
- 1python入门(三):if语句&字典(if语句,使用字典,遍历字典,嵌套)_字典可以做if条件判断吗
- 2微信小程序入坑教程二十一:使用wx.saveImageToPhotosAlbum保存图片时通过检测scope.writePhotosAlbum权限来提醒用户是否需要授权
- 3使用kaggle免费进行tensorflow模型训练_safetensors模型怎么用
- 4GitLab的简单使用_gitlab 创建项目后 existing floder 在那个
- 5gpg加密命令 linux_GPG Suite for Mac(GPG加密工具套装)
- 6博客杂谈---开源软件的影响力
- 7Diffusion model在其他领域中的相关论文_contextual net: a multimodal vision-language model
- 8rust编程之道_【Rust日报】 20190414
- 9Tensorflow构建自己的图片数据集TFrecords_tensorflow 自己的图片 数组
- 10linux常用命令及快捷键大全_linux命令框快捷键
UniPose:Unified Human Pose Estimation in Single Images and Videos_unipose: unified human pose estimation in single i
赞
踩
论文地址:https://arxiv.org/abs/2001.08095
1.摘要
作者基于“Waterfall” Atrous Spatial Pooling 体系结构,提出了UniPose。 利用标准CNN架构的当前姿态估计方法在很大程度上依赖于统计后处理或预定义的anchor 姿态进行联合定位。 UniPose结合了上下文分割和联合定位功能,可以在不依赖统计后处理方法的情况下,在单阶段高精度地估计人体姿势。 UniPose中的Waterfall模块利用级联体系结构中渐进式过滤的效率,同时保持与空间金字塔结构相当的多尺度特征。 此外,本文的方法已扩展到UniPose-LSTM以进行多帧处理,并获得了视频中姿势估计的SOTA结果。
架构的主要组成部分是Waterfall Atrous Spatial Pooling(WASP)模块,该模块将空洞卷积的级联方法与从空洞空间金字塔池化(ASPP)模块[11]的并行结构中获得的较大FOV相结合。 由于网络中使用了较大的视野(Field-of-View ,FOV)和多尺度方法,因此该方法使用上下文信息来预测关节的位置。 使用上下文方法,网络将包含整个框架的信息,因此,不需要基于统计或几何方法的后分析。
2. 相关工作
2.1 姿态估计方法
传统的人体姿态估计方法着重于关节的检测,并因此通过探索目标图像中关节之间的几何形状来进行姿态的检测。 近年来,依靠卷积神经网络(CNN)的方法取得了优异的结果。
- 流行的卷积位姿机制(CPM)通过网络中的一组操作改进了联合检测。
- 堆叠式沙漏网络利用沙漏结构的级联进行姿势估计任务。
- Yan等人集成了部分相似性字段(PAF)的概念,从而产生了OpenPose方法。 PAF使用更重要的关节的检测来更好地估计不太重要的关节的预测。 这项创新使得复杂度和计算能力降低很多,使得多人姿态估计技术得以发展。
- [Multi-context attention for human pose estimation]中的多上下文方法依靠沙漏网络来进行姿势估计。 Hourglass Residual Unit(HRU)增强了原始骨干,目的是增加FOV。
- 具有条件随机场(CRF)的后期处理用于组合检测到的关节之间的关系。 但是,CRF的缺点是增加了复杂性,需要较高的计算能力并降低了速度。
- 高分辨率网络(HRNet)包括高分辨率和低分辨率表示。 从高分辨率开始,该方法逐渐添加低分辨率子网以形成更多阶段,并在子网之间执行多尺度融合。 HRNet受益于更大的多分辨率FOV,这也是本文通过WASP模块以更简单的方式实现的功能。
- DeepPose 利用了一系列深层的CNN,并通过回归将身体关节定位。 该方法依靠迭代细化,以更好地预测对称和较低置信度的关节。
- 一些最近的工作试图将上下文信息用于姿势估计。 级联预测融合(CPF)使用图形组件以便为姿势估计使用上下文。
- 同样,Cascade Feature Aggregation(CFA)旨在利用语义信息通过级联方法检测姿势。
- 位置,分类和回归网络(LCR-Net)通过深度回归将姿势估计扩展到3D空间。 LCR-Net依靠Detectron骨干来检测人体关节位置。从这些位置,该方法为检测到的人体姿势找到最适合预定义锚定姿势的方法。最后,LCR-Net执行回归以估计图像中的3D坐标。此方法的缺点是可用的锚定姿势组有限,这在网络上限制了不可预见的姿势的估计。
- 在用于3D姿态估计的另一种方法中,用于人类捕获的MonoCap方法将CNN与几何先验耦合,以便使用Expectation-Maximization算法来统计确定姿态的三维。
当前方法的缺点是它们需要独立的分支来检测 框架中人类目标的边界框。 例如,LightTrack 依靠单独的YOLO 在检测关节之前执行目标的检测。在不同的框架中,LCR-Net [38]具有不同的分支,可用于使用Detectron [17]进行检测并在分类过程中布置关节。而本文是无需使用后处理或独立的并行分支即可生成边界框检测。
2.2 空洞卷积和ASPP
结合CNN层的语义分割和姿态估计方法的一个重要挑战是池化所导致分辨率显著降低。全卷积网络(FCN)通过在反卷积层上部署上采样策略解决了分辨率降低的问题。 这些尝试颠倒了卷积操作,并将特征图的大小增加到原始图像的尺寸。
语义分割中的一种流行技术是使用空洞卷积(Atrous或dilated卷积)[Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution and fully connectedcfrs]。 空洞卷积的主要目标是增加网络中感受野的大小,避免下采样并生成用于处理的多尺度框架。
在更简单的一维卷积情况下,信号的输出定义如下:
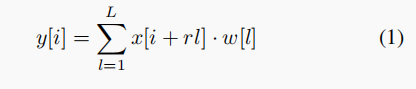
其中,r 是扩张率,ω[l]是长度L的滤波器,x [i]是输入,y [i] 是输出。 只有一个扩张率值是常规卷积运算。
受空间金字塔应用于池化运算的成功推动,ASPP体系结构成功地并入了DeepLab 中以进行语义分割。 ASPP方法在四个具有不同扩张率的并行分支中组合空洞卷积,这些分支通过快速双线性插值与八个附加参数进行组合。 此结构可恢复原始图像分辨率中的特征图。 在姿态估计期间,ASPP网络中分辨率和FOV(Field-of-View)的提高可能有益于身体部位的上下文检测。 UniPose框架中的Waterfall体系结构可更有效地利用此特征。
3. 本文方法
UniPose架构利用“Waterfall”结构中空洞卷积与卷积级联相结合生成的大FOV。 WASP模块在缩小的网络规模中提供了多尺度的特征表示以及较高的效率。 作为对以前工作的改进,Uni-Pose不需要单独的分支来进行边界框和关节检测。 相反,它对人体及其关节的边界框执行统一检测。
3.1 总体结构

首先输入尺寸为H*W的彩色图像,然后通过ResNet-101和WASP模块,以将降低的分辨率提高8倍,从而获得256个特征通道。得到的特征图由编码器网络处理,该编码器网络生成K个热图,每个关节一个,并从Softmax获得相应的概率分布。 然后,解码器执行双线性插值以恢复原始分辨率,随后局部最大操作以定位关节以进行姿势估计。 此外,网络中的解码器会生成可见和遮挡部分的关节检测。 该解码器无需使用后处理或独立的并行分支即可生成边界框检测。
3.2 WASP Module

WASP模块生成了有效的多尺度特征表示形式,以使UniPose获得SOTA结果。 图4所示的WASP体系结构经过设计,可以充分利用ASPP结构的较大FOV和级联方法的减小的size。 WASP的灵感在于结合ASPP,Cascade和Res2Net模块的优势。
WASP依赖于ASPP基础的atrous卷积来维持较大的FOV。 WASP还以级联方法激发了级联的atrous卷积,以提高效率。此外,WASP融合了Res2Net架构和其他多尺度方法所使用的多尺度特征。 与ASPP和Res2Net相比,WASP不会立即并行化输入流。 相反,它首先通过卷积过滤器进行处理,然后创建一个新分支,从而创建瀑布流(waterfall flow)。 WASP还超越了级联方法,它结合了其所有分支的流和原始输入的平均池化以实现多尺度表示。
WASP的设计目标是减少参数数量以应对内存限制并克服 WASP中的四个分支具有不同的FOV,并且以瀑布状的方式排列。 WASP中的atrous卷积以6的小比率开始,此比率在随后的分支中不断增加(6、12、18、24的比率)。 由于较小的滤波器尺寸,此配置可提高效率,并与每个分支组合创建多尺度特征以获得更丰富的表示。 WASP模块在图2的UniPose架构中用于姿势估计。
3.3 Decoder Module

原始图像尺寸为(1280x720)。 解码器的输入是256通道的ResNet低层特征和256通道的WASP得分特征图。对于Resnet的特征,经过1×1卷积和最大池化得到120×90×48的特征图;对于WASP模块产生的得分特征图,经过双线性插值得到120×90×304的特征图。将这两个特征图concat后,依次通过卷积层,dropout层和最终的双线性插值来对特征图进行级联和处理,以将其调整为原始输入大小。 解码器的输出是与K个关节相对应的K个热图,如图像示例所示,这K个热图用于局部最大操作后的关节定位。 此外,解码器还会输出边界框的热图(图中未显示)。
3.4 UniPose-LSTM for Pose Estimation in Video

图5:用于视频中姿势估计的UniPose-LSTM体系结构。 来自UniPose解码器的联合热图与来自先前LSTM状态的最终热图一起馈入LSTM。 LSTM之后的卷积层将输出重组为用于联合定位的最终热图。
对于视频处理,利用连续帧之间的相似性和时间相关性是很有用的。要在视频处理模式下运行,UniPose体系结构将通过一个LSTM模块进行增强,该模块可接收前一帧的最终热图以及当前帧的编码器热图。 UniPose-LSTM的pipeline如图5所示。该网络包括LSTM之后的CNN层,以生成用于联合检测的最终热图。UniPose-LSTM结构允许网络使用先前处理的帧中的信息,而不会显着增加网络的总大小。 对于单一图像和视频配置,网络使用相同的ResNet-101主干网,WASP模块和解码器。 当对多个帧使用LSTM时,作者评估了由于内存组件的时间长度而导致的性能优势。 实验确定,在LSTM中合并多达5个帧时,精度会提高,并且在其他帧中,精度会达到稳定水平。
4. 实验
4.1 LSP dataset

4.2 MPII dataset

4.3 Penn Action dataset


4.4 BBC Pose dataset


