
- 1ElasticSearch:处理数据的关联关系 nested 父子文档_nested对象 列表 关联性
- 2Flink窗口全解析:三种时间窗口、窗口处理函数使用及案例_tumblingprocessingtimewindows
- 3如何本地部署虚VideoReTalking
- 4Flink 检查点(checkpoint)
- 5数据结构初阶——算法复杂度超详解_时间复杂度 空间复杂度
- 6[嵌入式系统-53]:嵌入式系统集成开发环境大全 ( IAR Embedded Workbench(通用)、MDK(ARM)比较 )
- 7NLP-深度学习和神经网络_nlp是神经网络吗
- 8linux 网关怎么配置,linux服务器怎么配置网关
- 9Redission 解锁unlock异常:attempt to unlock lock, not locked by current thread by node id的解决方案
- 10git连接gitee远程仓库及使用_git远程仓库怎么引入,2024年最新程序员面试题网站_git链接gitee
SpringCloud+Python 混合微服务,如何打造AI分布式业务应用的技术底层?_springcloud集成python
赞
踩
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型架构师。
目前,他管理了10人左右的团队,包括一个2-3人的python算法小分队,包括一个3-4人Java应用开发小分队,包括一个2-3人实施运维小分队。并且他们的产品也收到了丰厚的经济回报, 他们的AIGC大模型产品,好像已经实施了不下10家的大中型企业客户。
当然,尼恩更关注的,主要还是他的个人的职业身价。
小伙伴反馈,不到一年,他现在是人才市场的香馍馍。怎么说呢?
他现在职业机会不知道有多少, 而是大部分都是P8+ (年薪200W+)的顶级机会。
回想一下,去年小伙伴来找尼恩的时候, 可谓是 令人唏嘘。
当时,小伙伴被网易裁员, 自己折腾 2个月,没什么好的offer, 才找尼恩求助。
当时,小伙伴其实并没有做过的大模型架构, 仅仅具备一些 通用架构( JAVA 架构、K8S云原生架构) 能力,而且这些能力还没有完全成型。
特别说明,他当时 没有做过大模型的架构,对大模型架构是一片空白。
本来,尼恩是规划指导小伙做通用架构师的( JAVA 架构、K8S云原生架构),
毫无疑问,大模型架构师更有钱途,所以, 当时候尼恩也是 壮着胆子, 死马当作活马指导他改造为 大模型架构师。
回忆起当时决策的出发点,主要有3个:
(1)架构思想和体系,本身和语言无关,和业务也关系不大,都是通的。
(2)小伙伴本身也熟悉一点点深度学习,懂python,懂点深度学习的框架,至少,demo能跑起来。
(3)大模型架构师稀缺,反正面试官也不是太懂 大模型架构。
基于这个3个原因,尼恩大胆的决策,指导他往大模型架构走,先改造简历,然后去面试大模型的工程架构师,特别注意,这个小伙伴面的不是大模型算法架构师。
没想到,由于尼恩的大胆指导, 小伙伴成了。
没想到,由于尼恩的大胆指导, 小伙伴成了, 而且是大成,实现了真正的逆天改命。
相当于他不到1年时间, 职业身价翻了1倍多,可以拿到年薪 200W的offer了。
既然有一个这么成功的案例,尼恩能想到的,就是希望能帮助更多的社群小伙伴, 成长为大模型架构师,也去逆天改命。
于是,从2024年的4月份开始,尼恩开始写 《LLM大模型学习圣经》,帮助大家穿透大模型,走向大模型之路。

尼恩架构团队的大模型《LLM大模型学习圣经》是一个系列,初步的规划包括下面的内容:
- 《LLM大模型学习圣经:从0到1吃透Transformer技术底座》
- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《SpringCloud + Python 混合微服务架构,打造AI分布式业务应用的技术底层》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
本文是第3篇,第一作者是资深架构师Andy,第二作者是43岁老架构师尼恩(带给大家一种俯视技术,技术自由的高度)。
尼恩架构团队会持续迭代和更新,后面会有实战篇,架构篇等等出来。 并且录制配套视频。
在尼恩的架构师哲学中,开宗明义:架构和语言无关,架构的思想和模式,本就是想通的。
架构思想和体系,本身和语言无关,和业务也关系不大,都是通的。
所以,尼恩用自己的架构内功,以及20年时间积累的架构洪荒之力,通过《LLM大模型学习圣经》,给大家做一下系统化、体系化的LLM梳理,使得大家内力猛增,成为大模型架构师,然后实现”offer直提”, 逆天改命。
尼恩 《LLM大模型学习圣经》PDF 系列文档,会延续尼恩的一贯风格,会持续迭代,持续升级。
这个文档将成为大家 学习大模型的杀手锏, 此文当最新PDF版本,可以来《技术自由圈》公号获取。
SpringCloud + Python 混合微服务的使用场景
从尼恩社群指导简历的情况来看, 在AI+业务的场景越来越多
-
懂 大模型 工程的 占优势,比较好拿offer
-
懂 小模型 工程的 占优势,比较好拿offer
但是,大家在生产场景中,SpringCloud 有一个完整的业务开发生态体系,Python 有一个完整的AI开发生态体系, 就是如何将Python写的微服务融入到以Spring Cloud微服务体系中?
换句话说,在AI+业务的场景,不仅仅需要Python写一个微服务,并且还要融入以Java技术栈为主的Spring Cloud微服务体系中,如何实现?
或者说,如何实现一个 SpringCloud + Python 混合微服务架构?
一般来说,后端软件系统采用的也是基于Spring Cloud框架为主的微服务架构,服务的注册发现是基于Nacos,而服务的调用基于OpenFeign调用,负载均衡Robbin实现的,所以整体架构大概就是这样的一个标准Spring Cloud微服务架构。
如图所示:
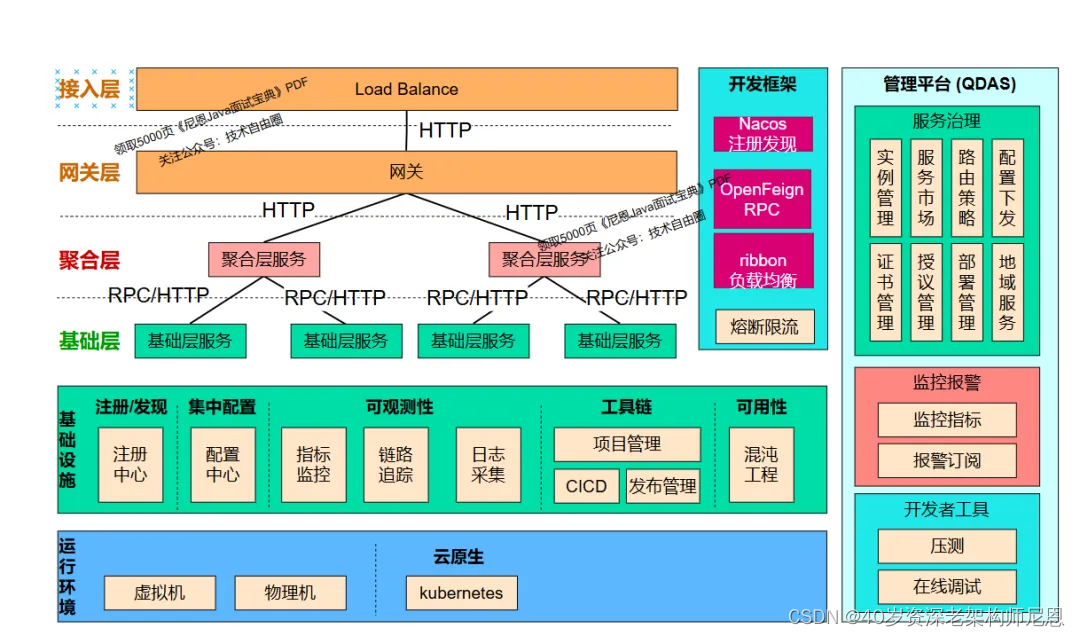
上面的图太大, Java 微服务直接的RPC,大概是下面的调用关系
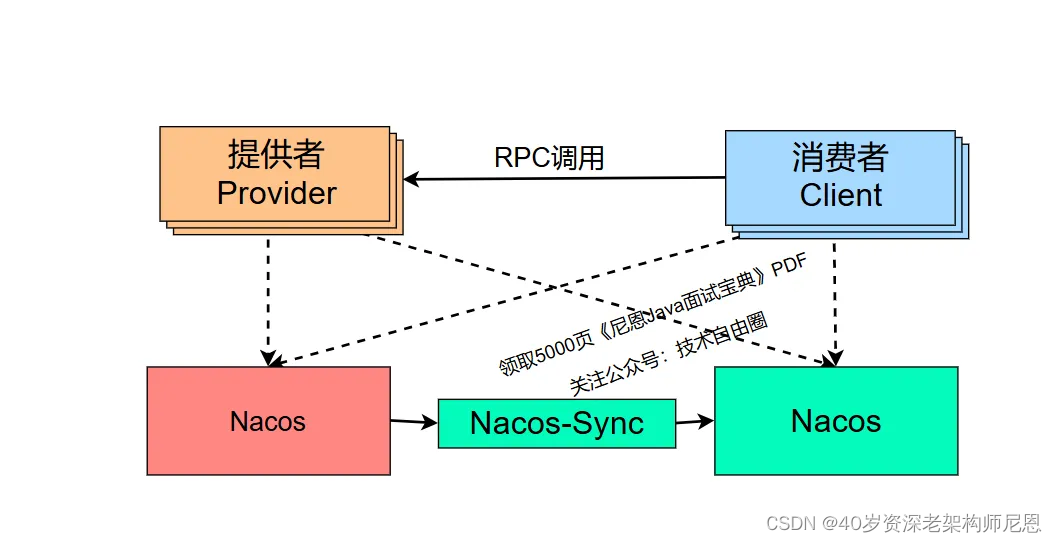
大部分场景,基于以上微服务架构是比较好扩展的。
例如有一个新的微服务,只需要基于Spring Boot编写一个微服务项目,然后通过Spring Cloud提供的注解将其快速地注入Nacos的服务注册&发现机制,然后就可以很快地对内或对外提供服务了。
然后,如果是 在AI+业务的场景呢?
AI应用,比如图形识别,比如翻译,比如AIGC(文生文、文生图)等等。 这些应用,用Java开发的话很不方便,更佳的方式是使用Python开发,因为: Python 有一个完整的AI开发生态体系。
那么,就意味着Python 微服务需要 混入 Spring Cloud 微服务体系,否则,需要对于Python服务做单独的部署及负载设计、服务治理设计等等大量重复性的工作。
Java+python 的rpc 基础调用的视频介绍,请参考后面的 《技术自由圈 专门的AI架构视频》
SpringCloud + Python 混合微服务,如何架构?
SpringCloud + Python 混合微服务,如何架构?
一种切实可行的方式是:
- 将Python写的异构服务也能不融入Spring Cloud体系,能够通过Nacos实现注册发现
- 能够通过OpenFeign/gRpc进行远程调用,能够使用Ribbo进行负载均衡
如下图所示:
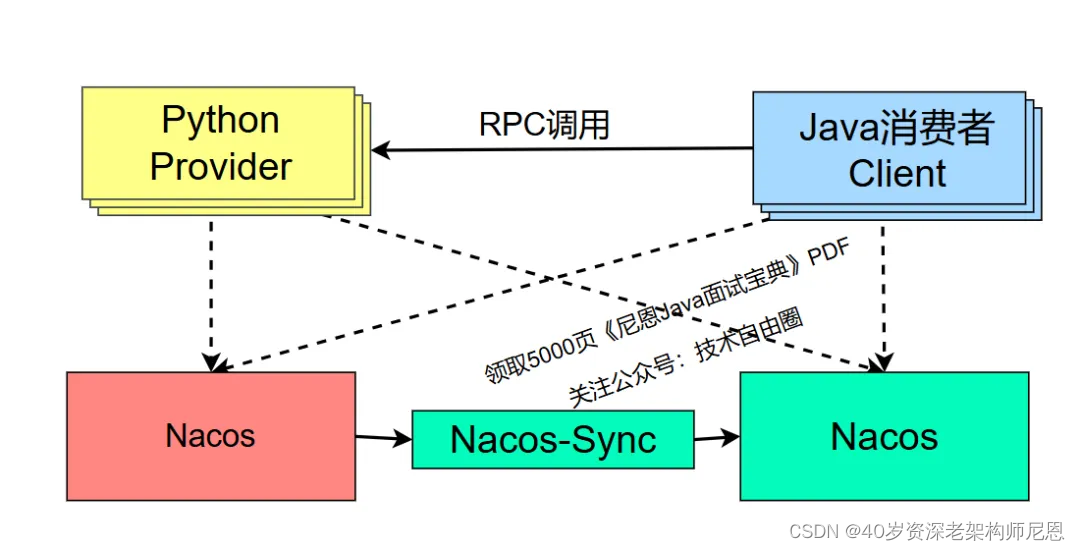
Java+python 的rpc 基础调用的视频介绍,请参考后面的 《技术自由圈 专门的AI架构视频》
SpringCloud + Python 混合微服务架构实操
实操场景介绍
这里,通过Python 图像识别与文本提取(OCR) 业务为例,实现一个 SpringCloud + Python 混合微服务架构实操。
在日常的开发中,图像识别与文本提取(OCR)技术扮演着至关重要的角色,它们极大地促进了业务流程的自动化,提升了用户体验。特别是在互联网和金融行业,这一需求尤为显著。
一般来说,图像识别与文本提取(OCR)都是通过python实现。
并且在Python生态中,有一个OCR的明星库——PaddleOCR。
PaddleOCR以其在OCR领域的高性能和高精度著称,似乎是解决这一挑战的理想工具。
PaddleOCR是由百度飞桨(PaddlePaddle)团队开发的开源OCR(Optical Character Recognition,光学字符识别)工具。
它基于深度学习技术,提供了一整套高效、易用的OCR解决方案,能够识别多种语言和复杂场景下的文本。
PaddleOCR在处理文字检测和文字识别方面具有高性能和高准确性,被广泛应用于图像处理、文本提取等领域。
PaddleOCR的关键特性
- 高精度:
- 基于深度学习模型,PaddleOCR在各种复杂场景下均能提供高精度的文字识别,包括自然场景文本、印刷文本、手写文本等。
- 多语言支持:
- PaddleOCR支持多种语言的文字识别,适用于全球范围内的多语言文本处理需求。
- 丰富的功能:
- PaddleOCR不仅提供了文字检测(识别文本区域)和文字识别(识别文本内容),还包括文字方向分类、表格识别、版面分析等高级功能。
- 易用性:
- 提供了丰富的API接口和详细的文档,方便开发者快速集成和使用。
- 高效性:
- 利用飞桨(PaddlePaddle)深度学习框架的高效计算能力,PaddleOCR能够在保证精度的前提下提供快速的文字识别服务。
然而,随着项目的深入实施,一系列预料之外的难题逐渐浮现,揭示了直接在Java微服务中集成AI模型面临的困境。
传统的 SpringCloud + Python 本地直接调用的不足
在使用微服务架构之前,传统的 SpringCloud + Python 互相调用,使用的是 本地直接调用的方式,
原始本地直接调用的架构设计如下:
1.本地直接调用流程:
- 用户通过前端上传图片到Java微服务。
- Java微服务接收到图片后,通过本地进程调用Python脚本来处理图片。
- Python脚本利用PaddleOCR库进行OCR处理,将结果返回给Java微服务。
- Java微服务接收OCR结果,并将其返回给用户或存入数据库。
- 本地直接具体实现:
- 在Java代码中,使用
ProcessBuilder或Runtime.exec执行Python脚本。 - Python脚本通过命令行参数或读取临时文件的方式获取图像数据。
- OCR结果通过标准输出返回给Java微服务,Java读取标准输出获取结果。
本地直接设计存在以下几个主要问题:
- 语言跨界调用复杂性:
- Java微服务直接调用本地Python脚本执行PaddleOCR,这要求在Java环境中嵌入Python解释器或通过进程间通信(如使用Jython或子进程调用),增加了系统的维护成本和运行时的不稳定因素。
- 硬件依赖限制:
- PaddleOCR为了达到最佳性能,推荐使用GPU进行模型推理。这意味着部署环境必须配备NVIDIA GPU,限制了服务的部署灵活性和成本控制。
- 耦合度高与扩展性差:
- Java服务直接绑定到本地Python脚本,这种紧耦合设计不仅难以适应未来技术栈的变化,也影响了服务的独立升级和横向扩展能力。
- 配置与管理难题:
- 随着服务规模的扩大,对服务实例的监控、配置更新和故障转移变得愈发困难,原始设计缺乏有效的服务治理机制。
针对以上问题,我们对此进行了改进:SpringCloud + Python 远程调用的架构方案
先进的 SpringCloud + Python 远程调用的架构方案
为了解决上述问题,我们提出了一个新的架构设计方案,SpringCloud + Python 统一微服务治理+RPC远程调用的架构方案,主要有以下3步
-
第一步,AI的微服务化:利用FastAPI构建轻量级Python后端服务,专门负责OCR处理,
-
第二步,通过Nacos注册发现:并结合Python-Nacos客户端SDK实现服务的注册发现及动态配置管理。
-
第三步,通过RPC进行远程调用:通过OpenFein/gPRC进行远程调用
Java+python 的rpc 基础调用的视频介绍,请参考后面的 《技术自由圈 专门的AI架构视频》
SpringCloud + Python混合微服务架构设计及步骤
第一步:AI的微服务化
FastAPI服务封装 OCR处理,暴露成为rest服务, 以服务的形式进行能力的暴露,而不是以 函数的形式进行能力的暴露。
创建FastAPI应用:

FastAPI是一个现代的,快速(高性能)python web框架。基于标准的python类型提示,使用python3.6+构建API的Web框架。
FastAPI的主要特点如下:
-
快速:非常高的性能,与NodeJS和Go相当(这个要感谢Starlette和Pydantic),是最快的Python框架之一。
-
快速编码:将开发速度提高约200%到300%。
-
更少的bug:减少大约40%的开发人员人为引起的错误。
-
直观:强大的编辑器支持,调试时间更短。
-
简单:易于使用和学习。减少阅读文档的时间。
-
代码简洁:尽量减少代码重复。每个参数可以声明多个功能,减少程序的bug。
-
健壮:生产代码会自动生成交互式文档。
-
基于标准:基于并完全兼容API的开放标准:OpenAPI和JSON模式。
总之,FastAPI是一个现代、快速(高性能)的Web框架,用于基于Python 3.7+构建API,借助标准Python类型提示,FastAPI可以提供自动文档生成、高性能和易于使用的开发体验。
FastAPI以极简的代码实现高效的API接口,非常适合构建RESTful API和微服务。
首先,利用FastAPI快速搭建一个RESTful API服务,该服务对外提供API接口,接收HTTP请求,其中包含待处理的图片数据路径。
集成PaddleOCR:在FastAPI应用中,定义路由处理函数,调用PaddleOCR库处理接收到的图片数据,将识别结果以JSON格式返回。
Java+python 的rpc 基础调用的视频介绍,请参考后面的 《技术自由圈 专门的AI架构视频》
第二步:通过Nacos服务注册与发现:
引入Python-Nacos客户端:Nacos作为阿里巴巴开源的服务发现与配置管理平台,提供了Python客户端。在FastAPI应用中集成该客户端,实现服务的自动注册与发现。
配置管理:利用Nacos的配置中心,集中管理FastAPI服务的配置信息,如OCR模型参数等,实现配置的动态刷新,无需重启服务即可生效。
第三步:通过RPC进行远程调用
调整Java服务逻辑,改为通过Nacos注册中心发现在线AI服务,
通过 OpenFeign 发起HTTP请求调用FastAPI提供的OCR服务,彻底解耦Java微服务与AI模型环境,增强系统的灵活性和可维护性。
改进后的架构优点如下:
- 松耦合架构: Java微服务与OCR服务通过API接口交互,降低了组件间的直接依赖,便于独立开发、测试和部署。
- 部署灵活性: FastAPI服务可部署在任何支持Python的环境中,包括云服务器,不再受限于GPU,可通过水平扩展提高处理能力。
- 服务治理能力增强: 借助Nacos,实现了服务的自动化注册与发现,简化了微服务架构下的服务管理和配置管理,提高了系统的稳定性和可扩展性。
- 资源优化与成本控制: 通过分离OCR处理逻辑,可以根据实际需求灵活分配计算资源,有效控制成本。
代码实现
接下来我们将深入实践,通过细致的代码示例与步骤解析,展现如何巧妙地构建JAVA微服务与AI模型服务之间的无缝集成。
不再是简单的理论探讨,而是动手操作,从零开始,直到完成一个功能完备、高度解耦的系统集成方案。
环境安装
在开始代码编写前,我们需要准备好运行环境,java和maven的安装就不在此介绍了,我们简单介绍下如何准备python环境以及nacos。
Python虚拟环境
本文采用anaonda配置虚拟环境,
-
Anaconda是一个开源的Python和R编程语言的发行版,用于数据科学、机器学习、深度学习、科学计算以及大数据处理。
-
Anaconda包含了众多流行的数据科学包和工具,以及一个包管理系统和环境管理系统。
-
Anaconda可以帮助开发者轻松地管理和部署不同的项目环境,并解决包依赖问题。
Anaconda是一种广泛使用的开源Python和R编程语言的发行版,主要用于数据科学、机器学习和大数据处理。Anaconda包含了众多常用的数据科学包和库,并提供了一个包管理器和环境管理器(Conda),这使得用户可以轻松地安装、更新和管理Python包及其依赖项。
安装Anaconda
下载Anaconda:
访问 Anaconda官网 并下载适合你操作系统的安装程序(Windows、macOS或Linux)。
ananconda的安装和配置建议参考清华源:
anaconda | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
安装Anaconda:
根据下载的安装程序运行安装,按照提示完成安装过程。
可以选择将Anaconda添加到系统PATH中,这样可以直接在命令行中使用conda命令。
WIN+R键调出运行窗口,输入cmd回车
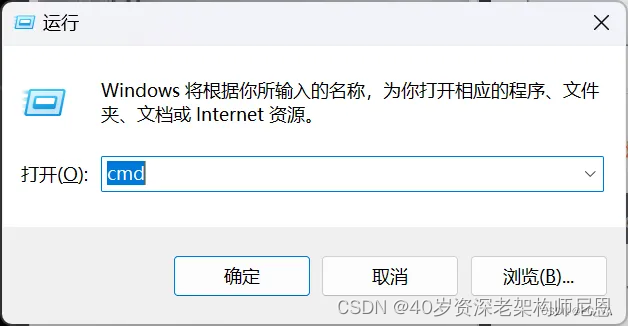
输入conda -V命令,可以看到版本信息,代表安装成功。
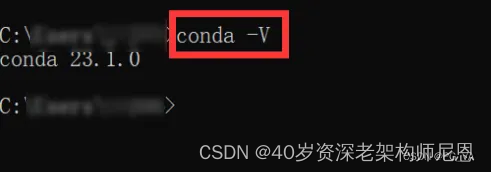
接着,输入python命令查看python是否安装成功。
到此安装完成。
使用Anaconda
创建和管理环境
Anaconda通过Conda提供了强大的环境管理功能,使得用户可以为不同的项目创建隔离的环境,以避免包版本冲突。
-
创建新环境:
conda create --name myenv python=3.8- 1
这将创建一个名为
myenv的环境,并安装Python 3.8。 -
激活环境:
conda activate myenv- 1
激活后,所有的包管理操作都会在这个环境中进行。
-
安装依赖包:
conda install numpy pandas- 1
这将在当前激活的环境中安装
numpy和pandas包。 -
列出环境:
conda env list- 1
这将列出所有创建的Conda环境。
-
删除环境:
conda remove --name myenv --all- 1
这将删除名为
myenv的环境。
使用Jupyter Notebook
Anaconda默认包含Jupyter Notebook,一个广泛使用的交互式笔记本工具,特别适合于数据科学和机器学习项目。
-
安装Jupyter Notebook(如果未安装):
conda install jupyter- 1
-
启动Jupyter Notebook:
jupyter notebook- 1
这将启动Jupyter Notebook服务器,并在浏览器中打开一个新的标签页。
管理包
除了Conda,Anaconda也支持使用pip来安装Python包。
以下是一些常见的包管理操作:
-
使用Conda安装包:
conda install scipy- 1
-
使用pip安装包:
pip install requests- 1
-
更新包:
conda update numpy- 1
-
卸载包:
conda remove pandas- 1
第一步:使用Anaconda进行Python微服务的开发
数据科学项目
-
创建项目环境:
conda create --name myproject python=3.8 conda activate myproject- 1
- 2
-
安装数据科学包:
conda install numpy pandas scikit-learn matplotlib seaborn- 1
-
启动Jupyter Notebook进行数据分析:
jupyter notebook- 1
机器学习项目
-
创建项目环境并安装机器学习包:
conda create --name mlproject python=3.8 conda activate mlproject conda install scikit-learn tensorflow keras- 1
- 2
- 3
-
开始开发机器学习模型:
可以在Jupyter Notebook中编写和运行代码,或者使用任意Python IDE进行开发。
Anaconda 安装PaddleOCR
Anaconda通过其强大的包管理和环境管理功能,为数据科学和机器学习项目提供了一个便捷的开发平台。
无论是安装包、管理环境,还是使用Jupyter Notebook进行交互式编程,Anaconda都能大大简化工作流程,提高工作效率。
安装完成后,就可以创建虚拟环境及安装依赖库了。
创建项目环境 paddle_env:
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- 1
- 2
- 3
激活项目环境 paddle_env:
conda activate paddle_env
- 1
- 2
- 3
- 4
安装依赖包
pip install paddlepaddle paddleocr fastapi uvicorn python-nacos
- 1
Nacos
Nacos(Dynamic Naming and Configuration Service)是阿里巴巴开源的一个服务发现、配置管理和服务治理平台。它能够帮助开发者更高效地构建、管理和维护微服务架构。
Nacos提供了一整套简便易用的工具和API,用于服务注册与发现、动态配置管理、服务健康监测以及DNS服务。
安装及配置建议参考官方文档,
Nacos 快速开始
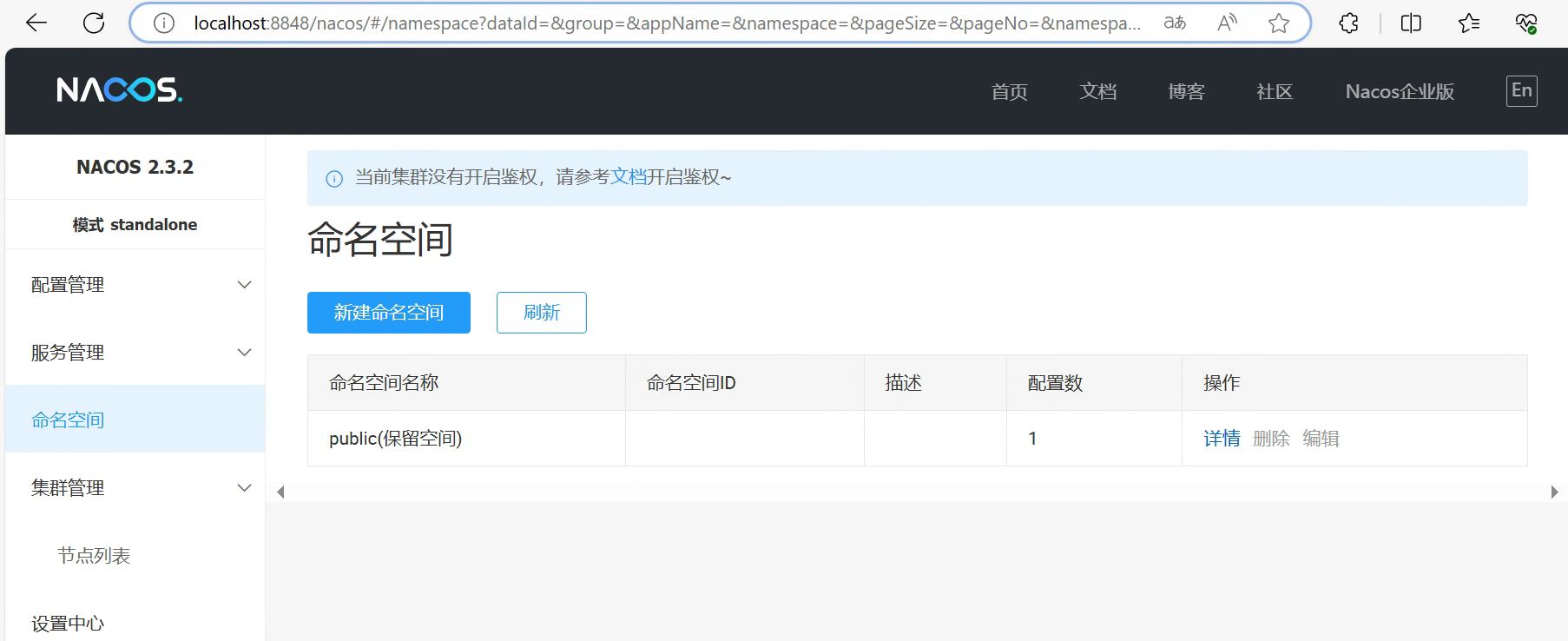
下载安装包后,解压缩,在bin目录下下运行以下命令:
startup.cmd -m standalone
- 1
启动后,既可打开nacos管理页面
示例:图文识别的AI服务
我们要创建一个名为ocr-service 的AI服务,下面是整体的目录结构:

Java+python 的rpc 基础调用的视频介绍,请参考后面的 《技术自由圈 专门的AI架构视频》
首先编写基础模块,
- settings.py: 初始化相关配置参数及更新方法:
# settings.py import socket def get_local_ip(): """ 获取当前计算机的IP地址 """ return socket.gethostbyname(socket.gethostname()) # 服务端口 SERVICE_PORT = 8000 SERVICE_IP = get_local_ip() # 服务名 SERVICE_NAME = "ocr-service" # Nacos 配置 NACOS_SERVER_ADDRESS = "127.0.0.1:8848" NACOS_NAMESPACE = "public" NACOS_DATA_ID = "ocr-service" NACOS_USERNAME = "nacos" NACOS_PASSWORD = "nacos" NACOS_GROUP_NAME = "DEFAULT_GROUP" # 语言属性 LANG = "ch" # 例如:中文 def set_lang(new_lang): """ 设置OCR模型语言属性 :param new_lang: 新的语言属性 """ print("设置OCR模型语言属性为:", new_lang) global LANG LANG = new_lang

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- nacos_client.py: 初始化nacos client ,以及相关的注册、心跳及监听配置等方法。
import nacos import asyncio import yaml import app.settings as settings # 初始化 Nacos 客户端 # 使用settings中的NACOS_SERVER_ADDRESS, NACOS_NAMESPACE, NACOS_USERNAME, NACOS_PASSWORD来初始化Nacos客户端 client = nacos.NacosClient(settings.NACOS_SERVER_ADDRESS, namespace=settings.NACOS_NAMESPACE, username=settings.NACOS_USERNAME, password=settings.NACOS_PASSWORD) def register_service(): # 向Nacos注册服务实例 client.add_naming_instance( settings.SERVICE_NAME, settings.SERVICE_IP, settings.SERVICE_PORT) async def send_heartbeat(): # 异步发送心跳,每10秒发送一次心跳 while True: try: client.send_heartbeat(settings.SERVICE_NAME, settings.SERVICE_IP, settings.SERVICE_PORT) except Exception as e: print(f"Failed to send heartbeat: {e}") await asyncio.sleep(10) # 每10秒发送一次心跳 def load_config(content): # 加载配置文件,解析yaml格式,设置语言 yaml_config = yaml.full_load(content) print("yaml_config:", yaml_config) lang = yaml_config['lang'] settings.set_lang(lang) def nacos_config_callback(args): # Nacos配置回调函数,处理配置更新 content = args['raw_content'] load_config(content) def watch_config(): # 启动时,强制同步一次配置 config = client.get_config(settings.NACOS_DATA_ID, settings.NACOS_GROUP_NAME) print("config:", config) load_config(config) # 启动监听器,监控配置变化 client.add_config_watcher(settings.NACOS_DATA_ID, settings.NACOS_GROUP_NAME, nacos_config_callback)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- pocr.py : 提供根据图片地址,提取对应图片的文本信息方法。
import os import sys from paddleocr import PaddleOCR import app.settings as settings def recognize_image_text(image_path): # 初始化PaddleOCR对象,加载预训练模型 ocr = PaddleOCR(use_angle_cls=True, lang=settings.LANG) # 更改lang参数以支持不同语言 # 加载图片并进行识别 result = ocr.ocr(image_path) print(result) # 提取并格式化识别出的文本 recognized_text = '' for line in result: # 每个line是一个包含坐标信息和文字识别结果的元组列表 for item in line: recognized_text += item[1][0] + '\n' # 提取文字内容 # 去除末尾的换行符(如果存在) if recognized_text.endswith('\n'): recognized_text = recognized_text[:-1] return recognized_text if __name__ == "__main__": # 输入图片路径 image_path = sys.argv[1] # 提取图片中的文字 output_text = recognize_image_text(image_path) print("Recognized text:", output_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- routes.py: 创建API路由对象,提供接口访问ocr方法。
from fastapi import APIRouter, HTTPException import os from pydantic import BaseModel from pocr.pocr import recognize_image_text # 定义请求体模型 # 创建一个请求体模型,用于接收文件路径 class FilePathModel(BaseModel): filePath: str # 创建路由 # 创建一个API路由对象 router = APIRouter() # 定义一个异步函数,用于处理POST请求,接收文件路径并识别图片中的文本信息 @router.post("/ocr/") async def print_file_path(file_path_model: FilePathModel): filePath = file_path_model.filePath if not os.path.exists(filePath): raise HTTPException(status_code=400, detail="File path does not exist") print(f"Received file path: {filePath}") text = recognize_image_text(filePath) return {"message": text}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- main.py
from fastapi import FastAPI # 导入 FastAPI 框架 import uvicorn # 导入 uvicorn 用于运行 ASGI 应用 import asyncio # 异步编程库 from app.nacos_client import register_service, send_heartbeat, watch_config # 从 app.nacos_client 模块导入注册服务、发送心跳和监听配置的函数 from app.routes import router # 从 app.routes 模块导入路由 import app.settings as settings # 导入 app.settings 模块,并重命名为 settings # 创建 FastAPI 应用 app = FastAPI() # 注册路由 app.include_router(router) # 当应用启动时执行的事件 @app.on_event("startup") async def startup_event(): register_service() # 调用注册服务函数 watch_config() # 调用监听配置函数 # 启动心跳任务 asyncio.create_task(send_heartbeat()) # 创建异步任务发送心跳 if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=settings.SERVICE_PORT) # 运行应用,监听指定端口
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
代码编写完成后,我们还需要在nacos配置中心,创建配置文件:
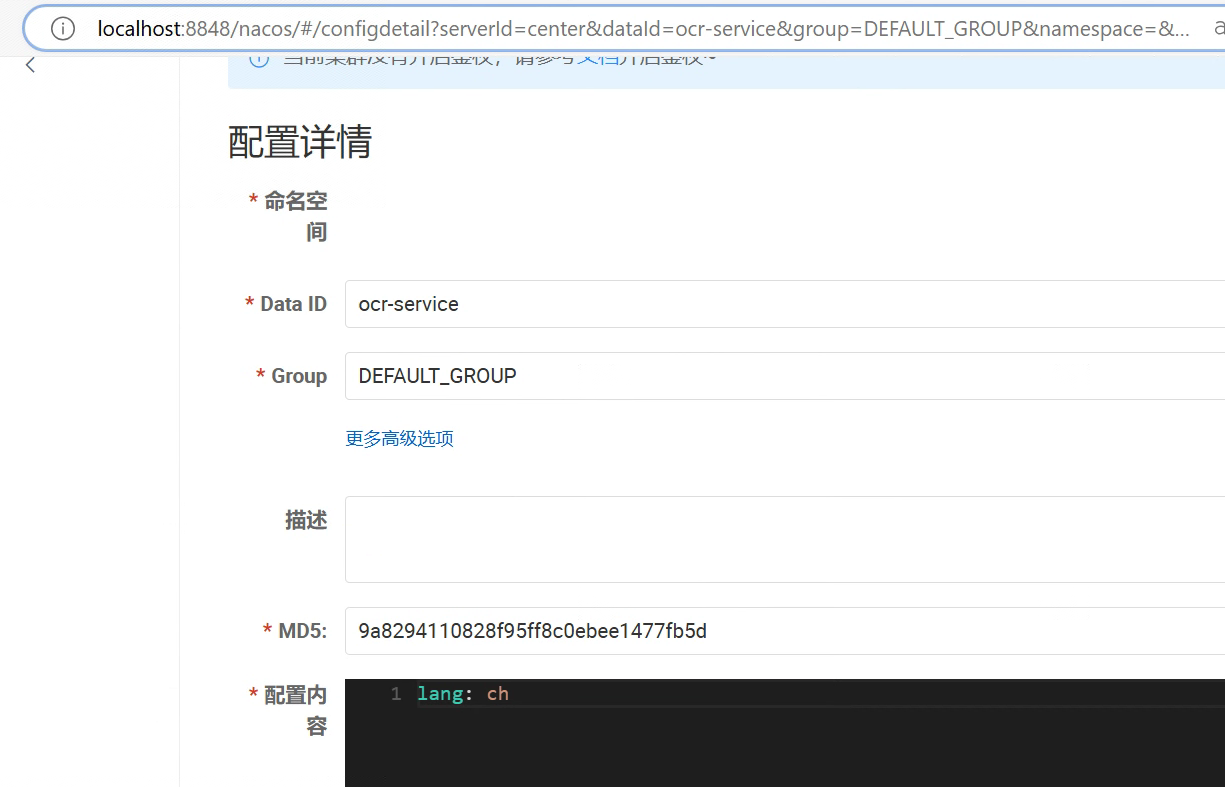
启动项目:
(paddle_env) PS D:\doc\crazy\nacos\ocr-servic& D:/portable/anaconda/envs/paddle_env/python.exe d:/doc/crazy/nacos/ocr-service/main.py
INFO: Started server process [20328]
INFO: Waiting for application startup.
config: lang: ch
yaml_config: {'lang': 'ch'}
设置OCR模型语言属性为: ch
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
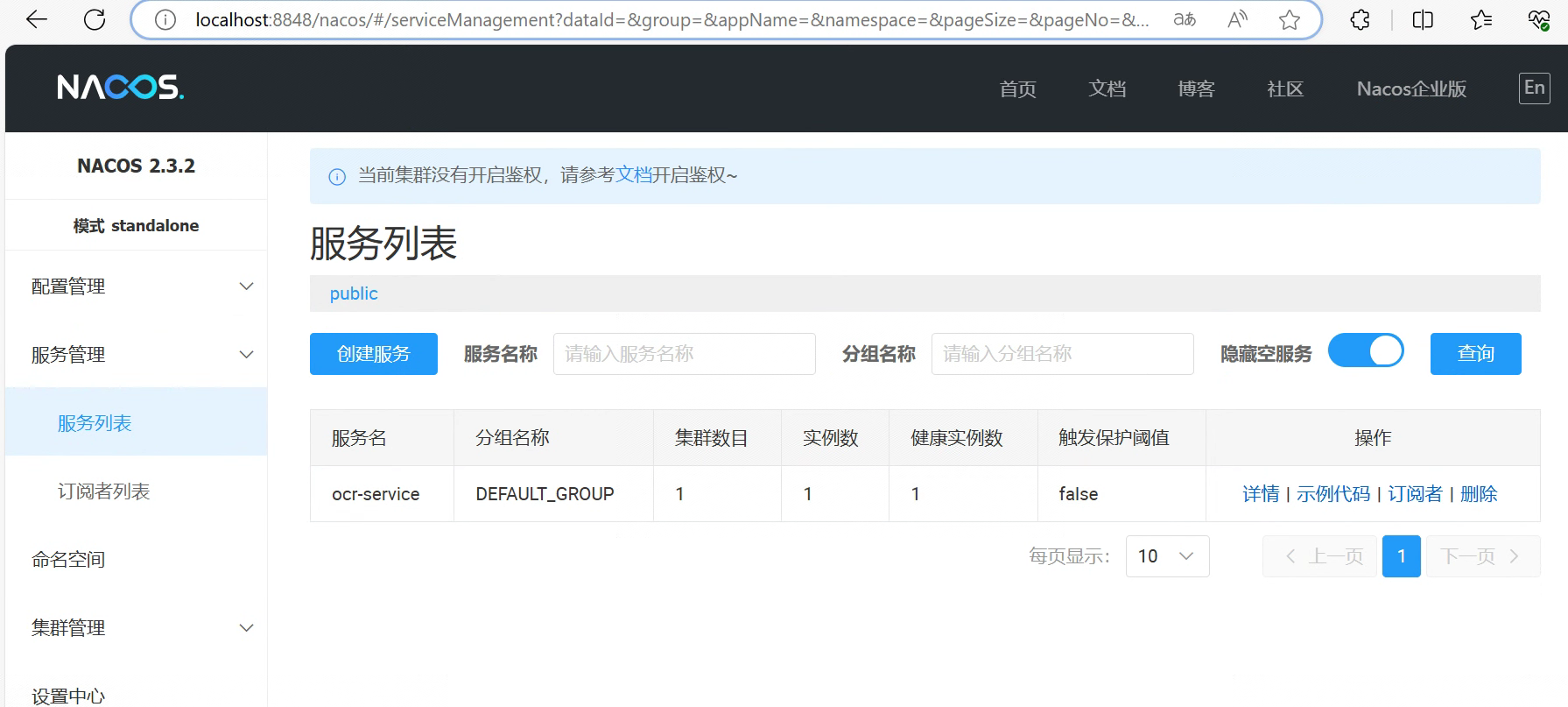
从启动日志可以看到,服务启动时会从nacos读取配置,并更新对应的lang值。
启动后,在nacos管理页面可以看到服务已经注册成功:
准备一张包含文字的图片demo.jpg,放在D盘下,在终端使用curl命令调用服务的接口:
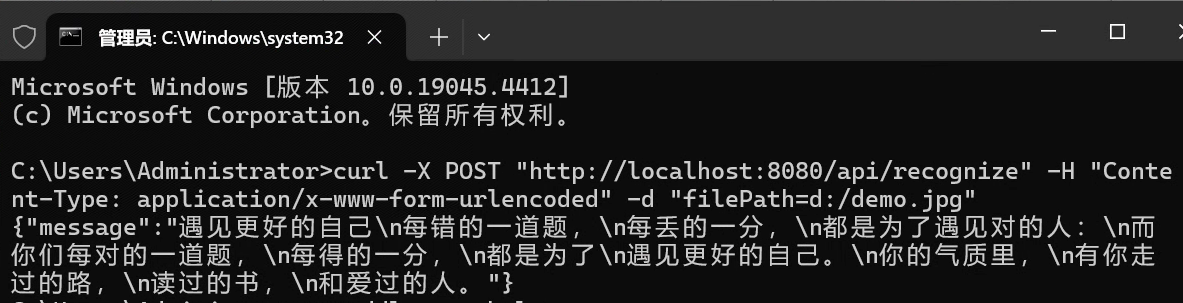
可以看到接口返回了图片的文本信息。
SpringCloud 微服务
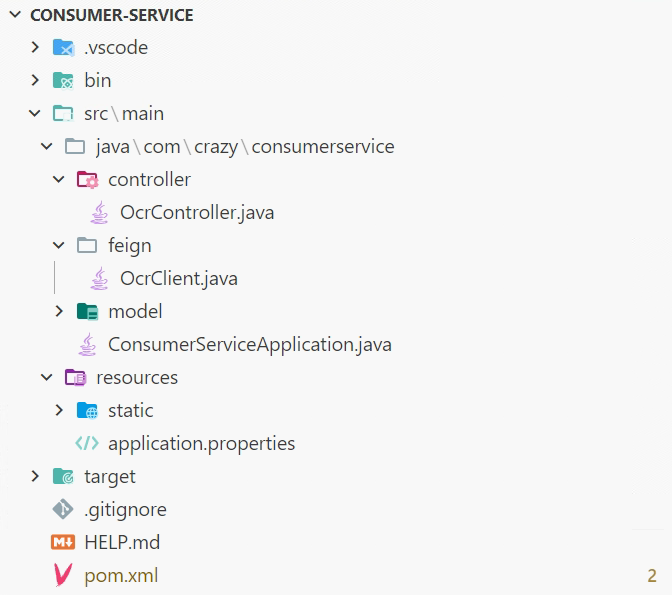
现在,我们可以创建一个简单的spring cloud 微服务项目,名为 consumer-service,
项目结构如下:
OcrClient.java :
使用Feign构建OCRClient接口, 代理ocr-service服务的ocr接口
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import com.crazy.consumerservice.model.ImagePathRequest;
@FeignClient(name = "ocr-service")
public interface OcrClient {
@PostMapping("/ocr/")
String recognizeImage(@RequestBody ImagePathRequest imagePathRequest);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- OcrController.java
import com.crazy.consumerservice.feign.OcrClient; import com.crazy.consumerservice.model.ImagePathRequest; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.*; @RestController @RequestMapping("/api") public class OcrController { @Autowired private OcrClient ocrClient; @PostMapping("/recognize") public String recognizeImage(@RequestParam String filePath) { ImagePathRequest request = new ImagePathRequest(); request.setFilePath(filePath); return ocrClient.recognizeImage(request); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
启动服务后,在nacos可以看到服务已注册
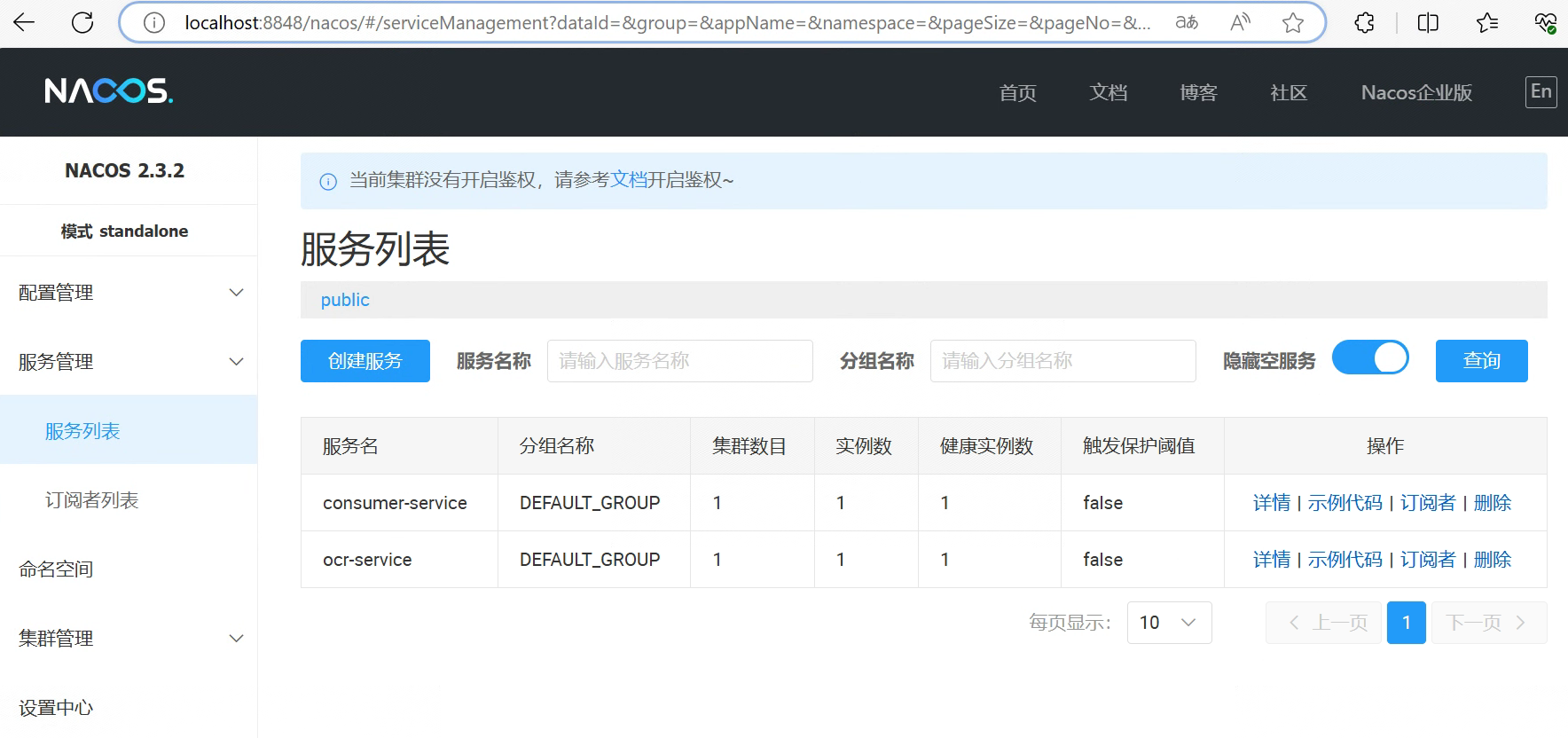
启动SpringBoot微服务
访问swagger界面
现在,记住咱们要 识别的图片的路径 d:\03.png

然后,在Java微服务的swagger界面填写这个路径 ,发现java到python 的RPC调用成功
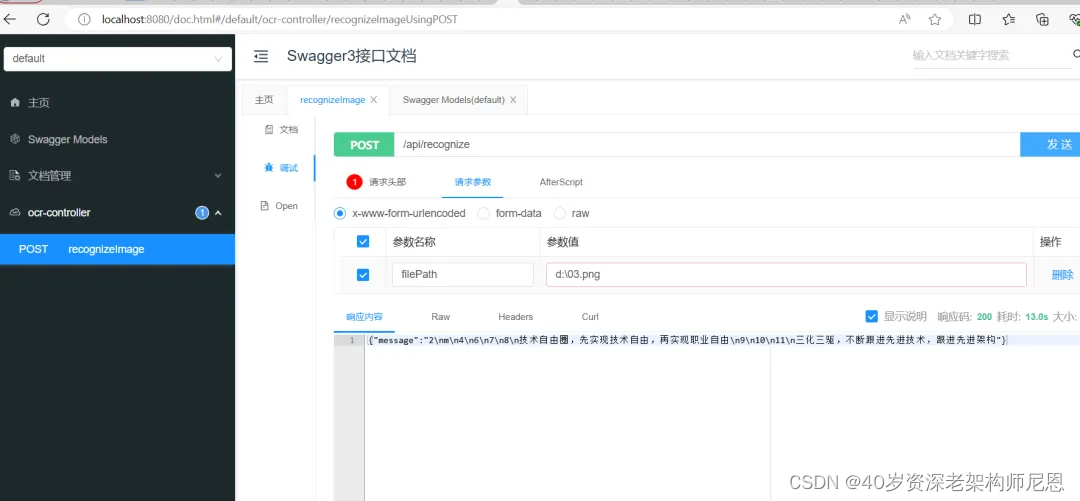
看以看到该接口成功的调用了ocr-service服务对应的接口,并返回了相应的信息。
Java+python 的rpc 基础调用的视频介绍,请参考后面的 《技术自由圈 专门的AI架构视频》
结语
通过重构原有的Java微服务与AI服务集成方式,采用FastAPI与Python-Nacos相结合的方案,我们不仅解决了原有架构的种种痛点,还为系统带来了更高的灵活性、可扩展性和运维便利性。
说在最后:有问题找老架构取经
毫无疑问,大模型架构师更有钱途, 这个代表未来的架构。
前面讲到,尼恩指导的那个一个成功案例,是一个9年经验 网易的小伙伴,拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型架构师。回想当时,尼恩本来是规划指导小伙做通用架构师的( JAVA 架构、K8S云原生架构), 当时候为了他的钱途, 尼恩也是 壮着胆子, 死马当作活马指导他改造为 大模型架构师。
没想到,由于尼恩的大胆尝试, 小伙伴成了, 相当于他不到1年时间, 职业身价翻了1倍多,现在可以拿到年薪 200W的offer了。
应该来说,小伙伴大成,实现了真正的逆天改命。
既然有一个这么成功的案例,尼恩能想到的,就是希望能帮助更多的社群小伙伴, 成长为大模型架构师,也去逆天改命。
技术是相同的,架构也是。
这一次,尼恩团队用积累了20年的深厚的架构功力,编写一个《LLM大模型学习圣经》,帮助大家进行一次真正的AI架构穿透,帮助大家穿透AI架构。
尼恩架构团队的大模型《LLM大模型学习圣经》是一个系列,初步的规划包括下面的内容:
- 《LLM大模型学习圣经:从0到1吃透Transformer技术底座》
- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
本文是第2篇,这一篇的作者是Andy。后面的文章,尼恩团队会持续迭代和更新。 并且录制配套视频。
当然,除了大模型学习圣经,尼恩团队,持续深耕技术,为大家输出更多,更深入的技术体系,思想体系。
多年来,用深厚的架构功力,把很多复杂的问题做清晰深入的穿透式、起底式的分析,写了大量的技术圣经:
- Netty 学习圣经:穿透Netty的内存池和对象池(那个超级难,很多人穷其一生都搞不懂),
- DDD学习圣经: 穿透 DDD的建模和落地,
- Caffeine学习圣经:比如Caffeine的底层架构,
- 比如高性能葵花宝典
- Thread Local 学习圣经
- 等等等等。
上面这些学习圣经,大家可以通过《技术自由圈》公众号,找尼恩获取。
大家深入阅读和掌握上面这些学习圣经之后,一定内力猛涨。
所以,尼恩强烈建议大家去看看尼恩的这些核心内容。
另外,如果学好了之后,还是遇到职业难题, 没有面试机会,怎么办?
可以找尼恩来帮扶、领路。
尼恩已经指导了大量的就业困难的小伙伴上岸.
前段时间,帮助一个40岁+就业困难小伙伴拿到了一个年薪100W的offer,小伙伴实现了 逆天改命 。
另外,如果没有面试机会,可以找尼恩来帮扶、领路。
- 大龄男的最佳出路是 架构+ 管理
- 大龄女的最佳出路是 DPM,

女程序员如何成为DPM,请参见:
DPM (双栖)陪跑,助力小白一步登天,升格 产品经理+研发经理
领跑模式,尼恩已经指导了大量的就业困难的小伙伴上岸。
前段时间,领跑一个40岁+就业困难小伙伴拿到了一个年薪100W的offer,小伙伴实现了 逆天改命。
另外,尼恩也给一线企业提供 《DDD 的架构落地》企业内部培训,目前给不少企业做过内部的咨询和培训,效果非常好。

尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓


