
热门标签
热门文章
- 1linux系统安装配置_linux nat
- 2mysql集群搭建_MySQL InnoDB cluster 搭建教程
- 3邮箱报错javax.mail.AuthenticationFailedException: 535 Login Fail. Please enter your authorization......
- 4oracle rac一个节点执行语句很慢_浅析ORACLE数据库物理体系结构及其对应优化策略...
- 5Yearning SQL审核平台(只供个人记录,待研究,大家不要点击查看了)
- 6微软TTS延迟因素分析
- 7银河麒麟操作系统 v10 中离线安装 Docker_麒麟v10 安装docker
- 8【2021】荣耀22届校招——一面面经_荣耀面经
- 9深入探索CSS的:local-link伪类:选择指向同一文档的链接
- 10CSA GCR大会正式发布全球首个云渗透测试认证专家课程,腾讯安全获评“特别贡献单位”_云鼎实验室李鑫
当前位置: article > 正文
ChatGLM2-6b的本地部署_chatglm2-6b部署
作者:我家自动化 | 2024-08-19 10:14:45
赞
踩
chatglm2-6b部署
** 大模型玩了一段时间了,一直没有记录,借假期记录下来 **
ChatGlm2介绍:
chatglm2是清华大学发布的中英文双语对话模型,具备强大的问答和对话功能,拥有长达32K的上下文,可以输出比较长的文本。6b的训练参数量为60亿,本地部署大约需要12G以上的显存才能运行起来,但6b提供了一个量化后的int4版本,实测推理仅需要6gb即可。int4版本对于某些老旧的或者不支持int4的GPU而言运行不了,在额外的blog里面会记录如何修改使其运行起来。
硬件需求
要确保自己有超过32G的内存,超过12G的显存且显卡支持float16计算,以及足够的硬盘空间
模型部署
代码下载
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
- 1
- 2
- 3
环境配置
conda create -n torch python=3.10 ipykernel
conda activate torch
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simlple
- 1
- 2
- 3
模型下载
建议使用这样的方式,同时这也解决了国内无法访问huggingface的问题:
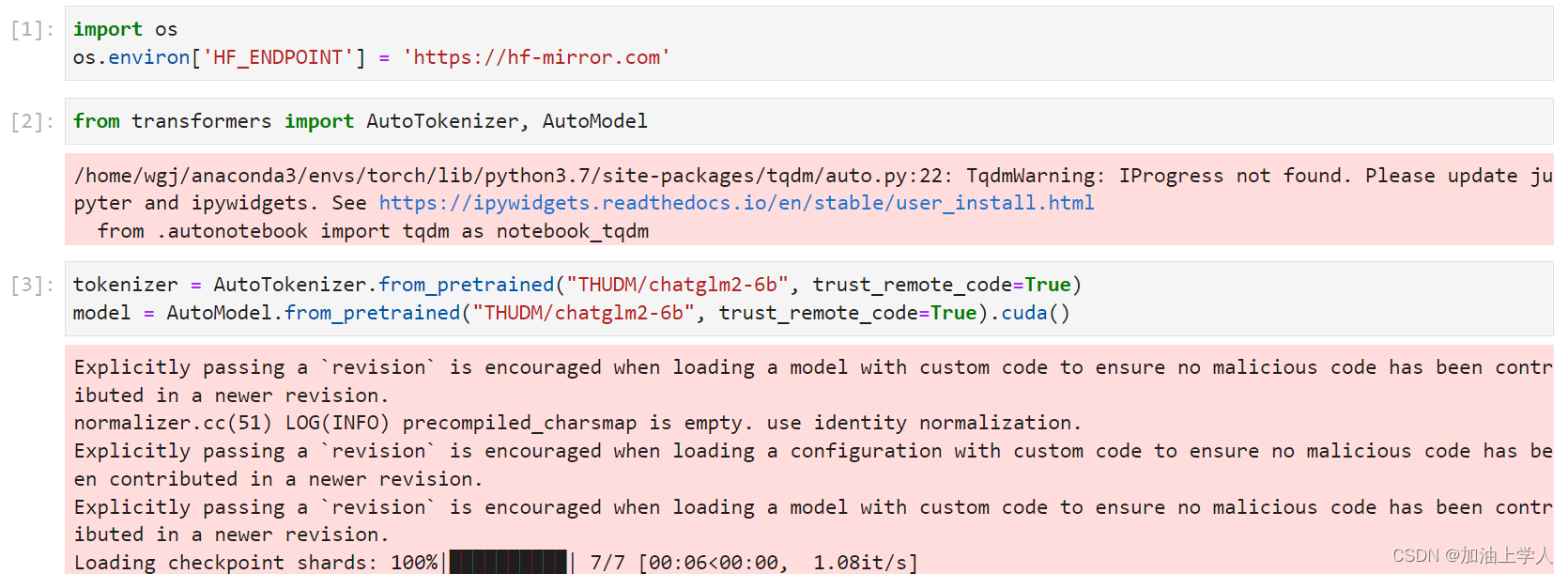
或者直接从清华的数据库进行下载:清华云
如果速度不够快,也可以用paddle,阿里云进行下载,实际测试发现,阿里云下载下来的模型容易出错,慎用。
模型下载下来以后,直接放在文件夹下面即可!
配置GPU
查看设备:
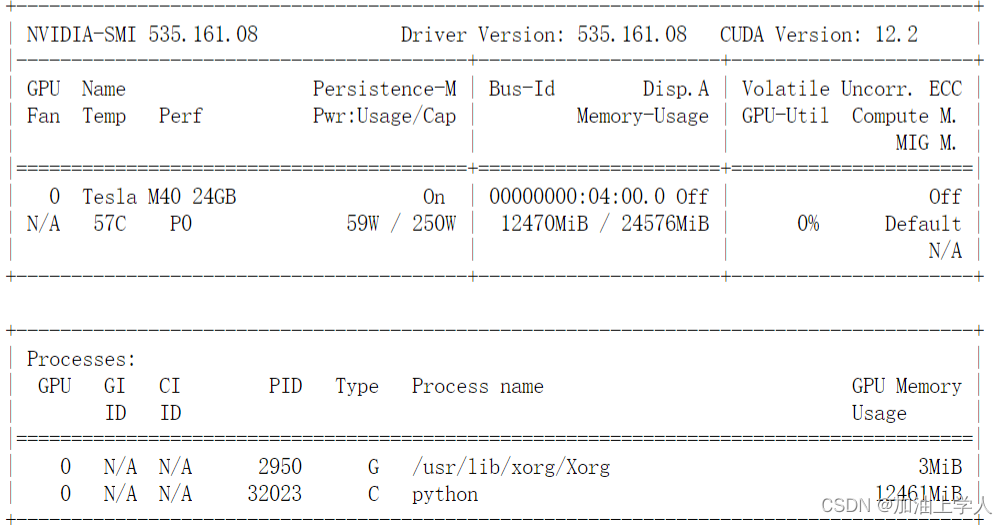
torch2.0以上需要CUDA12以上的支持,故安装一个比较高版本的CUDA即可解决问题,因为CUDA是向下兼容的,即CUDA12.2支持CUDA11.8,同时要选择合适的CUDNN,通常CUDA12.2对应的CUDNN为8.8.0以上。

检查GPU是否可用
import torch
torch.cuda.is_available()
- 1
- 2
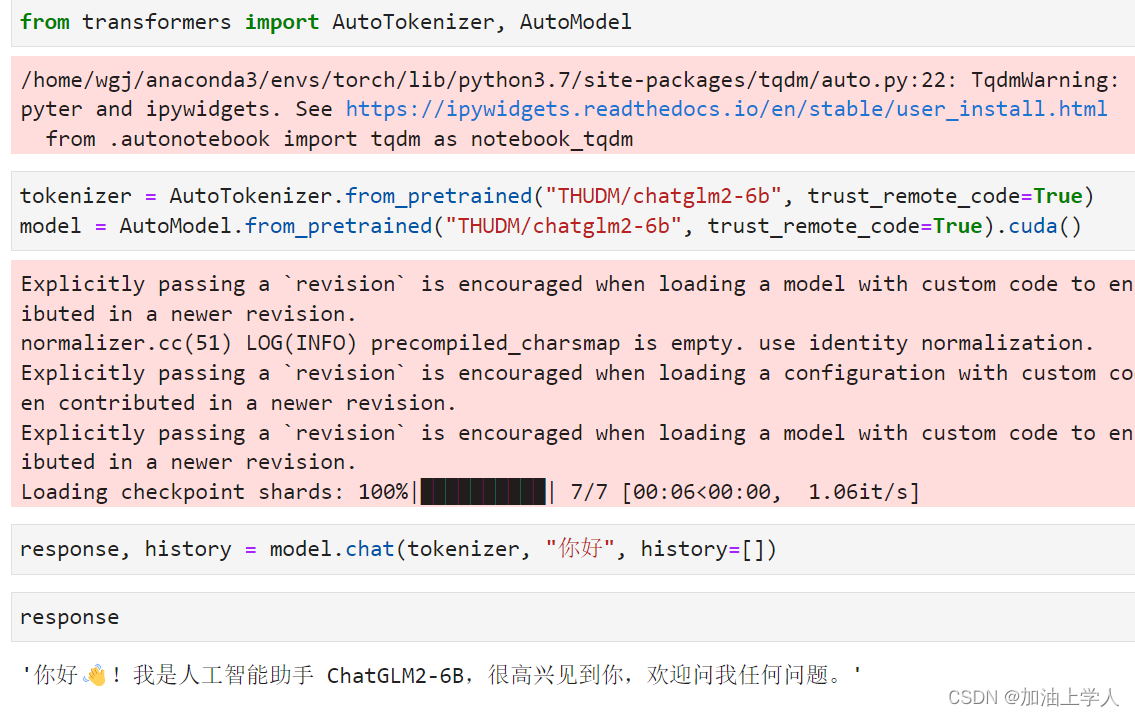
开始本地测试
测试web
如果是在本地电脑上,可以不修改服务器的端口,负责要在lauch中修改server_name为0.0.0.0或所用电脑的ip。

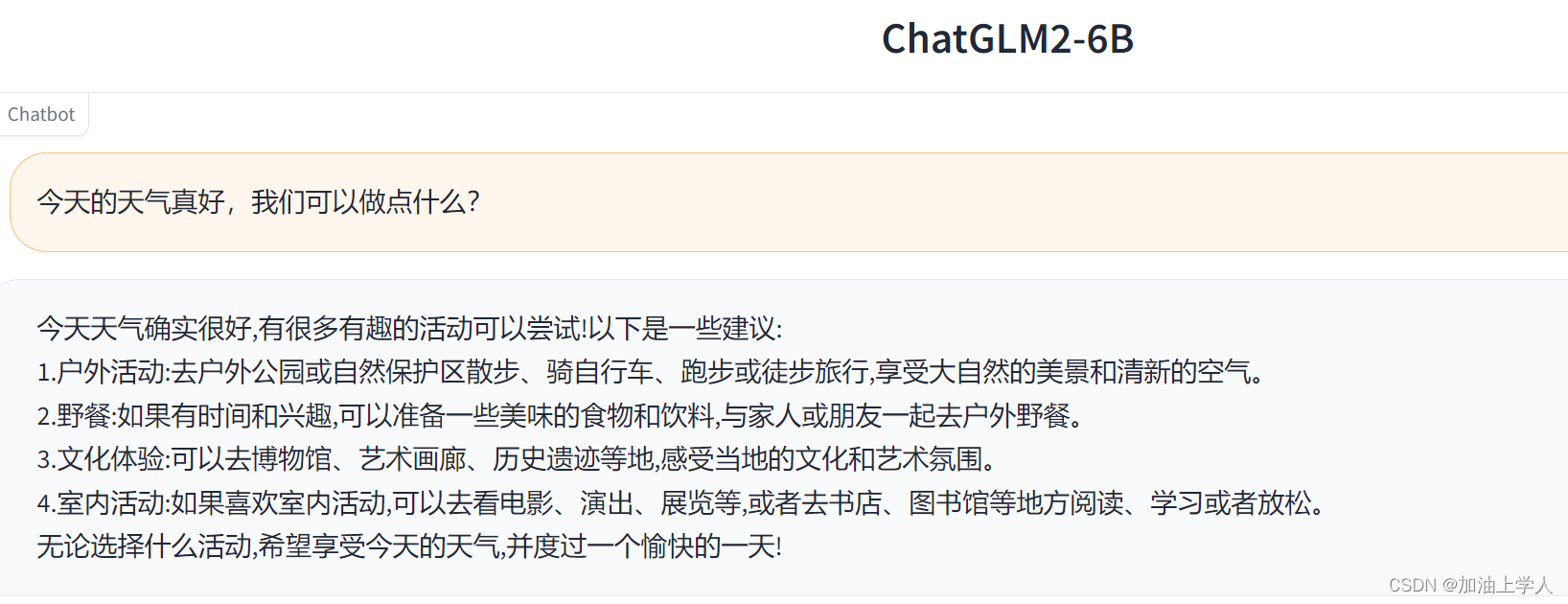
jupyter
至此,本地部署完成。
后期将陆续更新:
如何将int4版本做修改让其跑起来;
如何基于peft做微调;
如何基于prompt做微调
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/1001840
推荐阅读
相关标签

