
热门标签
热门文章
- 1XShell 搭配 XManager 显示 Linux 图形化界面_xshell连接linux 打开图形化界面
- 2Python3 多线程
- 3这7本书都没有,还学什么Web安全?(附全套PDF)_白帽子讲web安全pdf下载
- 4vue2实现可拖拽甘特图(结合element-ui的gantt图)_vue 实现甘特图
- 5python 学习笔记(4)—— webdriver 自动化操作浏览器(基础操作)_python webdriver教程
- 6C语言 春天是鲜花的季节,水仙花就是其中最迷人的代表,数学上有个水仙花数,他是这样定义的:“水仙花数”是指一个三位数,它的各位数字的立方和等于其本身,比如:153=1^3+5^3+3^3。现在_春天是鲜花的季节,mm们也是花枝招展,水仙花就是其中最迷人的代表,数学上有个水仙
- 7AI助力智慧农业,基于DETR【DEtection TRansformer】模型开发构建田间作物场景下庄稼作物、杂草检测识别系统_杂草高度ai识别
- 8Ubuntu20.04开启/禁用ipv6_ubuntu服务器怎么允许ipv6访问
- 9我的AIGC部署实践02_aigc 本地端 部署
- 10日志审计与分析实验4-1(掌握Linux下安装、删除软件的方法)_centos7.9的dhcp-common可以卸载吗
当前位置: article > 正文
LLM大模型推理加速 vLLM;docker推理大模型;Qwen vLLM使用案例;模型生成速度吞吐量计算_vllm qwen
作者:我家自动化 | 2024-03-01 17:08:28
赞
踩
vllm qwen
参考:
https://github.com/vllm-project/vllm
https://zhuanlan.zhihu.com/p/645732302
https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html ##文档
1、vLLM
这里使用的cuda版本是11.4,tesla T4卡
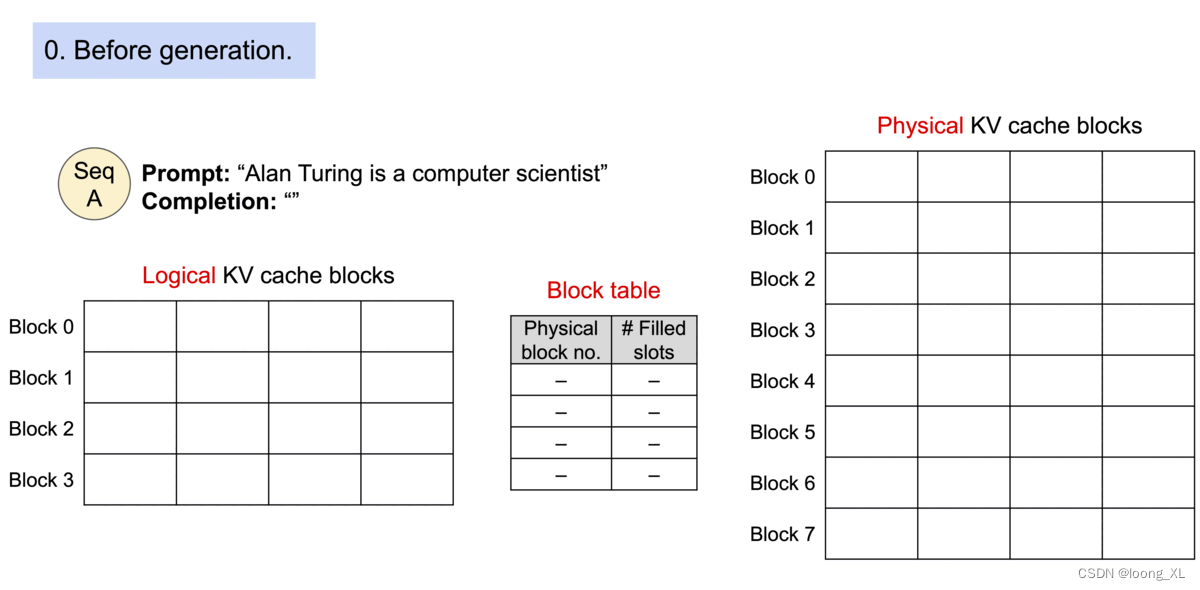
加速原理:
PagedAttention,主要是利用kv缓存
2、qwen测试使用:
注意:用最新的qwen 7B v1.1版本的话,vllm要升级到最新0.2.0才可以(https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary)
注意更改:–dtype=half
python -m vllm.entrypoints声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/175531
推荐阅读
相关标签

