
- 1js Blob对象_js new blob
- 2gephi和python_python+nlp+Gephi 分析电视剧【人民的名义】
- 3ubuntu 18.04 安装CUDA + CUDNN + tensorflow-gpu_ubuntu18.04安装tensfrflow-gpu
- 4【深度学习】卷积神经网络CNN-3 可视化_cnn3
- 5看了绝不后悔的文章--(最后附源码 cv即可看到效果)--给哔站的视频生成一个进度条 显示你看的视频时间和你剩余需要观看时间_怎样将网页视频的进度看完代码显示出来
- 6【c#面向对象】项目实践—汽车租赁系统3:实现汽车出租功能_实现一个简单的出租车计费系统面向对象程序设计c#
- 7灾备,两地三中心
- 8com.microsoft.sqlserver.jdbc.SQLServerException: 驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接。_the unlimited policy files for earlier releases ar
- 9RPC通信相关
- 10Unity 报错【已解决】:ArgumentException: Input Axis Horizonal is not setup._argumentexception: input axis horizontal is not se
解码大语言模型奥秘:《大规模语言模型:从理论到实践》震撼上市!_大语言模型参考文献有哪些
赞
踩
2022年11月,ChatGPT的问世展示了大模型的强大潜能,对人工智能领域有重大意义,并对自然语言处理研究产生了深远影响,引发了大模型研究的热潮。
距ChatGPT问世不到一年,截至2023年10月,国产大模型玩家就有近200家,国内AI大模型如雨后春笋般涌现,一时间形成了百家争鸣、百花齐放的发展态势。
“大模型”当之无愧地承包了2023年科技圈全年的亮点!
那么,对IT圈的科技从业者来说,应该做什么?
拥抱技术变革,理解产业市场,找到适合自己的位置。
大模型市场可以分为通用大模型和垂直大模型两大类。
大模型的代表ChatGPT是通用大模型,也是许多国内厂家对标的大模型,以技术攻克为目的。国内的文心一言就属于这一类。
垂直大模型
为了使更多的自然语言处理研究人员和对大语言模型感兴趣的读者能够快速了解大模型的理论基础,并开展大模型实践,复旦大学张奇教授团队结合他们在自然语言处理领域的研究经验,以及分布式系统和并行计算的教学经验,在大模型实践和理论研究的过程中,历时8个月完成《大规模语言模型:从理论到实践》一书的撰写。希望这本书能够帮助读者快速入门大模型的研究和应用,并解决相关技术问题。

本书一经上市,便摘得京东新书日榜销售TOP1的桂冠,可想大家对本书的认可和支持!
这本书为什么如此受欢迎?它究竟讲了什么?下面就给大家详细~~
本书主要内容
本书围绕大语言模型构建的四个主要阶段——预训练、有监督微调、奖励建模和强化学习展开,详细介绍各阶段使用的算法、数据、难点及实践经验。
预训练阶段需要利用包含数千亿甚至数万亿单词的训练数据,并借助由数千块高性能GPU 和高速网络组成的超级计算机,花费数十天完成深度神经网络参数的训练。这一阶段的难点在于如何构建训练数据,以及如何高效地进行分布式训练。
有监督微调阶段利用少量高质量的数据集,其中包含用户输入的提示词和对应的理想输出结果。提示词可以是问题、闲聊对话、任务指令等多种形式和任务。这个阶段是从语言模型向对话模型转变的关键,其核心难点在于如何构建训练数据,包括训练数据内部多个任务之间的关系、训练数据与预训练之间的关系及训练数据的规模。
奖励建模阶段的目标是构建一个文本质量对比模型,用于对有监督微调模型对于同一个提示词给出的多个不同输出结果进行质量排序。这一阶段的难点在于如何限定奖励模型的应用范围及如何构建训练数据。
强化学习阶段,根据数十万提示词,利用前一阶段训练的奖励模型,对有监督微调模型对用户提示词补全结果的质量进行评估,与语言模型建模目标综合得到更好的效果。这一阶段的难点在于解决强化学习方法稳定性不高、超参数众多及模型收敛困难等问题。
除了大语言模型的构建,本书还介绍了大语言模型的应用和评估方法,主要内容包括如何将大语言模型与外部工具和知识源进行连接、如何利用大语言模型进行自动规划,完成复杂任务,以及针对大语言模型的各类评估方法。

本书目录
第1章 绪论 1
1.1 大语言模型的基本概念 1
1.2 大语言模型的发展历程 4
1.3 大语言模型的构建流程 8
1.4 本书的内容安排 11
第2章 大语言模型基础 13
2.1 Transformer结构 13
2.1.1 嵌入表示层 14
2.1.2 注意力层 16
2.1.3 前馈层 18
2.1.4 残差连接与层归一化 19
2.1.5 编码器和解码器结构 20
2.2 生成式预训练语言模型GPT 25
2.2.1 无监督预训练 26
2.2.2 有监督下游任务微调 27
2.2.3 基于HuggingFace的预训练语言模型实践 27
2.3 大语言模型的结构 33
2.3.1 LLaMA的模型结构 34
2.3.2 注意力机制优化 40
2.4 实践思考 47
第3章 大语言模型预训练数据 49
3.1 数据来源 49
3.1.1 通用数据 50
3.1.2 专业数据 51
3.2 数据处理 52
3.2.1 质量过滤 52
3.2.2 冗余去除 53
3.2.3 隐私消除 55
3.2.4 词元切分 55
3.3 数据影响分析 61
3.3.1 数据规模 61
3.3.2 数据质量 64
3.3.3 数据多样性 66
3.4 开源数据集 68
3.4.1 Pile 68
3.4.2 ROOTS 71
3.4.3 RefinedWeb 73
3.4.4 SlimPajama 75
3.5 实践思考 79
第4章 分布式训练 80
4.1 分布式训练概述 80
4.2 分布式训练的并行策略 83
4.2.1 数据并行 84
4.2.2 模型并行 88
4.2.3 混合并行 96
4.2.4 计算设备内存优化 97
4.3 分布式训练的集群架构 102
4.3.1 高性能计算集群的典型硬件组成 102
4.3.2 参数服务器架构 103
4.3.3 去中心化架构 104
4.4 DeepSpeed实践 110
4.4.1 基础概念 112
4.4.2 LLaMA分布式训练实践 115
4.5 实践思考 127
第5章 有监督微调 128
5.1 提示学习和语境学习 128
5.1.1 提示学习 128
5.1.2 语境学习 130
5.2 高效模型微调 131
5.2.1 LoRA 131
5.2.2 LoRA的变体 135
5.3 模型上下文窗口扩展 137
5.3.1 具有外推能力的位置编码 137
5.3.2 插值法 138
5.4 指令数据的构建 141
5.4.1 手动构建指令 141
5.4.2 自动构建指令 142
5.4.3 开源指令数据集 146
5.5 DeepSpeed-Chat SFT实践 147
5.5.1 代码结构 148
5.5.2 数据预处理 151
5.5.3 自定义模型 153
5.5.4 模型训练 155
5.5.5 模型推理 156
5.6 实践思考 157
第6章 强化学习 158
6.1 基于人类反馈的强化学习 158
6.1.1 强化学习概述 159
6.1.2 强化学习与有监督学习的区别 161
6.1.3 基于人类反馈的强化学习流程 162
6.2 奖励模型 163
6.2.1 数据收集 164
6.2.2 模型训练 166
6.2.3 开源数据 167
6.3 近端策略优化 168
6.3.1 策略梯度 168
6.3.2 广义优势估计 173
6.3.3 近端策略优化算法 175
6.4 MOSS-RLHF实践 180
6.4.1 奖励模型训练 180
6.4.2 PPO微调 181
6.5 实践思考 191
第7章 大语言模型应用 193
7.1 推理规划 193
7.1.1 思维链提示 193
7.1.2 由少至多提示 196
7.2 综合应用框架 197
7.2.1 LangChain框架核心模块 198
7.2.2 知识库问答系统实践 216
7.3 智能代理 219
7.3.1 智能代理的组成 219
7.3.2 智能代理的应用实例 221
7.4 多模态大语言模型 228
7.4.1 模型架构 229
7.4.2 数据收集与训练策略 232
7.4.3 多模态能力示例 236
7.5 大语言模型推理优化 238
7.5.1 FastServe框架 241
7.5.2 vLLM推理框架实践 242
7.6 实践思考 244
第8章 大语言模型评估 245
8.1 模型评估概述 245
8.2 大语言模型评估体系 247
8.2.1 知识与能力 247
8.2.2 伦理与安全 250
8.2.3 垂直领域评估 255
8.3 大语言模型评估方法 260
8.3.1 评估指标 260
8.3.2 评估方法 267
8.4 大语言模型评估实践 274
8.4.1 基础模型评估 274
8.4.2 SFT模型和RL模型评估 277
8.5 实践思考 282
参考文献 284
索引 303
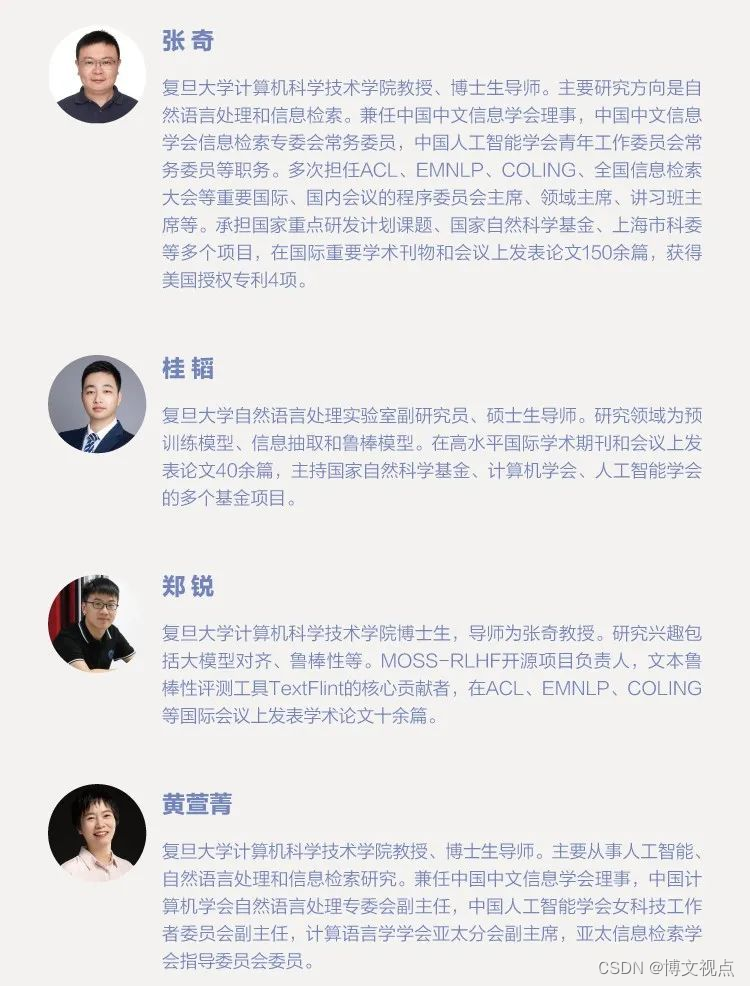
作者介绍
名家寄语
2022年11月ChatGPT的出现,开启了大规模语言模型的新时代。面对人工智能(AI)大模型引发的广泛讨论,如何在日新月异的科技创新环境中赢得主动、在关键领域取得创新突破,是时代给予教育的新命题。这不仅关系到人才培养,也关系到未来的国际竞争。高校有责任在“AI时代”为科学理念的普及、科学应用的拓展、科学伦理的探讨发挥引领和导向作用,使得更多群体、更多领域共享“AI 时代”的红利。
《大规模语言模型:从理论到实践》的作者对自然语言处理和大语言模型方法开展了广泛而深入的研究,该书及时地对大语言模型的理论基础和实践经验进行了介绍,可以为广大研究人员、学生和算法研究员提供很好的入门指南。
——金力 中国科学院院士,复旦大学校长
大规模语言模型的成功研发和应用,帮助人类开启了通用人工智能时代的大门。
《大规模语言模型:从理论到实践》是张奇教授等几位作者的倾心之作,作者以深厚的学术造诣和丰富的实践经验,为我们揭示了大规模语言模型的基础理论、技术演进、训练方法和实践应用。
本书不仅为读者提供了翔实的技术细节,更展示了作者对人工智能领域的严谨理解。对于从事自然语言处理、深度学习等领域的研究者和工程师来说,本书无疑是进入大规模语言模型领域的案头参考书。
——王小川 百川智能创始人兼CEO
我始终相信,大规模语言模型带来了一场新的科技革命,这场革命会逐渐渗透到整个社会的方方面面,带来极其深远的影响。了解、理解直至掌握大规模语言模型技术,对于众多技术从业者而言迫在眉睫。
出自复旦大学自然语言处理团队的这本书的出版适逢其时,作者团队堪称豪华,在学术界也一直以严谨著称。
这本书不仅介绍了大规模语言模型的基本概念和原理,还提供了大量的工程实践方法和示例代码。无论是初学者还是经验丰富的从业者,都会从中受益。这本书,你值得拥有!
——王斌 小米集团AI 实验室主任、自然语言处理首席科学家
《大规模语言模型:从理论到实践》一书深入阐述了大规模语言模型的演变历程、理论基础及开发实践。
本书聚焦大规模语言模型构建的核心技术,包括语言模型预训练、指令微调和强化学习,并细致地介绍了每个阶段所使用的算法、数据来源、面临的难题及实践经验。
此外,本书探讨了大规模语言模型的应用领域和评价方法,为对大规模语言模型研究感兴趣的研究者提供了理论支持和实践指导。不仅如此,对于希望将大规模语言模型应用于实际问题解决的研发人员来说,本书同样具有重要的参考价值。特此力荐!
——范建平 联想集团副总裁、联想研究院人工智能实验室负责人
大规模语言模型是技术发展最快的研究和产业方向,没有之一。然而,很多人仅知其然不知其所以然,很多学生也没有深入研究大规模语言模型的实践机会。
本书作者结合自己在自然语言处理领域多年的研究经验、近300篇相关论文深度研读感悟,特别是作者团队从零开始研发复旦大学大规模语言模型过程中经历的切身实践经验,最终形成本书,为读者展示了大规模语言模型训练的全流程细节,同时深入浅出地解释了设计每一步的原理和效用,值得所有具备科学精神、想搞清楚大规模语言模型到底是怎么训出来的投资人、管理者认真阅读,更值得所有想从事或刚从事大规模语言模型研究和改进的研究人员深度阅读。
——胡国平 科大讯飞高级副总裁,认知智能全国重点实验室主任
↑限时五折优惠↑


限时五折优惠,快快抢购吧!

