
- 1微信小程序uniapp+springboot实现小程序服务通知_微信小程序 服务通知
- 2docker.service启动失败:Unit not found_failed to start docker.service:unit not found
- 3云计算基础
- 4第十五章 拦截器_wen.xml拦截器只拦截某一个
- 5elementUI 去除导航菜单menu横向滚动条和竖向滚动条_elementui 导航栏菜单有滑块怎么取消
- 6selenium自动化测试的安装与配置_selemuit软件自动化测试软件的安装
- 7ElasticSearch 7.3 实战:中文分词器(IK Analyzer)及自定义词库
- 8国产化网管实现方案
- 9RabbitMq的五大消息模型及Java代码演示_rabbitmq五种消息模型
- 10uniapp——新闻列表(uni-list、uni-list-item)--顶部下拉刷新--上拉加载更多--顶部提示语
AI推理红海战:百万Token一元钱,低价背后藏何种猫腻?
赞
踩

原创:谭婧
(一)价格战?
就在最近,看到,就被震惊到。
竟然有推理服务的价格降到了:
每百万个Token,只要1块钱。
准确是:输入1块,输出2块。
“卷”出超低价。
没有最惊,只有更惊,
你一到两块?
某厂我8毛。
某厂我直降97%。
某厂我免费,立即生效。
要知道,前几周,
谭老师我拿价格打个比方,
都不敢用这种价格。
故事情节已经发展到,
编剧都不敢编的时候,
戏剧化的程度可见一斑。
脑海中迷之浮现一支神曲,
钵钵鸡,一元一串的钵钵鸡。
好吧,钵钵鸡都不知道,
买“一百万的Tokens”的钱,快买不了钵钵鸡了。
科技与美食的缘分妙不可言。
不开玩笑了
讲回AI推理服务,
单论价格这件事,
对消费者(用户)来说,
越低越好。
对于高投入的大模型创业公司,
及其投资人来说,
就悲剧了。
为什么这么说?
大模型训练是投入,俗称烧钱。
大模型推理是赚钱,俗称回本。
回本之时,打价格战。
这是好事吗?
红海市场不可能由成本决定价格,
而是市场参与者们共同决定价格。
当每次服务的价格确定,
收入等于价格乘以次数。
大模型的预期收入,
相信投资人已经拿小本本算出来了。
推理放量,利润才厚。
用户也能用得划算。
价格便宜的好处显而易见,
大大有利于技术推广。
大模型的竞争,
有点高端商战的味道了。
不再是:
翻墙偷商密文件,
开水浇竞争对手门口发财树……
(二)中国厂商靠什么博眼球?
红海市场的商品,似乎越便宜越有竞争力。
但是,可以孤立谈价格的前提是,
商品的其他要素完全一样。
对于标准化的商品来说,
这很好对比。
对于推理这样的高科技服务来说,
对比难度很大。
于是,打广告的操作空间就大了。
参考中文俗语的智慧就是:
“抛开剂量谈毒性,就是耍流氓”,
理解推理有服务,有个高门槛。
推理服务的吞吐很重要,
也就是,到底是高并发,还是低并发。
这里应该有个中文俗语:
抛开并发数量谈推理价格,就是耍流氓。
有没有一种可能,某厂商是高情商:
低价只给了低并发,
高并发还是高价。
也就是说,抢一些试用客户,大客户价格没有变。
一但企业用户用了,大概率高并发。
比如,企业级推理服务,几万个员工,
整个公司流程系统里面嵌入大模型服务。
一秒钟小几万个并发,也属于正常。
我们算一笔账,
甲方企业客户手里的GPU有100个,
一秒的请求数少一点,
就算1000个请求,
那么,平均并发数是10。
这种情况肯定不能用低并发的价格,
并发数量远远高于一秒钟一个。
关键问题是,广告打得到位,企业用户才会来用。
时值夏日,便于理解,
姑且管低并发服务叫做“夏日体验装”吧。
再有没有一种可能,
另一家某厂商也是高情商:
百万Token 8毛钱啦,
但是,前提是每秒不要超过1个调用请求。
中国式智慧,果然“但是”后面才是重点。
便宜货果然只适用于体验。
再再有没有一种可能,
一些厂商是低情商,
他们家的“体验装”还免费呢,
直接被高情商厂商的广告冲击了。
再再再有没有一种可能,
某些厂商为了疯狂卷死对手,
具体不透露,就说免费,立刻生效,
你得和销售具体询价。
高并发的一切成本都是非常高的,
低价?你想什么呢。
下次,请直接和厂商商务人员这样询价:
麻烦将高并发的价格,低并发的价格分别报价。
也就是说,两种情况下,
词(Token)的价格完全不一样。
谭老师我感觉,一天之内,这价格,
玩出了股价的既视感,真刺激。
科技产品的秘密,从来不是唾手可得。
为此,要付出点脑力代价。
不好意思,前方知识高能预警。
好的,我们聊一下,
推理的运作原理是什么?并发是什么?
推理分两步走:
准备(Prefill)和生成(Decoding)。
如果记不住,可以看一下这张图。
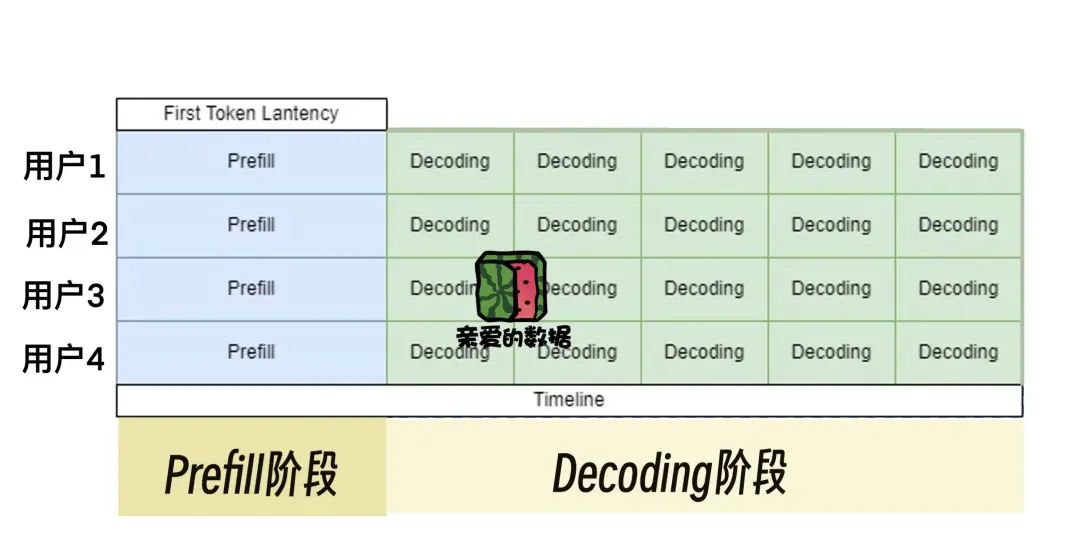
大模型推理,
这是一个时间,价格,生成Token数量的游戏。
要分开讨论,两个阶段也是两种情况
第一步,
聊聊准备(Prefill)。
一个大模型,可以支持多次计算过程同时进行。
当然,只要系统支撑得住,
同时进行的计算数量越多越好。
一次计算收一份钱,
同时进行100次计算就可以同时收100份钱。
岂不美哉。
把系统的能力看做算力,
接待请求数量的能力越强越好。
好比,办婚礼收份子钱,只要席面坐的下,
来给份子钱的客人,越多越好。
上限是什么呢?
是时间。
一般,人类忍受的极限1-3秒,此处取2秒。
2秒内返回所有的请求。
老师下课可以拖堂,
而生成第一个Token的耗时,
不可能无节制的延长。
反过来理解,当目标时间确定,
接待客人的数量越多越好。
因为Prefill总时长和这一期间接待客人的数量成正比。
为了好理解,后文中,
我把推理所需权重和参数都装在一起这件事,
称为装箱子。
为什么叫箱子?
因为推理的时候,里面的东西总要被搬来搬去。
而并发请求的所有用户,
我称之为,共用箱子人。
共用箱子的人数,会影响到下一个阶段,
也就是在生成(Decoding)阶段,
共用箱子人越多的吞吐越高。
第二步,聊聊生成(Decoding)。
因为生成(Decoding)的核心是,
绝大部分时间都用来搬运箱子(权重和参数)了。
而好处是只搬运一次箱子就够了,
然后,大家一起来共用箱子。
比如,你只要搬运一次箱子,
之后哪怕10个请求一起来(并发),
都可以把10个请求同时处理完毕。
因为在生成(Decoding)的时候,
所有人一块儿用同一个箱子。
比如,一个箱子搬运完,
给10个人一起用。
这样,每秒的Token数量自然就高。
我们讨论两种情况来加深理解。
当推理时间是20毫秒,
情况一:
只给1个人用,每秒50个Token。
20毫秒处理50个Token。
情况二:
同时给16个人用,每秒50个Token。
20毫秒处理800个Token。
你看哪个处理量大?
所以,在生成(Decoding)阶段,
箱子越大越好,
越多数量的人用同一个箱子越好。
总之,吞吐的极限越大,推理能力越强。
大模型厂商的技术能力越强。
有关正常人类阅读的常识是:
一个人一秒钟大约只能读完6个Token
(学霸不在讨论范围),
假如系统一秒钟只能生成6个Token,
且只能支持一个客户。
那这个系统的推理性能,真是低到荒谬。
当Token的价格是确定的,
每秒钟生成Token越多赚钱。
假如一个系统可以一秒钟生成60个Token,
那我就可以支持10个正常阅读速度的人类用户。
聊到这里,
基本上把“每秒生成的Token数量
(Tokens per second)”这个指标聊透了。
可以进入下一个话题。

(三)美国厂商靠什么博眼球?
还是这个指标,
每秒生成的Token数量(Tokens per second)。
全球把这个指标打到极致的是一家美国公司,
叫做Groq公司。
要知道,吴恩达老师在推特(X)上点名表扬过。
它的定位是速度快,
而且是全球最快。
这一点非常吸引眼球。
谭老师我只能说,
这是他们自己号称的。
当然,为了证明这个地位,
Groq公司也拿出了相应的推理服务指标:
Mixtral模型 8×7B版本,
每秒输出500个Token;
Llama 2模型的 70B版本,
每秒输出300个Token;
Llama 3模型的8B版本,
每秒输出800个Token;
Falcon的180B模型,
每秒输出173个Token。
这速度真的杠杠的,
然而,光看这些数字,还不够。
更重要的是,Groq公司的很多模型没有定价。
中美价格顺手对比一下,
Llama 3模型的8B版本
输入,3毛5人民币,每百万Token。
输出,7毛钱人民币,每百万Token。
然而这还不够。
当你能把准备(Prefill)
和生成(Decoding)的特点,
彻底分清楚,
就会发现“猫腻”,
或者说,才能发现“猫腻”。
没办法,AI就是这样,
搞不懂,就看不透。
准备(Prefill)
是关于生成第一个Token的时间。
生成(Decoding)
是关于生成其余Token的时间。
我解释一下,
准备阶段就是大模型从喂进去问题到蹦出第一个单词;
英伟达很擅长干这个,
准备这种计算人家有真章。
随后,下一步,进入Decoding阶段。
谭老师我要说“套娃话”了。
每一个新词都要并入计算,以便以得到下一个新词。
从数学角度讲,推理的过程是,
如果进来100个Token,全部都算一遍,
生成第101个Token,
再把这101个Token作为下一轮的输入,
从而,计算出第102个Token,
往后,计算复杂度是平方关系。
打个比方,
写一篇1000字的文章,
写一个字一秒钟,
写完需要1000秒时间(线性复杂度),
但如果你写每个字都要把前面的字再想一遍,
每想一个词,且花一秒。
所需要的时间和字数是平方关系。
这个比方,
谭老师我非常喜欢。
受油管博主bai的启发,
他是一位NLP领域的PHD。
这里要写一些谭老师我的个人理解了。
如果“参数和权重”是箱子,
那KV Cache就是每个给大模型输入问题的用户的手提箱,
对每个用户问的问题不同,
手提箱里装的东西也不同。
好消息是,
由于前面的计算结果是缓存下来的
(KV Cache),
所以,
生成阶段的计算量显然比前一个阶段少了很多。
可惜,KV Cache并不少。
举个例子,
一个模型60GB,
它的KV Cache居然高达180GB。
这有点多。
这就好比,谭老师我解一道题,
写了60页纸,
给教授交作业,就交这些。
其实,演算的草稿纸有180页,
计算过程中,草稿纸要留好,
上面有些中间计算结果,后面还要用到,
不过,你不能连草稿纸一起给教授。
教授说,谢谢,我不搞废纸回收。
可以说,KV Cache的原理,
和它的名字紧密相关。
主要计算三样东西(Q和K和V)。
简单讲,
Q代表每一次计算,
每生成一个新Token。
而K和V计算的是“上下文”。
Q是一次计算得到一个新Token,
而K和V变化很小,
只是把新的放进去而已。
其实,每一个新Token,
对应K矩阵中的一列,
也对应V矩阵的一行。
关键在于,
K和V总要被来回计算,所以重复了。
而一旦我们计算完毕,
新Token生成,所属它的那一行,
那一列存好了,
也不会再变动。
既然不变,搞节约,
就可以从此处入手。
于是,有了“KV Cache”技术。
把这些重复计算的K和V放在什么地方存起来,
用的时候再取,而不是再算。
60GB和180GB这个例子是真实的。
来自Meta公司的OPT模型30B参数版本。
说到底,这就是一个搬箱子和搬手提箱的故事。
同学,醒一醒。
关键的地方快到了,不接着看下去,
就不知道美国公司Groq搞了什么猫腻了。
推理分两部分的本质分别是,
“准备”依赖算力,
“生成”依赖内存和内存带宽,
也就是“搬箱子”。
搬箱子需要时间,
也就是说,缓存(KV Cache)的时间很重要。
为什么?
因为这时候计算的活干得少了,
大部分时间花在 “存”这件事情上,
而存得快慢取决于存的带宽。
于是,带宽大,存得快,
存的时间越短,推理的时间越短。
所以,人们拼命提高内存的带宽。
既然大部分时间花在将模型参数从芯片外内存(HBM)搬到芯片上内存,
那能不能不搬了?
于是,Grog公司就从这个地方入手。
不搬就得存,
存的这个地方可以叫“箱子暂存点”
而一颗芯片上存的地方一般都不大,怎么办?
第一,可以扩大。
第二,把几十片芯片,上百片芯片,
甚至一千片芯片连在一起。
这就是Grog公司的“妙招”。
这样做有缺点。
把准备(Prefill)的时间变长了,
原因是,这么多卡连一起,
只有做数据并行了(Pipeline Parallel)。
这时候,有了一个巧合。
英伟达GPU很擅长Prefill,有多擅长呢?
早在上一个以人脸识别为代表的时期,
Prefill的时间就被英伟达打下来了。
而大语言模型时期,
生成(Decoding)时间远大于准备(Prefill),
渐渐的,
人们就把生成(Decoding)的速度作为推理速度的唯一评判标准了。
Groq公司可能认为,
既然人们把这个作为衡量推理速度的时间标准,
那我就下大功夫去优化它。
然而,
准备(Prefill)在大语言模型时期和之前大为不同。
毕竟当下是自注意力机制,
十分消耗时间,
准备(Prefill)时间很长,
此处,敲黑板。
Groq公司广告逻辑很简单,
单独算Decoding(生成)部分。
让Decoding(生成)的速度=推理速度。
本质上,推理时间,
必须把准备(Prefill)和Decoding(生成)的时间加总,
可不能忽略前者。
好巧不巧,
我拿到了一份美国硅谷工程师给我的数据。
数据来源是,Groq自己公司模型给出的答案,
当输入文本长度3.4K左右,
这个图上,
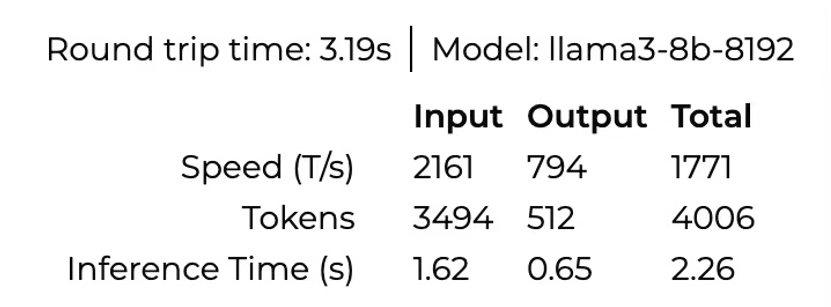
Prefill(Input)的时间,1.62秒。
Decoding(Output)的时间,0.65秒。
总计时间,2.26秒。
输出的速度高达每秒794Tokens。
怪不得外媒盛赞:
《AI 芯片公司Groq的突破性:
LLaMA 3上实现了每秒 800 个Tokens的速度》。

然而,这张图上,清楚地看到,
准备(Prefill)的时间变长了,
这样,Decoding(生成)再快也没用。
为什么说准备(Prefill)的时间变长了?
对比另一家AI芯片公司:
SambaNova。
同样是Llama3模型8B版本,
同样是Prefill阶段的时间,
SambaNova公司的是0.22秒,
而Groq公司的是1.62秒,
生成(Decoding)的时间。
差距如此之大。
这还不够,
再看这张公开的表。

数据来源:
https://sambanova.ai/blog/tokens-per-second-is-not-all-you-need?hs_amp=true
标题:《每秒Token数并不是您所需要的全部》
原来Groq这家芯片公司的“广告”有水分,
且被我发现了。
原来大模型高端商战,
美国公司也钻空子。
速度的故事讲得好,
留给投资人的印象就好。
补充一个“美国湾区老道消息”:
Groq公司现在的芯片是14nm,
他们有可能急切融一笔钱,
来流5nm的芯片。
谭老师我的评价是,
高端商战果然硝烟密布,
中美厂商各有“高招”。
中国厂商卷价格博眼球。
美国厂商卷速度博眼球。
(四)谁赢得利润?
文章接近尾声了,
自始至终都还没聊一个决定性因素:
模型输出结果的质量。
大模型的生成质量在全球范围内竞争,
无论是全国最好,
还是全球最好。
只要某一个厂商的大模型生成质量“遥遥领先”。
那它带动“价格战”的可能性极低。
暗战的背后,
最好是技术上有绝活。
最后,锐评一句:
也许不是“最便宜的赢得商战”,
而是“最能落地的赢得利润”。
(完)

《我看见了风暴:人工智能基建革命》,
作者:谭婧

更多阅读
长文系列
4. 假如你家大模型还是个二傻子,就不用像llya那样操心AI安全
6. 对话百度孙珂:想玩好AI Agent,大模型的“外挂”生意怎么做?
7. 再造一个英伟达?黄仁勋如何看待生物学与AI大模型的未来?
8. 科大讯飞刘聪:假如对大模型算法没把握,错一个东西,三个月就过去了
9.美国AI芯片公司“赢”大模型?Samba-CoE v0.2超过多个业界知名对手
11.如何辨别真假“AI刘强东”?10亿参数,数字人实时生成视频
12.GPT-4o“成精了”:推测技术原理,附送“美国湾区”小道消息
漫画系列

