
- 1Android——最强大的RecyclerView框架
- 2Flink集成kafka消费数据和推送消息_flink 推送
- 3lstm 文本纠错_PyCorrector文本纠错工具实践和代码详解
- 4【面试题】手写Promise_面试题手写一个promise代码
- 5J204B接口简介
- 6数据结构:顺序表的实现
- 7KVM IO虚拟化_virtualio和virtual bus
- 8用Python的flask、tornado和fastapi探索SSE推送服务_flask sse
- 92024年运维最新dbeaver安装和使用教程_dbeaver使用教程,2024年最新透彻解析
- 10el-select的错误提示不生效、el-select验证失灵、el-select的blur规则失灵_elementplus el-select v-model placeholder 不生效
快讯|大数据挑战赛周周星评选获奖队伍公布,附赛事经验分享!
赞
踩

2024中国高校计算机大赛-大数据挑战赛初赛阶段周周星奖项评选环节开始啦,通过对参赛选手在线提交相关模型文件的系统自动评测得分(以7月3日18:00榜单排名为准),第一周周周星在校生队伍和在职队伍排名榜单已出炉,恭喜获奖的学生队伍!
目前榜单前三名的队伍在参赛中有哪些实战的经验呢,让我们一起听听他们的分享吧!

深度不爱学习-获奖经验分享

首先,很荣幸能获得这周的周周星来进行分享,当然首先要声明我目前分数是两个sota模型融合的结果,单模大概是1.0,所以在此抛砖引玉吧,我们主要是将此次比赛分成了四个部分,我们是尝试在以下四个部分去思考,来寻找上分的方法,以下是我们在各个部分的一些思路和做法。
1.数据:
①数据可以操作的空间不多,但是看讨论区聊过的后期可以尝试根据温度等气候筛选中国或者与中国类似的站点,在训练好的模型后进行增量训练
2.模型:
①尝试不同的sota模型,当然这边差距不大,因为很多模型都只是attention机制不同,可以试试叠加attention
②尝试修改模型的decoder,比如加入cnn或者lstm、mlp,我们实测有上分,就是层数要把握好一点,层数太深可能会过拟合。
③增加encoder层数,用不同的encoder叠加
④后期模型融合
⑤刚刚从群里看到的,可以使用多任务训练,也就是同时预测两个变量,这可能是因为两个变量也存在互相影响的关系。
⑥使用两个模型时,两个变量不一定要使用一样的模型,可以根据实际表现对两个模型进行调整。
3.训练
①线下划分验证集进行观察,目前我们也是划分最后的0.1,但是效果不好,可以试试随机站点+随机时间窗。
②bs内存充足可以尝试使用稍大的bs,这样一定程度上应该能够防止模型的过拟合。
③调整超参数(lr,使用学习率调度器)
④模型防过拟合(EMA之类的)
⑤通过对抗训练在训练时添加噪声,一定程度也可以避免过拟合,起到数据增强的效果。
4.后处理
①预测平滑处理,用之前的一些数据进行移动平均防止后面的预测过于激进
②可以试试专门训练一个后处理模型
在具体的一些参数设置上,我们的学习率是0.1,epochs是3
扫地僧-获奖经验分享
大家好,我是扫地僧团队的队长,以前参加这样打榜的比赛比较少,了解的打榜技巧不是太多,所以想从科研的角度给大家一点分享。
这次比赛主要从以下五个步骤进行:1.数据集构造 2.Baseline选择 3.模型优化 4.模型调参 5.模型集成
1. 数据集构造
官方已经给了数据集,可以尝试根据温度筛选出与中国温度类似的场站,但是不确定是否会有效果:

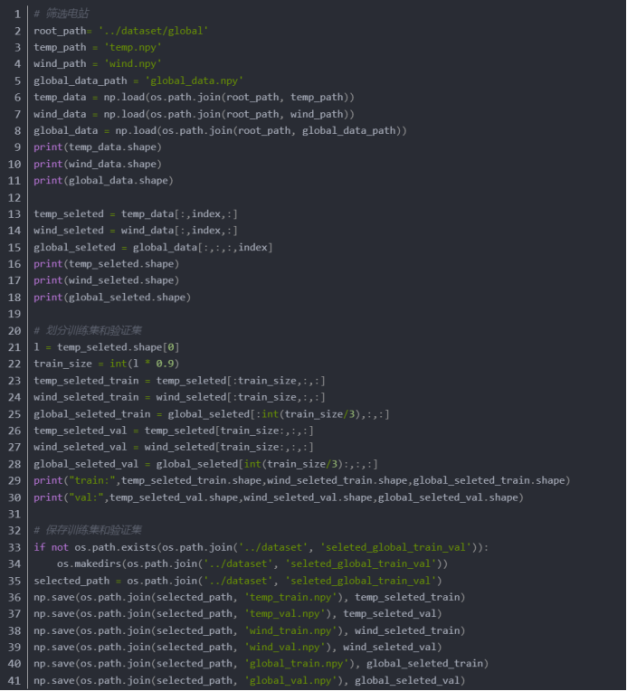
筛选后温度和风速形状如图所示:

2. Baseline选择
官方Baseline给的是iTransformer,关于iTransformer模型的解读请参考:【PaperInFive-时间序列预测】iTransformer:转置Transformer刷新时间序列预测SOTA(清华)
可以关注近近两年开源的SOTA模型,这里分享一个Github,可以去上面找近年的SOTA模型:https://github.com/ddz16/TSFpaper
3. 模型优化
选好效果好的Baseline后就可以进行模型优化,比如iTransformer只建模了特征信息,那么可以在模型中补充对时序特征的建模,比如进行一些卷积操作,或者在时间维度上进行self-Attention,关于时间维度上的建模大家也可以参考SOTA论文,可以把不同论文里的模块进行一个融合,说不定会有好效果。
4. 模型调参
确定了模型结构后就可以进行模型超参数的调整,比如模型的维度和层数,学习率和batch size等,经过测试增加模型的dimention在一定程度上可以提高模型表现,但是增加层数好像效果不太明显。
学习率方面我初始值为0.01或0.005,每一轮除以2进行衰减。batch size我设为40960。
5. 模型集成
最后可以把不同特征的模型进行集成,比如可以把多个模型的结果取平均,或者可以在训练时采用Mixture of Expert的方式加权求和。
帮助代码
1. 模型测试
加在exp_long_term_forecasting.py里面:
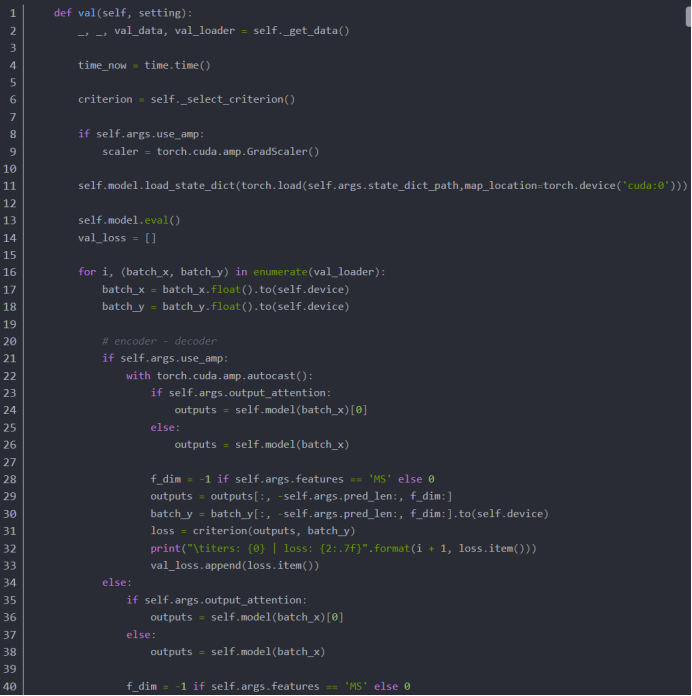
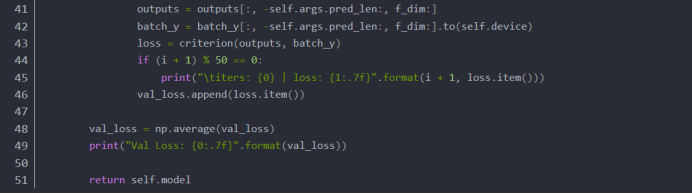
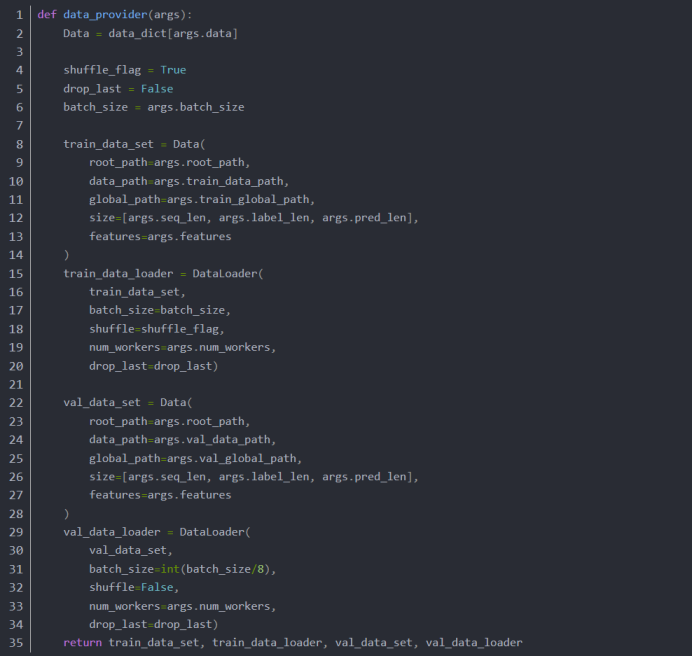
2. 验证集Dataloader
加在data_factory.py里面:
最后
希望大家以赛为友,共同进步,一起分享一些有用的小技巧。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议。
原文链接:https://blog.csdn.net/cyj972628089/article/details/140163246
xiyan队-获奖经验分享
首先,很荣幸有机会分享自己对于赛题的理解和方案,同时也希望能学习和收获到更多的知识和比赛经验。
目前的方案:
1.只用了baseline的iTransformer模型,单模成绩在1.01左右;因为考试的原因前段时间没有更多时间投入比赛当中,个人目前没有在模型的选择上进行更多的尝试;对于temp和wind是分开训练的,看到群中的讨论可以用一个模型训练,感觉可以尝试一下。
2.在训练时,目前没有划分验证集进行线下验证,只是大致看mse损失,训练集损失temp大概在5.8-6.1左右,wind大概在3.4左右;同时,在训练wind时梯度容易爆炸,训练时不太容易训练,相同的模型可能temp的loss在一直下降,但wind无法训练,所以最近的尝试和提分也都是temp的提升,个人感觉temp的误差也比wind更容易降低。
3.在提分过程中没有过多在意一些细节,例如batch_size、learning_rate等超参数并没有细致的选择,只是大概确定训练方向后做实验尝试进行提分。
训练过程中的实验:
1.在baseline跑通后,简单训练5轮左右以后就可以达到1.07左右的分数。
2.在之后的尝试只是对iTransformer进行调整,可以观察训练时的loss大致呈下降趋势即可,个人认为模型没有太过于拟合训练数据,暂时没有线下loss下降,同时线上分数变差的情况。
下一步的方向:
1.结合一些新的sota模型,边学边改,后期的提分可能会在不同模型的融合上。
2.目前对数据的理解不是很深入,个人感觉在数据的处理方式上进行一些改进可能是后期提分的关键。
最后,欢迎和大家交流和学习。

本次大赛组委会精心为每周的周周星获奖者们准备了琳琅满目、极具民族特色的奖品大礼包,让我们先一睹为快!



上下滑动浏览
特别介绍:大赛主办方之一、决赛比赛地点预告
——鄂尔多斯欢迎你!

鄂尔多斯,这座融合了古老文明与现代科技的活力之城,以它独有的“暖城”魅力,张开怀抱欢迎来自世界各地的参赛者。作为内蒙古经济发展的领航者,鄂尔多斯在新能源、新材料、现代煤化工以及羊绒产业等领域树立了世界级的标杆,这里不仅拥有国家煤炭保障基地的坚实后盾,还有清洁电力供应、油气战略储备、氢能应用示范及储能实证的前沿探索,是国家能源安全的坚实“压舱石”。
在这片充满无限可能的土地上,大数据挑战赛不仅仅是对参赛者的历练,更是鄂尔多斯展现其魅力与潜力的窗口。大赛期间,除了紧张激烈的比赛,选手们还将有机会漫步在鄂尔多斯的蓝天白云下,体验草原文化的民族特色,感受生态与人文的和谐共生,见证这座城市在创新驱动下的日新月异。


目前,大赛报名阶段接近尾声,已有来自340多所高校和企事业单位参赛,报名总人数突破2000人。参赛选手可以继续从指定网站下载比赛的训练数据和测试数据,并在线提交相关模型文件,报名截止至7月12日12:00。
每一次努力都值得被看见,每一份才华都值得被赞赏。让我们一起,用代码书写梦想,用数据描绘未来!

欢迎了解更多(数据派THU菜单栏-关于我们-大赛入口)
• 大赛官网:http://nercbds.tsinghua.edu.cn/bdc/
• 大赛小程序:可赛
• 大赛邮箱:data@tsinghua.edu.cn
• 大赛 QQ 群:762146461 / 901317172
点击阅读原文,观看大赛启动会直播回顾


