
热门标签
热门文章
- 1P4770 [NOI2018] 你的名字 洛谷黑题题解详解
- 2Python-模块与包_关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无
- 3C语言实现(封装、继承和多态)_c实现继承
- 4linux磁盘空间查看及空间满的处理,linux磁盘空间占满问题快速定位并解决
- 5VScode 中 Python 代码不高亮显示怎么办?_vscode的python语法不高亮
- 6Failed to obtain JDBC Connection; nested exception is java.sql.SQLException_failed to obtain jdbc connection; nested exception
- 7怎么让linux支持yum,如何安装和使用'yum-utils'来维护Yum并提高其性能
- 8向爬虫而生---Redis 拓宽篇6<redis分布式锁 ---ZooKeeper>
- 9AIGC|AGI究竟是什么?为什么大家都在争先入场?
- 10Docker入门安装、镜像与容器下载 —— 基本操作
当前位置: article > 正文
Python openpyxl使用教程
作者:我家小花儿 | 2024-02-16 13:10:15
赞
踩
openpyxl
openpyxl是Python下的Excel库,它能够很容易的对Excel数据进行读取、写入以及样式的设置,能够帮助我们实现大量的、重复的Excel操作,提高我们的办公效率,实现Excel办公自动化。
- 安装方法:
pip install openpyxl - 国内镜像安装:
pip install -i https://mirrors.aliyun.com/pypi/simple/ openpyxl(推荐,安装更快) - 中文文档:https://www.osgeo.cn/openpyxl/index.html#usage-examples
- 工作簿、工作表、单元格之间的关系:
- 一个工作簿(workbook)由多个工作表(worksheet)组成;
- 一个工作表有多个单元格(cell)组成;
- 通过行(row)和列(column)可以定位到单元格。
新建并写入文件
- Workbook():新建excel文件,新建文件时默认有一个名为Sheet工作表
# coding=utf-8
from openpyxl import Workbook
wb = Workbook() # 新建工作簿
ws = wb.active # 获取工作表
ws.append(['姓名', '学号', '年龄']) # 追加一行数据
ws.append(['张三', "1101", 17]) # 追加一行数据
ws.append(['李四', "1102", 18]) # 追加一行数据
wb.save(r'测试1.xlsx') # 保存到指定路径,保存的文件必须不能处于打开状态,因为文件打开后文件只读
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
打开并读取文件
- load_workbook(path):加载指定路径的excel文件
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active # 获取工作表
for row in ws.values: # 输出所有数据
print(row)
- 1
- 2
- 3
- 4
- 5
- 6

工作簿对象-workbook
- wb.active :获取第一张工作表对象
- wb[sheet_name] :获取指定名称的工作表对象
- wb.sheetnames :获取所有工作表名称
- wb.worksheets:获取所有工作表对象,wb.worksheets[0]可以根据索引获取工作表,0代表第一个
- wb.create_sheet(sheet_name,index=“end”):创建并返回一个工作表对象,默认位置最后,0代表第一个
- wb.copy_worksheet(sheet):在当前工作簿复制指定的工作表并返回复制后的工作表对象
- move_sheet( sheet, offset=0):移动工作表,offset代表偏移量,正数向后移,负数向前移
- wb.remove(sheet):删除指定的工作表
- ws.save(path):保存到指定路径path的Excel文件中,若文件不存在会新建,若文件存在会覆盖
# coding=utf-8 from openpyxl import load_workbook wb = load_workbook(r"测试1.xlsx") """获取工作表""" active_sheet = wb.active # 获取第一个工作表 print(active_sheet) # 输出工作表:<Worksheet "Sheet"> by_name_sheet = wb["Sheet"] # 根据工作表名称获取工作表 by_index_sheet = wb.worksheets[0] # 根据工作表索引获取工作表 """获取所有工作表""" print("获取所有",wb.sheetnames) """新建工作表""" New_Sheet = wb.create_sheet("New") # 在最后新建工作表 First_Sheet = wb.create_sheet("First",index=0) # 在开头新建工作表 print("新建后",wb.sheetnames) """复制工作表""" Copy_Sheet = wb.copy_worksheet(active_sheet) # 复制第一个工作表 Copy_Sheet.title = "Copy" print("复制后",wb.sheetnames) """删除工作表""" wb.remove(First_Sheet) # 根据指定的工作表对象删除工作表 wb.remove(New_Sheet) print("删除后",wb.sheetnames) wb.save(r"测试2.xlsx")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

工作表对象-worksheet
- ws.title:获取或设置工作表名
- ws.max_row:工作表最大行数
- ws.max_column:工作表最大列数
- ws.append(list):表格末尾追加数据
- ws.merged_cells:获取所有合并单元格
- ws.merge_cells(‘A2:D2’):合并单元格
- ws.unmerge_cells(‘A2:D2’):解除合并单元格。
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active
print("工作表名",ws.title)
ws.title = "学生信息表"
print("修改后工作表名",ws.title)
print("最大行数",ws.max_row)
print("最大列数",ws.max_column)
ws.append(["王五","1103",17])
print("最大行数",ws.max_row)
wb.save(r"测试3.xlsx")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

单元格读取
- ws[‘A1’]:根据坐标获取单个单元格对象
- ws.cell(row, column, value=None):根据行列获取单个单元格对象,其中cell(1,1)代表A1
- ws[1]:获取第一行所有单元格对象,ws[“1”]也可
- ws[“A”]:获取第A列所有单元格对象
- ws[“A”:“B”]:获取A到B列所有单元格对象,ws[“A:B”]也可
- ws[1:2]:获取1到2行所有单元格对象,ws[“1:2”]也可
- ws[“A1”:“B2”]:获取A1到B2范围所有单元格对象,ws[“A1:B2”]也可。
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx')
ws = wb.active
A1 = ws["A1"] # 根据坐标获取单个单元格
print("第一行第一列",ws.cell(1,1)) # 根据行列获取单个单元格
print("第一行",ws[1])
print("第A列",ws["A"])
print("A到B列",ws["A":"B"])
print("1到2行",ws["1":"2"])
print("A1到B2范围",ws["A1":"B2"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

- ws.values:获取所有单元格数据的可迭代对象,可以通过for循环迭代或通过list(ws.values)转换为数据列表
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active # 获取工作表
for row in ws.values: # for循环迭代
print(row)
print(list(ws.values)) # 转换为数据列表
- 1
- 2
- 3
- 4
- 5
- 6
- 7

- ws.rows:获取所有数据以行的格式组成的可迭代对象
- ws.columns:获取所有数据以列的格式组成的可迭代对象
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx')
ws = wb.active
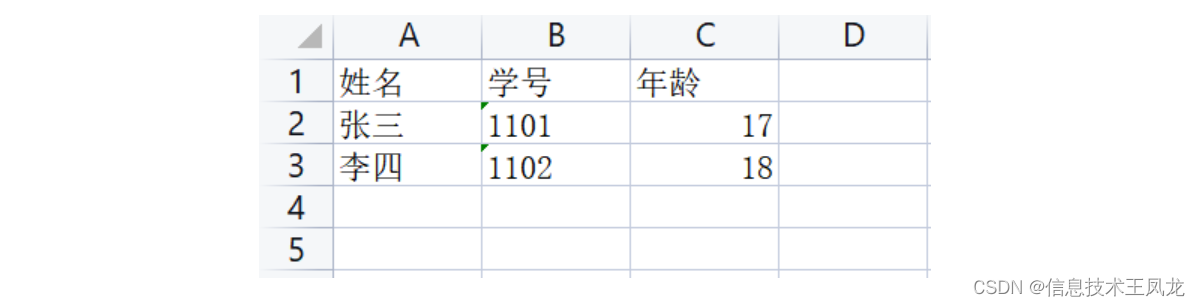
for row in ws.rows: # 以行的形式迭代
print(row)
print("-"*55)
for col in ws.columns: # 以列的形式迭代
print(col)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- ws.iter_rows(min_row=None, max_row=None, min_col=None, max_col=None):获取指定边界范围并以行的格式组成的可迭代对象,默认所有行
- ws.iter_cols(min_col=None, max_col=None, min_row=None, max_row=None): 获取指定边界范围并以列的格式组成的可迭代对象,默认所有列
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx')
ws = wb.active
for row in ws.iter_rows(max_row=2,max_col=2): # 指定边界范围并以行的形式可迭代
print(row)
print("-"*35)
for column in ws.iter_cols(max_row=2,max_col=2): # 指定边界范围并以行的形式可迭代
print(column)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

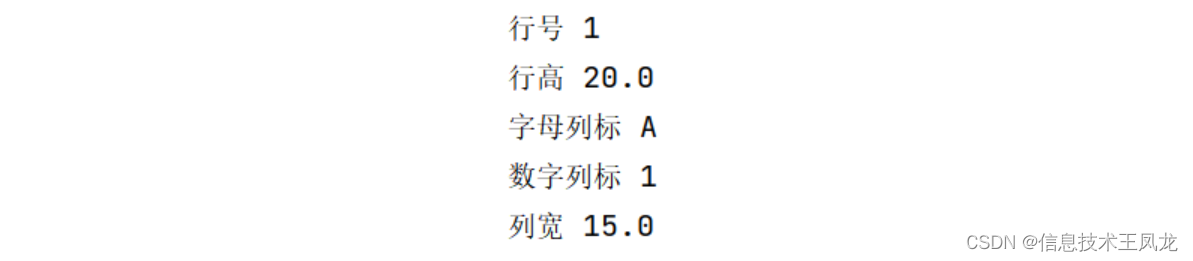
单元格对象 - cell
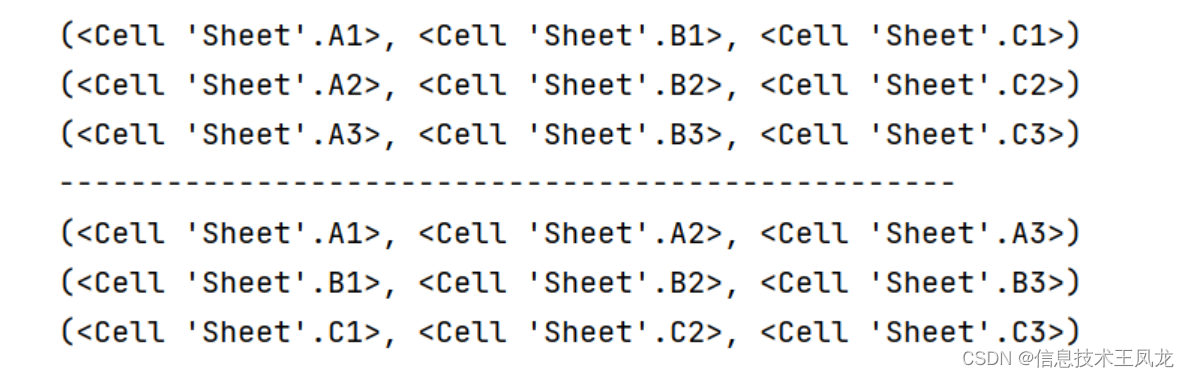
- cell.value :获取或设置值
- cell.column : 数字列标
- cell.column_letter : 字母列标
- cell.row : 行号
- cell.coordinate : 坐标,例如’A1’
- cell.data_type : 数据类型, ’s‘ = string字符串,‘n’ = number数值,会根据单元格值自动判断
- cell.number_format :单元格格式,默认”General“常规,详见excel自定义数据类型
- cell.hyperlink:获取或设置单元格超链接(可以是网址或者本地文件路径)
# coding=utf-8 from openpyxl import Workbook wb = Workbook() # 新建工作簿 ws = wb.active """获取与设置单元格值的两种方式""" cell1 = ws.cell(1, 1) # 先获取第一行第一列的单元格对象 cell1.value = 18 # 再设置单元格对象的值 print("值", cell1.value) print("数字列标", cell1.column) print("字母列标", cell1.column_letter) print("行号", cell1.row) print("坐标", cell1.coordinate) cell2 = ws.cell(2, 1, 17) # 直接在获取单元格的时候设置值 """使用公式和不适用公式""" cell3 = ws.cell(3, 1, "=A1+A2") # 直接输入公式具有计算功能 cell4 = ws.cell(4, 1, "=A1+A2") cell4.data_type = 's' # 指定单元格数据类型为文本可以避免公式被计算 """设置格式和不设置格式""" cell5 = ws.cell(5, 1, 3.1415) # 默认常规格式 cell6 = ws.cell(6, 1, 3.1415) cell6.number_format = "0.00" # 设置格式为保留两位小数 """超链接""" cell7 = ws.cell(7, 1, "百度翻译") cell7.hyperlink = "https://fanyi.baidu.com/" # 设置超链接 # cell7.hyperlink = r"C:\Users\admin\Desktop\测试.xlsx" # 打开本地文件 # print(cell7.hyperlink.target) # 获取超链接地址 cell7.font = Font(color="0000FF", underline='single') # 字体颜色为蓝色+下划线 wb.save(r'测试4.xlsx') # 保存到指定路径
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
单元格样式
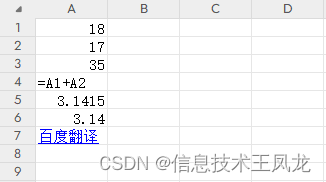
- cell.font :获取或设置单元格Font对象
- cell.border : 获取或设置单元格边框
- cell.alignment : 获取或设置单元格水平、垂直对齐方式、自动换行等
- cell.fill:获取或设置单元格填充颜色
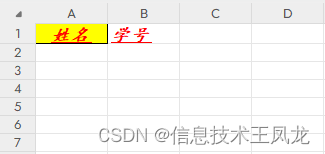
from openpyxl import Workbook from openpyxl.styles import Font, Border, Side, Alignment,PatternFill from copy import copy wb = Workbook() ws = wb.active """获取单元格并设置单元格值为 姓名 """ cell = ws.cell(1,1,"姓名") """设置单元格文字样式""" cell.font = Font(bold=True, # 加粗 italic=True, # 倾斜 name="楷体", # 字体 size=13, # 文字大小 color="FF0000", # 字体颜色为红色 underline='single' # 下划线 ) """复制单元格样式""" cell2 = ws.cell(1,2,"学号") cell2.font = copy(cell.font) """设置单元格边框为黑色边框""" cell.border = Border(bottom=Side(style='thin', color='000000'), right=Side(style='thin', color='000000'), left=Side(style='thin', color='000000'), top=Side(style='thin', color='000000')) """设置单元格对齐方式为水平居中和垂直居中,单元格内容超出范围自动换行""" cell.alignment = Alignment(horizontal='center',vertical='center',wrap_text=True) """设置单元格底纹颜色为黄色""" cell.fill = PatternFill(fill_type='solid', start_color='FFFF00') """ 白色:FFFFFF,黑色:000000,红色:FF0000,黄色:FFFF00 绿色:00FF00,蓝色:0000FF,橙色:FF9900,灰色:C0C0C0 常见颜色代码表:https://www.osgeo.cn/openpyxl/styles.html#indexed-colours """ wb.save(r"测试5.xlsx")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
列宽与行高
- ws.row_dimensions[行号]:获取行对象(非行数据,包括行的相关属性、行高等)
- ws.column_dimensions[字母列标]:获取列对象(非行数据,包括行的相关属性、列宽等)
- get_column_letter(index):根据列的索引返回字母
- column_index_from_string(string):根据字母返回列的索引
- row.height:获取或设置行高
- column.width:获取或设置列宽
from openpyxl import Workbook from openpyxl.utils import get_column_letter,column_index_from_string wb = Workbook() ws = wb.active """行""" row = ws.row_dimensions[1] # 获取第一行行对象 print("行号",row.index) row.height = 20 # 设置行高 print("行高",row.height) """列""" column = ws.column_dimensions["A"] # 根据字母列标获取第一列列对象 column = ws.column_dimensions[get_column_letter(1)] # 根据数字列标获取第一列列对象 print("字母列标",column.index) print("数字列标",column_index_from_string(column.index)) column.width = 15 # 设置列宽 print("列宽",column.width) wb.save(r'测试6.xlsx')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
如何根据输入内容计算其在excel的列宽是多少?
- 利用GBK编码方式,非汉字字符占1个长度,汉字字符占2个长度
from openpyxl import Workbook
from openpyxl.utils import get_column_letter,column_index_from_string
wb = Workbook()
ws = wb.active
column = ws.column_dimensions[get_column_letter(1)] # 根据数字列标获取第一列列对象
value = "我爱中国ILoveChain" # 4*2+10*1+1=19
column.width = len(str(value).encode("GBK"))+1 # 根据内容设置列宽,+1既可以补充误差又可以让两边留有一定的空白,美观
print("列宽",column.width) # 输出:19
ws.cell(1,1,value)
wb.save(r'测试6.xlsx')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

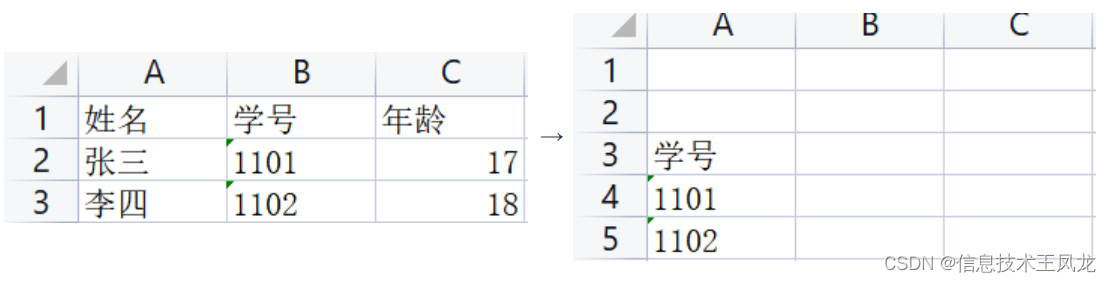
插入和删除行和列
插入和删除行、列均使用数字指定
- ws.insert_rows(row_index,amount=1):在第row_index行上方插入amount列,默认插入1列
- ws.insert_cols(col_index,amount=1):在第col_index列左侧插入amount列,默认插入1列
- ws.delete_rows(row_index,amount=1):从row_index行开始向下删除amount行,默认删除1行
- ws.delete_cols(col_index,amount=1):从col_index列开始向右删除amount行,默认删除1列
from openpyxl import Workbook,load_workbook
wb = load_workbook("测试1.xlsx")
ws = wb.active
ws.insert_rows(1,2) # 在第一行前插入两行
delete_col_index = [1,3] # 删除1、3两列
"""为避免删除多列时前面列对后面列产生影响,采取从后面列往前面列删的策略,行同理"""
delete_col_index.sort(reverse=True) # 从大到小排序
for col_index in delete_col_index:
ws.delete_cols(col_index)
wb.save(r'测试7.xlsx')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
插入和获取图片
插入图片
- ws.add_img(img,“坐标”):添加图片到指定单元格位置
from openpyxl import Workbook
from openpyxl.drawing.image import Image
wb = Workbook()
ws = wb.active
img = Image('logo.png') # 打开图片
img.width,img.height = 80,80 # 设置图片宽、高
ws.add_image(img, 'A1')
wb.save('logo.xlsx')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
获取图片
- ws._images:获取当前工作表的图片列表
from openpyxl import load_workbook
from PIL import Image as PILImage
wb = load_workbook(r'logo.xlsx')
ws = wb.active
for img in ws._images:
img = PILImage.open(img.ref) # 获取图片对象
img.save(r'logo.{}'.format(img.format)) # 保存图片到指定位置
"""获取多张图片"""
for index,img in enumerate(ws._images):
img = PILImage.open(img.ref) # 获取图片对象
img.save(r'图片{}.{}'.format(index+1,img.format)) # 保存图片到指定位置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
综合写入实践
写入后的效果如下:
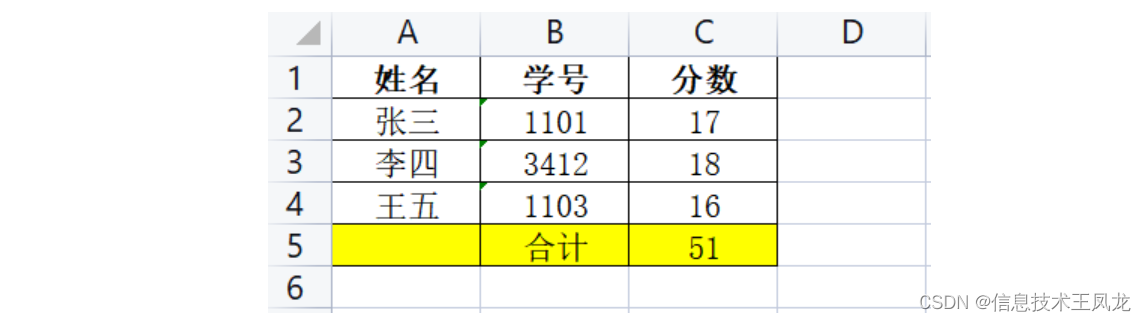
# coding=utf-8 from openpyxl import Workbook from openpyxl.styles import Font, Border, Side, Alignment, PatternFill wb = Workbook() ws = wb.active """设置全局样式""" border = Border(bottom=Side(style='thin', color='000000'), right=Side(style='thin', color='000000'), left=Side(style='thin', color='000000'), top=Side(style='thin', color='000000')) alignment = Alignment(horizontal='center', vertical='center') row_index = 1 # 写入的行索引,每写入一行后+1 """写入标题""" title = ['姓名', '学号', '分数'] for index,item in enumerate(title): cell = ws.cell(row_index,index+1,item) cell.border = border cell.alignment = alignment cell.font = Font(bold=True) row_index += 1 data = [['张三', "1101", 17],['李四', "3412", 18],['王五', "1103", 16]] """写入正文""" for row in data: for index,item in enumerate(row): cell = ws.cell(row_index, index + 1, item) cell.border = border cell.alignment = alignment row_index += 1 """写入结果""" result = ["", "合计", 17+18+16] for index,item in enumerate(result): cell = ws.cell(row_index,index+1,item) cell.border = border cell.alignment = alignment cell.fill = PatternFill(fill_type='solid', start_color="FFFF00") wb.save(r"学生信息表.xlsx")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
合并表格

# coding=utf-8 from openpyxl import Workbook,load_workbook import os dir_path = "学生名单" # 要合并文件的文件夹地址 """读取文件夹下的所有excel文件""" files = [] for file in os.listdir(dir_path): # 获取当前目录下的所有文件 files.append(os.path.join(dir_path,file)) # 获取文件夹+文件名的完整路径 """以第一个文件为基本表""" merge_excel = load_workbook(files[0]) merge_sheet = merge_excel.active """遍历剩余文件,追加到基本表""" for file in files[1:]: wb = load_workbook(file) ws = wb.active for row in list(ws.values)[1:]: # 从第二行开始读取每一行并追加到基本表 merge_sheet.append(row) merge_excel.save("高一学生汇总.xlsx")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
拆分表格
# coding=utf-8 from openpyxl import Workbook,load_workbook import os file_path = "高一学生汇总.xlsx" # 要拆分的文件地址 split_dir = "拆分结果" # 拆分文件后保存的文件夹 group_item = "班级" # 拆分的依据字段 """打开拆分的excel文件并读取标题""" wb = load_workbook(file_path) ws = wb.active title = [] for cell in ws[1]: title.append(cell.value) """开始分组,分组结果保存到字典,键为班级名,值为班级学生列表""" group_result = {} # 存储分组结果 group_index = title.index(group_item) # 获取拆分依据字段的索引 for row in list(ws.values)[1:]: class_name = row[group_index] # 获取分组依据数据,即班级名 if class_name in group_result: # 如果分组存在就追加,不存在就新建 group_result[class_name].append(row) else: group_result[class_name] = [row] """创建输出文件夹""" if not os.path.exists(split_dir): # 如果不存在文件夹就新建 os.mkdir(split_dir) os.chdir(split_dir) # 进入拆分文件夹 """打印并输出分组后的数据""" for class_name,students in group_result.items(): new_wb = Workbook() # 新建excel new_ws = new_wb.active new_ws.append(title) # 追加标题 for student in students: new_ws.append(student) # 讲分组数组追加到新excel中 new_wb.save("{}.xlsx".format(class_name))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
作业提交情况检测
# encoding: utf-8 import os from openpyxl import Workbook, load_workbook excel_path = r"学生名单/高一1班.xlsx" # excel文件路径 job_path = r"作业" # 作业文件夹路径 """获取姓名列表""" wb = load_workbook(excel_path) ws = wb.active names = [] for cell in ws["C"][1:]: # 获取第C列第2行开始的数据 names.append(cell.value) """获取作业列表""" os.chdir(job_path) # 切换到作业目录 files = [] # 获取文件列表 for file in os.listdir(): files.append(os.path.splitext(file)[0]) """作业检测""" yes,no = [],[] for name in names: # 逐个姓名判断 if name in files: # 判断姓名是否在文件列表中 yes.append(name) # 如果在,添加到已完成名单 else: no.append(name) # 否则,添加到未完成名单 print("已完成人数:{},已完成名单:{}".format(len(yes),yes)) print("未完成人数:{},未完成名单:{}".format(len(no),no))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/93585
推荐阅读
相关标签

