
- 1xss漏洞的修复建议/方法_xss漏洞修复
- 2http 和 https 的区别?
- 3Vue3 - 获取 Proxy 对象代理中包裹的 “真实数据“,解决对象或数组打印后是 Proxy 对象无法拿到原始数据的问题(提供 2 种详细解决方案)_vue3proxy里面拿到数组
- 4cudnn环境变量配置_cudnn 环境变量
- 5基于卷积神经网络的多目标图像检测研究(一)_多类目标图像识别
- 6Android中怎么重新启动APP或系统_kotlin android重启当前app
- 7计算机网络——网络层(2)
- 8在虚拟机上安装centos7_pve安装centos7
- 9Vue3中的Proxy和Reflect_vue3 refs proxy
- 10前端食堂技术周刊第 109 期:Vue2 即将 EOL、CSS 年度回顾、11 月登陆 Web 平台的新功能、Oxlint、shadcn/ui 揭秘、TC39 faq_vue shadcn-ui
【AI工具篇】使用OpenAI开源的Whisper模型,制作本地离线的视频或音频转文本功能...
赞
踩
有时候在看一些学习视频时候,难免感觉进度太慢,或者学习视频太枯燥,想自己根据视频关键信息做总结或快速浏览,想着如果有一个工具,我把视频丢进去,它自己给我生成里面语音的所有文本的信息,然后我自己根据文本来提炼关键的有用的信息,还可以节约看视频的时间,是不是会很Nice? 于是,前一天经过一位小伙伴的推荐,使用一款OpenAI开源的模型,也就是今天的主角——Whisper,来实现我们的上面这个偷懒的功能。
首先,去hugging face网上下载对应的模型,该模型分为几个不同的档次,可以根据自己的电脑配置要求来。例如,显卡显存、或者内存。如果使用CPU计算,可以使用内存,不过准确度会降低;如果使用显卡计算,就会提高很多准确度。同时,模型对显存需求越大,也代表精确越高。
模型下载地址:https://huggingface.co/ggerganov/whisper.cpp
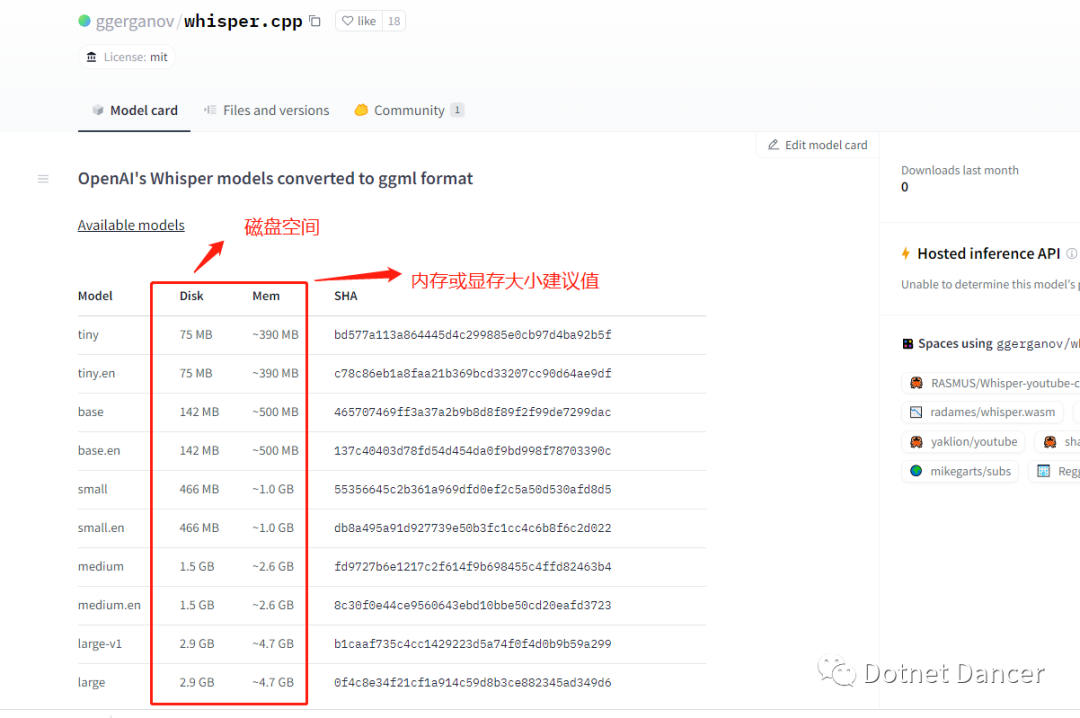
选择模型版本,根据自己需要选择。我的电脑是老古董了,还用着1060的卡,但是足够用了,就这么着吧。如果配置比较差的情况下,建议适当选择其他模型。large模型比较大,但是会更准确一些。我这边就用large系列模型好了,虽然显卡不咋地,但是跑这个还是够用了。
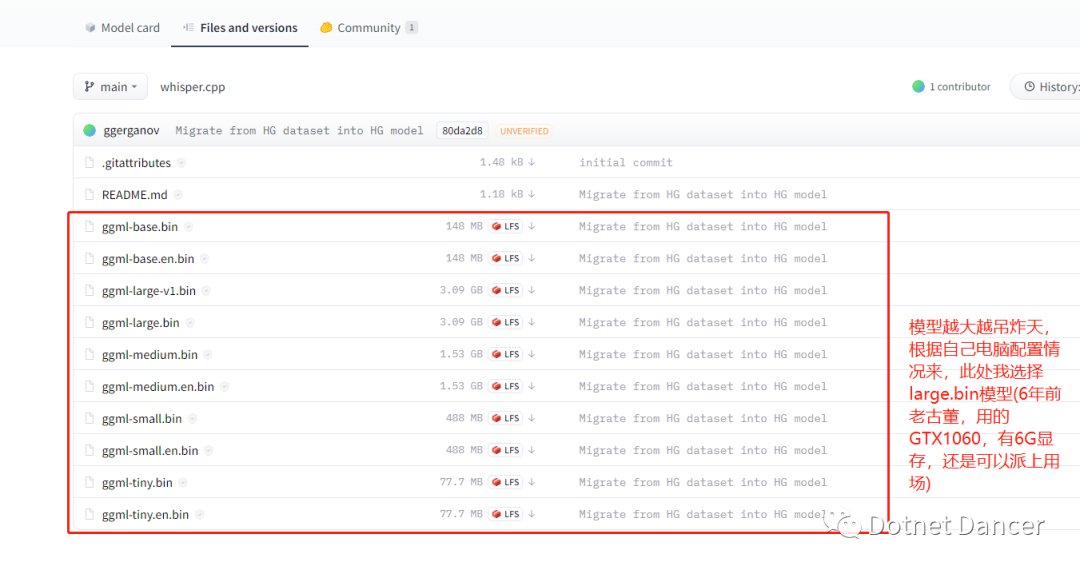
然后下载官方提供的客户端,客户端下载可能需要梯子,此处为了节省大家时间,我下载了个最新版本的客户端(截止到2023年4月1日)放网盘上,可在本公众号【Dotnet Dancer】后台回复【AI文本提取】进行获取编译后的客户端以及官方客户端源码(C++和C#开发的源码)
进入到解压缩文件夹,双击exe运行
打开页面,选择模型文件
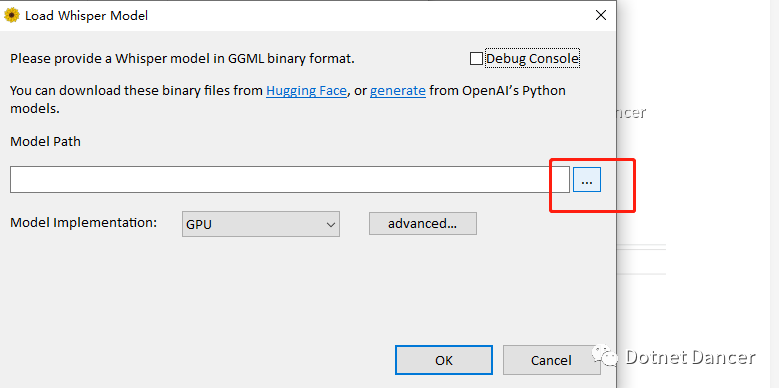
选择GPU,然后在 advanced里面选择你的显卡,例如我的老破小GTX1060
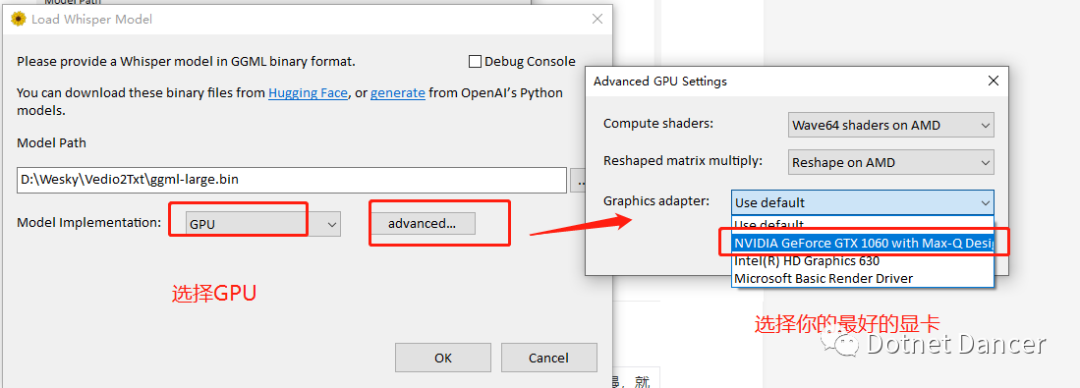
点击OK,加载模型

然后选择语言,例如我的视频是中文版的,就选择中文
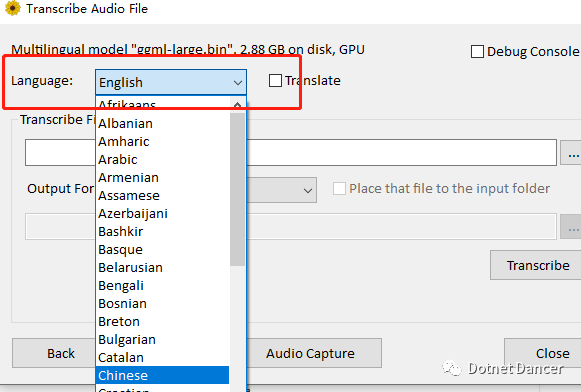
然后选择需要处理的音视频文件,以及选择输出文本样式格式(例如我选择的是带时间线的,每个文本会自带文字信息)和需要保存的文件名称等。

完了以后,点击Transcribe,然后开始执行,电脑也开始轰轰响(毕竟是老古董)

右上角勾选debug console,可以打开控制台,查看实时信息
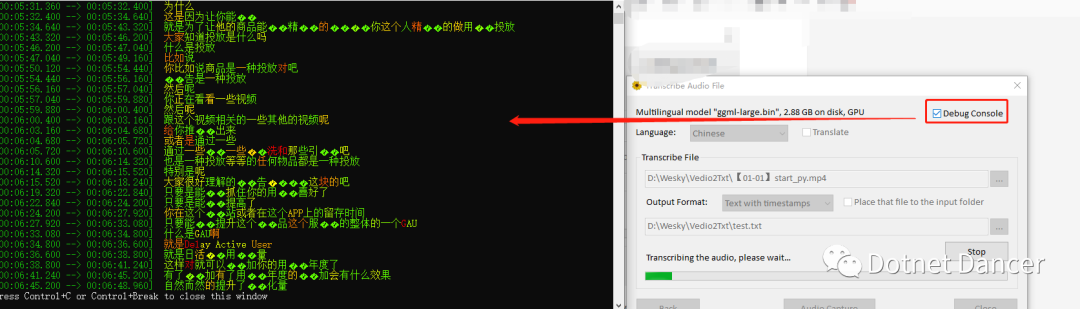
按Ctrl C,或者取消掉勾选,控制台实时日志就会关闭掉。
让机器跑一会儿,看了下视频有点大,接近俩小时,可能要个几分钟。
两分钟过去了……
看来还要点时间,我去喝杯茶压压惊先,等下再回来续写。
……
看来机器不给力,又三分钟过去了,看样子才1/4 ~ 1/3的样子。
继续喝杯茶压压惊提提神
……
大概20分钟又过去了,虽然还没完成,看来黎明就在眼前~
老古董电脑太卡了,显卡还是有点小压力~~~
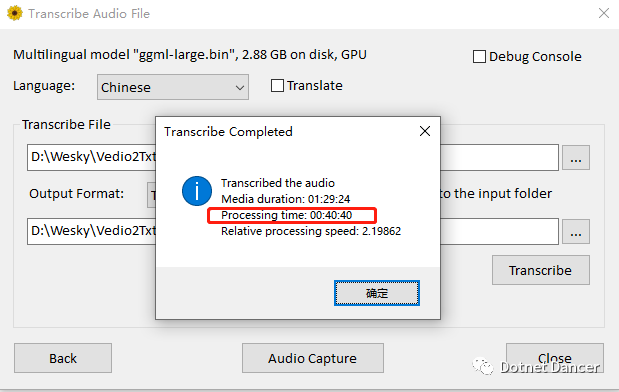
……又过了三分钟,弹出提示OK了.一共用了40分钟,视频是1小时29分钟,看来还是得需要牛逼点的显卡啊!!!我这款1060老破小,还算勉强能用。
接下来看提取的内容的效果
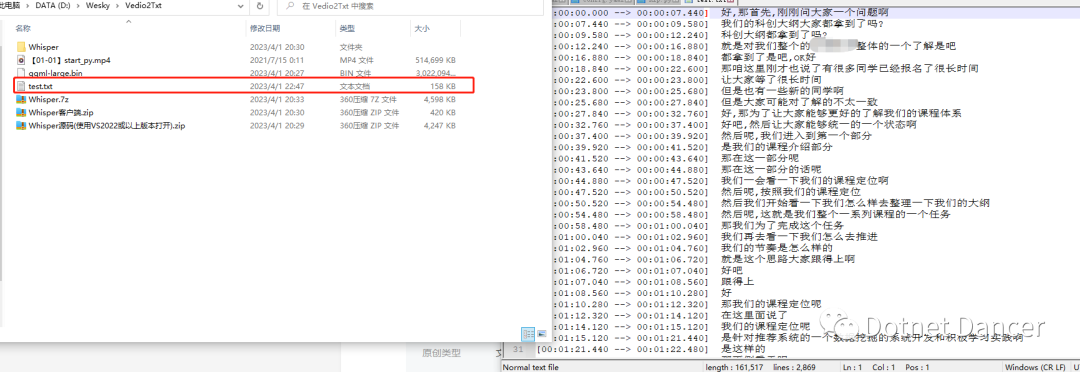
哦豁,基本上内容没毛病,和视频内的发音内容很一致,说明OK,拉到最底下看看:
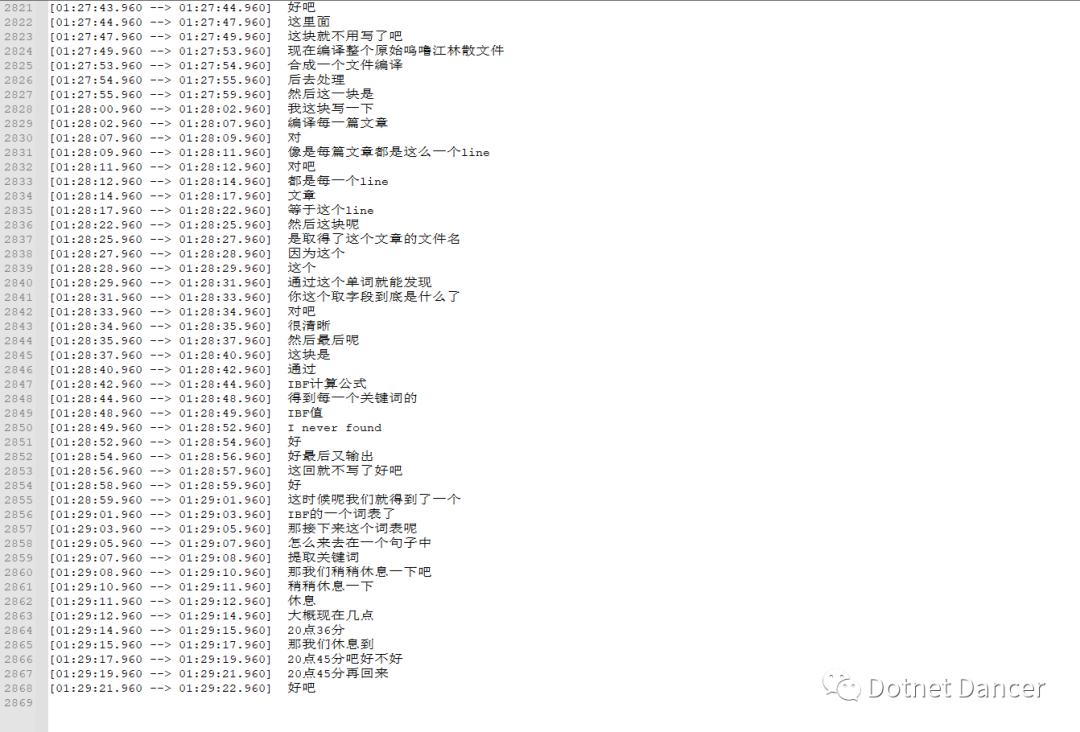
嗯,也没毛病,说明提示的效果还可以接受,错别字也很少。
以上就是该文章的全部内容。
祝大家玩的愉快~~~

![[python]基于faster whisper实时语音识别语音转文本_fast whisper 语](https://img-blog.csdnimg.cn/img_convert/cf52fbe57e404f30babcdda6f1ef2c08.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)


