340.98−0.11)=(1.73−0.25)
MP算法实质
从下面的图,我们可以很清楚地看到MP算法的实质:就是利用原子向量的线性运算去逐渐去逼近信号向量,经过不停地迭代,最后达到给定的稀疏度.
匹配追踪算法可以直接得到信号稀疏性的表达. 以贪婪迭代的方法选择DD的列,使得在每次迭代的过程中所选择的列与当前冗余向量最大程度的相关.