
- 1动态控制GridView的每一列的宽度_webform gridview 每一列宽度
- 2华为新设备升级示例
- 3iOS经典讲解之实现上拉刷新和下拉刷新
- 4基于SSH+MySQL的食品销售购物商城网站设计与实现_用ssh框架实现网上商城网站
- 5安卓苹果TikTok中国大陆使用详细教程(建议收藏)_苹果手机tiktok
- 6nginx部署vue项目_nginx部署vue项目后端地址
- 7Java循环与数组_java 循环建立数组
- 8AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.02.10-2024.02.15
- 9Artificial Intelligence for the Metaverse: A Survey
- 10Docker Container(容器)_container 容器
MySQL——索引详解_mysql索引
赞
踩
目录
一、为什么要有索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
二、什么是索引?
索引在MySQL中也叫是一种“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能 非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。 索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。 索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
三、索引的原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段…这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?按照搜索树的模型,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
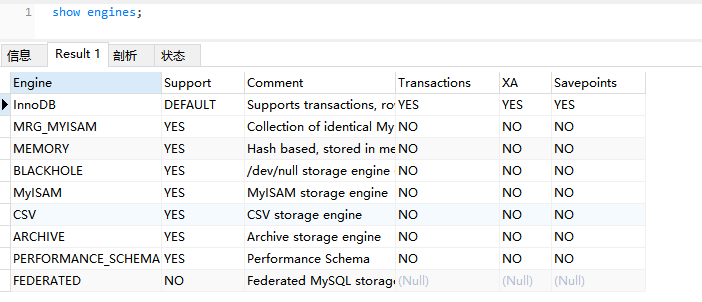
四、MySQL的存储引擎
- #查询索引
- show engines;

各存储引擎的特性如下表所示:
其中最常见的两种存储引擎是MyISAM和InnoDB
| 特点 | InnoDB | MyIsam | Memory | Archive | BDB |
|---|---|---|---|---|---|
| 存储限制 | 64TB | 没有 | 有 | 没有 | 没有 |
| 事务安全 | 支持 | 支持 | |||
| 锁机制 | 行锁 | 表锁 | 表锁 | 行锁 | 页锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 | |
| 哈希索引 | 支持 | 支持 | |||
| 全文索引 | 支持 | ||||
| 集群索引 | 支持 | ||||
| 数据缓存 | 支持 | 支持 | |||
| 索引缓存 | 支持 | 支持 | 支持 | ||
| 数据可压缩 | 支持 | 支持 | |||
| 空间使用 | 高 | 低 | N/A | 非常低 | 低 |
| 内存使用 | 高 | 低 | 中等 | 低 | 低 |
| 批量插入的速度 | 低 | 高 | 高 | 非常高 | 高 |
| 支持外键 | 支持 |
五、索引的数据结构
MySQL主要用到两种结构:B+ Tree索引和Hash索引:InnoDB存储引擎默认是B+Tree索引,Memory 存储引擎默认Hash索引。
MySQL中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是Memory表的默认索引类型,Memory表也可以使用B+Tree索引。Hash索引把数据以hash形式组织起来,因此当查找某一条记录的时候,速度非常快。但是因为hash结构,每个键只对应一个值,而且是散列的方式分布。所以它并不支持范围查找和排序等功能。B+Tree是mysql使用最频繁的一个索引数据结构,是InnoDB和MyIsam存储引擎模式的索引类型。相对Hash索引,B+Tree在查找单条记录的速度比不上Hash索引,但是因为更适合排序等操作,所以它更受欢迎。毕竟不可能只对数据库进行单条记录的操作。
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的二节点间有指针相关连接,在B+树上的常规检索,从根节点到叶子节点的搜索效率基本相当,不会出现大幅波动,而且基于索引的顺序扫描时,也可以利用双向指针快速左右移动,效率非常高。因此B+树索引被广泛应用于数据库、文件系统等场景。
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
两种索引的对比如下:
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值,前提是键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,知道找到对应的数据。
如果是范围查询检索,这时候哈徐索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;哈希索引也没办法利用索引完成排序,以及like这样的部分模糊查询;哈希索引也不支持多列联合索引的最左匹配规则。
B+树索引的关键字检索效率比较平均,不像B树那样波动大,在有大量重复键值情况下,哈希索引的效率也是极低的,因此存在哈希碰撞问题。
对比小结:
- hash类型的索引:查询单条快,范围查询慢
- btree类型的索引:b+树,层数越多,数据量指数级增长(InnoDB默认支持)
六、聚簇和非聚簇索引
mysql的索引类型跟存储引擎是相关的,InnoDB存储引擎数据文件跟索引文件全部放在ibd文件中,而MyIsam的数据文件放在myd文件中,索引放在myi文件中,其实区分聚簇索引和非聚簇索引非常简单,只要判断数据跟索引是否存储在一起就可以了。

InnoDB存储引擎在进行数据插入的时候,数据必须要跟索引放在一起,如果有主键就使用主键,没有主键就使用唯一键,没有唯一键就使用6字节的rowid,因此跟数据绑定在一起的就是聚簇索引,而为了避免数据冗余存储,其他的索引的叶子节点中存储的都是聚簇索引的key值,因此InnoDB中既有聚簇索引也有非聚簇索引,而MyIsam中只有非聚簇索引。
七、索引的设计原则
在进行索引设计的时候,应该保证索引字段占用的空间越小越好,这只是一个大的方向,还有一些细节点需要注意下:
- 适合索引的列是出现在where字句中的列,或者连接子句中指定的列
- 基数较小的表,索引效果差,没必要创建索引
- 在选择索引列的时候,越短越好,可以指定某些列的一部分,没必要用全部字段的值
- 不要给表中的每一个字段都创建索引,并不是索引越多越好
- 定义有外键的数据列一定要创建索引
- 更新频繁的字段不要有索引
- 创建索引的列不要过多,可以创建组合索引,但是组合索引的列的个数不建议太多
- 大文本、大对象不要创建索引

