
- 1CentOS7自制openssh rpm包(含ssh-copy-id命令)—— 筑梦之路_centos7 openssh rpm
- 2ts: axios 返回值类型报错 和 解构赋值_axios.d.ts
- 3python opencv入门 光流法(41)_ret, old_frame = cap.read()
- 4Stable Diffusion 学习(一)——Web UI 的安装与部署_webui 1.6学习
- 5【2023】uniapp+vue3+ts超实用模板_uniapp v3 ts
- 6【Linux】iftop命令详解_iftop命令结果查看
- 7Spring Batch | quick start
- 8HarmonyOS-AES加解密
- 9中南大学计算机学院的机房,-中南大学高性能计算中心.pdf
- 10SpringBoot:多环境打包配置_@package.environment@
Linux内核启动流程(待完善)_内核启动流程内容
赞
踩
文章目录
- 一、Linux内核自解压过程
- 二、Linux内核启动第二阶段stage1
- 2.1、linux系统启动入口函数(stext)
- 2.2、内核初始化阶段(start_kernel)
- 2.3、创建kernel_init线程(start_kernel->rest_init->kernel_init)
- 2.3.1 kernel_init函数
- 2.3.2 kernel_init_freeable函数(start_kernel->rest_init->kernel_init->kernel_init_freeable)
- 2.3.3 do_basic_setup(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup)
- 2.3.4 driver_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init)
- 2.3.4.1 driver_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->devices_init)
- 2.3.4.2 buses_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->buses_init)
- 2.3.4.3 classes_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->classes_init)
- 2.3.4.4 firmware_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->firmware_init)
- 2.3.4.5 hypervisor_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->hypervisor_init)
- 2.3.4.6 platform_bus_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->platform_bus_init)
- 2.3.4.7 cpu_dev_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->cpu_dev_init)
- 2.3.4.8 memory_dev_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->memory_dev_init)
- 2.3.4.9 container_dev_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->container_dev_init)
- 2.3.5 do_initcalls函数(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->do_initcalls)
- 三、init进程
- 四、init进程在内核态下的分析(也就是kernel_init函数)
- 四、流程图
本文以Linux4.9版本源码为例分析其启动流程。各版本启动代码略有不同,但核心流程与思想万变不离其宗。
嵌入式linux内核的启动全过程主要分为三个阶段。
- 第一阶段为内核自解压过程
- 第二阶段主要工作是设置ARM处理器工作模式、使能MMU、设置一级页表等
- 第三阶段则主要为C代码,包括内核初始化的全部工作。
一、Linux内核自解压过程
内核压缩和解压缩代码都在目录kernel-4.9/arch/arm/boot/compressed下,编译完成后将产生head.o、misc.o、piggy.gzip.o、vmlinux、decompress.o这几个文件,head.o是内核的头部文件,负责初始设置;misc.o将主要负责内核的解压工作,它在head.o之后;piggy.gzip.o是一个中间文件,其实是一个压缩的内核(kernel/vmlinux),只不过没有和初始化文件及解压文件链接而已;vmlinux是没有(zImage是压缩过的内核)压缩过的内核,就是由piggy.gzip.o、head.o、misc.o组成的,而decompress.o是为支持更多的压缩格式而新引入的。
在BootLoader完成系统的引导以后并将Linux内核调入内存之后,调用do_bootm_linux(),这个函数将跳转到kernel的起始位置。如果kernel没有被压缩,就可以启动了。如果kernel被压缩过,则要进行解压,在压缩过的kernel头部有解压程序。压缩过的kernel入口***个文件源码位置在arch/arm/boot/compressed/head.S。它将调用函数decompress_kernel(),这个函数在文件arch/arm/boot/compressed/misc.c中,decompress_kernel()又调用proc_decomp_setup(),arch_decomp_setup()进行设置,然后打印出信息“Uncompressing Linux…”后,调用gunzip()将内核放于指定的位置。
下面简单介绍一下解压缩过程,也就是函数decompress_kernel实现的功能:解压缩代码位于kernel/lib/inflate.c,inflate.c是从gzip源程序中分离出来的,包含了一些对全局数据的直接引用,在使用时需要直接嵌入到代码中。gzip压缩文件时总是在前32K字节的范围内寻找重复的字符串进行编码, 在解压时需要一个至少为32K字节的解压缓冲区,它定义为window[WSIZE]。inflate.c使用get_byte()读取输入文件,它被定义成宏来提高效率。输入缓冲区指针必须定义为inptr,inflate.c中对之有减量操作。inflate.c调用flush_window()来输出window缓冲区中的解压出的字节串,每次输出长度用outcnt变量表示。在flush_window()中,还必须对输出字节串计算CRC并且刷新crc变量。在调用gunzip()开始解压之前,调用makecrc()初始化CRC计算表。***gunzip()返回0表示解压成功。我们在内核启动的开始都会看到这样的输出:
UncompressingLinux…done, booting the kernel.
这也是由decompress_kernel函数输出的,执行完解压过程,再返回到head.S中的583行,启动内核
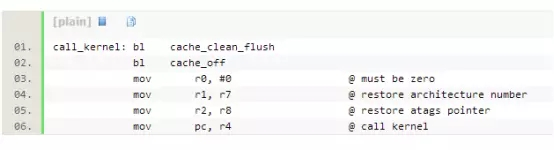
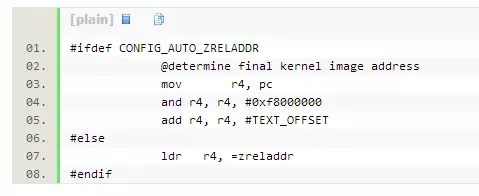
其中r4中已经在head.S的第180行处预置为内核镜像的地址,如下代码:
这样就进入Linux内核的第二阶段,我们也称之为stage1。
二、Linux内核启动第二阶段stage1
2.1、linux系统启动入口函数(stext)
内核映像被加载到内存并获得控制权之后,内核启动流程开始。通常,内核映像以压缩形式存储,并不是一个可以执行的内核。因此,内核阶段的首要工作是自解压内核映像。
内核编译生成vmliunx后,通常会对其进行压缩,得到zImage(小内核,小于512KB)或bzImage(大内核,大于512KB)。在它们的头部嵌有解压缩程序。
通过kernel-4.9/arch/arm/boot/compressed/Makefile可知道,vmlinux文件的链接脚本为vmlinux.lds,可以从中查找linux系统启动入口函数。
$(obj)/vmlinux: $(obj)/vmlinux.lds $(obj)/$(HEAD) $(obj)/piggy.o \
$(addprefix $(obj)/, $(OBJS)) $(lib1funcs) $(ashldi3) \
$(bswapsdi2) $(efi-obj-y) FORCE
@$(check_for_multiple_zreladdr)
$(call if_changed,ld)
@$(check_for_bad_syms)
- 1
- 2
- 3
- 4
- 5
- 6
vmlinux.lds(kernel-4.9/arch/arm/kernel/vmlinux.lds.S)链接脚本开头内容
OUTPUT_ARCH(arm)
ENTRY(stext)
- 1
- 2
从ENTRY,得到内核入口函数为 stext(kernel-4.9/arch/arm/kernel/head.S)
内核引导阶段
ENTRY(stext) ....... bl __lookup_processor_type @ r5=procinfo r9=cpuid //处理器是否支持 movs r10, r5 @ invalid processor (r5=0)? THUMB( it eq ) @ force fixup-able long branch encoding beq __error_p @ yes, error 'p' //不支持则打印错误信息 ....... bl __create_page_tables //创建页表 /* * The following calls CPU specific code in a position independent * manner. See arch/arm/mm/proc-*.S for details. r10 = base of * xxx_proc_info structure selected by __lookup_processor_type * above. On return, the CPU will be ready for the MMU to be * turned on, and r0 will hold the CPU control register value. */ ldr r13, =__mmap_switched @ address to jump to after //保存MMU使能后跳转地址 @ mmu has been enabled badr lr, 1f @ return (PIC) address mov r8, r4 @ set TTBR1 to swapper_pg_dir ARM( add pc, r10, #PROCINFO_INITFUNC ) THUMB( add r12, r10, #PROCINFO_INITFUNC ) THUMB( mov pc, r12 ) 1: b __enable_mmu //使能MMU后跳转到__mmap_switched ENTRY(stext) ............ bl __lookup_processor_type @ r5=procinfo r9=cpuid //处理器是否支持 movs r10, r5 @ invalid processor (r5=0)? THUMB( it eq ) @ force fixup-able long branch encoding beq __error_p @ yes, error 'p' //不支持则打印错误信息 ........... bl __create_page_tables //创建页表 /* * The following calls CPU specific code in a position independent * manner. See arch/arm/mm/proc-*.S for details. r10 = base of * xxx_proc_info structure selected by __lookup_processor_type * above. * * The processor init function will be called with: * r1 - machine type * r2 - boot data (atags/dt) pointer * r4 - translation table base (low word) * r5 - translation table base (high word, if LPAE) * r8 - translation table base 1 (pfn if LPAE) * r9 - cpuid * r13 - virtual address for __enable_mmu -> __turn_mmu_on * * On return, the CPU will be ready for the MMU to be turned on, * r0 will hold the CPU control register value, r1, r2, r4, and * r9 will be preserved. r5 will also be preserved if LPAE. */ ldr r13, =__mmap_switched @ address to jump to after //保存MMU使能后跳转地址 @ mmu has been enabled badr lr, 1f @ return (PIC) address #ifdef CONFIG_ARM_LPAE mov r5, #0 @ high TTBR0 mov r8, r4, lsr #12 @ TTBR1 is swapper_pg_dir pfn #else mov r8, r4 @ set TTBR1 to swapper_pg_dir #endif ldr r12, [r10, #PROCINFO_INITFUNC] add r12, r12, r10 ret r12 1: b __enable_mmu //使能MMU后跳转到__mmap_switched ENDPROC(stext)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
查找标签__mmap_switched所在位置:kernel-4.9/arch/arm/kernel/head-common.S
__INIT __mmap_switched: adr r3, __mmap_switched_data ldmia r3!, {r4, r5, r6, r7} cmp r4, r5 @ Copy data segment if needed 1: cmpne r5, r6 ldrne fp, [r4], #4 strne fp, [r5], #4 bne 1b mov fp, #0 @ Clear BSS (and zero fp) 1: cmp r6, r7 strcc fp, [r6],#4 bcc 1b ARM( ldmia r3, {r4, r5, r6, r7, sp}) THUMB( ldmia r3, {r4, r5, r6, r7} ) THUMB( ldr sp, [r3, #16] ) str r9, [r4] @ Save processor ID str r1, [r5] @ Save machine type str r2, [r6] @ Save atags pointer cmp r7, #0 strne r0, [r7] @ Save control register values b start_kernel
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
程序跳转到start_kernel函数。
2.2、内核初始化阶段(start_kernel)
从start_kernel函数开始,内核进入C语言部分,完成内核的大部分初始化工作。
函数所在位置:kernel-4.9/init/Main.c
start_kernel涉及大量初始化工作,只例举重要的初始化工作。
asmlinkage __visible void __init start_kernel(void) { char *command_line; char *after_dashes; set_task_stack_end_magic(&init_task); //当只有一个CPU的时候这个函数就什么都不做,但是如果有多个CPU的时候那么它就返回在启动的时候的那个CPU的号 smp_setup_processor_id(); //smp相关,返回启动CPU号 debug_objects_early_init(); /* * Set up the the initial canary ASAP: */ boot_init_stack_canary(); //为栈增加保护机制,预防一些缓冲区溢出之类的攻击 cgroup_init_early(); local_irq_disable(); //关闭当前CPU的中断 early_boot_irqs_disabled = true; /* * Interrupts are still disabled. Do necessary setups, then * enable them */ boot_cpu_init(); //激活当前CPU page_address_init(); //初始化页地址,使用链表将其链接起来 pr_notice("%s", linux_banner); //显示内核版本信息,如:Linux version 4.9.217+ /* 每种体系结构都有自己的setup_arch()函数,是体系结构相关的,具体编译哪个 体系结构的setup_arch()函数,由源码树顶层目录下的Makefile中的ARCH变量决定*/ setup_arch(&command_line); //对不同体系结构的CPU设置不同的参数、选项等 mm_init_cpumask(&init_mm); setup_command_line(command_line); setup_nr_cpu_ids(); setup_per_cpu_areas(); smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */ boot_cpu_hotplug_init(); build_all_zonelists(NULL, NULL); page_alloc_init(); //页内存申请初始化 pr_notice("Kernel command line: %s\n", boot_command_line);//打印内核启动命令行参数 /* parameters may set static keys */ jump_label_init(); parse_early_param(); //查找内核参数 after_dashes = parse_args("Booting kernel", static_command_line, __start___param, __stop___param - __start___param,//解析由BOOT传递的内核启动命令行参数 -1, -1, NULL, &unknown_bootoption); if (!IS_ERR_OR_NULL(after_dashes)) parse_args("Setting init args", after_dashes, NULL, 0, -1, -1, NULL, set_init_arg); /* * These use large bootmem allocations and must precede * kmem_cache_init() */ setup_log_buf(0); pidhash_init(); //初始化hash表,便于从进程的PID获得对应的进程描述符指针 vfs_caches_init_early(); //虚拟文件系统的初始化 sort_main_extable(); /*trap_init函数完成对系统保留中断向量(异常、非屏蔽中断以及系统调用)的初始化,init_IRQ函 数则完成其余中断向量的初始化*/ trap_init(); //初始化硬件中断,函数中设置了很多中断门 mm_init(); //建立内核的内存分配器 /* * Set up the scheduler prior starting any interrupts (such as the * timer interrupt). Full topology setup happens at smp_init() * time - but meanwhile we still have a functioning scheduler. */ sched_init(); //初始化任务调度 /* * Disable preemption - early bootup scheduling is extremely * fragile until we cpu_idle() for the first time. */ preempt_disable(); //禁止内核抢占 if (WARN(!irqs_disabled(), "Interrupts were enabled *very* early, fixing it\n")) local_irq_disable(); //检查关闭CPU中断 /*大量初始化内容 见名知意*/ idr_init_cache(); rcu_init(); //初始化RCU(Read-Copy Update)机制 /* trace_printk() and trace points may be used after this */ trace_init(); context_tracking_init(); radix_tree_init(); /* init some links before init_ISA_irqs() */ early_irq_init(); init_IRQ(); //中断向量的初始化 tick_init(); //初始化内核时钟系统 rcu_init_nohz(); init_timers(); //初始化定时器相关的数据结构 hrtimers_init(); //对高精度时钟进行初始化 softirq_init(); //初始化tasklet_softirq和hi_softirq timekeeping_init(); time_init(); //初始化系统时钟源 sched_clock_postinit(); printk_nmi_init(); perf_event_init(); profile_init(); //对内核的profile(一个内核性能调式工具)功能进行初始化 call_function_init(); WARN(!irqs_disabled(), "Interrupts were enabled early\n"); early_boot_irqs_disabled = false; local_irq_enable(); //本地中断可以使用了 kmem_cache_init_late(); /* * HACK ALERT! This is early. We're enabling the console before * we've done PCI setups etc, and console_init() must be aware of * this. But we do want output early, in case something goes wrong. */ /* 初始化控制台以显示printk的内容,在此之前调用的printk只是把数据存到缓冲区里*/ console_init(); //初始化控制台,可以使用printk了 if (panic_later) panic("Too many boot %s vars at `%s'", panic_later, panic_param); lockdep_info();//如果定义了CONFIG_LOCKDEP宏,则打印锁依赖信息,否则什么也不做 /* * Need to run this when irqs are enabled, because it wants * to self-test [hard/soft]-irqs on/off lock inversion bugs * too: */ locking_selftest(); #ifdef CONFIG_BLK_DEV_INITRD if (initrd_start && !initrd_below_start_ok && page_to_pfn(virt_to_page((void *)initrd_start)) < min_low_pfn) { pr_crit("initrd overwritten (0x%08lx < 0x%08lx) - disabling it.\n", page_to_pfn(virt_to_page((void *)initrd_start)), min_low_pfn); initrd_start = 0; } #endif page_ext_init(); debug_objects_mem_init(); kmemleak_init(); setup_per_cpu_pageset(); numa_policy_init(); if (late_time_init) late_time_init(); sched_clock_init(); /*一个非常有趣的CPU性能测试函数,可以计 算出CPU在1s内执行了多少次一个极短的循环,计算出来的值经过处理后得到BogoMIPS值(Bogo是Bogus的意思)*/ calibrate_delay(); pidmap_init(); anon_vma_init(); acpi_early_init(); #ifdef CONFIG_X86 if (efi_enabled(EFI_RUNTIME_SERVICES)) efi_enter_virtual_mode(); #endif #ifdef CONFIG_X86_ESPFIX64 /* Should be run before the first non-init thread is created */ init_espfix_bsp(); #endif thread_stack_cache_init(); cred_init(); fork_init(); //初始化fork proc_caches_init(); buffer_init(); key_init(); security_init(); dbg_late_init(); vfs_caches_init(); //虚拟文件系统初始化 signals_init(); /* rootfs populating might need page-writeback */ page_writeback_init(); proc_root_init(); nsfs_init(); cpuset_init(); cgroup_init(); taskstats_init_early(); delayacct_init(); /* 测试该CPU的各种缺陷,记录检测到的缺陷,以便于内核的其他部分以后可以使用它们的工作。*/ check_bugs(); acpi_subsystem_init(); sfi_init_late(); if (efi_enabled(EFI_RUNTIME_SERVICES)) { efi_late_init(); efi_free_boot_services(); } ftrace_init(); /* Do the rest non-__init'ed, we're now alive */ rest_init(); //剩下的初始化工作 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
2.3.2 rest_init函数(start_kernel->rest_init)
接下来是rest_init函数:
函数所在位置:kernel-4.9/init/Main.c
static noinline void __ref rest_init(void) { int pid; rcu_scheduler_starting(); /* * We need to spawn init first so that it obtains pid 1, however * the init task will end up wanting to create kthreads, which, if * we schedule it before we create kthreadd, will OOPS. */ kernel_thread(kernel_init, NULL, CLONE_FS); //创建kernel_init numa_default_policy(); pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES); rcu_read_lock(); kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns); rcu_read_unlock(); complete(&kthreadd_done); /* * The boot idle thread must execute schedule() * at least once to get things moving: */ init_idle_bootup_task(current); schedule_preempt_disabled(); /* Call into cpu_idle with preempt disabled */ //cpu_idle就是在系统闲置时用来降低电力的使用和减少热的产生的空转函数,函数至此不再返回,其余工作从kernel_init进程处发起 cpu_startup_entry(CPUHP_ONLINE); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
函数最后调用rest_init()函数
(1)rest_init中调用kernel_thread函数启动了2个内核线程,分别是:kernel_init和kthreadd。kernel_thead函数其实就是把kernel_init和kthreadd变成了一个内核线程去运行起来,然后他可以被内核调度系统去调度。说白了就是去调度器注册了一下,以后人家调度的时候会考虑你。
(2)调用schedule函数开启了内核的调度系统,从此linux系统开始转起来了。
(3)rest_init最终调用cpu_idle函数结束了整个内核的启动。也就是说linux内核最终结束了一个函数cpu_idle。这个函数里面肯定是死循环。
(4)简单来说,linux内核最终的状态是:有事干的时候去执行有意义的工作(执行各个进程任务),实在没活干的时候就去死循环(实际上死循环也可以看成是一个任务)。
(5)之前已经启动了内核调度系统,调度系统会负责考评系统中所有的进程,这些进程里面只有有哪个需要被运行,调度系统就会终止cpu_idle死循环进程(空闲进程)转而去执行有意义的干活的进程。这样操作系统就转起来了。
2.3、创建kernel_init线程(start_kernel->rest_init->kernel_init)
最重要使命:创建kernel_init线程(用kernel_thread创建的是线程,不是进程,可能面试会用到),并进行后续初始化。
2.3.1 kernel_init函数
kernel_init函数将完成设备驱动程序的初始化,并调用init_post函数启动用户进程
部分书籍介绍的内核启动流程基于经典的2.6版本,kernel_init函数还会调用init_post函数专门负责_init进程的启动,现版本已经被整合到了一起。
函数所在位置:kernel-4.9/init/Main.c
static int __ref kernel_init(void *unused) { int ret; kernel_init_freeable(); //该函数中完成smp开启、驱动初始化、共享内存初始化等工作 /* need to finish all async __init code before freeing the memory */ async_synchronize_full();//等待所有异步调用执行完成,在释放内存前,必须完成所有的异步 __init 代码 free_initmem(); //初始化尾声,清除内存无用数据(释放所有init.* 段中的内存) mark_readonly(); system_state = SYSTEM_RUNNING; //设置系统状态为运行状态 numa_default_policy(); //设定NUMA系统的默认内存访问策略 rcu_end_inkernel_boot(); if (ramdisk_execute_command) { //ramdisk_execute_command的值为"/init" ret = run_init_process(ramdisk_execute_command); //运行根目录下的init程序 if (!ret) return 0; pr_err("Failed to execute %s (error %d)\n", ramdisk_execute_command, ret); } /* * We try each of these until one succeeds. * * The Bourne shell can be used instead of init if we are * trying to recover a really broken machine. *寻找init函数,创建一号进程_init (第一个用户空间进程)*/ if (execute_command) {//execute_command的值如果有定义就去根目录下找对应的应用程序,然后启动 if (sys_access((const char __user *) execute_command, 0) != 0) execute_command = "/init"; ret = run_init_process(execute_command); if (!ret) return 0; panic("Requested init %s failed (error %d).", execute_command, ret); } //如果ramdisk_execute_command和execute_command定义的应用程序都没有找到, //就到根目录下找 /sbin/init,/etc/init,/bin/init,/bin/sh 这四个应用程序进行启动 if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0; panic("No working init found. Try passing init= option to kernel. " "See Linux Documentation/init.txt for guidance."); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
当执行完kernel_init_freeable和async_synchronize_full,内核初始化已经接近尾声,所有的初始化函数都已经调用,因此调用free_initmem函数,舍弃内存的__init_begin至__init_end之间的数据。
2.3.2 kernel_init_freeable函数(start_kernel->rest_init->kernel_init->kernel_init_freeable)
首先,调用kernel_init_freeable函数:
函数所在位置:kernel-4.9/init/Main.c
static noinline void __init kernel_init_freeable(void) { /* * Wait until kthreadd is all set-up. */ wait_for_completion(&kthreadd_done); /* Now the scheduler is fully set up and can do blocking allocations */ gfp_allowed_mask = __GFP_BITS_MASK; /* * init can allocate pages on any node */ set_mems_allowed(node_states[N_MEMORY]); /* * init can run on any cpu. */ set_cpus_allowed_ptr(current, cpu_all_mask); cad_pid = task_pid(current); smp_prepare_cpus(setup_max_cpus); do_pre_smp_initcalls(); lockup_detector_init(); smp_init(); sched_init_smp(); page_alloc_init_late(); do_basic_setup(); /* Open the /dev/console on the rootfs, this should never fail */ if (sys_open((const char __user *) "/dev/console", O_RDWR, 0) < 0) pr_err("Warning: unable to open an initial console.\n"); (void) sys_dup(0); (void) sys_dup(0); /* * check if there is an early userspace init. If yes, let it do all * the work */ if (!ramdisk_execute_command) ramdisk_execute_command = "/init"; if (sys_access((const char __user *) ramdisk_execute_command, 0) != 0) { ramdisk_execute_command = NULL; prepare_namespace(); } /* * Ok, we have completed the initial bootup, and * we're essentially up and running. Get rid of the * initmem segments and start the user-mode stuff.. * * rootfs is available now, try loading the public keys * and default modules */ integrity_load_keys(); load_default_modules(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
2.3.3 do_basic_setup(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup)
函数do_basic_setup做了很多内核和驱动的初始化工作。
/好了, 设备现在已经初始化完成。 但是还没有一个设备被初始化过,
但是 CPU 的子系统已经启动并运行,
且内存和处理器管理系统已经在工作了。
现在我们终于可以开始做一些实际的工作了/
函数所在位置:kernel-4.9/init/Main.c
static void __init do_basic_setup(void)
{
/*针对SMP系统,初始化内核control group的cpuset子系统。如果非SMP,此函数为空。
cpuset是在用户空间中操作cgroup文件系统来执行进程与cpu和进程与内存结点之间的绑定。
本函数将cpus_allowed和mems_allwed更新为在线的cpu和在线的内存结点,并为内存热插拨注册了钩子函数,最后创建一个单线程工作队列cpuset。*/
cpuset_init_smp(); 针对SMP系统,初始化内核control group的cpuset子系统。
shmem_init(); // 初始化共享内存
driver_init(); //初始化驱动模型中的各子系统,可见的现象是在/sys中出现的目录和文件
init_irq_proc(); //创建/proc/irq目录, 并初始化系统中所有中断对应的子目录
do_ctors(); //调用链接到内核中的所有构造函数,也就是链接进.ctors段中的所有函数。
usermodehelper_enable(); // 创建khelper单线程工作队列,用于协助新建和运行用户空间程序
do_initcalls();//遍历initcall_levels数组,调用里面的initcall函数,
//这里主要是对设备、驱动、文件系统进行初始化,之所有将函数封装到数组进行遍历,主要是为了好扩展
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.3.4 driver_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init)
由driver_init函数完成设备驱动子系统的初始化,主要完成了设备驱动子系统的一个整体框架;
路径:kernel-4.9/drivers/base/init.c
/** * driver_init - initialize driver model. * * Call the driver model init functions to initialize their * subsystems. Called early from init/main.c. */ void __init driver_init(void) { /* These are the core pieces */ devtmpfs_init();//初始化devtmpfs文件系统,驱动核心设备将在这个文件系统中添加它们的设备节点。 /*初始化驱动模型中的部分子系统和kobject: devices dev dev/block dev/char */ devices_init();//建立/sys/devices、/sys/dev这两个顶级容器节点 //和/sys/dev/block、/sys/dev/char这两个二级节点。 buses_init(); //初始化驱动模型中的bus子系统,创建/sys/bus节点 classes_init(); //初始化驱动模型中的class子系统,创建/sys/class节点 firmware_init(); //初始化驱动模型中的firmware子系统,创建/sys/firmware节点 hypervisor_init(); //初始化驱动模型中的hypervisor子系统,创建/sys/hypervisor节点 /* These are also core pieces, but must come after the * core core pieces. * 这些也是核心部件, 但是必须在以上核心中的核心部件之后调用。 */ platform_bus_init();//初始化驱动模型中的bus/platform子系统, //创建platform节点/sys/devices/platform cpu_dev_init(); //初始化驱动模型中的devices/system/cpu子系统, //创建/sys/devices/system/cpu节点 memory_dev_init(); //初始化驱动模型中的devices/system/memory子系统 container_dev_init();//创建/sys/devices/system/container节点 of_core_init(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
devtmpfs_int函数注册一个名为devtmpfs的文件系统dev_fs_type,这部分和设备驱动子系统的建立关系并不大,这里不多做介绍。
2.3.4.1 driver_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->devices_init)
devices_init函数:创建devices相关的设备模型
路径:kernel-4.9/drivers/base/core.c
int __init devices_init(void) { devices_kset = kset_create_and_add("devices", &device_uevent_ops, NULL); if (!devices_kset) return -ENOMEM; dev_kobj = kobject_create_and_add("dev", NULL); if (!dev_kobj) goto dev_kobj_err; sysfs_dev_block_kobj = kobject_create_and_add("block", dev_kobj); if (!sysfs_dev_block_kobj) goto block_kobj_err; sysfs_dev_char_kobj = kobject_create_and_add("char", dev_kobj); if (!sysfs_dev_char_kobj) goto char_kobj_err; return 0; char_kobj_err: kobject_put(sysfs_dev_block_kobj); block_kobj_err: kobject_put(dev_kobj); dev_kobj_err: kset_unregister(devices_kset); return -ENOMEM; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
devices_init函数建立/sys/devices、/sys/dev这两个顶级容器节点和/sys/dev/block、/sys/dev/char这两个二级节点。
devices_kset是在kernel-4.9/driver/base/core.c中定义的全局变量,对应于sysfs的/sys/devices节点
dev_kobj是在kernel-4.9/driver/base/core.c中定义的static变量, 对应于sysfs的/sys/dev节点
sysfs_dev_block_kobj是在kernel-4.9/driver/base/core.c中定义的全局变量,是dev_kobj的子节点,对应于sysfs的/sys/dev/block,该节点是所有block设备的父节点
sysfs_dev_char_kobj是在kernel-4.9/driver/base/core.c中定义的全局变量,是dev_kobj的子节点,对应于sysfs的/sys/dev/char,该节点是所有char设备的父节点
2.3.4.2 buses_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->buses_init)
建立Linux设备模型总线部分的顶级节点
路径:kernel-4.9/drivers/base/bus.c
int __init buses_init(void)
{
bus_kset = kset_create_and_add("bus", &bus_uevent_ops, NULL);
if (!bus_kset)
return -ENOMEM;
system_kset = kset_create_and_add("system", NULL, &devices_kset->kobj);
if (!system_kset)
return -ENOMEM;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
buses_init函数建立了/sys/bus这个顶级容器节点,该节点是Linux内核中所有总线类型的父节点,
bus_kset是kernel-4.9/drivers/base/bus.c中定义的static变量。
通过kset_create_and_add函数建立了/sys/devices/system这个容器节点,system_kset是drivers/base/sys.c中定义的static变量。
这个节点中主要是一些和cpu、中断控制器、时钟之类的设备。
2.3.4.3 classes_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->classes_init)
classes_init函数:建立Linux设备模型类部分的顶级容器节点
路径:kernel-4.9/drivers/base/class.c
int __init classes_init(void)
{
class_kset = kset_create_and_add("class", NULL, NULL);
if (!class_kset)
return -ENOMEM;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
建立了/sys/class这个顶级容器节点,该节点是Linux内核中所有class类型的父节点,class_kset是kernel-4.9/drivers/base/class.c中定义的static变量
2.3.4.4 firmware_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->firmware_init)
建立Linux设备模型中firmware部分的顶级节点
路径:kernel-4.9/drivers/base/firmware.c
int __init firmware_init(void)
{
firmware_kobj = kobject_create_and_add("firmware", NULL);
if (!firmware_kobj)
return -ENOMEM;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
建立了/sys/firmware这个顶级kobj节点,firmware_kobj是在kernel-4.9/drivers/base/firmware.c定义的全局变量
2.3.4.5 hypervisor_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->hypervisor_init)
建立hypervisor_kobj的顶级容器节点
路径:kernel-4.9/drivers/base/hypervisor.c
int __init hypervisor_init(void)
{
hypervisor_kobj = kobject_create_and_add("hypervisor", NULL);
if (!hypervisor_kobj)
return -ENOMEM;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
建立了/sys/hypervisor这个顶级节点,hypervisor_kobj是在 kernel-4.9/drivers/base/hypervisor.c中定义的全局变量
前面几个函数执行完成后基本已经建立起Linux设备模型的框架了,接下来几个函数都是在前面框架中的扩展
2.3.4.6 platform_bus_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->platform_bus_init)
初始化Linux平台总线,平台总线(platform_bus_type)是在2.6 kernel中引入的一种虚拟总线,主要用来管理CPU的片上资源,具有较好的可移植性能,因此在2.6及以后的kernel中,很多驱动都已经用platform改写了
路径:kernel-4.9/drivers/base/platform.c
int __init platform_bus_init(void)
{
int error;
early_platform_cleanup();
error = device_register(&platform_bus);
if (error)
return error;
error = bus_register(&platform_bus_type);
if (error)
device_unregister(&platform_bus);
of_platform_register_reconfig_notifier();
return error;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
platform_bus_init函数中引入两个变量platform_bus,platform_bus_type,均为在drivers/base/platform.c中定义的全局变量,如下:
struct device platform_bus = {
.init_name = "platform",
};
struct bus_type platform_bus_type = {
.name = "platform",
.dev_groups = platform_dev_groups,
.match = platform_match,
.uevent = platform_uevent,
.pm = &platform_dev_pm_ops,
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
该函数先调用device_register函数注册platform_bus这个设备,这会在/sys/devices/节点下创建platform节点/sys/devices/platform,此设备节点是所有platform设备的父节点,即所有platform_device设备都会在/sys/devices/platform下创建子节点。
然后调用bus_register函数注册platform_bus_type这个总线类型,这会在/sys/bus目录下创建一个platform节点,这个节点是所有platform设备和驱动的总线类型,即所有platform设备和驱动都会挂载到这个总线上;
2.3.4.7 cpu_dev_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->cpu_dev_init)
建立一个名为”cpu”的节点
路径:kernel-4.9/drivers/base/cpu.c
void __init cpu_dev_init(void)
{
if (subsys_system_register(&cpu_subsys, cpu_root_attr_groups))
panic("Failed to register CPU subsystem");
cpu_dev_register_generic();
cpu_register_vulnerabilities();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
subsys_system_register函数会在/sys/devices/system下面建立一个节点,
这里会建立一个/sys/devices/system/cpu节点
2.3.4.8 memory_dev_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->memory_dev_init)
建立memory设备在sysfs中的接口
路径:kernel-4.9/drivers/base/cpu.c
/* * Initialize the sysfs support for memory devices... */ int __init memory_dev_init(void) { unsigned int i; int ret; int err; unsigned long block_sz; ret = subsys_system_register(&memory_subsys, memory_root_attr_groups); if (ret) goto out; block_sz = get_memory_block_size(); sections_per_block = block_sz / MIN_MEMORY_BLOCK_SIZE; /* * Create entries for memory sections that were found * during boot and have been initialized */ mutex_lock(&mem_sysfs_mutex); for (i = 0; i < NR_MEM_SECTIONS; i += sections_per_block) { err = add_memory_block(i); if (!ret) ret = err; } mutex_unlock(&mem_sysfs_mutex); out: if (ret) printk(KERN_ERR "%s() failed: %d\n", __func__, ret); return ret; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
subsys_system_register函数会在/sys/devices/system下面建立一个节点,
但实际在Android上,看到在/sys/devices/system下只有cpu、clockevents、clocksource和container。这里待定。
2.3.4.9 container_dev_init(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->driver_init->container_dev_init)
建立memory设备在sysfs中的接口
路径:kernel-4.9/drivers/base/container.c
void __init container_dev_init(void)
{
int ret;
ret = subsys_system_register(&container_subsys, NULL);
if (ret)
pr_err("%s() failed: %d\n", __func__, ret);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
subsys_system_register函数会在/sys/devices/system下面建立一个节点,
这里会创建/sys/devices/system/container节点。
2.3.5 do_initcalls函数(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->do_initcalls)
作用:调用所有编译内核的驱动模块中的初始化函数。
这里就是驱动程序员需要关心的步骤,其中按照各个内核模块初始化函数所自定义的启动级别(0~7),按从0到7的顺序调用器初始化函数。
对于同一级别的初始化函数,看 makefile 的加载顺序,即obj -y += xxx.o在前面的就先启动。
在编写内核模块的时候需要注意:比如编写的模块使用的是I2C的API,那模块的初始化函数的级别必须低于I2C子系统初始化函数的级别(也就是级别数(0~7)要大于I2C子系统)。如果编写的模块必须和依赖的模块在同一级,那就必须注意内核Makefile的修改了。
调用流程:
start_kernel()–>rest_init()–>kernel_init()–>kernel_init_freeable()–>do_basic_setup()–>do_initcalls()–>do_initcall_level()–>do_one_initcall()
do_initcalls()将从__initcall_start开始,到__initcall_end结束的section中以函数指针的形式顺序取出这些编译到内核的驱动模块中初始化函数起始地址,来依次完成相应的初始化。而这些初始化函数由__define_initcall(level,fn)指示编译器在编译的时候,将这些初始化函数的起始地址值按照一定的顺序放在这个section中。由于内核某些部分的初始化需要依赖于其他某些部分的初始化的完成,因此这个顺序排列非常重要。
函数所在位置:kernel-4.9/init/Main.c
static void __init do_initcalls(void)
{
int level;
................
for (level = 0; level < ARRAY_SIZE(initcall_levels) - 1; level++)
do_initcall_level(level);
................
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
initcall_levels相关的定义:
函数所在位置:kernel-4.9/init/Main.c
extern initcall_t __initcall_start[]; extern initcall_t __initcall0_start[]; extern initcall_t __initcall1_start[]; extern initcall_t __initcall2_start[]; extern initcall_t __initcall3_start[]; extern initcall_t __initcall4_start[]; extern initcall_t __initcall5_start[]; extern initcall_t __initcall6_start[]; extern initcall_t __initcall7_start[]; extern initcall_t __initcall_end[]; static initcall_t *initcall_levels[] __initdata = { __initcall0_start, __initcall1_start, __initcall2_start, __initcall3_start, __initcall4_start, __initcall5_start, __initcall6_start, __initcall7_start, __initcall_end, };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
路径:kernel-4.9/include/linux/init.h
#ifndef MODULE #define __define_initcall(fn, id) \ static initcall_t __initcall_name(fn, id) __used \ __attribute__((__section__(".initcall" #id ".init"))) = fn; /* * Early initcalls run before initializing SMP. * * Only for built-in code, not modules. */ #define early_initcall(fn) __define_initcall(fn, early) /* * A "pure" initcall has no dependencies on anything else, and purely * initializes variables that couldn't be statically initialized. * * This only exists for built-in code, not for modules. * Keep main.c:initcall_level_names[] in sync. */ #define pure_initcall(fn) __define_initcall(fn, 0) #define core_initcall(fn) __define_initcall(fn, 1) #define core_initcall_sync(fn) __define_initcall(fn, 1s) #define postcore_initcall(fn) __define_initcall(fn, 2) #define postcore_initcall_sync(fn) __define_initcall(fn, 2s) #define arch_initcall(fn) __define_initcall(fn, 3) #define arch_initcall_sync(fn) __define_initcall(fn, 3s) #define subsys_initcall(fn) __define_initcall(fn, 4) #define subsys_initcall_sync(fn) __define_initcall(fn, 4s) #define fs_initcall(fn) __define_initcall(fn, 5) #define fs_initcall_sync(fn) __define_initcall(fn, 5s) #define rootfs_initcall(fn) __define_initcall(fn, rootfs) #define device_initcall(fn) __define_initcall(fn, 6) #define device_initcall_sync(fn) __define_initcall(fn, 6s) #define late_initcall(fn) __define_initcall(fn, 7) #define late_initcall_sync(fn) __define_initcall(fn, 7s) #define __initcall(fn) device_initcall(fn) #endif
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
这里主要分析__define_initcall, initcall_t为函数指针,定义为:
typedef int (*initcall_t)(void);
typedef void (*exitcall_t)(void);
- 1
- 2
这个宏的目的是定义一个静态的函数指针,而属性__attribute__((section(x))表示将这个fn放到x这个section位置,所以 __define_initcall(fn, 6) 的意思是将fn放到".initcall.6.init"的section中。
例如:__define_initcall(tps2546_init, 6) 展开该宏为:
#define __define_initcall(tps2546_init, 6) \
static initcall_t __initcall_tps2546_init6 __used \
__attribute__((__section__(".initcall.6.init"))) = tps2546_init
- 1
- 2
- 3
通过查找内核映射表System.map,
路径:out/target/product/car_mt2712_main_t19/obj/KERNEL_OBJ/System.map
可以看到__initcall_tps2546_init6函数指针:
ffffff800902e7d0 T __initcall5_start
-------------------
ffffff800902e930 T __initcall6_start
-------------------
ffffff800902f320 t __initcall_coprocesor2_init6
ffffff800902f328 t __initcall_MCU_TPLCD_init6
ffffff800902f330 t __initcall_tps2546_init6
ffffff800902f338 t __initcall_alsa_timer_init6
ffffff800902f340 t __initcall_alsa_pcm_init6
ffffff800902f348 t __initcall_alsa_rawmidi_init6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
而__initcall_tps2546_init6函数指针是指向驱动模块初始化函数tps2546_init,所以我们的驱动编译进内核后,内核启动之后按照这个顺序注册驱动模块!
路径:kernel-4.9/include/linux/module.h
#ifndef MODULE #else /* MODULE */ /* * In most cases loadable modules do not need custom * initcall levels. There are still some valid cases where * a driver may be needed early if built in, and does not * matter when built as a loadable module. Like bus * snooping debug drivers. */ #define early_initcall(fn) module_init(fn) #define core_initcall(fn) module_init(fn) #define core_initcall_sync(fn) module_init(fn) #define postcore_initcall(fn) module_init(fn) #define postcore_initcall_sync(fn) module_init(fn) #define arch_initcall(fn) module_init(fn) #define subsys_initcall(fn) module_init(fn) #define subsys_initcall_sync(fn) module_init(fn) #define fs_initcall(fn) module_init(fn) #define fs_initcall_sync(fn) module_init(fn) #define rootfs_initcall(fn) module_init(fn) #define device_initcall(fn) module_init(fn) #define device_initcall_sync(fn) module_init(fn) #define late_initcall(fn) module_init(fn) #define late_initcall_sync(fn) module_init(fn) #define console_initcall(fn) module_init(fn) #define security_initcall(fn) module_init(fn) /* Each module must use one module_init(). */ #define module_init(initfn) \ static inline initcall_t __maybe_unused __inittest(void) \ { return initfn; } \ int init_module(void) __copy(initfn) __attribute__((alias(#initfn))); /* This is only required if you want to be unloadable. */ #define module_exit(exitfn) \ static inline exitcall_t __maybe_unused __exittest(void) \ { return exitfn; } \ void cleanup_module(void) __copy(exitfn) __attribute__((alias(#exitfn))); #endif
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
即如果没有定义MODULE,就使用init.h中的定义,如果定义了MODULE,就使用module.h中的定义。
这里的pure_initcall ~ late_initcall_sync 分别对应initcall_levels中的__initcall0_start ~ __initcall7_start。
2.3.4.1 do_initcall_level函数(start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->do_initcalls->do_initcall_level)
static void __init do_initcall_level(int level)
{
initcall_t *fn;
strcpy(initcall_command_line, saved_command_line);
parse_args(initcall_level_names[level],
initcall_command_line, __start___param,//解析由BOOT传递的内核启动命令行参数
__stop___param - __start___param,//start_kernel中,已经解析了内核启动命令行参数,这
level, level, //里又解析,待分析!
NULL, &repair_env_string);
for (fn = initcall_levels[level]; fn < initcall_levels[level+1]; fn++)
do_one_initcall(*fn); //初始化同一级别中的函数
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
主要分析do_one_initcall(*fn),先要明白这些函数是如何注册的,什么时候注册的。
int __init_or_module do_one_initcall(initcall_t fn) { int count = preempt_count(); int ret; char msgbuf[64]; if (initcall_blacklisted(fn)) return -EPERM; if (initcall_debug) ret = do_one_initcall_debug(fn); else ret = fn(); msgbuf[0] = 0; if (preempt_count() != count) { sprintf(msgbuf, "preemption imbalance "); preempt_count_set(count); } if (irqs_disabled()) { strlcat(msgbuf, "disabled interrupts ", sizeof(msgbuf)); local_irq_enable(); } WARN(msgbuf[0], "initcall %pF returned with %s\n", fn, msgbuf); add_latent_entropy(); return ret; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
do_one_initcall函数就非常简单了,让我们看看最重要的内容如下
if (initcall_debug)
ret = do_one_initcall_debug(fn);
else
ret = fn();
- 1
- 2
- 3
- 4
这里就是判断是不是debug模式,无非debug会多一些调试的操作。但是不管是哪一种,他们都执行 ret = fn( );
因为fn就是函数指针,fn指向的是我们注册到__initcall0_start … __initcall7_start的一系列函数。所以 fn( ); 就是 调用这些函数。当然也包括了驱动中module_init注册的函数啦,只是通过module_init注册的level等级是6,for循环是从level = 0开始的,这也能看出0是优先级最高,7是优先级最低的。
到此,内核初始化已经接近尾声,所有的初始化函数都已经调用,因此free_initmem函数可以舍弃内存的__init_begin至__init_end之间的数据。
三、init进程
init进程是linux系统中用户空间的第一个进程,进程号为1.
当bootloader启动后,启动kernel,kernel启动完后,在用户空间启动init进程,再通过init进程,来读取init.rc中的相关配置,从而来启动其他相关进程以及其他操作。
kernel_init启动后,完成一些init的初始化操作,然后去系统根目录下依次找ramdisk_execute_command(/init)和execute_command设置的应用程序,如果这两个目录都找不到,就依次去根目录下找 /sbin/init,/etc/init,/bin/init,/bin/sh 这四个应用程序进行启动,只要这些应用程序有一个启动了,其他就不启动了。
3.1 开始启动init进程
路径:kernel-4.9/init/Main.c
start_kernel->rest_init->kernel_init
static int __ref kernel_init(void *unused) { ........................ if (ramdisk_execute_command) { ret = run_init_process(ramdisk_execute_command);//运行可执行文件,启动init进程 if (!ret) //ramdisk_execute_command就是"/init" return 0; pr_err("Failed to execute %s (error %d)\n", ramdisk_execute_command, ret); } /* * We try each of these until one succeeds. * * The Bourne shell can be used instead of init if we are * trying to recover a really broken machine. */ if (execute_command) { if (sys_access((const char __user *) execute_command, 0) != 0) execute_command = "/init"; ret = run_init_process(execute_command); if (!ret) return 0; panic("Requested init %s failed (error %d).", execute_command, ret); } if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0; panic("No working init found. Try passing init= option to kernel. " "See Linux Documentation/init.txt for guidance."); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ramdisk_execute_command在前面的函数中赋值:
if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
- 1
- 2
Android系统一般会在根目录下放一个init的可执行文件,也就是说Linux系统的init进程在内核初始化完成后,就直接执行init这个文件。
3.2.Init 进程具体实现源码分析
我们主要是分析Android 9.0 的init的代码。
涉及源码文件:
platform/system/core/init/main.cpp
platform/system/core/init/init.cpp
platform/system/core/init/ueventd.cpp
platform/system/core/init/selinux.cpp
platform/system/core/init/subcontext.cpp
platform/system/core/base/logging.cpp
platform/system/core/init/first_stage_init.cpp
platform/system/core/init/first_stage_main.cpp
platform/system/core/init/first_stage_mount.cpp
platform/system/core/init/keyutils.h
platform/system/core/init/property_service.cpp
platform/external/selinux/libselinux/src/label.c
platform/system/core/init/signal_handler.cpp
platform/system/core/init/service.cpp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.2.1 Init 进程入口
前面已经通过kernel_init,启动了init进程,init进程属于一个守护进程,准确的说,它是Linux系统中用户控制的第一个进程,它的进程号为1。它的生命周期贯穿整个Linux内核运行的始终。Android中所有其它的进程共同的鼻祖均为init进程。
可以通过"adb shell ps |grep init" 的命令来查看init的进程号。
Android Q(10.0) 的init入口函数由原先的init.cpp 调整到了main.cpp,把各个阶段的操作分离开来,使代码更加简洁命令,接下来我们就从main函数开始学习。
代码路径: [system/core/init/main.cpp]
/* * 1.第一个参数argc表示参数个数,第二个参数是参数列表,也就是具体的参数 * 2.main函数有四个参数入口, *一是参数中有ueventd,进入ueventd_main *二是参数中有subcontext,进入InitLogging 和SubcontextMain *三是参数中有selinux_setup,进入SetupSelinux *四是参数中有second_stage,进入SecondStageMain *3.main的执行顺序如下: * (1)ueventd_main init进程创建子进程ueventd, * 并将创建设备节点文件的工作托付给ueventd,ueventd通过两种方式创建设备节点文件 * (2)FirstStageMain 启动第一阶段 * (3)SetupSelinux 加载selinux规则,并设置selinux日志,完成SELinux相关工作 * (4)SecondStageMain 启动第二阶段 */ int main(int argc, char** argv) { //当argv[0]的内容为ueventd时,strcmp的值为0,!strcmp为1 //1表示true,也就执行ueventd_main,ueventd主要是负责设备节点的创建、权限设定等一些列工作 if (!strcmp(basename(argv[0]), "ueventd")) { return ueventd_main(argc, argv); } //当传入的参数个数大于1时,执行下面的几个操作 if (argc > 1) { //参数为subcontext,初始化日志系统, if (!strcmp(argv[1], "subcontext")) { android::base::InitLogging(argv, &android::base::KernelLogger); const BuiltinFunctionMap function_map; return SubcontextMain(argc, argv, &function_map); } //参数为“selinux_setup”,启动Selinux安全策略 if (!strcmp(argv[1], "selinux_setup")) { return SetupSelinux(argv); } //参数为“second_stage”,启动init进程第二阶段 if (!strcmp(argv[1], "second_stage")) { return SecondStageMain(argc, argv); } } // 默认启动init进程第一阶段 return FirstStageMain(argc, argv); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
3.2.2 ueventd_main
代码路径:platform/system/core/init/ueventd.cpp
Android根文件系统的镜像中不存在“/dev”目录,该目录是init进程启动后动态创建的。
因此,建立Android中设备节点文件的重任,也落在了init进程身上。为此,init进程创建子进程ueventd,并将创建设备节点文件的工作托付给ueventd。
ueventd通过两种方式创建设备节点文件。
第一种方式对应“冷插拔”(Cold Plug),即以预先定义的设备信息为基础,当ueventd启动后,统一创建设备节点文件。这一类设备节点文件也被称为静态节点文件。
第二种方式对应“热插拔”(Hot Plug),即在系统运行中,当有设备插入USB端口时,ueventd就会接收到这一事件,为插入的设备动态创建设备节点文件。这一类设备节点文件也被称为动态节点文件。
int ueventd_main(int argc, char** argv) { //设置新建文件的默认值,这个与chmod相反,这里相当于新建文件后的权限为666 umask(000); //初始化内核日志,位于节点/dev/kmsg, 此时logd、logcat进程还没有起来, //采用kernel的log系统,打开的设备节点/dev/kmsg, 那么可通过cat /dev/kmsg来获取内核log。 android::base::InitLogging(argv, &android::base::KernelLogger); //注册selinux相关的用于打印log的回调函数 SelinuxSetupKernelLogging(); SelabelInitialize(); //解析xml,根据不同SOC厂商获取不同的hardware rc文件 auto ueventd_configuration = ParseConfig({"/ueventd.rc", "/vendor/ueventd.rc", "/odm/ueventd.rc", "/ueventd." + hardware + ".rc"}); //冷启动 if (access(COLDBOOT_DONE, F_OK) != 0) { ColdBoot cold_boot(uevent_listener, uevent_handlers); cold_boot.Run(); } for (auto& uevent_handler : uevent_handlers) { uevent_handler->ColdbootDone(); } //忽略子进程终止信号 signal(SIGCHLD, SIG_IGN); // Reap and pending children that exited between the last call to waitpid() and setting SIG_IGN // for SIGCHLD above. //在最后一次调用waitpid()和为上面的sigchld设置SIG_IGN之间退出的获取和挂起的子级 while (waitpid(-1, nullptr, WNOHANG) > 0) { } //监听来自驱动的uevent,进行“热插拔”处理 uevent_listener.Poll([&uevent_handlers](const Uevent& uevent) { for (auto& uevent_handler : uevent_handlers) { uevent_handler->HandleUevent(uevent); //热启动,创建设备 } return ListenerAction::kContinue; }); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
3.2.3 init 进程启动第一阶段
代码路径:platform\system\core\init\first_stage_init.cpp
init进程第一阶段做的主要工作是挂载分区,创建设备节点和一些关键目录,初始化日志输出系统,启用SELinux安全策略
第一阶段完成以下内容:
- 01.创建文件系统目录并挂载相关的文件系统
- 02.屏蔽标准的输入输出/初始化内核log系统
3.2.3.1 FirstStageMain
int FirstStageMain(int argc, char** argv) { //init crash时重启引导加载程序 //这个函数主要作用将各种信号量,如SIGABRT,SIGBUS等的行为设置为SA_RESTART,一旦监听到这些信号即执行重启系统 if (REBOOT_BOOTLOADER_ON_PANIC) { InstallRebootSignalHandlers(); } //清空文件权限 umask(0); CHECKCALL(clearenv()); CHECKCALL(setenv("PATH", _PATH_DEFPATH, 1)); //在RAM内存上获取基本的文件系统,剩余的被rc文件所用 CHECKCALL(mount("tmpfs", "/dev", "tmpfs", MS_NOSUID, "mode=0755")); CHECKCALL(mkdir("/dev/pts", 0755)); CHECKCALL(mkdir("/dev/socket", 0755)); CHECKCALL(mount("devpts", "/dev/pts", "devpts", 0, NULL)); #define MAKE_STR(x) __STRING(x) CHECKCALL(mount("proc", "/proc", "proc", 0, "hidepid=2,gid=" MAKE_STR(AID_READPROC))); #undef MAKE_STR // 非特权应用不能使用Andrlid cmdline CHECKCALL(chmod("/proc/cmdline", 0440)); gid_t groups[] = {AID_READPROC}; CHECKCALL(setgroups(arraysize(groups), groups)); CHECKCALL(mount("sysfs", "/sys", "sysfs", 0, NULL)); CHECKCALL(mount("selinuxfs", "/sys/fs/selinux", "selinuxfs", 0, NULL)); CHECKCALL(mknod("/dev/kmsg", S_IFCHR | 0600, makedev(1, 11))); if constexpr (WORLD_WRITABLE_KMSG) { CHECKCALL(mknod("/dev/kmsg_debug", S_IFCHR | 0622, makedev(1, 11))); } CHECKCALL(mknod("/dev/random", S_IFCHR | 0666, makedev(1, 8))); CHECKCALL(mknod("/dev/urandom", S_IFCHR | 0666, makedev(1, 9))); //这对于日志包装器是必需的,它在ueventd运行之前被调用 CHECKCALL(mknod("/dev/ptmx", S_IFCHR | 0666, makedev(5, 2))); CHECKCALL(mknod("/dev/null", S_IFCHR | 0666, makedev(1, 3))); //在第一阶段挂在tmpfs、mnt/vendor、mount/product分区。其他的分区不需要在第一阶段加载, //只需要在第二阶段通过rc文件解析来加载。 CHECKCALL(mount("tmpfs", "/mnt", "tmpfs", MS_NOEXEC | MS_NOSUID | MS_NODEV, "mode=0755,uid=0,gid=1000")); //创建可供读写的vendor目录 CHECKCALL(mkdir("/mnt/vendor", 0755)); // /mnt/product is used to mount product-specific partitions that can not be // part of the product partition, e.g. because they are mounted read-write. CHECKCALL(mkdir("/mnt/product", 0755)); // 挂载APEX,这在Android 10.0中特殊引入,用来解决碎片化问题,类似一种组件方式,对Treble的增强, // 不写谷歌特殊更新不需要完整升级整个系统版本,只需要像升级APK一样,进行APEX组件升级 CHECKCALL(mount("tmpfs", "/apex", "tmpfs", MS_NOEXEC | MS_NOSUID | MS_NODEV, "mode=0755,uid=0,gid=0")); // /debug_ramdisk is used to preserve additional files from the debug ramdisk CHECKCALL(mount("tmpfs", "/debug_ramdisk", "tmpfs", MS_NOEXEC | MS_NOSUID | MS_NODEV, "mode=0755,uid=0,gid=0")); #undef CHECKCALL //把标准输入、标准输出和标准错误重定向到空设备文件"/dev/null" SetStdioToDevNull(argv); //在/dev目录下挂载好 tmpfs 以及 kmsg //这样就可以初始化 /kernel Log 系统,供用户打印log InitKernelLogging(argv); ... /* 初始化一些必须的分区 *主要作用是去解析/proc/device-tree/firmware/android/fstab, * 然后得到"/system", "/vendor", "/odm"三个目录的挂载信息 */ if (!DoFirstStageMount()) { LOG(FATAL) << "Failed to mount required partitions early ..."; } struct stat new_root_info; if (stat("/", &new_root_info) != 0) { PLOG(ERROR) << "Could not stat(\"/\"), not freeing ramdisk"; old_root_dir.reset(); } if (old_root_dir && old_root_info.st_dev != new_root_info.st_dev) { FreeRamdisk(old_root_dir.get(), old_root_info.st_dev); } SetInitAvbVersionInRecovery(); static constexpr uint32_t kNanosecondsPerMillisecond = 1e6; uint64_t start_ms = start_time.time_since_epoch().count() / kNanosecondsPerMillisecond; setenv("INIT_STARTED_AT", std::to_string(start_ms).c_str(), 1); //启动init进程,传入参数selinux_steup // 执行命令: /system/bin/init selinux_setup const char* path = "/system/bin/init"; const char* args[] = {path, "selinux_setup", nullptr}; execv(path, const_cast<char**>(args)); PLOG(FATAL) << "execv(\"" << path << "\") failed"; return 1; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
3.2.4 加载SELinux规则
SELinux是「Security-Enhanced Linux」的简称,是美国国家安全局「NSA=The National Security Agency」
和SCC(Secure Computing Corporation)开发的 Linux的一个扩张强制访问控制安全模块。
在这种访问控制体系的限制下,进程只能访问那些在他的任务中所需要文件。
selinux有两种工作模式:
permissive,所有的操作都被允许(即没有MAC),但是如果违反权限的话,会记录日志,一般eng模式用
enforcing,所有操作都会进行权限检查。一般user和user-debug模式用
不管是security_setenforce还是security_getenforce都是去操作/sys/fs/selinux/enforce 文件, 0表示permissive 1表示enforcing
3.2.4.1 SetupSelinux
说明:初始化selinux,加载SELinux规则,配置SELinux相关log输出,并启动第二阶段
代码路径: platform\system\core\init\selinux.cpp
/此函数初始化selinux,然后执行init以在init selinux中运行/
int SetupSelinux(char** argv) { //初始化Kernel日志 InitKernelLogging(argv); // Debug版本init crash时重启引导加载程序 if (REBOOT_BOOTLOADER_ON_PANIC) { InstallRebootSignalHandlers(); } //注册回调,用来设置需要写入kmsg的selinux日志 SelinuxSetupKernelLogging(); //加载SELinux规则 SelinuxInitialize(); /* *我们在内核域中,希望转换到init域。在其xattrs中存储selabel的文件系统(如ext4)不需要显式restorecon, *但其他文件系统需要。尤其是对于ramdisk,如对于a/b设备的恢复映像,这是必需要做的一步。 *其实就是当前在内核域中,在加载Seliux后,需要重新执行init切换到C空间的用户态 */ if (selinux_android_restorecon("/system/bin/init", 0) == -1) { PLOG(FATAL) << "restorecon failed of /system/bin/init failed"; } //准备启动innit进程,传入参数second_stage const char* path = "/system/bin/init"; const char* args[] = {path, "second_stage", nullptr}; execv(path, const_cast<char**>(args)); /* *执行 /system/bin/init second_stage, 进入第二阶段 */ PLOG(FATAL) << "execv(\"" << path << "\") failed"; return 1; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
3.2.4.2 SelinuxInitialize()
/*加载selinux 规则*/ void SelinuxInitialize() { LOG(INFO) << "Loading SELinux policy"; if (!LoadPolicy()) { LOG(FATAL) << "Unable to load SELinux policy"; } //获取当前Kernel的工作模式 bool kernel_enforcing = (security_getenforce() == 1); //获取工作模式的配置 bool is_enforcing = IsEnforcing(); //如果当前的工作模式与配置的不同,就将当前的工作模式改掉 if (kernel_enforcing != is_enforcing) { if (security_setenforce(is_enforcing)) { PLOG(FATAL) << "security_setenforce(" << (is_enforcing ? "true" : "false") << ") failed"; } } if (auto result = WriteFile("/sys/fs/selinux/checkreqprot", "0"); !result) { LOG(FATAL) << "Unable to write to /sys/fs/selinux/checkreqprot: " << result.error(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
/*
*加载SELinux规则
*这里区分了两种情况,这两种情况只是区分从哪里加载安全策略文件,
*第一个是从 /vendor/etc/selinux/precompiled_sepolicy 读取,
*第二个是从 /sepolicy 读取,他们最终都是调用selinux_android_load_policy_from_fd方法
*/
bool LoadPolicy() {
return IsSplitPolicyDevice() ? LoadSplitPolicy() : LoadMonolithicPolicy();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.2.5 init进程启动第二阶段
第二阶段主要内容:
- 创建进程会话密钥并初始化属性系统
- 进行SELinux第二阶段并恢复一些文件安全上下文
- 新建epoll并初始化子进程终止信号处理函数,详细看第五节-信号处理
- 启动匹配属性的服务端, 详细查看第六节-属性服务
- 解析init.rc等文件,建立rc文件的action 、service,启动其他进程,详细查看第七节-rc文件解析

3.2.5.1 SecondStageMain
int SecondStageMain(int argc, char** argv) { /* 01. 创建进程会话密钥并初始化属性系统 */ keyctl_get_keyring_ID(KEY_SPEC_SESSION_KEYRING, 1); //创建 /dev/.booting 文件,就是个标记,表示booting进行中 close(open("/dev/.booting", O_WRONLY | O_CREAT | O_CLOEXEC, 0000)); // 初始化属性系统,并从指定文件读取属性 property_init(); /* 02. 进行SELinux第二阶段并恢复一些文件安全上下文 */ SelinuxRestoreContext(); /* 03. 新建epoll并初始化子进程终止信号处理函数 */ Epoll epoll; if (auto result = epoll.Open(); !result) { PLOG(FATAL) << result.error(); } InstallSignalFdHandler(&epoll); /* 04. 设置其他系统属性并开启系统属性服务*/ StartPropertyService(&epoll); /* 05 解析init.rc等文件,建立rc文件的action 、service,启动其他进程*/ ActionManager& am = ActionManager::GetInstance(); ServiceList& sm = ServiceList::GetInstance(); LoadBootScripts(am, sm); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
代码流程详细解析:
int SecondStageMain(int argc, char** argv) { /* *init crash时重启引导加载程序 *这个函数主要作用将各种信号量,如SIGABRT,SIGBUS等的行为设置为SA_RESTART,一旦监听到这些信号即执行重启系统 */ if (REBOOT_BOOTLOADER_ON_PANIC) { InstallRebootSignalHandlers(); } //把标准输入、标准输出和标准错误重定向到空设备文件"/dev/null" SetStdioToDevNull(argv); //在/dev目录下挂载好 tmpfs 以及 kmsg //这样就可以初始化 /kernel Log 系统,供用户打印log InitKernelLogging(argv); LOG(INFO) << "init second stage started!"; // 01. 创建进程会话密钥并初始化属性系统 keyctl_get_keyring_ID(KEY_SPEC_SESSION_KEYRING, 1); //创建 /dev/.booting 文件,就是个标记,表示booting进行中 close(open("/dev/.booting", O_WRONLY | O_CREAT | O_CLOEXEC, 0000)); // 初始化属性系统,并从指定文件读取属性 property_init(); /* * 1.如果参数同时从命令行和DT传过来,DT的优先级总是大于命令行的 * 2.DT即device-tree,中文意思是设备树,这里面记录自己的硬件配置和系统运行参数, */ process_kernel_dt(); // 处理 DT属性 process_kernel_cmdline(); // 处理命令行属性 // 处理一些其他的属性 export_kernel_boot_props(); // Make the time that init started available for bootstat to log. property_set("ro.boottime.init", getenv("INIT_STARTED_AT")); property_set("ro.boottime.init.selinux", getenv("INIT_SELINUX_TOOK")); // Set libavb version for Framework-only OTA match in Treble build. const char* avb_version = getenv("INIT_AVB_VERSION"); if (avb_version) property_set("ro.boot.avb_version", avb_version); // See if need to load debug props to allow adb root, when the device is unlocked. const char* force_debuggable_env = getenv("INIT_FORCE_DEBUGGABLE"); if (force_debuggable_env && AvbHandle::IsDeviceUnlocked()) { load_debug_prop = "true"s == force_debuggable_env; } // 基于cmdline设置memcg属性 bool memcg_enabled = android::base::GetBoolProperty("ro.boot.memcg",false); if (memcg_enabled) { // root memory control cgroup mkdir("/dev/memcg", 0700); chown("/dev/memcg",AID_ROOT,AID_SYSTEM); mount("none", "/dev/memcg", "cgroup", 0, "memory"); // app mem cgroups, used by activity manager, lmkd and zygote mkdir("/dev/memcg/apps/",0755); chown("/dev/memcg/apps/",AID_SYSTEM,AID_SYSTEM); mkdir("/dev/memcg/system",0550); chown("/dev/memcg/system",AID_SYSTEM,AID_SYSTEM); } // 清空这些环境变量,之前已经存到了系统属性中去了 unsetenv("INIT_STARTED_AT"); unsetenv("INIT_SELINUX_TOOK"); unsetenv("INIT_AVB_VERSION"); unsetenv("INIT_FORCE_DEBUGGABLE"); // Now set up SELinux for second stage. SelinuxSetupKernelLogging(); SelabelInitialize(); /* * 02. 进行SELinux第二阶段并恢复一些文件安全上下文 * 恢复相关文件的安全上下文,因为这些文件是在SELinux安全机制初始化前创建的, * 所以需要重新恢复上下文 */ SelinuxRestoreContext(); /* * 03. 新建epoll并初始化子进程终止信号处理函数 * 创建epoll实例,并返回epoll的文件描述符 */ Epoll epoll; if (auto result = epoll.Open(); !result) { PLOG(FATAL) << result.error(); } /* *主要是创建handler处理子进程终止信号,注册一个signal到epoll进行监听 *进行子继承处理 */ InstallSignalFdHandler(&epoll); // 进行默认属性配置相关的工作 property_load_boot_defaults(load_debug_prop); UmountDebugRamdisk(); fs_mgr_vendor_overlay_mount_all(); export_oem_lock_status(); /* *04. 设置其他系统属性并开启系统属性服务 */ StartPropertyService(&epoll); MountHandler mount_handler(&epoll); //为USB存储设置udc Contorller, sys/class/udc set_usb_controller(); // 匹配命令和函数之间的对应关系 const BuiltinFunctionMap function_map; Action::set_function_map(&function_map); if (!SetupMountNamespaces()) { PLOG(FATAL) << "SetupMountNamespaces failed"; } // 初始化文件上下文 subcontexts = InitializeSubcontexts(); /* *05 解析init.rc等文件,建立rc文件的action 、service,启动其他进程 */ ActionManager& am = ActionManager::GetInstance(); ServiceList& sm = ServiceList::GetInstance(); LoadBootScripts(am, sm); // Turning this on and letting the INFO logging be discarded adds 0.2s to // Nexus 9 boot time, so it's disabled by default. if (false) DumpState(); // 当GSI脚本running时,确保GSI状态可用. if (android::gsi::IsGsiRunning()) { property_set("ro.gsid.image_running", "1"); } else { property_set("ro.gsid.image_running", "0"); } am.QueueBuiltinAction(SetupCgroupsAction, "SetupCgroups"); // 执行rc文件中触发器为 on early-init 的语句 am.QueueEventTrigger("early-init"); // 等冷插拔设备初始化完成 am.QueueBuiltinAction(wait_for_coldboot_done_action, "wait_for_coldboot_done"); // 开始查询来自 /dev的 action am.QueueBuiltinAction(MixHwrngIntoLinuxRngAction, "MixHwrngIntoLinuxRng"); am.QueueBuiltinAction(SetMmapRndBitsAction, "SetMmapRndBits"); am.QueueBuiltinAction(SetKptrRestrictAction, "SetKptrRestrict"); // 设备组合键的初始化操作 Keychords keychords; am.QueueBuiltinAction( [&epoll, &keychords](const BuiltinArguments& args) -> Result<Success> { for (const auto& svc : ServiceList::GetInstance()) { keychords.Register(svc->keycodes()); } keychords.Start(&epoll, HandleKeychord); return Success(); }, "KeychordInit"); //在屏幕上显示Android 静态LOGO am.QueueBuiltinAction(console_init_action, "console_init"); // 执行rc文件中触发器为on init的语句 am.QueueEventTrigger("init"); // Starting the BoringSSL self test, for NIAP certification compliance. am.QueueBuiltinAction(StartBoringSslSelfTest, "StartBoringSslSelfTest"); // Repeat mix_hwrng_into_linux_rng in case /dev/hw_random or /dev/random // wasn't ready immediately after wait_for_coldboot_done am.QueueBuiltinAction(MixHwrngIntoLinuxRngAction, "MixHwrngIntoLinuxRng"); // Initialize binder before bringing up other system services am.QueueBuiltinAction(InitBinder, "InitBinder"); // 当设备处于充电模式时,不需要mount文件系统或者启动系统服务 // 充电模式下,将charger假如执行队列,否则把late-init假如执行队列 std::string bootmode = GetProperty("ro.bootmode", ""); if (bootmode == "charger") { am.QueueEventTrigger("charger"); } else { am.QueueEventTrigger("late-init"); } // 基于属性当前状态 运行所有的属性触发器. am.QueueBuiltinAction(queue_property_triggers_action, "queue_property_triggers"); while (true) { // By default, sleep until something happens. auto epoll_timeout = std::optional<std::chrono::milliseconds>{}; if (do_shutdown && !shutting_down) { do_shutdown = false; if (HandlePowerctlMessage(shutdown_command)) { shutting_down = true; } } //依次执行每个action中携带command对应的执行函数 if (!(waiting_for_prop || Service::is_exec_service_running())) { am.ExecuteOneCommand(); } if (!(waiting_for_prop || Service::is_exec_service_running())) { if (!shutting_down) { auto next_process_action_time = HandleProcessActions(); // If there's a process that needs restarting, wake up in time for that. if (next_process_action_time) { epoll_timeout = std::chrono::ceil<std::chrono::milliseconds>( *next_process_action_time - boot_clock::now()); if (*epoll_timeout < 0ms) epoll_timeout = 0ms; } } // If there's more work to do, wake up again immediately. if (am.HasMoreCommands()) epoll_timeout = 0ms; } // 循环等待事件发生 if (auto result = epoll.Wait(epoll_timeout); !result) { LOG(ERROR) << result.error(); } } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
3.3. 信号处理
init是一个守护进程,为了防止init的子进程成为僵尸进程(zombie process),需要init在子进程在结束时获取子进程的结束码,通过结束码将程序表中的子进程移除,防止成为僵尸进程的子进程占用程序表的空间(程序表的空间达到上限时,系统就不能再启动新的进程了,会引起严重的系统问题)。
子进程重启流程如下图所示:

信号处理主要工作:
- 初始化信号signal句柄
- 循环处理子进程
- 注册epoll句柄
- 处理子进程终止
注: EPOLL类似于POLL,是Linux中用来做事件触发的,跟EventBus功能差不多。linux很长的时间都在使用select来做事件触发,它是通过轮询来处理的,轮询的fd数目越多,自然耗时越多,对于大量的描述符处理,EPOLL更有优势
3.3.1 InstallSignalFdHandler
在linux当中,父进程是通过捕捉SIGCHLD信号来得知子进程运行结束的情况,SIGCHLD信号会在子进程终止的时候发出,了解这些背景后,我们来看看init进程如何处理这个信号。
首先,新建一个sigaction结构体,sa_handler是信号处理函数,指向内核指定的函数指针SIG_DFL和Android 9.0及之前的版本不同,这里不再通过socket的读写句柄进行接收信号,改成了内核的信号处理函数SIG_DFL。
然后,sigaction(SIGCHLD, &act, nullptr) 这个是建立信号绑定关系,也就是说当监听到SIGCHLD信号时,由act这个sigaction结构体处理
最后,RegisterHandler 的作用就是signal_read_fd(之前的s[1])收到信号,触发handle_signal
终上所述,InstallSignalFdHandler函数的作用就是,接收到SIGCHLD信号时触发HandleSignalFd进行信号处理
信号处理示意图:

代码路径:platform/system/core/init.cpp
说明:该函数主要的作用是初始化子进程终止信号处理过程
static void InstallSignalFdHandler(Epoll* epoll) { // SA_NOCLDSTOP使init进程只有在其子进程终止时才会受到SIGCHLD信号 const struct sigaction act { .sa_handler = SIG_DFL, .sa_flags = SA_NOCLDSTOP }; sigaction(SIGCHLD, &act, nullptr); sigset_t mask; sigemptyset(&mask); sigaddset(&mask, SIGCHLD); if (!IsRebootCapable()) { // 如果init不具有 CAP_SYS_BOOT的能力,则它此时正值容器中运行 // 在这种场景下,接收SIGTERM 将会导致系统关闭 sigaddset(&mask, SIGTERM); } if (sigprocmask(SIG_BLOCK, &mask, nullptr) == -1) { PLOG(FATAL) << "failed to block signals"; } // 注册处理程序以解除对子进程中的信号的阻止 const int result = pthread_atfork(nullptr, nullptr, &UnblockSignals); if (result != 0) { LOG(FATAL) << "Failed to register a fork handler: " << strerror(result); } //创建信号句柄 signal_fd = signalfd(-1, &mask, SFD_CLOEXEC); if (signal_fd == -1) { PLOG(FATAL) << "failed to create signalfd"; } //信号注册,当signal_fd收到信号时,触发HandleSignalFd if (auto result = epoll->RegisterHandler(signal_fd, HandleSignalFd); !result) { LOG(FATAL) << result.error(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3.3.2 RegisterHandler
代码路径:/platform/system/core/epoll.cpp
说明:信号注册,把fd句柄加入到 epoll_fd_的监听队列中
Result Epoll::RegisterHandler(int fd, std::function<void()> handler, uint32_t events) {
if (!events) {
return Error() << “Must specify events”;
}
auto [it, inserted] = epoll_handlers_.emplace(fd, std::move(handler));
if (!inserted) {
return Error() << “Cannot specify two epoll handlers for a given FD”;
}
epoll_event ev;
ev.events = events;
// std::map’s iterators do not get invalidated until erased, so we use the
// pointer to the std::function in the map directly for epoll_ctl.
ev.data.ptr = reinterpret_cast<void*>(&it->second);
// 将fd的可读事件加入到epoll_fd_的监听队列中
if (epoll_ctl(epoll_fd_, EPOLL_CTL_ADD, fd, &ev) == -1) {
Result result = ErrnoError() << “epoll_ctl failed to add fd”;
epoll_handlers_.erase(fd);
return result;
}
return {};
}
3.3.3 HandleSignalFd
代码路径:platform/system/core/init.cpp
说明:监控SIGCHLD信号,调用 ReapAnyOutstandingChildren 来 终止出现问题的子进程
static void HandleSignalFd() {
signalfd_siginfo siginfo;
ssize_t bytes_read = TEMP_FAILURE_RETRY(read(signal_fd, &siginfo, sizeof(siginfo)));
if (bytes_read != sizeof(siginfo)) {
PLOG(ERROR) << “Failed to read siginfo from signal_fd”;
return;
}
//监控SIGCHLD信号
switch (siginfo.ssi_signo) {
case SIGCHLD:
ReapAnyOutstandingChildren();
break;
case SIGTERM:
HandleSigtermSignal(siginfo);
break;
default:
PLOG(ERROR) << "signal_fd: received unexpected signal " << siginfo.ssi_signo;
break;
}
}
3.3.4 ReapOneProcess
代码路径:/platform/system/core/sigchld_handle.cpp
说明:ReapOneProcess是最终的处理函数了,这个函数先用waitpid找出挂掉进程的pid,然后根据pid找到对应Service,最后调用Service的Reap方法清除资源,根据进程对应的类型,决定是否重启机器或重启进程
void ReapAnyOutstandingChildren() { while (ReapOneProcess()) { } } static bool ReapOneProcess() { siginfo_t siginfo = {}; //用waitpid函数获取状态发生变化的子进程pid //waitpid的标记为WNOHANG,即非阻塞,返回为正值就说明有进程挂掉了 if (TEMP_FAILURE_RETRY(waitid(P_ALL, 0, &siginfo, WEXITED | WNOHANG | WNOWAIT)) != 0) { PLOG(ERROR) << "waitid failed"; return false; } auto pid = siginfo.si_pid; if (pid == 0) return false; // 当我们知道当前有一个僵尸pid,我们使用scopeguard来清楚该pid auto reaper = make_scope_guard([pid] { TEMP_FAILURE_RETRY(waitpid(pid, nullptr, WNOHANG)); }); std::string name; std::string wait_string; Service* service = nullptr; if (SubcontextChildReap(pid)) { name = "Subcontext"; } else { //通过pid找到对应的service service = ServiceList::GetInstance().FindService(pid, &Service::pid); if (service) { name = StringPrintf("Service '%s' (pid %d)", service->name().c_str(), pid); if (service->flags() & SVC_EXEC) { auto exec_duration = boot_clock::now() - service->time_started(); auto exec_duration_ms = std::chrono::duration_cast<std::chrono::milliseconds>(exec_duration).count(); wait_string = StringPrintf(" waiting took %f seconds", exec_duration_ms / 1000.0f); } else if (service->flags() & SVC_ONESHOT) { auto exec_duration = boot_clock::now() - service->time_started(); auto exec_duration_ms = std::chrono::duration_cast<std::chrono::milliseconds>(exec_duration) .count(); wait_string = StringPrintf(" oneshot service took %f seconds in background",exec_duration_ms / 1000.0f); } } else { name = StringPrintf("Untracked pid %d", pid); } } if (siginfo.si_code == CLD_EXITED) { LOG(INFO) << name << " exited with status " << siginfo.si_status << wait_string; } else { LOG(INFO) << name << " received signal " << siginfo.si_status << wait_string; } //没有找到service,说明已经结束了,退出 if (!service) return true; service->Reap(siginfo);//清除子进程相关的资源 if (service->flags() & SVC_TEMPORARY) { ServiceList::GetInstance().RemoveService(*service); //移除该service } return true; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
3.4.属性服务
我们在开发和调试过程中看到通过property_set可以轻松设置系统属性,那干嘛这里还要启动一个属性服务呢?这里其实涉及到一些权限的问题,不是所有进程都可以随意修改任何的系统属性,
Android将属性的设置统一交由init进程管理,其他进程不能直接修改属性,而只能通知init进程来修改,而在这过程中,init进程可以进行权限控制,我们来看看具体的流程是什么
3.4.1 property_init
代码路径:platform/system/core/property_service.cpp
说明:初始化属性系统,并从指定文件读取属性,并进行SELinux注册,进行属性权限控制
清除缓存,这里主要是清除几个链表以及在内存中的映射,新建property_filename目录,这个目录的值为 /dev/properties
然后就是调用CreateSerializedPropertyInfo加载一些系统属性的类别信息,最后将加载的链表写入文件并映射到内存
void property_init() { //设置SELinux回调,进行权限控制 selinux_callback cb; cb.func_audit = PropertyAuditCallback; selinux_set_callback(SELINUX_CB_AUDIT, cb); mkdir("/dev/__properties__", S_IRWXU | S_IXGRP | S_IXOTH); CreateSerializedPropertyInfo(); if (__system_property_area_init()) { LOG(FATAL) << "Failed to initialize property area"; } if (!property_info_area.LoadDefaultPath()) { LOG(FATAL) << "Failed to load serialized property info file"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
通过CreateSerializedPropertyInfo 来加载以下目录的contexts:
1)与SELinux相关
/system/etc/selinux/plat_property_contexts
/vendor/etc/selinux/vendor_property_contexts
/vendor/etc/selinux/nonplat_property_contexts
/product/etc/selinux/product_property_contexts
/odm/etc/selinux/odm_property_contexts
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2)与SELinux无关
/plat_property_contexts
/vendor_property_contexts
/nonplat_property_contexts
/product_property_contexts
/odm_property_contexts
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.4.2 StartPropertyService
代码路径: platform/system/core/init.cpp
说明:启动属性服务
首先创建一个socket并返回文件描述符,然后设置最大并发数为8,其他进程可以通过这个socket通知init进程修改系统属性,
最后注册epoll事件,也就是当监听到property_set_fd改变时调用handle_property_set_fd
void StartPropertyService(Epoll* epoll) { property_set("ro.property_service.version", "2"); //建立socket连接 if (auto result = CreateSocket(PROP_SERVICE_NAME, SOCK_STREAM | SOCK_CLOEXEC | SOCK_NONBLOCK, false, 0666, 0, 0, {})) { property_set_fd = *result; } else { PLOG(FATAL) << "start_property_service socket creation failed: " << result.error(); } // 最大监听8个并发 listen(property_set_fd, 8); // 注册property_set_fd,当收到句柄改变时,通过handle_property_set_fd来处理 if (auto result = epoll->RegisterHandler(property_set_fd, handle_property_set_fd); !result) { PLOG(FATAL) << result.error(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.4.3 handle_property_set_fd
代码路径:platform/system/core/property_service.cpp
说明:建立socket连接,然后从socket中读取操作信息,根据不同的操作类型,调用HandlePropertySet做具体的操作
HandlePropertySet是最终的处理函数,以"ctl"开头的key就做一些Service的Start,Stop,Restart操作,其他的就是调用property_set进行属性设置,不管是前者还是后者,都要进行SELinux安全性检查,只有该进程有操作权限才能执行相应操作
static void handle_property_set_fd() { static constexpr uint32_t kDefaultSocketTimeout = 2000; /* ms */ // 等待客户端连接 int s = accept4(property_set_fd, nullptr, nullptr, SOCK_CLOEXEC); if (s == -1) { return; } ucred cr; socklen_t cr_size = sizeof(cr); // 获取连接到此socket的进程的凭据 if (getsockopt(s, SOL_SOCKET, SO_PEERCRED, &cr, &cr_size) < 0) { close(s); PLOG(ERROR) << "sys_prop: unable to get SO_PEERCRED"; return; } // 建立socket连接 SocketConnection socket(s, cr); uint32_t timeout_ms = kDefaultSocketTimeout; uint32_t cmd = 0; // 读取socket中的操作信息 if (!socket.RecvUint32(&cmd, &timeout_ms)) { PLOG(ERROR) << "sys_prop: error while reading command from the socket"; socket.SendUint32(PROP_ERROR_READ_CMD); return; } // 根据操作信息,执行对应处理,两者区别一个是以char形式读取,一个以String形式读取 switch (cmd) { case PROP_MSG_SETPROP: { char prop_name[PROP_NAME_MAX]; char prop_value[PROP_VALUE_MAX]; if (!socket.RecvChars(prop_name, PROP_NAME_MAX, &timeout_ms) || !socket.RecvChars(prop_value, PROP_VALUE_MAX, &timeout_ms)) { PLOG(ERROR) << "sys_prop(PROP_MSG_SETPROP): error while reading name/value from the socket"; return; } prop_name[PROP_NAME_MAX-1] = 0; prop_value[PROP_VALUE_MAX-1] = 0; std::string source_context; if (!socket.GetSourceContext(&source_context)) { PLOG(ERROR) << "Unable to set property '" << prop_name << "': getpeercon() failed"; return; } const auto& cr = socket.cred(); std::string error; uint32_t result = HandlePropertySet(prop_name, prop_value, source_context, cr, &error); if (result != PROP_SUCCESS) { LOG(ERROR) << "Unable to set property '" << prop_name << "' from uid:" << cr.uid << " gid:" << cr.gid << " pid:" << cr.pid << ": " << error; } break; } case PROP_MSG_SETPROP2: { std::string name; std::string value; if (!socket.RecvString(&name, &timeout_ms) || !socket.RecvString(&value, &timeout_ms)) { PLOG(ERROR) << "sys_prop(PROP_MSG_SETPROP2): error while reading name/value from the socket"; socket.SendUint32(PROP_ERROR_READ_DATA); return; } std::string source_context; if (!socket.GetSourceContext(&source_context)) { PLOG(ERROR) << "Unable to set property '" << name << "': getpeercon() failed"; socket.SendUint32(PROP_ERROR_PERMISSION_DENIED); return; } const auto& cr = socket.cred(); std::string error; uint32_t result = HandlePropertySet(name, value, source_context, cr, &error); if (result != PROP_SUCCESS) { LOG(ERROR) << "Unable to set property '" << name << "' from uid:" << cr.uid << " gid:" << cr.gid << " pid:" << cr.pid << ": " << error; } socket.SendUint32(result); break; } default: LOG(ERROR) << "sys_prop: invalid command " << cmd; socket.SendUint32(PROP_ERROR_INVALID_CMD); break; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
3.5.第三阶段init.rc
当属性服务建立完成后,init的自身功能基本就告一段落,接下来需要来启动其他的进程。但是init进程如何其他其他进程呢?其他进程都是一个二进制文件,我们可以直接通过exec的命令方式来启动,例如 ./system/bin/init second_stage,来启动init进程的第二阶段。但是Android系统有那么多的Native进程,如果都通过传exec在代码中一个个的来执行进程,那无疑是一个灾难性的设计。
在这个基础上Android推出了一个init.rc的机制,即类似通过读取配置文件的方式,来启动不同的进程。接下来我们就来看看init.rc是如何工作的。
init.rc是一个配置文件,内部由Android初始化语言编写(Android Init Language)编写的脚本。
init.rc在手机的目录:./init.rc
init.rc主要包含五种类型语句:
- Action
- Command
- Service
- Option
- Import

3.5.1 Action
动作表示了一组命令(commands)组成.动作包括一个触发器,决定了何时运行这个动作
Action: 通过触发器trigger,即以on开头的语句来决定执行相应的service的时机,具体有如下时机:
- on early-init; 在初始化早期阶段触发;
- on init; 在初始化阶段触发;
- on late-init; 在初始化晚期阶段触发;
- on boot/charger: 当系统启动/充电时触发;
- on property:=: 当属性值满足条件时触发;
3.5.2 Command
command是action的命令列表中的命令,或者是service中的选项 onrestart 的参数命令,命令将在所属事件发生时被一个个地执行.
下面列举常用的命令
- class_start <service_class_name>: 启动属于同一个class的所有服务;
- class_stop <service_class_name> : 停止指定类的服务
- start <service_name>: 启动指定的服务,若已启动则跳过;
- stop <service_name>: 停止正在运行的服务
- setprop :设置属性值
- mkdir
:创建指定目录 - symlink <sym_link>: 创建连接到的<sym_link>符号链接;
- write
: 向文件path中写入字符串; - exec: fork并执行,会阻塞init进程直到程序完毕;
- exprot :设定环境变量;
- loglevel :设置log级别
- hostname : 设置主机名
- import :导入一个额外的init配置文件
3.5.3 Service
服务Service,以 service开头,由init进程启动,一般运行在init的一个子进程,所以启动service前需要判断对应的可执行文件是否存在。
命令:service [ ]*
| 参数 | 含义 |
|---|---|
| 表示此服务的名称 | |
| 此服务所在路径因为是可执行文件,所以一定有存储路径。 | |
| 启动服务所带的参数 | |
| 对此服务的约束选项 |
init生成的子进程,定义在rc文件,其中每一个service在启动时会通过fork方式生成子进程。
例如: service servicemanager /system/bin/servicemanager代表的是服务名为servicemanager,服务执行的路径为/system/bin/servicemanager。
3.5.4 Options
Options是Service的可选项,与service配合使用
- disabled: 不随class自动启动,只有根据service名才启动;
- oneshot: service退出后不再重启;
- user/group: 设置执行服务的用户/用户组,默认都是root;
- class:设置所属的类名,当所属类启动/退出时,服务也启动/停止,默认为default;
- onrestart:当服务重启时执行相应命令;
- socket: 创建名为/dev/socket/的socket
- critical: 在规定时间内该service不断重启,则系统会重启并进入恢复模式
- default: 意味着disabled=false,oneshot=false,critical=false。
3.5.5 import
用来导入其他的rc文件
命令:import
3.5.6 init.rc 解析过程
3.5.6.1 LoadBootScripts
代码路径:platform\system\core\init\init.cpp
说明:如果没有特殊配置ro.boot.init_rc,则解析./init.rc
把/system/etc/init,/product/etc/init,/product_services/etc/init,/odm/etc/init,
/vendor/etc/init 这几个路径加入init.rc之后解析的路径,在init.rc解析完成后,解析这些目录里的rc文件
static void LoadBootScripts(ActionManager& action_manager, ServiceList& service_list) { Parser parser = CreateParser(action_manager, service_list); std::string bootscript = GetProperty("ro.boot.init_rc", ""); if (bootscript.empty()) { parser.ParseConfig("/init.rc"); if (!parser.ParseConfig("/system/etc/init")) { late_import_paths.emplace_back("/system/etc/init"); } if (!parser.ParseConfig("/product/etc/init")) { late_import_paths.emplace_back("/product/etc/init"); } if (!parser.ParseConfig("/product_services/etc/init")) { late_import_paths.emplace_back("/product_services/etc/init"); } if (!parser.ParseConfig("/odm/etc/init")) { late_import_paths.emplace_back("/odm/etc/init"); } if (!parser.ParseConfig("/vendor/etc/init")) { late_import_paths.emplace_back("/vendor/etc/init"); } } else { parser.ParseConfig(bootscript); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
Android7.0后,init.rc进行了拆分,每个服务都有自己的rc文件,他们基本上都被加载到/system/etc/init,/vendor/etc/init, /odm/etc/init等目录,等init.rc解析完成后,会来解析这些目录中的rc文件,用来执行相关的动作。
代码路径:platform\system\core\init\init.cpp
说明:创建Parser解析对象,例如service、on、import对象
Parser CreateParser(ActionManager& action_manager, ServiceList& service_list) {
Parser parser;
parser.AddSectionParser(
"service", std::make_unique<ServiceParser>(&service_list, subcontexts, std::nullopt));
parser.AddSectionParser("on", std::make_unique<ActionParser>(&action_manager, subcontexts));
parser.AddSectionParser("import", std::make_unique<ImportParser>(&parser));
return parser;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.5.6.2 执行Action动作
按顺序把相关Action加入触发器队列,按顺序为 early-init -> init -> late-init. 然后在循环中,执行所有触发器队列中Action带Command的执行函数。
am.QueueEventTrigger("early-init");
am.QueueEventTrigger("init");
am.QueueEventTrigger("late-init");
...
while (true) {
if (!(waiting_for_prop || Service::is_exec_service_running())) {
am.ExecuteOneCommand();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.6 Zygote启动
从Android 5.0的版本开始,Android支持64位的编译,因此zygote本身也支持32位和64位。通过属性ro.zygote来控制不同版本的zygote进程启动。
在init.rc的import段我们看到如下代码:
import /init.${ro.zygote}.rc // 可以看出init.rc不再直接引入一个固定的文件,而是根据属性ro.zygote的内容来引入不同的文件
- 1
init.rc位于/system/core/rootdir下。在这个路径下还包括四个关于zygote的rc文件。
分别是init.zygote32.rc,init.zygote32_64.rc,init.zygote64.rc,init.zygote64_32.rc,由硬件决定调用哪个文件。
这里拿64位处理器为例,init.zygote64.rc的代码如下所示:
service zygote /system/bin/app_process64 -Xzygote /system/bin --zygote --start-system-server
class main # class是一个option,指定zygote服务的类型为main
priority -20
user root
group root readproc reserved_disk
socket zygote stream 660 root system # socket关键字表示一个option,创建一个名为dev/socket/zygote,类型为stream,权限为660的socket
socket usap_pool_primary stream 660 root system
onrestart write /sys/android_power/request_state wake # onrestart是一个option,说明在zygote重启时需要执行的command
onrestart write /sys/power/state on
onrestart restart audioserver
onrestart restart cameraserver
onrestart restart media
onrestart restart netd
onrestart restart wificond
writepid /dev/cpuset/foreground/tasks
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
service zygote /system/bin/app_process64 -Xzygote /system/bin --zygote --start-system-server 解析:
service zygote :init.zygote64.rc 中定义了一个zygote服务。 init进程就是通过这个service名称来创建zygote进程
/system/bin/app_process64 -Xzygote /system/bin --zygote --start-system-server解析:
zygote这个服务,通过执行进行/system/bin/app_process64 并传入4个参数进行运行:
- 参数1:-Xzygote 该参数将作为虚拟机启动时所需的参数
- 参数2:/system/bin 代表虚拟机程序所在目录
- 参数3:–zygote 指明以ZygoteInit.java类中的main函数作为虚拟机执行入口
- 参数4:–start-system-server 告诉Zygote进程启动systemServer进程
四、init进程在内核态下的分析(也就是kernel_init函数)
路径:kernel-4.9/init/Main.c
start_kernel->rest_init->kernel_init->kernel_init_freeable
4.1 打开控制台
代码如下:
/* Open the /dev/console on the rootfs, this should never fail */
if (sys_open((const char __user *) "/dev/console", O_RDWR, 0) < 0)
pr_err("Warning: unable to open an initial console.\n");
(void) sys_dup(0);
(void) sys_dup(0);
- 1
- 2
- 3
- 4
- 5
- 6
(1)linux系统中每个进程都有自己的一个文件描述符表,表中存储的是本进程打开的文件。
(2)linux系统中有一个设计理念:一切届是文件。所以设备也是以文件的方式来访问的。我们要访问一个设备,就要去打开这个设备对应的文件描述符。譬如/dev/fb0这个设备文件就代表LCD显示器设备,/dev/buzzer代表蜂鸣器设备,/dev/console代表控制台设备。打开一个设备的文件就会得到这个设备的文件描述符(或者是文件描述符的编号),这个编号就代表这个设备,以后操作这个设备就用这个文件描述符来操作它
(3)这里我们打开了/dev/console文件,并且复制了2次文件描述符,一共得到了3个文件描述符。这三个文件描述符分别是0、1、2.这三个文件描述符就是所谓的:标准输入、标准输出、标准错误。
(4)进程1打开了三个标准输出输出错误文件,因此后续的进程1衍生出来的所有的进程默认都具有这3个三件描述符
4.2:挂载根文件系统
linux中每个应用程序是存放在根文件系统里面
代码如下
if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
if (sys_access((const char __user *) ramdisk_execute_command, 0) != 0) {
ramdisk_execute_command = NULL;
prepare_namespace();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(1)prepare_namespace函数中挂载根文件系统
(2)根文件系统在哪里?根文件系统的文件系统类型是什么? uboot通过传参来告诉内核这些信息。uboot传参中的root=/dev/mmcblk0p2 rw 这一句就是告诉内核根文件系统在哪里uboot传参中的rootfstype=ext3这一句就是告诉内核rootfs的类型。
(3)如果内核挂载根文件系统成功,则会打印出:VFS: Mounted root (ext3 filesystem) on device 179:2.如果挂载根文件系统失败,则会打印:No filesystem could mount root, tried: yaffs2
(4)如果内核启动时挂载rootfs失败,则后面肯定没法执行了。内核中设置了启动失败休息5s自动重启的机制,因此这里会自动重启,所以有时候大家会看到反复重启的情况。
(5)如果挂载rootfs失败,可能的原因有:最常见的错误就是uboot的bootargs设置不对。rootfs烧录失败(fastboot烧录不容易出错,以前是手工烧录很容易出错)rootfs本身制作失败的。(尤其是自己做的rootfs,或者别人给的第一次用)
四、流程图
(此流程图是引用他人的,Linux4.9与此稍有差别,如init_post,但总体是一样的)
以下为内核启动流程图:

总结:linux内核的启动过程,这里是从start_kernel到init,从而来理解linux的第一个进程及后面进程的产生过程。整个linux系统的所有进程是一个树形结 构。树根是系统自动构造的,树根即是0号进程 。Linux一开始先在无进程的情况下将一直从初始化部分的代码执行到start_kernel,然后再到其最后一个函数调用rest_init。从rest_init开始,Linux开始产生进程,在rest_init中,通过init_task产生pid=0的进程,即0号进程(idle进程),它是内核状态下的进程;在rest_init函数中,内核通过kernel_ini创建1号进程,它是第一个用户态进程。关于init_task(也就是idle),当运行队列中没有别的就绪进程时,init_task(也就是idle)将会被调用,它的核心是一个while(1)循环,在循环中它将会调用schedule函数以便在运行队列中有新进程加入时切换到该新进程上
参考:
[1]:https://blog.csdn.net/perfect1t/article/details/81741531
[2]:https://blog.csdn.net/chenliang0224/article/details/78747117
[3]:module_init分析不错,可参考:https://blog.csdn.net/Richard_LiuJH/article/details/46758073
[4]:driver_init分析:https://www.cnblogs.com/helloahui/p/3551231.html
[5]:Android 10.0系统启动之init进程-[Android取经之路]https://blog.csdn.net/yiranfeng/article/details/103549394

