
- 1xss漏洞的修复建议/方法_xss漏洞修复
- 2http 和 https 的区别?
- 3Vue3 - 获取 Proxy 对象代理中包裹的 “真实数据“,解决对象或数组打印后是 Proxy 对象无法拿到原始数据的问题(提供 2 种详细解决方案)_vue3proxy里面拿到数组
- 4cudnn环境变量配置_cudnn 环境变量
- 5基于卷积神经网络的多目标图像检测研究(一)_多类目标图像识别
- 6Android中怎么重新启动APP或系统_kotlin android重启当前app
- 7计算机网络——网络层(2)
- 8在虚拟机上安装centos7_pve安装centos7
- 9Vue3中的Proxy和Reflect_vue3 refs proxy
- 10前端食堂技术周刊第 109 期:Vue2 即将 EOL、CSS 年度回顾、11 月登陆 Web 平台的新功能、Oxlint、shadcn/ui 揭秘、TC39 faq_vue shadcn-ui
即插即用! | 国防科大联合慕尼黑工业大学提出新型解耦头 TSCODE: 助力目标检测器轻松涨点!
赞
踩

Title: Task-Specific Context Decoupling for Object Detection
Paper: https://arxiv.org/pdf/2303.01047v1.pdf
导读
相比于图像分类任务而言,目标检测还需要定位出图像中每个感兴趣目标所在的位置。以最流行的YOLOv5检测器为例,输出端一般有三个不同的感受野分支,每个分支均是一个耦合的头部(Coupled Head),直接一步到位预测出分类和回归任务,如下图所示:
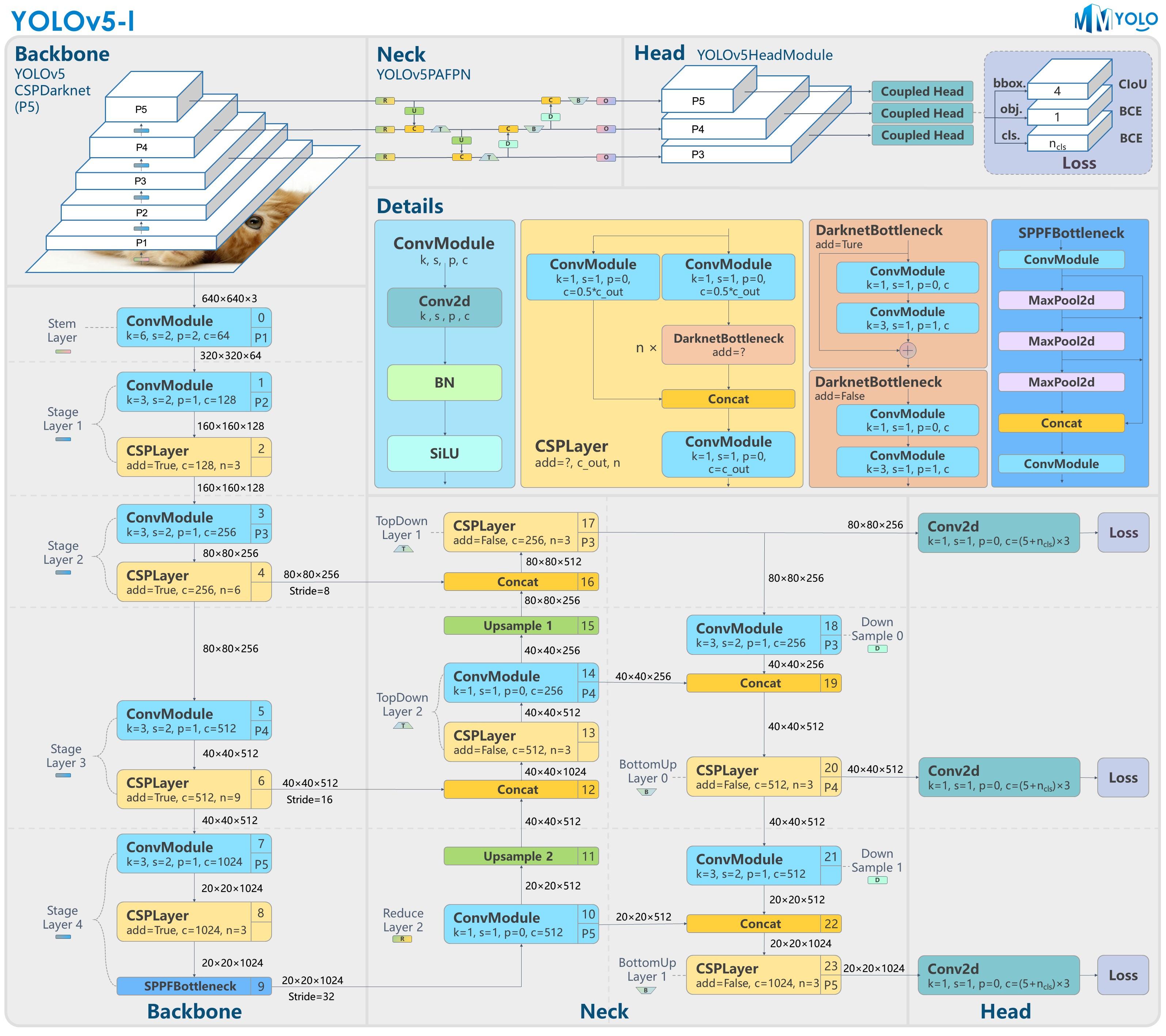
当然,这种用于分类和定位的共享头最早可追溯到来两阶段网络的Fast RCNN中,在早期的目标检测中几乎是标配。不过,正如TSD中指出的,两个子任务互相耦合其实是会极大的影响网络收敛的,它们之间存在一种空间不对齐(spatial misalignment)的问题,简单点理解就是两个子任务Focus的点并不同:
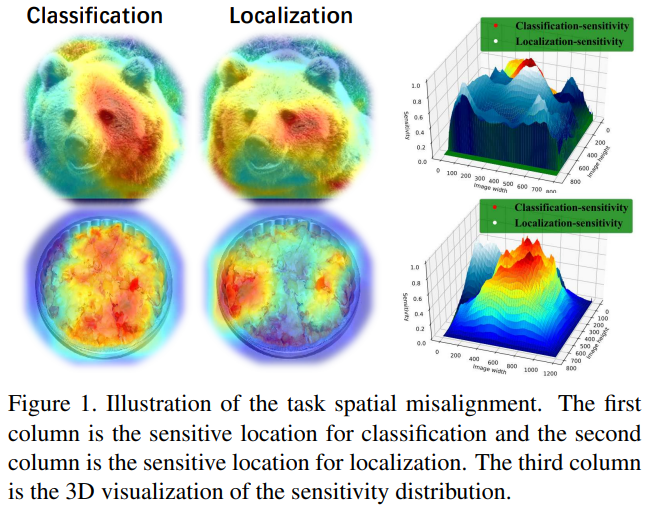
如图所示,某些显着区域的特征可能具有丰富的分类信息,而边界周围的特征可能擅长边界框回归。另外,还有Double-Head-Ext中也提到了类似的问题,作者同样通过实验分析并发现了一个有趣的事实,即两个头部结构对这两个子任务的偏好相反。根据文章的结论,作者提出全连接头可能更适合分类任务,而卷积头则更适合定位任务,这是因为fc-head比conv-head具备更高的空间敏感性,具有更强的区分完整对象和部分对象的能力,但对于回归整个对象并不稳健。因此,作者提出了如下图所示的解耦头方法:
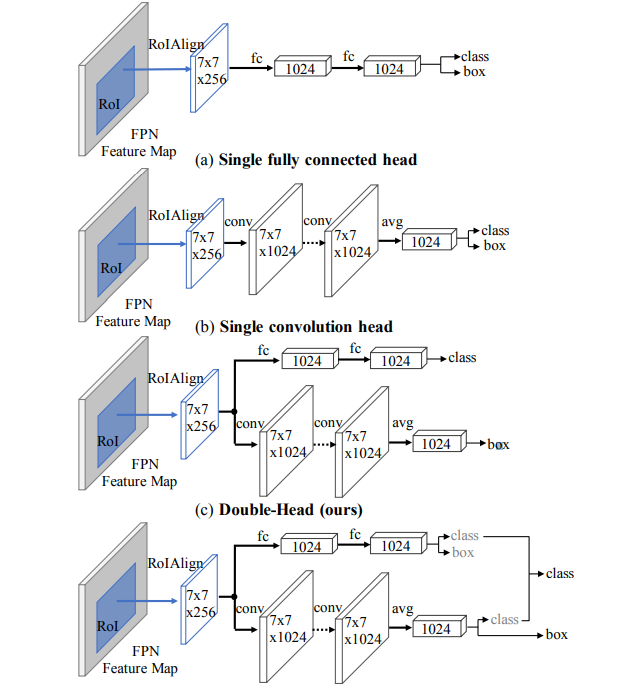
再接下来便是YOLOX直接把解耦头用上了,直接在YOLOv3的基础上提升了1.1个百分点的mAP:
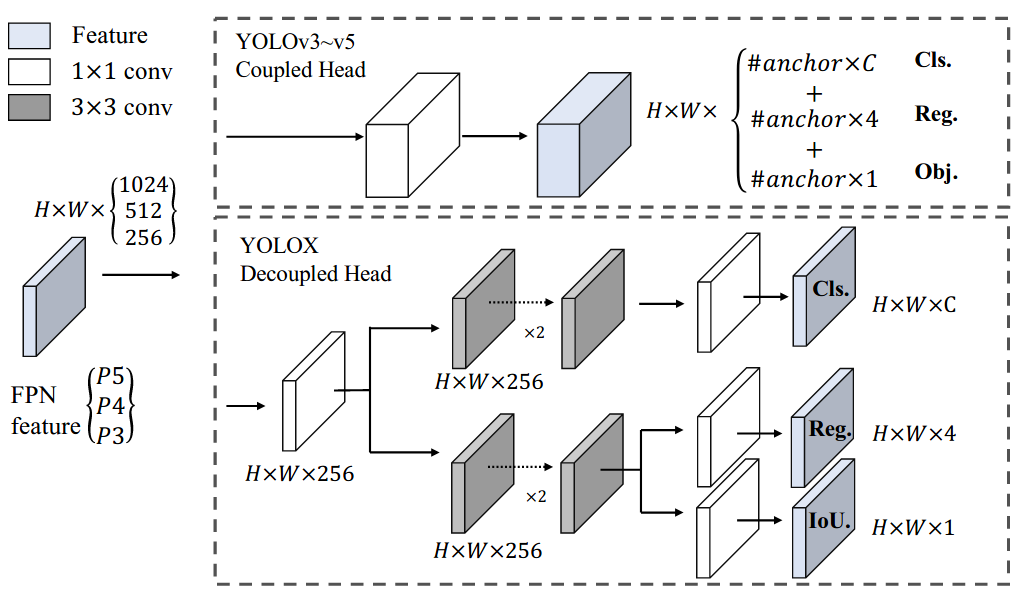
最后,便是主流的PPYOLO-E、YOLOv6甚至是YOLOv5官方新出版的YOLOv8均采用了这种范式。本文同样围绕这个方向提出了一种新颖的即插即用的特定于任务的上下文解耦头(Task-Specific COntext DEcoupling, TSCODE),通过进一步解开两个任务的特征编码来提升网络整体的性能。实验表明,所提方法可以有效的提升现有目标检测器的性能!
动机
可能不少小伙伴还在纳闷,检测头解耦,不就是拆成两个独立分支分别做分类和定位,这还能怎么水改?或者你以为是加点注意力去改善,但对不起,这次可能要让你失望了。如上所述,我们知道这两个子任务对特征上下文的偏好并不一致,其中,定位需要更多的边界感知特征来准确地回归边界框,而分类任务则需要更多的语义上下文信息。
而现有的方法通常都是利用解耦头来为每个任务学习不同的特征上下文。然而,不同head输入的特征却是相同的(没看懂的仔细观察上面的图片),作者认为这必然会导致分类和定位之间的仍然会有影响。于是,本文提倡对于分类任务应该生成空间粗糙但语义信息更强的的特征编码,而对于定位任务则需要提供包含更多边缘信息的高分辨率特征图,以更好地回归对象边界。笔者第一次看到的时候顿时有种“退一步海阔天空”的感觉。下面一起看看具体的实验分析:

图中显示的是NMS之前的结果,上半部分展示了利用原始FCOS推理结果,而下半部分则是插入TSCODE模块的效果。其中,与GT具有最高 IoU 的边界框以绿色框表示,而具有最高类别分数的前 3 个边界框以其他颜色标记。从图中可以明显的看出,原始的检测头机制存在明显的竞争关系,即具有最佳IoU(图中绿色框)的边界框反而具有较低的分类置信度,而具有最佳类别得分(图中蓝色框)的边界框却没有很好的贴齐目标,这岂不是乱了?
另一方面,我们可以观察到,加入TSCODE之后,图片瞬间变得清晰多了,即类别得分高的其目标框回归的也约贴近原始GT。这个方法也很简单,今天主要介绍下思想,下面快速的带大家过一遍,Let's go!
方法

一图胜千言,其实看图就知道作者在做什么了,但是遵循国际惯例,我们还是简单的讲解下凑下篇幅。
分类和定位是目标检测中两个高度相关但互相“矛盾”的任务。对于每个对象,分类属于粗粒度的戏细分任务,需要更丰富的语义上下文,而定位则相当细粒度,需要能提供更多丰富细节的边界信息。这一点不难理解,分类通常需要站在全局的角度去审时度势,这也是为什么大多数分类任务会采用全局上下文池化(Global Average Pooling, GAP)的原因。
如上所述,诸如YOLOX等常规的解耦头设置中,分类和回归分支都是共享来自Neck输出的相同输入特征。虽然它们使用单独的参数进行学习,以便为每个任务提供不同的特征上下文,即参数解耦,但这种简单的设计并不能从本质上解决问题。这是因为不同的输入特征其涵盖的语义和空间细节信息是并相同的。通常来说,低层特征具备更丰富的细节信息而缺乏语义信息,而高层特征则与之相反,这必然不能最大限度的发挥这种“解耦头”的优势。
如图所示,TSCODE整体的网络架构与常规的单阶段目标检测器并无多大差异,都是包含Backbone、Neck和Head。其中骨干网络充当特征提取器从输入图像生成多尺度特征图。随后通过类似于FPN或BiFPN之类的特征金字塔结构进行深、浅层的特征融合,最后再分别输入到头部进行相应的解码输出。需要注意的是,这里TSCODE接收来自中间三个层级输出的特征图,并生成用于分类和定位的解耦特征图。更重要的是,TSCODE是即插即用的,可以很容易地集成到大多数流行的检测器中,无论是Anchor-based还是Anchor-free。
至于为什么会选择中间三层特征,笔者猜想这是因为这三层在语义和细节信息的获取上是均衡的,严谨一点当然还是要做下消融实验验证下。下面一起看下这两个分支的具体操作流程。
Semantic Context Encoding for Classification
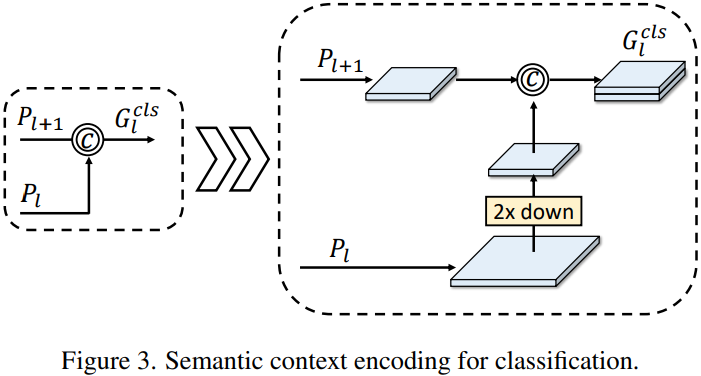
正如我们前面所提及的,分类任务需要更丰富的上下文语义信息。而深层特征便是具备这一特性,因此,一种自然而然的想法便是融合来自深层的特征,将丰富的语义信息嵌入到当前特征图中。
Detail-Preserving Encoding for Localization

另一方面,回归任务则需要更丰富的空间细节信息,这一点浅层特征能够提供所需要的。因此,很容易想到的一点便是将浅层的信息引导回流至下一层特征图中。一般而言,当前层级的特征以两个相邻层特征相关度较高,而其它层级的输出特征由于跨度太大可能会导致“语义鸿沟”(
Semantic Gap),因此通常都会优先考虑相邻层的特征融合。作者此处便借鉴了U-Net的思想完成了一次改造。
效果
Ablation Studies

如表1所示,仅应用
SCE可将基线模型的AP提高 0.6∼0.9 点,同时将FLOPs降低 9%。当同时应用SCE和DPE时可以进一步提升模型性能,这说明两种机制本质上是互相促进的。
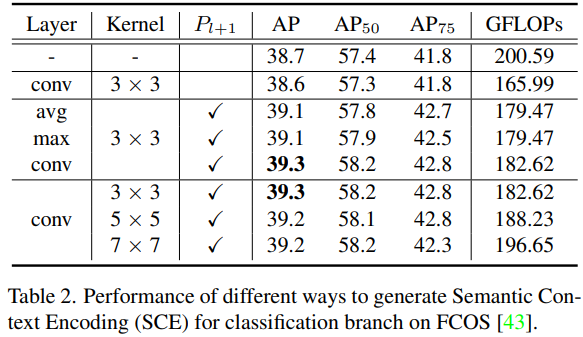
表2展示了
SCE模块的消融实验,其表明了下采样方式采用 3 × 3 3\times3 3×3的步长卷积能取得最佳性能。

表3展示了
DPE模块的消融实验,可以看出融合相邻层特征能获取最优的结果,并不是“越多越好”!
Generality to Different Detectors


总结
本文深入的探讨了目标检测任务中分类和定位分支之间的"冲突"原因,并提出了一种新颖的特定于任务的上下文解耦头机制来极大的缓解这种现象。TSCODE通过语义上下文编码和用于保留局部细节编码两种高效的设计将两个任务的语义上下文进行解耦,分别引入了更丰富的语义信息和用于定位的更多边缘信息的特征。最后,通过大量的实验验证表明了所提方法可以轻松插入各大主流的目标检测器小痛涨点!
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!
同时欢迎添加小编微信: cv_huber,备注CSDN,加入官方学术|技术|招聘交流群,一起探讨更多有趣的话题!

