
- 1iptables INPUT设置_iptables -a input
- 2使用Django+Pytest搭建在线自动化测试平台
- 3自考计算机应用基础停考,2020年最新汇总,全国自考停考专业!
- 4人工智能(NLP)常用算法总结(面试准备)_nlp十大经典算法
- 5Pyglet控件的批处理参数batch和分组参数group简析_batch / de-batch rhapsody控件
- 6Linux C 串口编程_linux c串口编程
- 7MVP:如何组织Presentation层_如何设计mvp中的presentation层
- 8教你三种方法,用Python制作出版级论文配图绘制_python绘制论文图
- 92024无参考图像的清晰度评价方法_quality-aware pre-trained models for blind image q
- 10CH10-HarmonyOS原子化服务_原子服务
什么是深度学习?_深度学习的提出
赞
踩

目录
简介
深度学习是在20世纪80年代被提出来的,主要是由加拿大的计算机科学家Geoffrey Hinton、Yoshua Bengio、Yann LeCun等人发起的。Geoffrey Hinton等人在经过多年的研究和实践之后,提出了一种基于神经网络的深度学习方法,通过多层的神经网络模型来实现更加准确、高效的机器学习,其重点在于使用多层神经网络模型来学习输入数据的表示,并从中提取出高层次的特征表达。它可以处理复杂的非线性关系,并且能够自动发现数据中的模式和规律,从而实现更准确的预测和识别。深度学习在图像识别、自然语言处理、语音识别以及推荐系统等领域中,具有广泛的应用。
深度学习的核心组成部分是神经网络,其包含输入层、隐藏层和输出层三个部分。隐藏层中的节点通过复杂的数学计算来处理输入的数据,以便更好地进行分类和预测。深度学习使用反向传播算法来训练神经网络,在训练过程中,通过对输出结果和真实结果之间的误差进行反向传播来更新神经网络中的权重和偏差。
深度学习还有许多强大的技术,例如卷积神经网络(CNNs)、循环神经网络(RNNs)和生成式对抗网络(GANs)等。这些技术可以处理各种类型的数据,包括图像、音频、文本、时间序列数据等,并为各种任务提供了出色的结果。
与传统机器学习方法相比,深度学习具有以下优势:
-
自动化特征提取:传统机器学习需要手动选择和提取特征,而深度学习可以自动从原始数据中学习到复杂的特征。
-
高精度预测:深度学习能够处理大量的数据,可以通过训练更加准确的模型进行分类或预测。
-
处理多维数据:深度学习可以处理不同类型的数据,包括图像、语音、文本等。
-
支持端到端学习:深度学习可以直接从原始的数据输入到输出,不需要中间的人工干预。
总之,深度学习是一种强大的机器学习技术,可以自动从大量的数据中学习模式和规律,从而实现各种任务的高准确性和高效率。随着硬件和算法的不断改进,深度学习在未来也将继续发挥重要的作用。

深度学习的由来
深度学习的由来可以追溯到人工神经网络的发展历史。20世纪50年代,人工神经网络被提出作为一种基于大脑神经元的计算模型。然而,在当时,由于计算资源和数据的缺乏,人工神经网络并没有得到广泛的应用和发展。
20世纪40年代至50年代,神经科学家们开始探索人脑是如何处理视觉信息的。在这期间,特立斯(McCulloch)和皮茨(Pitts)提出了一种模型,称为“M-P神经元模型”,它是第一个计算神经元的数学模型。这个模型启发了人们去探索人工神经网络的构建和应用。
然而,由于当时的计算机性能有限,人工神经网络的应用发展缓慢。直到20世纪80年代以后,随着计算机硬件和算法的进步,人工神经网络重新受到关注。1986年,机器学习研究者鲁曼哈特、海因里希和威廉姆斯提出了一种新型的人工神经网络,称为“多层感知器”(Multi-Layer Perceptron,MLP),该网络中的神经元不再是简单的线性模型,而是引入了非线性的激活函数,在处理非线性问题时具有更强的表达能力。
随后,1989年,加拿大多伦多大学的Geoffrey Hinton和他的学生Rumelhart在《Nature》杂志上发表了一篇名为《深度学习》的论文,提出了一种新型的多层神经网络模型,称为“深度置信网络”(Deep Belief Networks,DBN)。这种模型通过逐层训练,不断提取更高层次的特征表达,从而达到更高的分类性能。这个时候,深度学习的概念开始被广泛认知和关注,并引领了人工智能飞速发展的新时代。
从此,深度学习开始在计算机视觉、自然语言处理、语音识别等领域得到广泛应用,成为人工智能领域的重要研究方向之一。
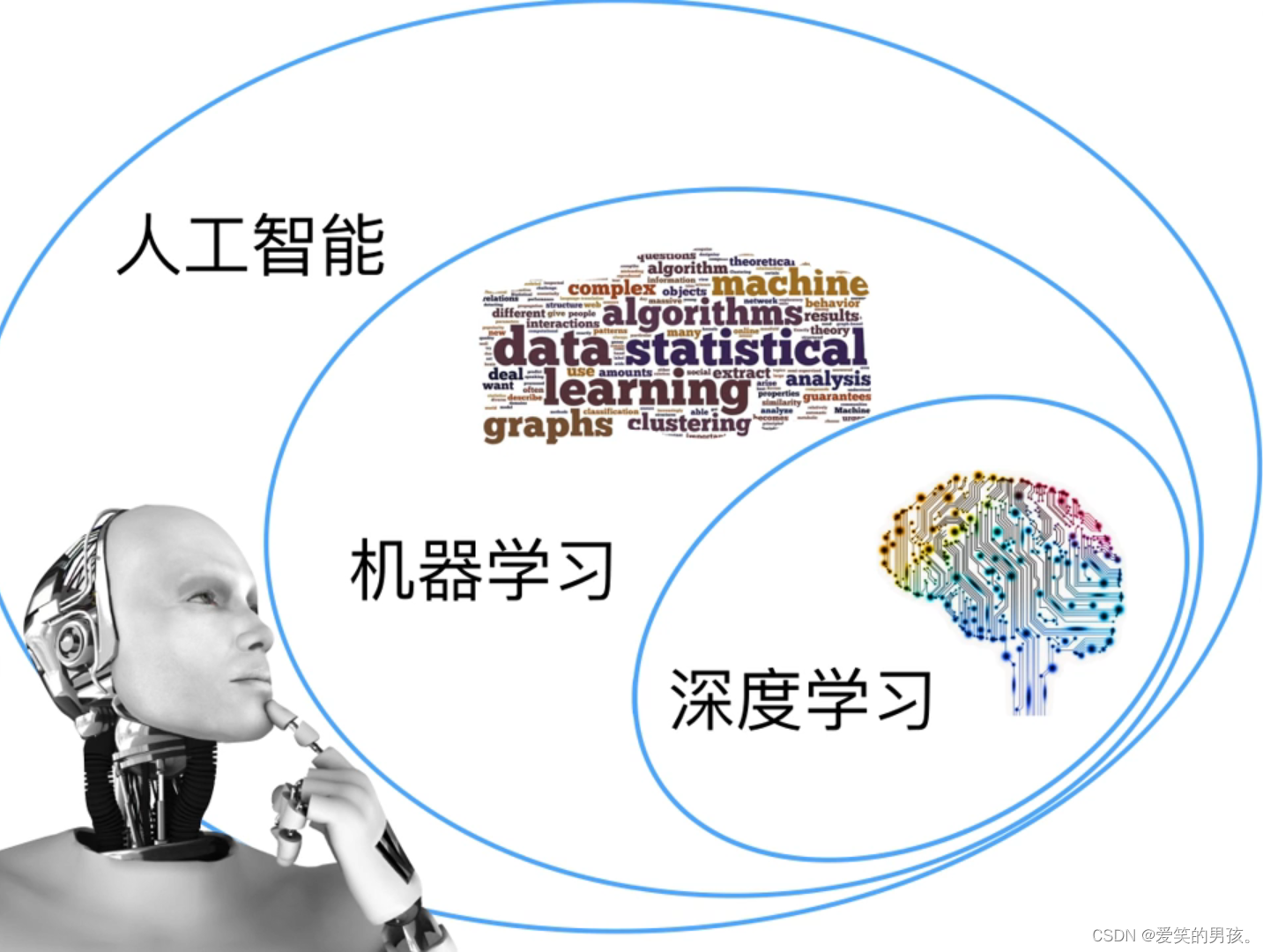
深度学习未来的趋势
深度学习在未来的发展趋势将会继续扩展和深化,特别是在以下方面:
-
自动化模型设计:深度学习模型的设计将越来越自动化,包括神经网络结构的自动搜索和自动调整参数。
-
大规模分布式训练:分布式训练将成为深度学习训练的主流方式,加速训练速度和提高模型参数的估计精度。
-
多模态和多任务学习:深度学习将扩展到对多个模态和多个任务的学习,例如视觉处理、语音识别、自然语言处理以及推荐系统等。
-
解释性深度学习:为了提高深度学习的可解释性,将出现一系列新的深度学习方法,以更好地理解模型的决策过程和输出结果的可信度。
-
强化学习:强化学习将成为深度学习的重要分支,用于解决更复杂的决策问题,例如游戏策略、自动驾驶和机器人控制等。
-
联邦学习:联邦学习将允许多个参与者共享数据,从而学习更具代表性和普遍性的模型,同时保护数据隐私和安全。
总的来说,深度学习将继续在解决现实世界的问题方面发挥重要作用,并且随着技术的不断进步,我们有望看到更多创新和发展。
总结
Python扛起了人工智能的大旗
Python YYDS

