
- 1MySQL PDO的介绍和使用
- 2git报错fatal: unable to access ‘https://github.com/.......‘: OpenSSL SSL_read: Connection was reset, e
- 3ROM学习笔记1-ROM、PROM、EPROM、EEPROM_掩膜rom
- 4java jls8_java基础学习----String
- 5Vue3的新特性变化,上手指南!_vue3的变化
- 6图解TCP/IP详解(史上最全)
- 7YOLOV9论文概述
- 81096: 水仙花数(函数专题,多实例)_利用实参和形参设计函数,判定水仙花数,实参传入数字,列出所有水仙花数
- 9从PHP开始学渗透 -- GET请求和POST请求_get渗透
- 10VSCode中打开md文件的智能提示
[数据分析实战]对比用Excel和Python用来做数据分析的优缺点,用Python的Pandas操作Excel数据表格原来如此简单?还不赶紧学起来?_excel数据分析实战
赞
踩
目录
首先,我先总结一下用Excel和Python用来做数据分析的优缺点
首先,我先总结一下用Excel和Python用来做数据分析的优缺点
老话说知己知彼才能百战不怠,我们先把两者的优缺点分析好,就会知道什么场景下该用Excel,什么场景下该用Python,如果不想看的小伙伴可以直接跳转到操作部分
Excel做数据分析的优点:
-
易用性:Excel是一个广泛使用和易学习的工具,几乎每个人都能够使用它来进行基本的数据处理和分析。
-
快速分析:Excel提供了一系列图表和函数,可以快速分析数据并获得结果。
-
适合小规模数据处理:如果数据集比较小,Excel可以轻松地处理这些数据。Excel还可以使用筛选器、排序和分组等功能来进一步细化分析。
-
Excel扩展性强:Excel支持VBA编程,用户可以通过编写宏程序来进一步扩展其功能。
-
可视化功能强大:Excel内置的绘图功能非常强大,可以快速绘制各种图表和统计图。
Excel做数据分析的缺点:
-
处理大型数据集:在处理大型数据集时,Excel的性能表现会受到限制。Excel可能会崩溃或运行缓慢。
-
数据不规范:如果数据有问题或不规范,Excel很难对其进行处理。例如,在字符分割方面,Excel的能力很有限。
-
数据安全性:Excel中的数据安全性较差,如果数据需要经常共享或与其他人交换,则需要使用诸如密码保护等其他技术来保护数据。
-
扩展性:Excel对于扩展性的支持比较有限,仅支持VBA宏编程。
Python做数据分析的优点:
-
处理庞大数据集:Python在处理大型数据集方面比Excel更有效率。numpy和pandas库针对大型数据集提供了高效的处理和存储技术。
-
灵活性更强:Python语言本身非常灵活,可以执行更多的数据处理和分析操作。Python还支持大量的第三方库,例如matplotlib和seaborn用于可视化,scikit-learn用于机器学习等,可以满足不同数据分析需求。
-
自动化:Python可以实现自动化数据分析过程,能够大幅度提高数据分析的效率和准确性。可以通过编写Python程序来自动化执行数据读取、清洗、转换和建模等操作。
-
代码管理:Python代码可以集成到版本控制工具中,使代码管理变得更加容易。这对于多人协作的情况非常有帮助。
-
开放源代码社区支持:Python拥有一个庞大的开放源代码的社区,这个社区为Python用户提供了丰富的支持、文档和示例。
Python做数据分析的缺点:
-
上手难度:相较于Excel,Python学习曲线较高,需要具备一定的编程基础。
-
可视化难度:尽管Python有很多数据可视化库,但与Excel的可视化工具相比,它们可能需要更多的代码和操作。
-
缺少Excel的特定功能:Excel还有一些Python不太适用(或没有)的具体功能,例如共享文档的实时转发、权限控制等。
-
计算机配置:Python处理大型数据集需要计算机配置较高。需要更大的内存空间来容纳数据,更快的处理器来加速运算。
我相信各位聪明的小伙伴都看出来了,虽然学习Python确实是会有一些难度,但是好处可不只一星半点。
如果是数据量并不大,使用Excel还是比较方便的,
不过你得知道:Python更适合处理比更大容量的数据,灵活性更强,老板总会有奇葩的需求但是会了Python这个利器,无疑是给我们如虎添翼。
它可以自动化处理好老板的需求,而且Python还能操作一些Excel内容,那么下面我们就来请出Python练个手吧!
下面我们会通过python与excel的功能对比,来详细介绍一下我们应该如何使用python通过函数式编程完成excel中的数据处理及分析工作。
1.展示本例子中使用的数据
网上某药店2021年上半年销售数据

2.开始动手
一、导入数据以及理解数据部分
import pandas as pd # 导入pandas库,用于处理Excel数据
medicineData = pd.ExcelFile('d:/data/数据分析实例.xlsx') # 选择文件
sales = medicineData.parse('药物销售单') # 选择要导入的sheet名,确定要导哪张表
sales.head(10) # 显示表格的前10行
运行结果:
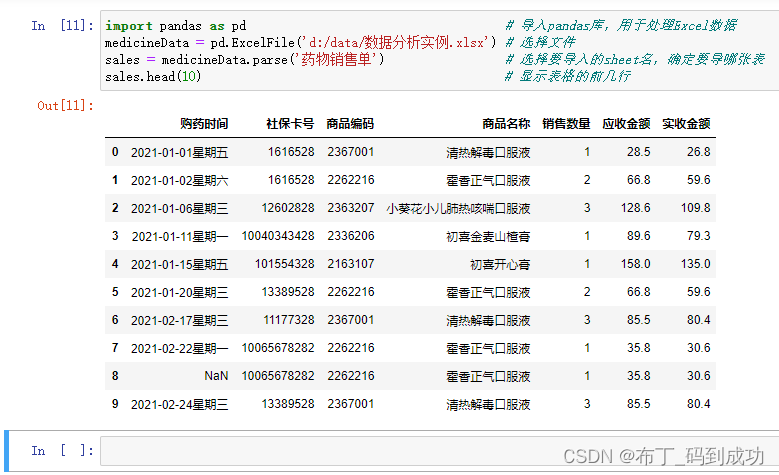
这里有用到Jupter Notebook来做演示。
1.1查看数据维度(行列)
shape可以查看该表中的行数和列数

2.2.查看数据格式
Dtypes是一个查看数据格式的函数,可以一次性查看数据表中所有数据的格式,也可以指定一列来单独查看。

1.3指定一列查看:

1.4查看统计信息
使用Describe函数可以查看统计信息计数,平均值,标准差,最小值,四分位数,中位数,最大值。
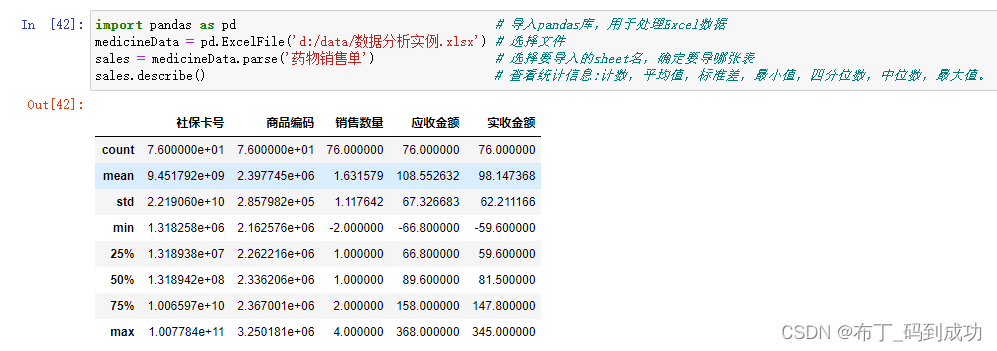
1.5查看列名称
使用columns函数查看列名称

二、数据清洗部分
2.1删除缺失值
Excel做法:

Python做法
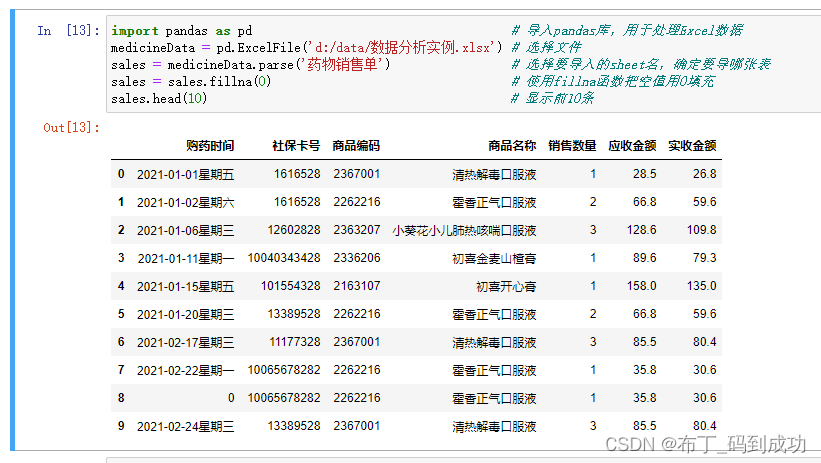
Python中处理空值的方法比较灵活,可以使用dropna函数用来删除数据表中包含空值的数据,也可以使用fillna函数对空值进行填充

2.2使用fillna函数把空值用0填充
2.3更改列名称
rename是更改列名称的函数,我们将来数据表中的应收金额列更改为应收金额(元)

2.4删除重复值
Excel做法:
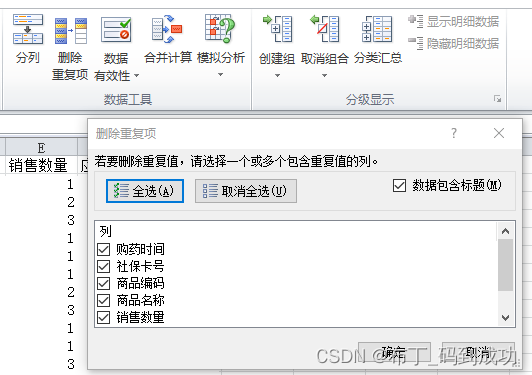
Python做法:
使用drop_duplicates()方法删除重复值

2.5分列
Excel做法:

Python做法:
sales_split = pd.DataFrame((x.split(' ') for x in sales['购药时间']), index = sales.index, columns = ['日期', '星期'])
如果你执行代码,会出现下面的错误,这是什么原因呢?
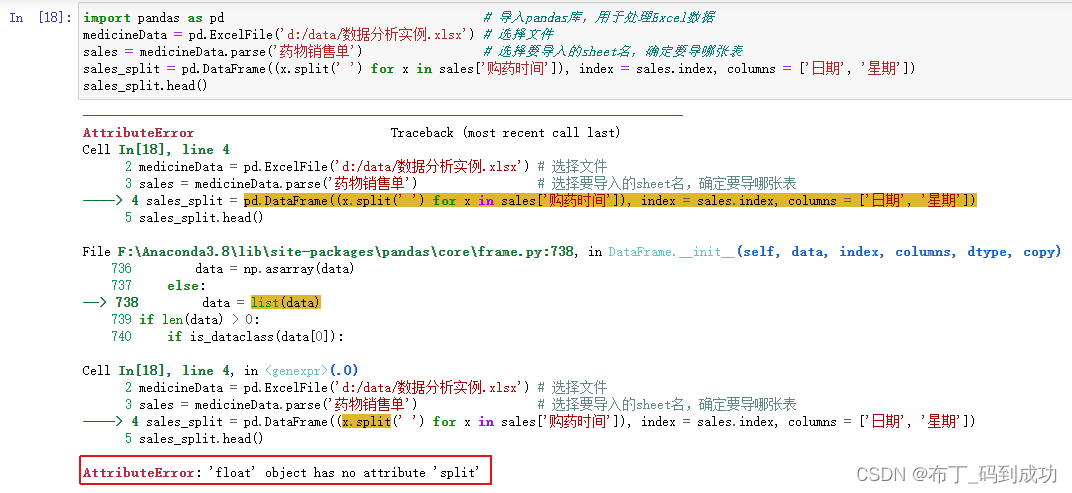
这里,我们需要注意的是缺失值会被当作浮点型 而split函数需要字符串类型,要先删除缺失值。

2.6将完成分列后的数据表与原数据表进行匹配
sales = pd.merge(sales, sales_split, right_index = True, left_index = True) 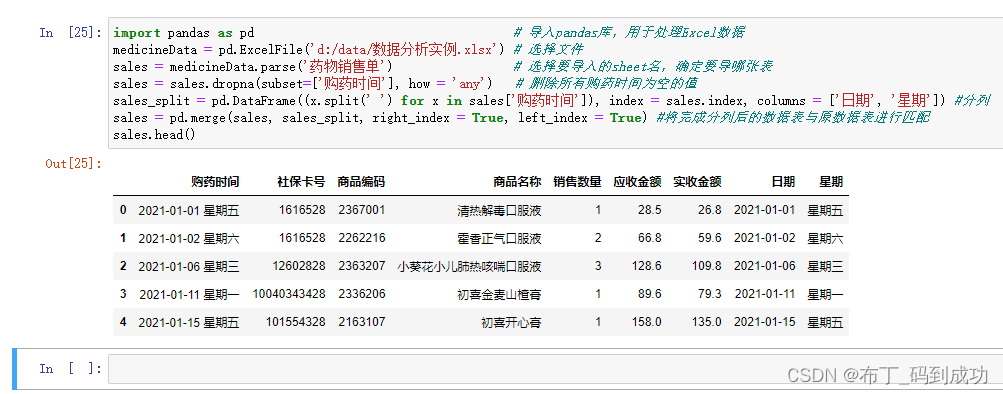
2.7删除列
Excel做法

Python做法:
Python中使用drop方法来删除列,下面两种方式都是可以的。
sales = sales.drop('购药时间', 1)
sales = sales.drop('购药时间', axis = 1, inplace = True)
使用drop删除了购药时间这一列

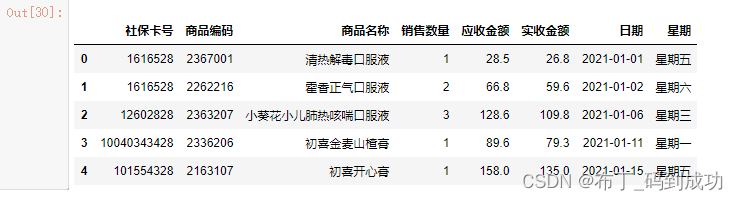
2.8修改日期格式
Excel做法:
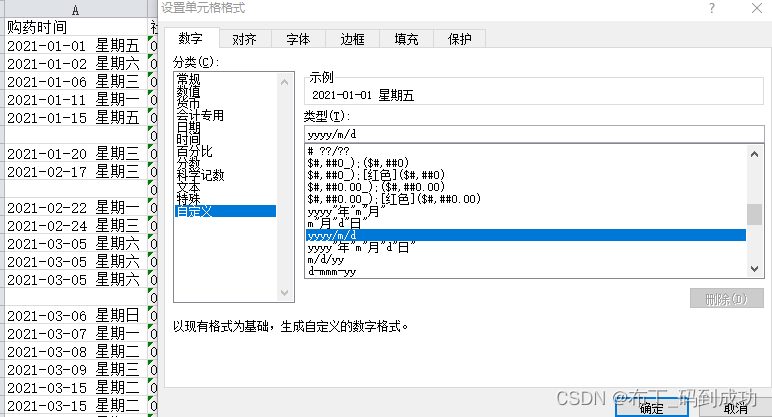
Python做法:
使用to_datetime函数进行修改
sales.loc[:,'日期'] = pd.to_datetime(sales.loc[:,'日期'], format = '%Y-%m-%d', errors = 'coerce')
format='%Y-%m-%d':指定输入日期字符串的格式为 %Y-%m-%d,其中 %Y 表示四位数年份, %m 表示两位数月份, %d 表示两位数日期
errors='coerce':当遇到无法解析的日期字符串时,强制将其设为缺失值 NaT,而不是抛出异常。
sales.loc 表示通过标签(label)定位DataFrame中的元素,冒号 : 表示选取所有行,'日期' 则指定选取的列名称为 日期 。最终返回的结果是一个由所有行组成的Series对象,其中索引为原DataFrame行索引,值为原DataFrame中该列的值。


2.9排序
By:按哪一列排序
ascending=True降序
ascending=Falses升序
sales = sales.sort_values(by = '日期', ascending = True)


2.10重命名行名
使用reset_index重命名行名

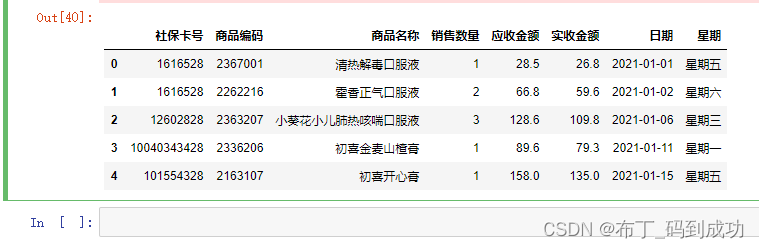 2.11 删除异常值
2.11 删除异常值
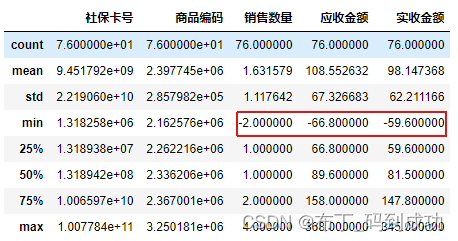
由于销量、应收金额、实收金额都不应为负,所以应该清除异常值。

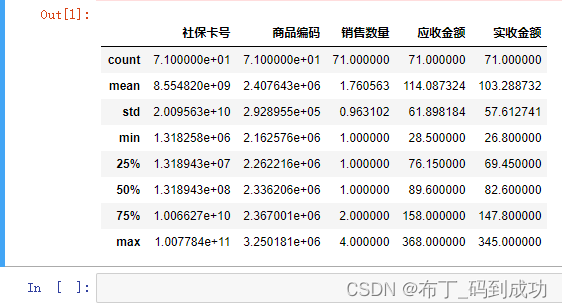
使用查询条件删除了异常值

