
- 1python 爬虫爬取地理空间高程图GDEMV2 30m 中国地形
- 2c++课程设计(学生课程学分信息管理)_(1)能从键盘输入某位学生的信息(不包含学分)。(2)给定学号,显示该学生的所完
- 3已解决ERROR: pip’s dependency resolver does not currently take into account all the packages异常的正确解决方法,亲_pip's dependency resolver does not currently take
- 4python编程自动化实例_Python自动化开发学习8
- 5ffmpeg 提取视频文件关键帧
- 6【QT入门】VS qt和QtCreator项目的相互转换
- 720道常见的kafka面试题以及答案_kafka运维面试问题
- 8Zabbix 3.4过滤多余的windows网卡监控
- 9jieba分词浅析---关键词提取_jieba关键词提取
- 10【JS 逆向百例】吾爱破解2022春节解题领红包之番外篇 Web 中级题解
AI框架:9大主流分布式深度学习框架简介
赞
踩
前言
转载翻译Medium上一篇关于分布式深度学习框架的文章 https://medium.com/@mlblogging.k/9-libraries-for-parallel-distributed-training-inference-of-deep-learning-models-5faa86199c1fmedium.com/@mlblogging.k/9-libraries-for-parallel-distributed-training-inference-of-deep-learning-models-5faa86199c1f
一、训练大模型的基础
大型深度学习模型在训练时需要大量内存来存储中间激活、权重等参数,导致某些模型只能在单个 GPU 上使用非常小的批大小进行训练,甚至无法在单个 GPU上进行训练,使得模型训练在某些情况下非常低效和不可能。
在大规模深度学习模型训练中有个主要范式:
- 数据并行
- 模型并行
我们将讨论大规模深度学习模型训练中的核心概念以及在模型训练领域的最新进展和改进方法,然后分享一些实现这些方法的可用库。
1.数据并行
应用数据并行最常见的场景是模型尺寸能够被 GPU 内存容纳,数据批大小会增加模型训练的难度。解决方案是让模型的不同实例在不同的 GPU 和不同批数据上运行,如下图所示。
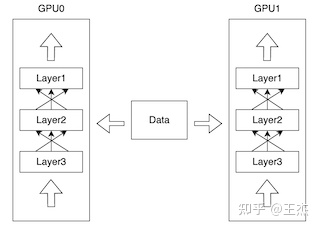
模型的每个实例都使用相同的参数进行初始化,但在前向传递期间,不同批次的数据被发送到每个模型。 收集来自每个模型实例的梯度并计算梯度更新。,然后更新模型参数并将其作为更新发送到每个模型实例。
2.模型并行
当单个 GPU无法容纳模型尺寸时,模型并行性变得必要,有必要将模型拆分到多个 GPU 上进行训练。

通过把一个大模型拆分到多个 GPU 上训练,可以实现模型尺寸超过单个 GPU显存的深度学习模型训练。 这种方法的问题是计算使用效率不高,因为在任何时间点只有一个 GPU 正在使用,而其他 GPU 处于空闲状态。
二、进阶演化
上述两个并行训练范式已有各种优化和增强方法,使训练/推理变得高效,包含如下:
三、主流框架
1. Megatron-LM
Megatron 是由 NVIDIA 深度学习应用研究团队开发的大型 Transformer 语言模型,该模型用于研究大规模训练大型语言模型。Megatron 支持transformer模型的模型并行(张量、序列和管道)和多节点预训练,同时还支持 BERT、GPT 和 T5 等模型。
2.DeepSpeed

DeepSpeed是微软的深度学习库,已被用于训练 Megatron-Turing NLG 530B 和 BLOOM等大型模型。DeepSpeed的创新体现在三个方面:训练 ,推理 ,压缩
DeepSpeed具备以下优势:
- 训练/推理具有数十亿或数万亿个参数的密集或稀疏模型
- 实现出色的系统吞吐量并有效扩展到数千个 GPU
- 在资源受限的 GPU 系统上训练/推理
- 为推理实现前所未有的低延迟和高吞吐量
- 以低成本实现极致压缩,实现无与伦比的推理延迟和模型尺寸缩减
3. FairScale

FairScale(由 Facebook 研究)是一个用于高性能和大规模训练的 PyTorch 扩展库。 FairScale 的愿景如下:
- 可用性:用户应该能够以最小的认知代价理解和使用 FairScale API。
- 模块化:用户应该能够将多个 FairScale API 无缝组合为训练循环的一部分。
- 性能:airScale API 在扩展和效率方面提供了最佳性能。
FairScale 支持Fully Sharded Data Parallel (FSDP),这是扩展大型神经网络训练的推荐方式。

FSDP workflow from https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
4. ParallelFormers

Parallelformers 是一个基于 Megatron-LM 的库。 它与 Huggingface 库很好地集成在一起。 Huggingface 库中的模型可以用一行代码并行化。 目前它只支持推理。
from transformers import AutoModelForCausalLM, AutoTokenizer
from parallelformers import parallelize
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B")
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
parallelize(model, num_gpus=2, fp16=True, verbose='detail')
- 1
- 2
- 3
- 4
- 5
- 6
5. ColossalAI

Colossal-AI提供了一组并行组件,可以用来实现定制化的分布式/并行训练,包含以下并行化策略和增强功能:
- Data Parallelism
- Pipeline Parallelism
- **1D,2D,2.5D,****3D**Tensor Parallelism
- Sequence Parallelism
- Zero Redundancy Optimizer (ZeRO)
- Heterogeneous Memory Management (PatrickStar)
- For Inference**Energon-AI**
6. Alpa

Alpa是一个用于训练和服务大规模神经网络的系统,具备如下特点:
- 自动并行化:Alpa基于数据、运算符和管道并行机制自动化地实现单设备代码在分布式集群并行化。
- 完美的表现:Alpa 在分布式集群上实现了数十亿参数的训练模型的线性缩放。
- 与机器学习生态系统紧密集成:Alpa由开源、高性能和生产就绪的库(如 Jax、XLA 和 Ray)提供支持。
7. Hivemind
Hivemind是一个在互联网上使用 Pytorch 进行去中心化深度学习的库。 它主要服务场景是在来自不同大学、公司和志愿者的数百台计算机上训练一个大型模型。
其主要特点是:
- 没有主节点的分布式训练:分布式哈希表允许连接分散网络中的计算机。
- 容错反向传播:即使某些节点没有响应或响应时间过长,前向和后向传递也会成功。
- 分散的参数平均:迭代地聚合来自多个工作人员的更新,而无需在整个网络中同步(论文)。
- 训练任意大小的神经网络:它们的部分层通过分散的专家混合(论文)分布在参与者之间。
8. OneFlow
OneFlow 是一个深度学习框架,旨在实现用户友好、可扩展和高效。 使用 OneFlow,很容易:
- 使用类似 PyTorch 的 API 编写模型
- 使用 Global View API 将模型缩放到 n 维并行/分布式执行
- 使用静态图编译器加速/部署模型。
9. Mesh-Tensorflow
根据 github 页面:Mesh TensorFlow (mtf) 是一种用于分布式深度学习的语言,能够指定广泛的分布式张量计算类别。 这里的“Mesh”是指处理器或计算设备的互连网络。
其他
1.引用
- Survey on Large Scale Neural Network Training
- Dive into Big Model Training
- How to Train Really Large Models on Many GPUs?
- https://github.com/qhliu26/BM-Training
- https://huggingface.co/docs/transformers/v4.17.0/en/parallelism
- https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
- https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- https://pytorch.org/tutorials/i
2.参考
https://zhuanlan.zhihu.com/p/582498905


