
- 1ChatGLM本地部署(支持中英文,超级好用)!_chatgpt本地部署
- 2HarmonyOS鸿蒙基于Java开发: 基于Java UI实现的Java卡片开发指导_鸿蒙ets 实现java放射
- 3【JavaBigDecimal练习】利用BigDecimal精确计算欧拉数_用java求小数点后1000位
- 4Windows本地部署ChatGLM3-6B模型_chatglm3-6b 下载
- 5网络安全 kali 渗透学习 web 渗透入门 kali 系统的安装和使用_kaliweb渗透
- 6elementui中的el-input回显成功后input框不能进行编辑的问题_回显后的值el-input 无法输入
- 7深度学习交通标志识别项目
- 8初学vue,模仿个静态网站
- 9如何利用PS中的钢笔抠图
- 10【问题记录】关于vue-cli项目build后,index.html无法在浏览器打开_vue3本地build打开html接口调不通
深入理解Linux网络——内核是如何接收到网络包的_内核跟踪网络层
赞
踩
系列文章:
- 深入理解Linux网络——内核是如何接收到网络包的
- 深入理解Linux网络——内核与用户进程协作之同步阻塞方案(BIO)
- 深入理解Linux网络——内核与用户进程协作之多路复用方案(epoll)
- 深入理解Linux网络——内核是如何发送网络包的
- 深入理解Linux网络——本机网络IO
- 深入理解Linux网络——TCP连接建立过程(三次握手源码详解)
- 深入理解Linux网络——TCP连接的开销
一、相关实际问题
- RingBuffer是什么,为什么会丢包
- 网络相关的硬中断、软中断是什么
- Linux里的ksoftirqd内核线程是干什么的
- 为什么网卡开启多队列能提升网络性能
- tcpdump是如何工作的
- iptable/netfilter是在哪一层实现的
- tcpdump能否抓到被iptable封禁的包
- 网络接收过程中如何查看CPU开销
- DPDK是什么
二、数据是如何从网卡到协议栈的
1、Linux网络收包总览
Linux内核以及网卡驱动主要实现链路层、网络层和传输层这三层上的功能,内核为更上面的应用层提供socket接口来支持用户进程访问。
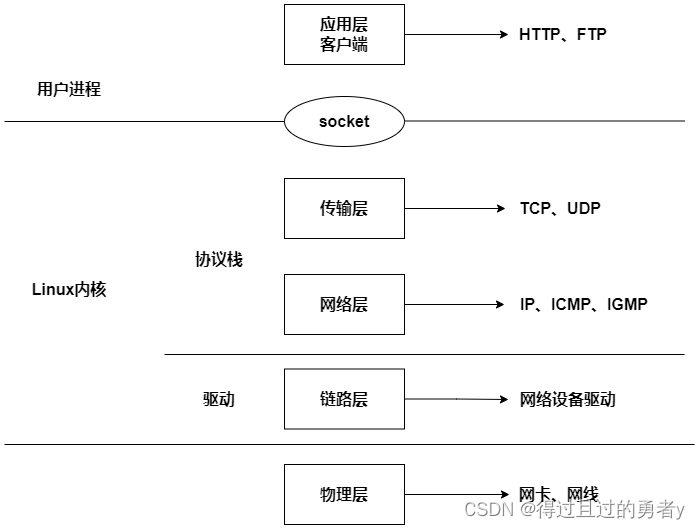
内核和网络设备驱动是通过中断的方式来处理的。当设备上有数据达到时,会给CPU的相关引脚触发一个电压变化,以通知CPU来处理数据(硬中断)。对于网络模块来说,由于处理过程比较复杂和耗时,如果在中断函数中完成所有的处理,将会导致中断处理函数(优先级过高)过度占用CPU,使得CPU无法响应其他设备,如鼠标和键盘的消息。
因此Linux中断处理函数是分上半部和下半部的。上半部只进行最简单的工作,快速处理然后释放CPU,接着CPU就可以允许其它中断进来。将剩下的绝大部分的工作都放到下部分,可以慢慢地处理。2.4以后的Linux内核版本采用的下半部实现方式是软中断,由ksoftirqd内核线程全权处理。
硬中断是通过给CPU物理引脚施加电压变化实现的,而软中断是通过给内存中的一个变量赋予二进制值以标记有软中断发生。
软中断是Linux内核用于处理一些不能在硬中断上下文中完成的异步任务的机制。硬中断处理程序(interrupt handlers)通常需要尽可能快地执行并返回,以便CPU可以继续执行其他任务。因此,如果硬中断处理程序需要进行一些可能会花费较多时间的操作(例如,处理网络数据包或磁盘I/O),它通常会把这些操作安排到一个软中断中,然后快速返回。
总体工作步骤:
- 数据帧从外部网络到达网卡
- 网卡收到数据后以DMA的方式将帧写到内存
- 硬中断通知CPU
- CPU收到中断请求后调用网络设备驱动注册的中断处理函数,简单处理后发出软中断请求,然后迅速释放CPU
- ksoftirqd内核线程检测到软中断请求到达,调用poll(网卡驱动程序注册的函数)开始轮询收包
- 数据帧从RingBuffer上摘下来保存为一个skb(struct sk_buff对象的简称,是Linux网络模块中的核心数据结构体,各个层用到的数据包都是存在这个结构体里的)
- 将包交由各级协议层处理,处理完后放到socket的接收队列
- 内核唤醒用户进程
2、Linux启动
Linux驱动、内核协议栈等模块在能够接受网卡数据包之前,要做很多的准备工作才行。比如提前创建好ksoftirqd内核线程,注册好各个协议对应的处理函数,初始化网卡设备子系统并启动网卡等。只有这些都准备好后才能真正开始接收数据包。
1)创建ksotfirqd内核线程
Linux的软中断都是在专门的内核线程ksoftirqd中进行的,该线程的数量不是1个,而是N个,N即对应机器的核数。
在Linux内核中,软中断可以在几种不同的上下文中被执行:在硬中断处理程序返回后,或者在内核退出到用户空间之前。然而,如果CPU在处理用户空间的任务,或者在处理某些不能被中断的内核任务,那么软中断的处理可能会被推迟,在这种情况下,软中断的处理会被交给ksoftirqd。在大多数系统中,ksoftirqd线程大部分时间都处于休眠状态,因为大多数软中断都能在其他上下文中立即被处理。但是,在高负载的系统中,ksoftirqd线程可能会变得非常活跃,以帮助处理积压的软中断。
ksoftirqd是一个优先级比较低的内核线程。当系统中有其它更高优先级的任务(例如用户空间的任务或者其它内核任务)需要运行时,ksoftirqd可能会被调度器放在一边,等待CPU空闲。只有当CPU有足够的空闲时间,或者当软中断的处理不能再被推迟时,ksoftirqd才会被调度运行。这种设计可以确保CPU的时间被优先用于处理用户空间的任务和高优先级的内核任务,同时还能确保软中断最终会被处理。也就是说,ksoftirqd提供了一种机制,用于在CPU有空闲时间时处理软中断,或者在软中断的处理不能再被推迟时处理软中断。
系统初始化的时候在kernel/smpboot.c中调用了smpboot_register_percpu_thread,该函数会进一步执行到spawn_ksoftirqd(位于kernel/ksoftirqd.c)来创建softirqd线程。
- ksoftirqd会在一个循环中运行,这个循环检查softirq_pending变量,看是否有软中断需要处理。
- 如果没有软中断需要处理(softirq_pending是0),那么ksoftirqd就会通过调用schedule()函数将自己置于休眠状态。在这种状态下,ksoftirqd并不消耗CPU时间。
- 当有新的软中断被安排时,ksoftirqd会被唤醒。这通常是通过设置softirq_pending变量并唤醒ksoftirqd来实现的。
软中断不仅有网络软中断,还有其他类型。Linux内核在interrupt.h中定义了所有的软中断类型,其中网络相关的是NET_TX_SOFTIRQ和NET_RX_SOFTIRQ。
- NET_RX_SOFTIRQ:此软中断主要用于处理网络设备的接收(Receive)部分
- NET_TX_SOFTIRQ:此软中断用于处理网络设备的发送(Transmit)部分
将网络处理任务划分为接收和发送两部分,然后使用不同的软中断来处理的设计,有利于提高网络处理的效率。尤其在多核处理器系统中,不同的软中断可以在不同的CPU核心上并行运行,从而进一步提高处理速度。
2)网络子系统初始化
在网络子系统的初始化过程中,会为每个CPU初始化softnet_data,也会为RX_SOFTIRQ和TX_SOFTIRQ注册处理函数。
struct softnet_data
{
struct Qdisc *output_queue;
struct Qdisc **output_queue_tailp;
struct list_head poll_list; // 一个设备列表,存储的是需要被轮询处理的设备。硬中断处理程序会将设备添加到这个列表,然后软中断处理程序会轮询这个列表,处理每个设备的接收队列
struct sk_buff *completion_queue; // 一个skb列表,用于存储已经处理但尚未释放的数据包。软中断处理程序在处理完数据包后,会将数据包添加到这个队列,然后在适当的时候释放这些数据包
struct sk_buff_head process_queue;
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
在Linux网络子系统中,softnet_data数据结构包含了各种网络处理需要的数据和状态信息,其中包括接收队列和发送队列。为了提高多核或多处理器系统的性能,操作系统会为每个CPU创建一个这样的数据结构。在处理网络数据包时,各个CPU可以根据它们各自的softnet_data数据结构中的接收队列和发送队列来独立进行处理。
-
为软中断注册处理函数使用方法open_softirq。NET_TX_SOFTIRQ的处理函数为net_tx_action,NET_RX_SOFTIRQ的处理函数为net_rx_action。具体实现方式是将软中断和处理函数的对应关系记录到softirq_vec数组,后续ksoftirqd线程收到软中断的时候就会使用这个变量来找到对应的处理函数。
void open_softirq(int nr, void (*action)(struct softirq_action *) { softirq_vec[nr].action = action; }- 1
- 2
- 3
- 4
Linux内核通过调用subsys_initcall来初始化各个子系统,这里是要初始化网络子系统(subsys_initcall(net_dev_init)),会执行net_dev_init函数。
3)协议栈注册
内核实现了网络层的IP协议和传输层的TCP、UDP协议,这些协议对应的实现函数分别是ip_rcv()、tcp_v4_rcv()和udp_rcv()。
Linux内核中通过fs_initcall(文件系统初始化,类似subsys_initcall,也是初始化模块的入口)来调用inet_init进行网络协议栈的注册。inet_init将上述的协议实现函数注册到inet_protos(注册udp_rcv函数和tcp_v4_rcv函数,是一个数组)和ptype_base(注册ip_rcv函数,是一个哈希表)数据结构中。
即协议栈注册后后,inet_protos中记录着UDP、TCP的处理函数地址,ptype_base存储着ip_rcv函数的处理地址。软中断中会通过ptype_base找到ip_rcv函数地址,进而将IP包正确送到ip_rcv()中执行,ip_rcv()会通过inet_protos找到TCP或UDP的处理函数,再把包转发给udp_rcv()或tcp_v4_rcv()函数。
如果去看ip_rcv()和udp_rcv()等函数的代码,能看到很多协议的处理过程,如ip_rcv中会处理iptable netfilter过滤,udp_rcv中会判断socket接收队列是否满了,对应的相关内核参数是net.core.rmem_max和net.core.rmem_default。
4)网卡驱动初始化
每一个驱动程序(不仅仅包括网卡驱动程序)会使用module_init向内核注册一个初始化函数,当驱动程序被加载时,内核会调用这个函数。以igb网卡驱动程序为例,其初始化函数为
static int __init igb_init_module(void)
{
......
ret = pci_register_driver(&igb_drvier);
return ret;
}
- 1
- 2
- 3
- 4
- 5
- 6
通过module_init(igb_init_module),当驱动的pci_register_driver执行完成后内核就知道了该驱动的相关信息,如igb网卡驱动的igb_driver_name和igb_probe函数地址等。当网卡设备被识别以后,内核会调用其驱动的probe方法让设备处于ready状态,具体流程如下:
- 内核调用驱动probe
- 网卡驱动获取网卡MAC地址
- 网卡驱动DMA初始化
- 注册ethtool实现函数(ethtool命令之所以能够查看网卡收发包统计、修改自适应模式、调整RX队列大小和数量,是因为网卡驱动提供了相应的方法)
- 注册net_device_ops、netdev等变量(igb_device_ops变量中包含igb_open等函数,在网卡启动时会被调用)
- NAPI初始化,注册poll函数
当一个网络设备(例如以太网卡)被系统识别并初始化时,设备驱动程序会为设备的每个接收队列创建一个napi_struct实例。在驱动程序中,通常会有一段类似以下的代码来创建和初始化napi_struct实例:
struct napi_struct *napi; // 分配napi_struct实例 napi = kzalloc(sizeof(*napi), GFP_KERNEL); // 初始化napi_struct实例 netif_napi_add(dev, napi, my_poll_function, WEIGHT); // dev是网络设备,my_poll_function是设备驱动定义的轮询函数,WEIGHT是在一个轮询周期中设备可以处理的最大数据包数量 struct napi_struct { struct list_head poll_list; // 一个列表节点,用于将这个napi_struct实例链接到softnet_data结构的poll_list中 unsigned long state; // 一个状态变量,用于表示这个napi_struct实例的状态,例如它是否在poll_list中,是否正在被轮询等 int weight; // 这个成员定义了在一个轮询周期中,这个设备可以处理的最大数据包数量 int (*poll)(struct napi_struct *, int); // 函数指针,指向设备驱动定义的轮询函数。这个函数会被NAPI调用以处理设备的接收队列 #ifdef CONFIG_NETPOLL spinlock_t poll_lock; int poll_owner; struct net_device *dev; // 一个指向对应的net_device结构的指针,表示这个napi_struct实例对应的网络设备 struct list_head dev_list; #endif };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
创建napi_struct实例后,驱动程序通常会将其与相应的接收队列关联起来,每个napi_struct实例代表一个接收队列。当数据包到来时,其会被添加到CPU的softnet_data中,之后在软中断时通过遍历内核就可以知道需要处理哪些接收队列,以及怎么处理(poll函数)。
5)网卡启动
以上的初始化都完成以后就可以启动网卡了。在上一步网卡驱动初始化时,驱动向内核注册了net_device_ops变量,其中包含着网卡启动、发包、设置MAC地址等回调函数(函数指针)。当启动一个网卡时(例如通过ifconfig eth0 up),net_device_ops变量中的ndo_open方法会被调用(这是一个函数指针,对于igb网卡来说指向了igb_open方法)。具体启动的执行流程如下:
- 启动网卡
- 内核调用net_device_ops中注册的open函数,如igb_open
- 网卡驱动分配RX,TX队列内存
- 网卡驱动注册中断处理函数
- 网卡驱动打开硬中断,等待数据包到来
- 启用NAPI
NAPI(New API,也被称为 NAPI)是一个在 Linux 内核中用于改善网络性能的接口。NAPI 主要解决的问题是当网络流量非常大时,中断处理的开销过大问题。
在早期的网络接口设计中,每个接收到的数据包都会触发一个硬件中断,然后 CPU 停止当前任务,转而去处理这个数据包。然而,在高流量的网络中,数据包的接收频率可能非常高,可能会导致大量的中断,这可能会占据大部分 CPU 时间,导致所谓的"中断风暴"(interrupt storm)。
为了解决这个问题,NAPI 引入了一种被称为"轮询"(polling)的机制。在轮询模式下,网络设备在接收到数据包时不再触发中断,而是简单地将数据包放入接收队列。然后,CPU 定期轮询这个队列,处理所有待处理的数据包。在网络流量非常大的情况下,这种方法可以减少 CPU 的中断处理开销,从而提高网络性能。
NAPI 还包含一种"混合模式",在网络流量较小的情况下使用中断模式,当网络流量较大时自动切换到轮询模式。这种方式结合了两种模式的优点,能够在不同的网络环境中提供较好的性能。
NAPI 是 Linux 内核的一部分,被包括在 Linux 的网络子系统中。许多现代的网络设备驱动都使用 NAPI 来提高性能。
igb_open方法实现如下:
static int __igb_open(struct net_device *netdev, bool resuming)
{
// 分配传输描述符数组
err = igb_setup_all_tx_resources(adpater);
// 分配接收描述符数组
err = igb_setup_all_rx_resources(adpater);
// 注册中断处理函数
err = igb_request_irq(adapter);
if(err)
goto err_req_irq;
// 启用NAPI
for(i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
......
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
以上代码中,_igb_open函数调用了igb_setup_all_tx_resources和igb_setup_all_rx_resources,调用igb_setup_all_rx_resources时分配了RingBuffer,并建立内存和Rx队列的映射关系。实际上一个RingBuffer的内部不是仅有一个环形队列数组,而是两个,一个是内核使用的指针数组(igb_rx_buffer),一个是给网卡硬件使用的bd数组(e1000_adv_rx_desc)。
在网络设备驱动中,环形缓冲区(Ring Buffer)通常有两个核心组件:一个是用于存储数据包描述符(packet descriptors)的环形数组,另一个是用于存储实际数据包的环形数组。
- 描述符数组:这个数组存储的是网络数据包的描述符。描述符通常是一个数据结构,包含了一些元数据,如数据包的长度、数据包在数据数组中的位置,以及一些状态信息,例如数据包是否已经被处理等。这个数组通常被网卡硬件和设备驱动共享,用于协调数据包的处理。
- 数据数组:这个数组实际存储网络数据包的数据。当网络设备接收到一个数据包时,它会将数据包的数据复制到这个数组的一个位置,然后在描述符数组中添加一个新的描述符,指向这个数据包的位置。
在处理数据包时,设备驱动会首先查看描述符数组,找到待处理的数据包的描述符,然后根据描述符的信息,从数据数组中获取并处理数据包的数据。
对于Intel的igb驱动,e1000_adv_rx_desc数组和igb_rx_buffer数组都是被网卡硬件和内核驱动共同使用的,但它们的使用方式有所不同:
- e1000_adv_rx_desc数组:这个队列存储的是接收描述符(Receive Descriptor),它们是网卡硬件和驱动程序共享的数据结构,用于描述接收到的数据包。每一个接收描述符包含数据包的物理地址、长度、状态、错误信息等。当网卡硬件接收到一个数据包,会将数据包的信息填充到一个接收描述符中,然后将这个描述符放入e1000_adv_rx_desc的一个条目中
- igb_rx_buffer数组:这个队列存储的是指向sk_buff结构的指针,sk_buff是网络数据包在Linux内核中的表示。当网卡驱动从网卡硬件接收到一个数据包时,会为这个数据包在内存中分配一个sk_buff,然后将这个sk_buff的指针放入igb_rx_buffer的一个条目中。
在注册中断处理函数时,对于多队列(多个RingBuffer)的网卡,每一个队列都注册了中断。
前面在初始化网络子系统时也注册了中断处理函数,当时使用的是open_softirq函数,这个函数注册的软中断的处理函数,而这里是使用request_irq注册硬中断处理函数。
3、迎接数据的到来
1)硬中断处理
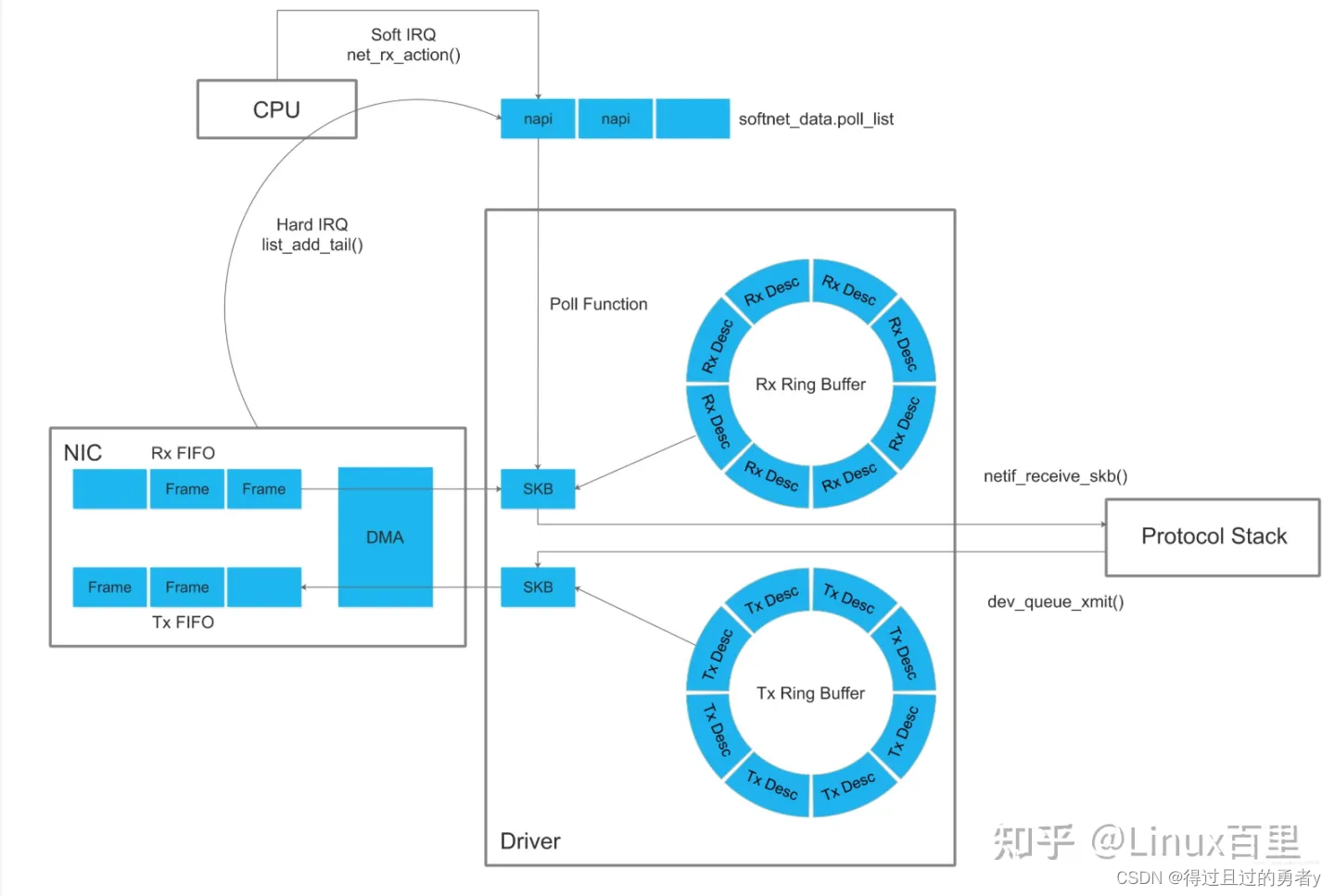
当数据帧从网线到达网卡上的时候,第一站是网卡的接收队列。网卡在分配给自己的RingBuffer中寻找到可用的内存位置,找到后DMA引擎会把数据DMA到网卡之前关联的内存里,到这个时候CPU都是无感的。当DMA操作完成以后,网卡会向CPU发起一个硬中断,通知CPU有数据到达。
具体流程如下:
- 网卡接收数据包,将数据包写入Rx FIFO
- DMA找到rx descriptor ring中下一个将要使用的descriptor
- DMA通过PCI总线将Rx FIFO中的数据包复制到descriptor的数据缓存区
- 调用驱动注册的硬中断处理函数,通知CPU数据缓存区中已经有新的数据包了
当RingBuffer满的时候新来的数据包将被丢弃。使用ifconfig命令查看网卡的时候,可以看到里面有个overruns,表示因为环形队列满被丢弃的包数,可能需要通过ethtool命令来加大环形队列的长度。
网卡硬中断处理函数示例:
/file: drivers/net/ethernet/intel/igb/igb_main.c
static irqreturn_t igb_msix_ring(intirq, void *data){
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
函数接受一个irq参数,它是触发中断的中断请求号(不同队列的请求号不同),和一个data参数,它是注册中断处理函数时传递的上下文数据。在这个例子中,data被转换为一个igb_q_vector指针,它代表一个网卡的接收或发送队列。
在硬中断处理中,只完成了很简单的工作。首先时记录了硬件中断的频率(igb_write_itr),其次在napi_schedule中通过list_add_tail修改CPU变量softnet_data(前面网络子系统初始化时为每个CPU创建的数据结构)中的poll_list(一个双向列表,其中的设备都带有输入帧等着被处理),将驱动传过来的poll_list添加了进来(每一个napi_struct都包含一个list_head类型的poll_list成员,这个poll_list成员用于将这个napi_struct实例链接到softnet_data的poll_list中)。之后便调用__raise_softirq_irqoff(NET_RX_SOFTIRQ)触发一个软中断NET_SOFTIRQ,转交给ksoftirq线程进行软中断处理(轮询列表中收到的数据包)
在Linux内核中,list_head类型的数据结构通常用于创建并管理一个链表。napi_struct结构中的poll_list成员(类型为list_head)就是用来将一个napi_struct实例链接到softnet_data结构中的poll_list成员的。每个队列通常都会有一个关联的napi_struct实例,其中提供了poll轮询函数。当我们说一个napi_struct被添加到poll_list时,实际上是指napi_struct中的poll_list字段(也是list_head类型)被插入到softnet_data的poll_list链表中,通过list_head这种间接方式,将napi_struct元素串联在一起。
每个softnet_data结构对应一个CPU,而poll_list保存了这个CPU当前需要处理的所有napi_struct实例。当一个napi_struct需要被处理时(例如,当网络设备接收到一个数据包时),它的poll_list成员就会被添加到对应的softnet_data的poll_list中。这样,在处理软中断时,内核只需要遍历每个CPU的softnet_data的poll_list,就可以找到并处理所有需要处理的napi_struct实例。这个过程通常是在net_rx_action函数中进行的,这个函数会遍历poll_list并调用每个napi_struct实例的轮询函数。
2)ksoftirqd内核线程处理软中断
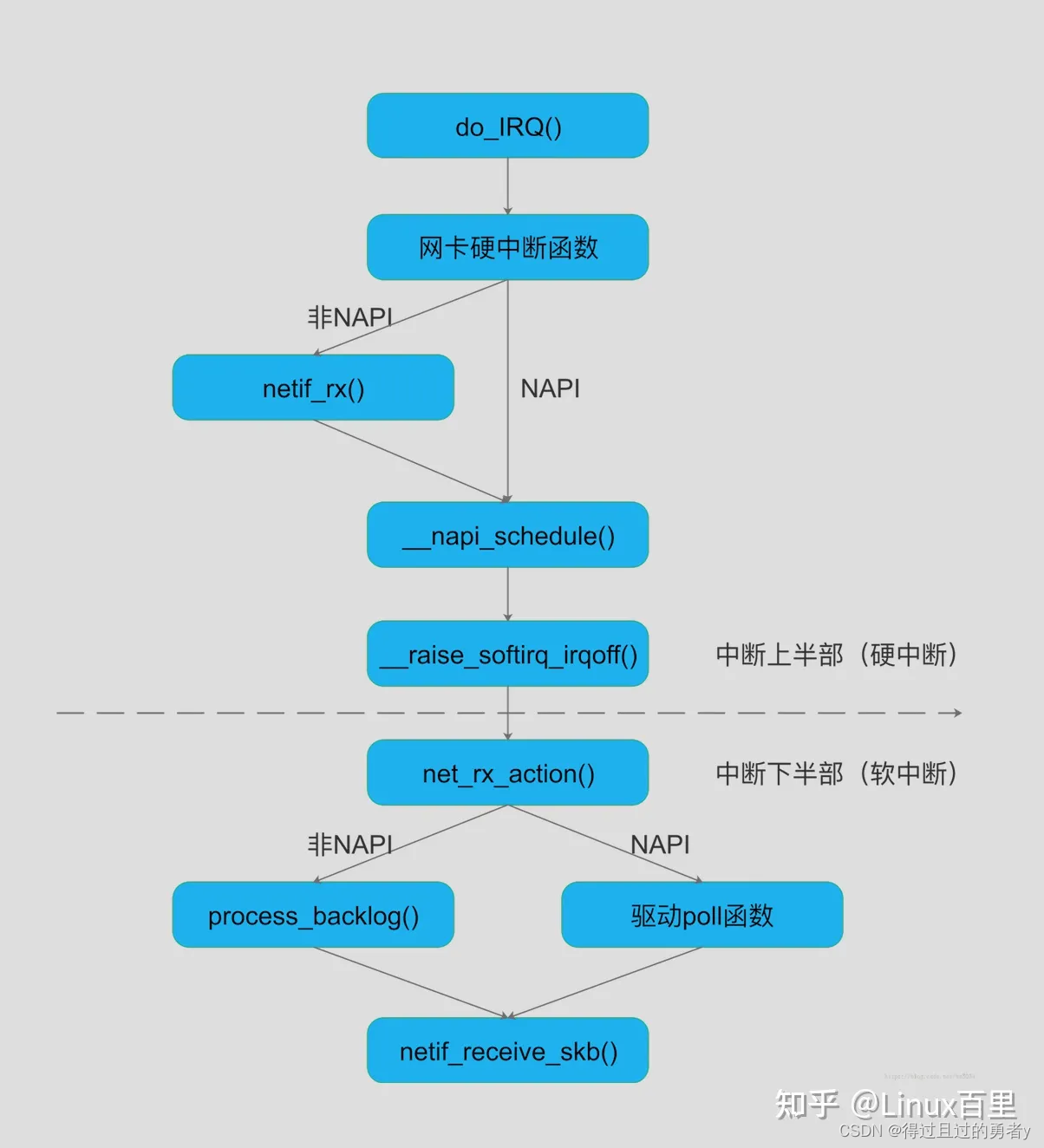
网络包的接受处理过程主要都在ksoftirqd内核线程中完成。ksoftirqd在创建完成之后就进入线程循环函数,如果硬中断设置了NET_RX_SOFTIRQ这里自然就能读取得到。接下来会根据当前CPU的软中断类型(判断softirq_pending标志,在硬中断中设置了)调用其注册的action方法(同样是在网络子系统初始化阶段中注册的)。
需要注意的是,硬中断中设置的软中断标记,和ksoftirqd中的判断是否有软中断到达,都是基于smp_processor_id()的。这意味着只要硬中断在哪个CPU上被响应,那么软中断也是在这个CPU上处理的。
如果发现Linux软中断的CPU消耗都集中在一个核心上,正确的做法应该是调整硬中断的CPU亲和性,将硬中断打散到不同的CPU核上去。
在Linux的NAPI(New API)网络子系统中,poll_list是用来存储正在轮询模式下运行的网络设备的列表。每个在poll_list列表中的设备都会在软中断上下文中被轮询,以处理这些设备的接收队列中的数据包。在软中断处理函数中会获取当前CPU变量softnet_data,然后停用设备的硬中断(防止硬中断重复将设备添加到poll_list中),随后开始轮询softnet_data的poll_list中的每个设备,并调用设备注册的poll函数(网卡驱动程序初始化时注册的)来处理设备的接收队列中的数据包。当接收队列被处理完毕,设备会从poll_list中移除,并重新启用设备的中断。具体的实现逻辑如下:
static void net_rx_action(struct softirq_action *h){ struct softnet_data *sd = &__get_cpu_var(softnet_data); unsigned long time_limit = jiffies + 2; int budget = netdev_budget; void *have; local_irq_disable(); while(!list_empty(&sd->poll_list)) { ...... n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list); work = 0; if(test_bit(NAPI_STATE_SCHED, &n->state)) { work = n->poll(n, weight); trace_napi_poll(n); } budget -= work; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- softnet_data结构的实例sd是使用__get_cpu_var宏获取的。这个宏会返回当前CPU的softnet_data实例。
- list_empty(&sd->poll_list)检查当前CPU的softnet_data的poll_list是否为空。如果不为空,说明有napi_struct实例需要被处理。
- 使用list_first_entry宏从poll_list取出第一个napi_struct实例。
- test_bit(NAPI_STATE_SCHED, &n->state)检查napi_struct的状态,如果已经被调度(即NAPI_STATE_SCHED标志被设置),则调用它的轮询函数n->poll。
- n->poll(n, weight)是对应网络设备驱动程序提供的轮询函数,用于处理网络数据包。这个函数会返回处理的数据包的数量。
- trace_napi_poll(n)调用追踪函数,用于追踪和调试。
- budget是处理数据包的预算,在每个软中断处理过程中,处理的数据包数量不能超过budget。
napi_struct包含一个指向与之关联的网络设备的指针,以及其他与设备特定操作(如数据包处理)相关的信息。这些信息可以间接地让napi_struct获取和操作相关的队列。
在napi_struct的轮询函数执行完毕后,如果处理了所有等待处理的数据包,napi_struct实例通常会从softnet_data的poll_list中移除。这是通过调用napi_complete_done或__napi_complete_done这类函数来完成的。这样做的原因是,在轮询过程中,一旦napi_struct实例处理完了所有的数据包,就没有必要保留在poll_list中了。将其从poll_list中移除可以避免在下一次软中断处理时对其进行无用的处理,从而提高效率。然而,如果网络设备继续接收新的数据包,对应的napi_struct实例可能会被重新添加到poll_list中,以便在下一次软中断处理中被处理。
poll函数中主要是将数据帧从RingBuffer中取下来,然后发送到协议栈中。skb被从RingBuffer(数据队列中包含了指向skb的指针)中取下来后,会再申请新的skb挂上去,避免后面的新包到来时没有skb可用。收取完数据之后会对其进行一些校验,判断数据帧是否正确,然后设置timestamp,VLAN id,protocol等字段。最后poll中还会将相关的小包合并成一个大包,以减少传送给网络栈的包数,有助于减少对CPU的使用量。
3)网络协议栈处理
netif_receive_skb函数会根据包的协议进行处理,假如是UDP包,将包一次送到ip_rcv、udp_rcv等处理函数中进行处理。具体逻辑在__netif_receive_skb_core函数中实现。
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc){ ...... //pcap逻辑,这里会将数据送入抓包点。tcpdump就是从这个入口获取包的 list_for_each_entry_rcu(ptype, &ptype_all, list) { if(!ptype->dev || ptype->dev == skb->dev) { if(pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } ...... list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) { if(ptype->type == type && (ptype->dev == null_or_dev || ptype->dev == skb->dev || ptype->dev == orig_dev)) { if(pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
代码首先通过遍历ptype_all链表处理所有注册在此链表上的协议类型。ptype_all链表中包含的协议类型不会对数据包的协议类型做任何特殊假设,因此所有的数据包都会被传递给这个链表中的处理函数。这个阶段通常用于那些需要处理所有数据包的组件,例如网络抓包工具(比如tcpdump)。tcmpdump是通过虚拟协议的方式工作的,它会将抓包函数以协议的形式挂到ptype_all上。
然后,代码通过遍历ptype_base哈希表来处理数据包的具体协议类型。ptype_base哈希表中包含的协议类型会对数据包的协议类型做特殊处理,因此只有满足特定协议类型的数据包才会被传递给这个哈希表中的处理函数。ip_rcv函数地址就是存在这个哈希表中的。
在这两个阶段中,deliver_skb函数用于将数据包传递给一个协议处理函数。如果协议处理函数返回非零值,那么数据包的处理就会在这里结束;否则,数据包的处理会继续进行,直到所有的协议处理函数都被尝试过。
4)IP层处理
对于IP包而言,在deliver_skb函数中会调用pt_prev->func来调用它的处理函数,进入ip_rcv(如果是ARP包则进入arp_rcv)
//file: net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
}
- 1
- 2
- 3
- 4
- 5
参数skb是指向表示数据包的sk_buff结构的指针,dev是接收到这个数据包的网络设备,pt是与数据包协议类型匹配的packet_type结构,orig_dev是原始接收设备(在处理VLAN和其他封装协议时,dev和orig_dev可能会不同)。
在函数体中,NF_HOOK是一个宏,用于调用Netfilter框架的钩子。Netfilter是Linux内核的一部分,用于实现防火墙和其他网络处理功能。NF_HOOK宏的参数表示要调用的钩子类型和参数。
在这个例子中,NFPROTO_IPV4表示钩子函数处理的是IPv4协议,NF_INET_PRE_ROUTING表示钩子函数是在路由决策之前被调用的。最后一个参数ip_rcv_finish是在Netfilter处理完成后,用于继续处理数据包的函数。
简单来说,这段代码是在数据包被接收和解析为IPv4协议后,但在路由决策之前,通过Netfilter进行进一步处理,比如网络地址转换(NAT)、防火墙过滤等操作。完成这些操作后,处理流程会继续到ip_rcv_finish函数。
在ip_rcv_finish函数中经过层层调用最终来到ip_local_deliver_finish函数,在这个函数中会使用inet_protos拿到协议的函数地址,根据包中的协议类型选择分发。在这里skb包将会进一步被派送到更上层的协议中,UDP或TCP。
4、小结
开始收包前的准备工作:
- 系统初始化时创建ksoftirqd线程
- 网络子系统初始化,为每个CPU初始化softnet_data,为网络收发软中断设置处理函数
- 协议栈注册,为ARP、IP、ICMP、UDP、TCP等协议注册处理函数
- 网卡驱动初始化,准备好DMA,注册ethtool实现函数和netdvice_ops等变量,初始化NAPI
- 启动网卡,分配RX、TX队列,为每个队列注册硬中断对应的处理函数,打开硬中断等待数据包
数据到来后的处理:
- 数据进入网卡Rx FIFO,通过DMA写入内存的RingBuffer,向CPU发起硬中断
- CPU响应硬中断,调用网卡启动时注册的中断处理函数
- 中断处理函数中将驱动传来的poll_list添加到CPU对应的softnet_data的poll_list,发起软中断
- 内核线程ksoftirqd发现软中断请求,关闭硬中断
- ksoftirqd线程根据软中断类型选择处理函数,调用驱动的poll函数收包
- poll函数摘下RIngBuffer上的skb,发到协议栈,并重新申请新的skb
- 协议栈根据数据帧的协议类型,找到对应的处理函数,如ip_rcv
- ip_rcv将包发送到上层协议处理函数,如udp_rcv或tcp_rcv_v4
三、问题解答
-
RingBuffer是什么,为什么会丢包
- RingBuffer是内存中的一块特殊区域,这个数据结构包括数据环形队列数组和描述符环形队列数组。网卡在收到数据的时候以DMA的方式将包写到RingBuffer中,软中断收包的时候skb取走,并申请新的skb重新挂上去。即指针数组是预先分配好的,而指向的skb是随着收包过程动态申请的。
- RingBuffer有大小和长度限制,当满了后新来的数据包就会被丢弃。可以通过ethtool工具(ethtool -g eth0)查看它的长度,通过ethtool工具(ethtool -S eth0)或ifconfig工具(overruns指标)查看是否有RingBuffer移除发生。
- 通过ethtool工具(ethtool -G eth1 rx 4096 tx 4096)可以修改RingBuffer的队列长度,不能超过最大允许值
- 通过分配更大的RingBuffer可以解决偶发的瞬时丢包,但是排队的包过多会增加处理网络包的延时。
-
网络相关的硬中断、软中断是什么
- 网卡将数据放到RingBuffer后就发起硬中断,通知CPU处理
- 硬中断触发软中断NET_SOFTIRQ,由ksoftirqd线程进行处理
-
Linux里的ksoftirqd内核线程是干什么的
- 内核线程ksoftirqd中包含了所有的软中断处理逻辑,根据软中断的类型来执行不同的处理函数。
- 软中断的信息可以从/proc/softirqd中读取(cat /proc/softirqd)
-
为什么网卡开启多队列能提升网络性能
- 现在主流的网卡基本上都支持多队列,通过ethtool(ethtool -l eth0)可以查看当前网卡的多队列情况,会显示支持的最大队列和当前开启的队列数。通过sysfs伪文件系统可以看到真正生效的队列数(ls /sys/class/net/eth0/queues)
- 如果想增大队列数量,可以通过ethtool -L eth0 combined 队列数实现
- 通过/proc/interrupts可以看到这些队列对应的硬件中断号,通过中断号对应的smp_affinity(cat /proc/irq/中断号/smp_affinity)可以查看队列亲和的CPU核是哪一个
- 每个队列会有独立的、不同的中断号,所以不同的队列在收到数据包后可以分别向不同的CPU发起硬中断通知,而哪个核响应的硬中断,那么该硬中断发起的软中断任务就必然由该核来处理
- 如果网络包的接收频率高而导致个别核si偏高,可以通过加大网卡队列数,并设置每个队列中断号上的smp_affinity,将各个队列的硬中断打散到不同的CPU,这样后续的软中断的CPU开销也可以分摊到多个核
-
tcpdump是如何工作的
- tcpdump工作在设备层,通过虚拟协议的方式工作的。它通过调用packet_create将抓包函数以协议的形式挂到ptype_all上。
- 当收包的时候,驱动中实现的igb_poll函数最终会调用到_netif_receive_skb_core,这个函数会在将包发送到协议栈函数如ip_rcv之前,将包先送到ptype_all抓包点。
-
iptable/netfilter是在哪一层实现的
- 主要在IP、ARP等层实现,可以通过搜索对NF_HOOK函数的引用来深入了解其实现
- 如果配置过于复杂的规则会消耗过多的CPU,加大网络延迟
-
tcpdump能否抓到被iptable封禁的包
- netfilter工作在IP、ARP等层,所以iptable封禁规则影响不到tcpdump抓包
- 发包的时候则相反,netfilter在协议层就被过滤掉了,所以tcpdump获取不到
-
网络接收过程中如何查看CPU开销
- top指令可以查看。其中hi是处理硬中断的开销,si是处理软中断的开销,都是通过百分比的形式来展示
-
DPDK是什么
- 数据包的接收需要内核进行非常复杂的工作,并且在数据接受完之后还需要将数据复制到用户空间的内存中。如果用户进程当前是阻塞的,还需要唤醒它,又是一次上下文切换的开销。
- DPDK就是用于让用户进程绕开内核协议栈,自己直接从网卡接收数据,省掉了繁杂的内核协议栈处理、数据拷贝开销、唤醒用户进程开销等。
参考资料:
Linux内核网络数据包处理流程 - 知乎 (zhihu.com)
《深入理解Linux网络》—— 张彦飞

