
一、汇编语言基础
一)、汇编语言:基本语法
1、汇编指令最典型的书写模式:
标号
操作码 操作数1, 操作数2,... ;注释
1)、标号是可选的,如果有,它必须顶格写。标号的作用是让汇编器来计算程序转移的地址。
2)、操作码是指令的助记符,它的前面必须有至少一个空白符,通常使用提个Tab键来产生。
3)、操作码后面往往跟若干个操作数,而第一个操作数,通常都给出本指令执行结果的存储地。不同指令需要不同数目的操作数,并且对操作数的语法要求也可以不同。
4)、注释均以;开头,它的有无不影响汇编操作,只是给程序员看的,让程序员更加可以理解代码。
2、可以使用EQU指示子来定义常数,也可以使用DCB来定义一串字节常数——允许以字符串的形式表达,还可以使用DCD来定义一串32位整数。
3、如果汇编器不能识别某些特殊指令的助记符,就需要“手工汇编”,查出该指令的确切二进制机器码,然后使用DCI编译器指示器。
4、不同汇编器的指示字和语法都可以不同。以上以ARM汇编器说明,如使用其他汇编器,细看说明和实例代码。
二)、汇编语言:后缀的使用
1、在ARM处理器中,指令可以带有后缀的:

2、在Cortex-CM3中,对条件后缀的使用有限制,只有转移指令(B指令)才可以随意使用。而对于其他指令,Cortex-CM3引入IF-THEN模块,在这个块中才可以加后缀,且
必须加后缀。
三)、汇编语言:统一的汇编语言
1、为了有力支持Thumb-2,引入了一个“统一汇编语言(UAL)”语法机制。对于16位指令和32位指令均能实现一些操作,有时虽然指令的实际操作数不同,或者对立即数的
长度有不同的限制,但是汇编器允许开发者以相同的语法格式编写,并且由汇编器来决定使用16位指令还是32位指令。
2、如果使用了传统的Thumb语法有些指令会默认更新APSR,即使你没有加上S后缀。如果使用UAL语法,则必须使用S后缀才能更新。
3、在Thumb-2指令集中,有些操作既可以由16位指令完成,也可以由32位指令完成。在UAL下,可以让编译器决定用哪个,也可以手工指令使用16位还是32位。
1)、.W后缀指定32位指令。如果没有给出后缀,会bain其会先试着用16位指令以缩小代码体积如果不行在使用32位指令。
2)、.N后缀指定16位指令。
4、32位Thumb-2指令可以按半字节对齐。
四、指令集
1、APSR中的5个标识位:
1)、N:复数表示(Negative)。
2)、Z:零结果标识(Zero)。
3)、C:进位/借位标识(Carry)。
4)、V:溢出标识(oVerflow)。
5)、S:饱和标识(Saturation),它不做条件转移的依据。
2、Cortex-CM3支持的指令集如下:
注意:边框双粗的是从ARMv6T2才支持的指令。
双线边框的是从Cortex-CM3才支持的指令,(v7的其他款式不一定支持)。
1)、16位数据操作指令
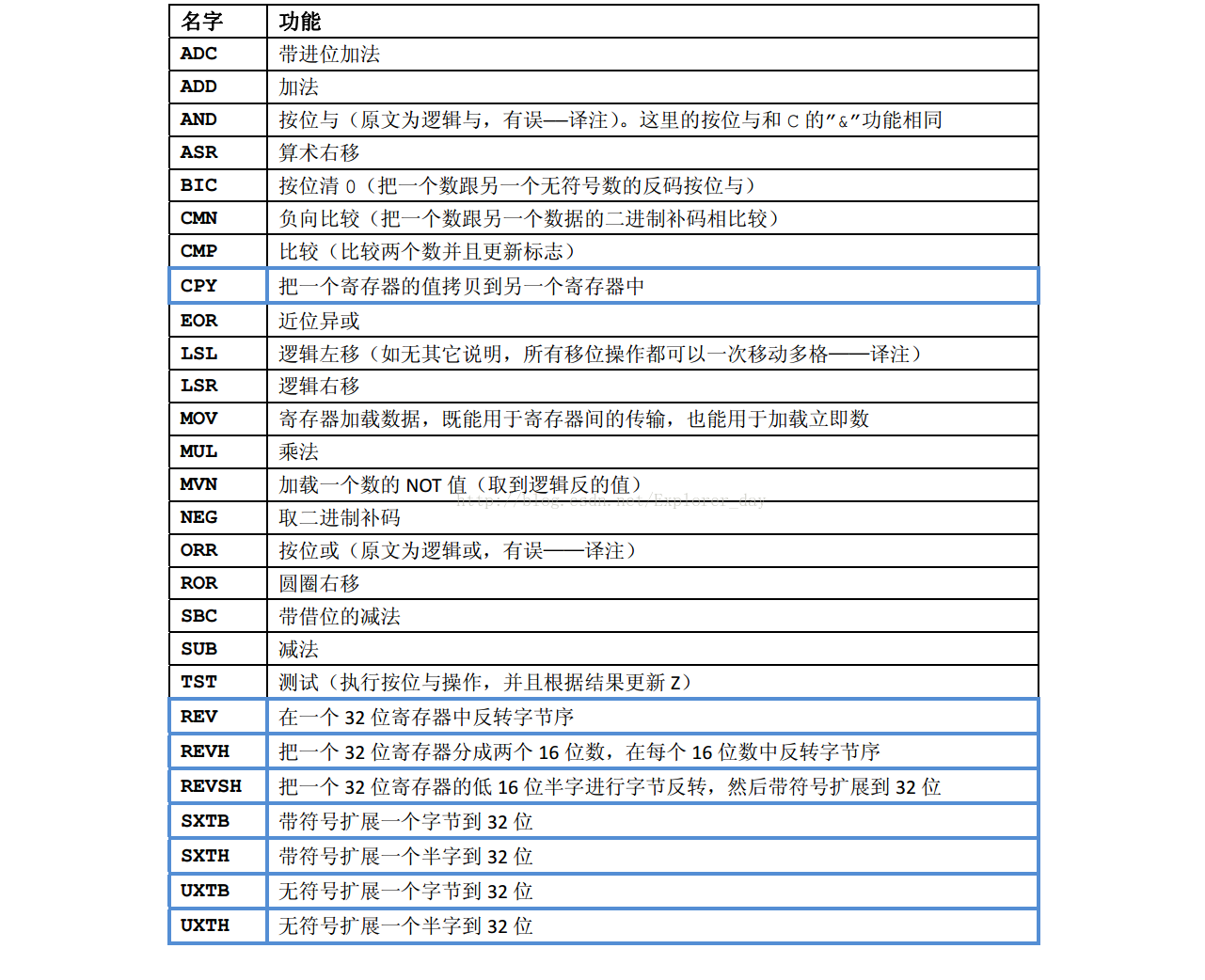
2)、16位转移指令

3)、16位存储器数据传送指令
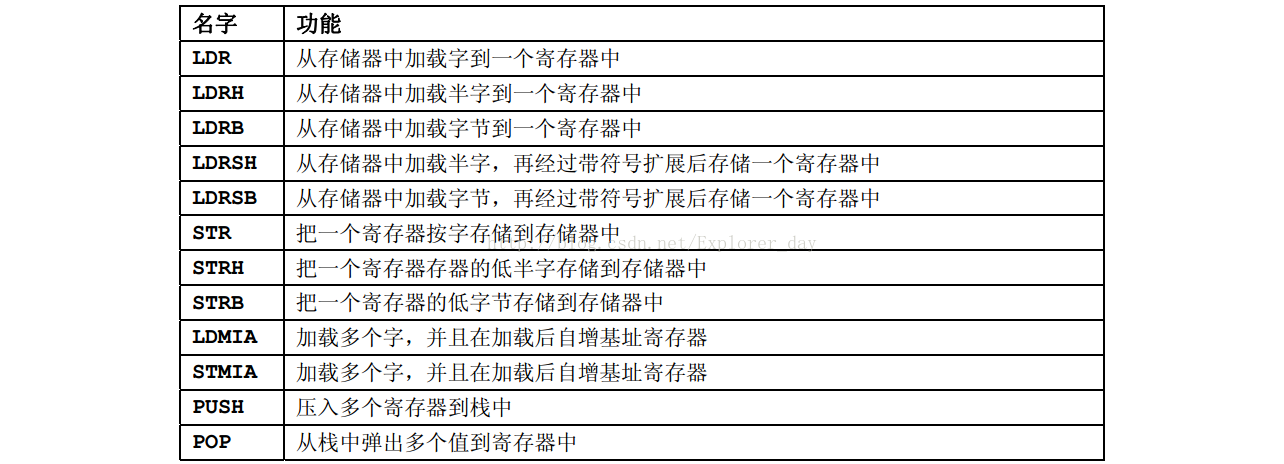
4)、其他16位指令

5)、32位数据操作指令
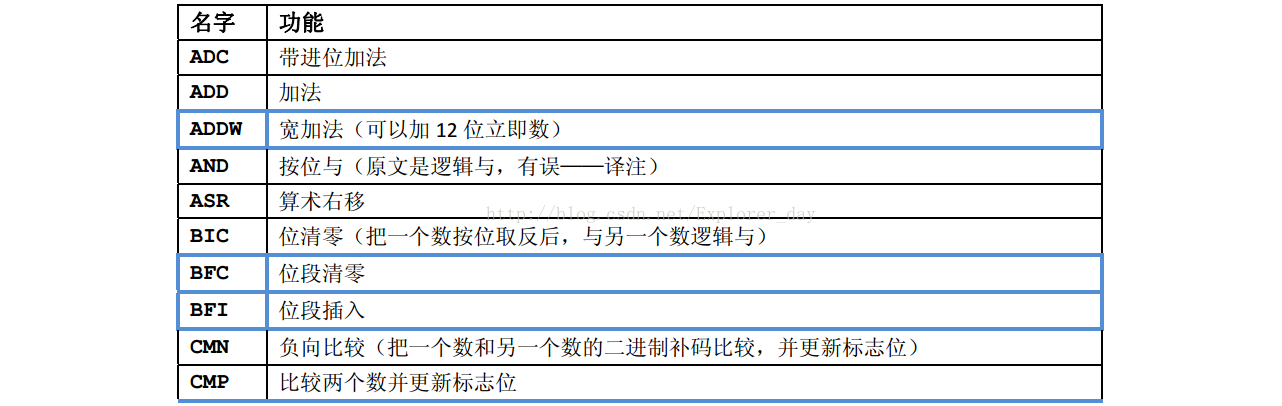

6)、32位存储器数据传送指令
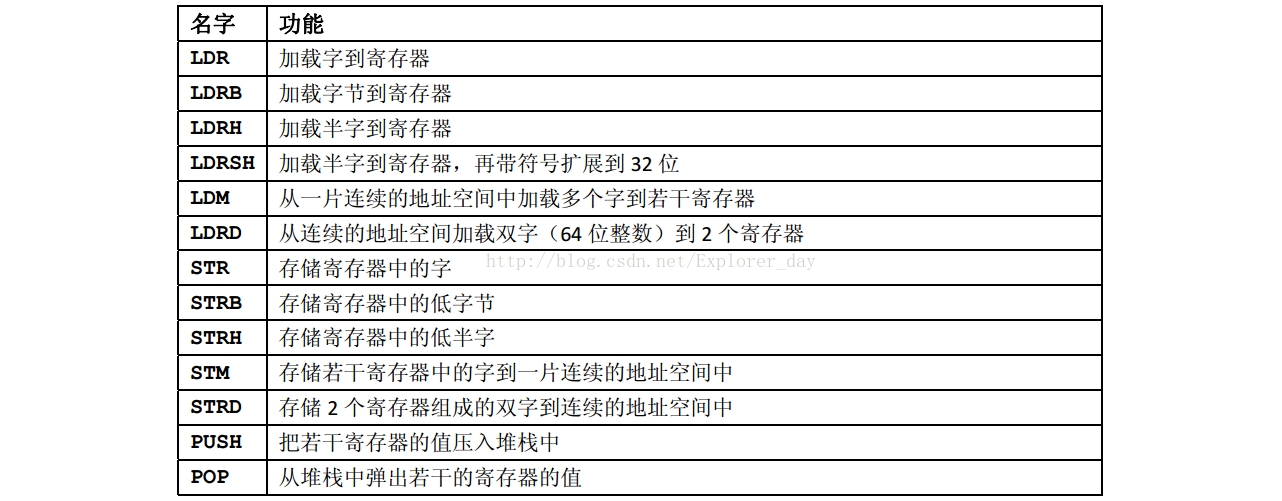
7)、32位转移指令

8)、其他32位指令


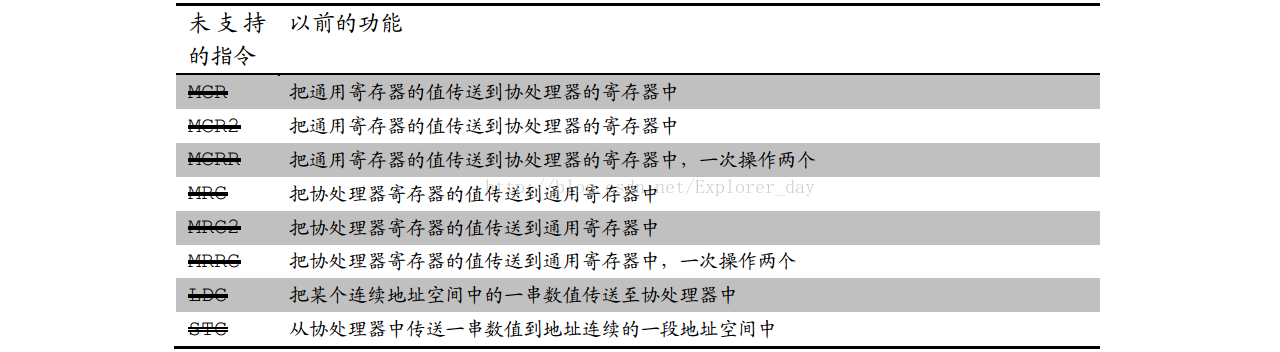
3、未支持的指令
1)、不再是传统的架构,呆滞某些指令已失去意义

2)、不支持的协处理器相关指令
3)、不支持的CPS指令用法

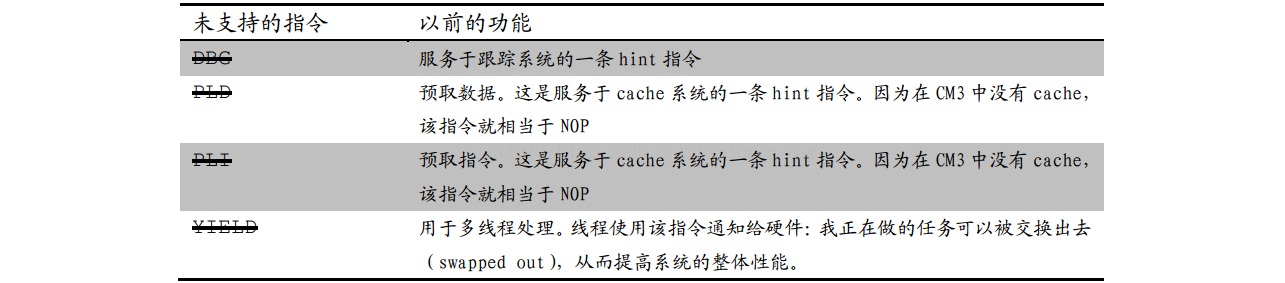
4)、不支持的hint指令
五、近距离的检视指令
一)、汇编语言:数据传送
1、Cortex-CM3中的数据传输类型
1)、两个寄存器间的传输数据。
2)、寄存器与存储器间传输数据。
3)、寄存器与特殊功能寄存器间传输数据。
4)、把一个立即数加载到寄存器。
2、用在数据传输的指令时MOV,它的另一个衍生物是MVN——把寄存器的内容取反后再传送。
3、用于访问存储器的基础指令是“加载(load)”和“存储(store)”。
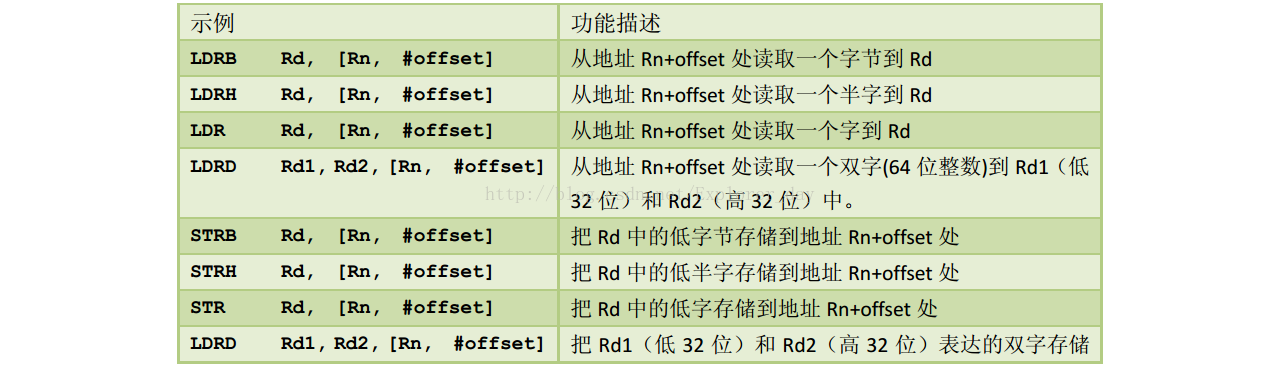
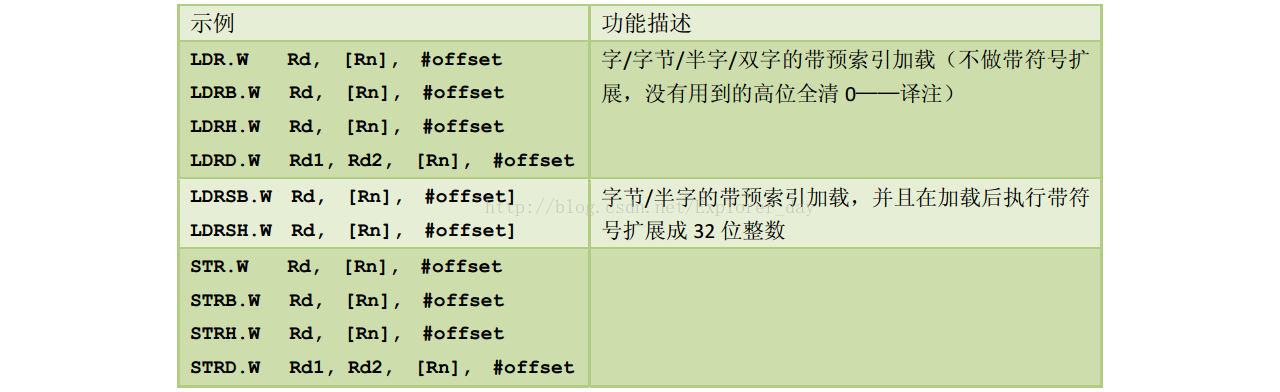
1)、加载指令LDR把存储器中的内容加载到寄存器中,存储指令STR把寄存器的内容存储到存储器中。传送过程中数据类型也可以变通,最常见的格式有:

2)、如果想一次性的解决存储器访问问题,可以使用LDM/STM来进行,它相当于把若干个LDR/STR给合并起来。
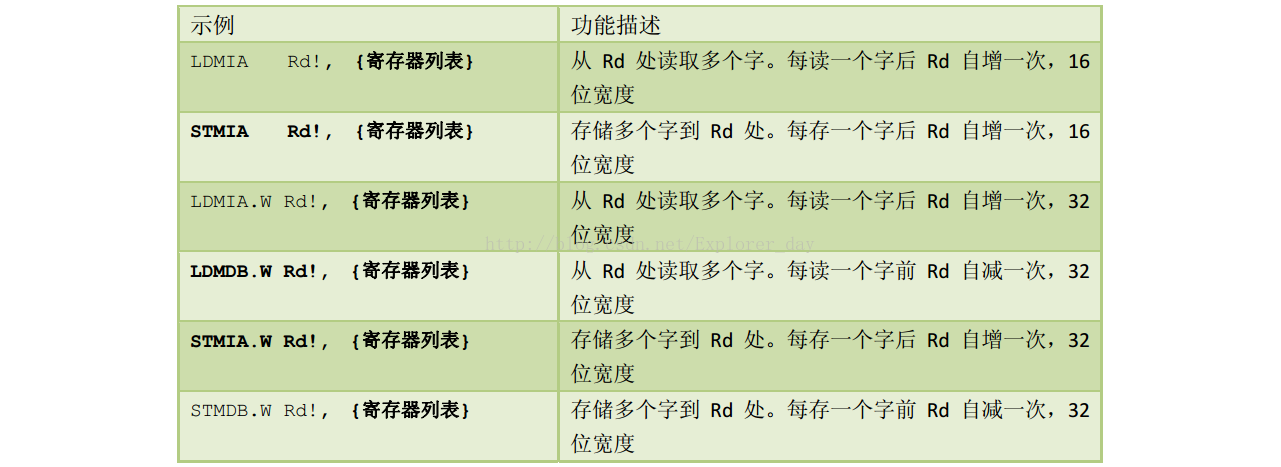
I、表中加粗的符合Cortex-CM3堆栈操作的LDM/STM的使用方式。并且如果Rd是R13,则与PUSH和POP等效。
II、感叹号表示自增或自减基址存储器Rd的值,时机是在每次访问前或访问后。感叹号还可以用于单一加载或存储指令,——LDR/STR。这也就是所谓的“带预索引”的LDR和
STR。


III、Cortex-CM3还支持后索引。后索引也要使用一个立即数offset,但与预索引不同的是,后索引是忠实使用基址寄存器Rd的值作为数据传送的地址的。待到数据传输之后,
在执行Rd<-Rd+offset。
4、LDR伪指令 VS ADR伪指令
1)、LDR和ADR都有能力产生一个地址,但是语法和行为不同。
2)、对于LDR,如果汇编器发生要产生立即数是一个程序地址,它会自动把LSB置位,
3)、对于ADR相反,它不会修改LSB。
二)、汇编语言:数据处理
1、虽然助记符都是ADD,但是二进制机器码是不同的。当使用16位加法时会自动更新APSR的标识位。然而,在使用了“.W”显式指定了32位指令后,就可以通过“S”后缀控制
对APSR的更新。
2、常见的算术四则运算指令
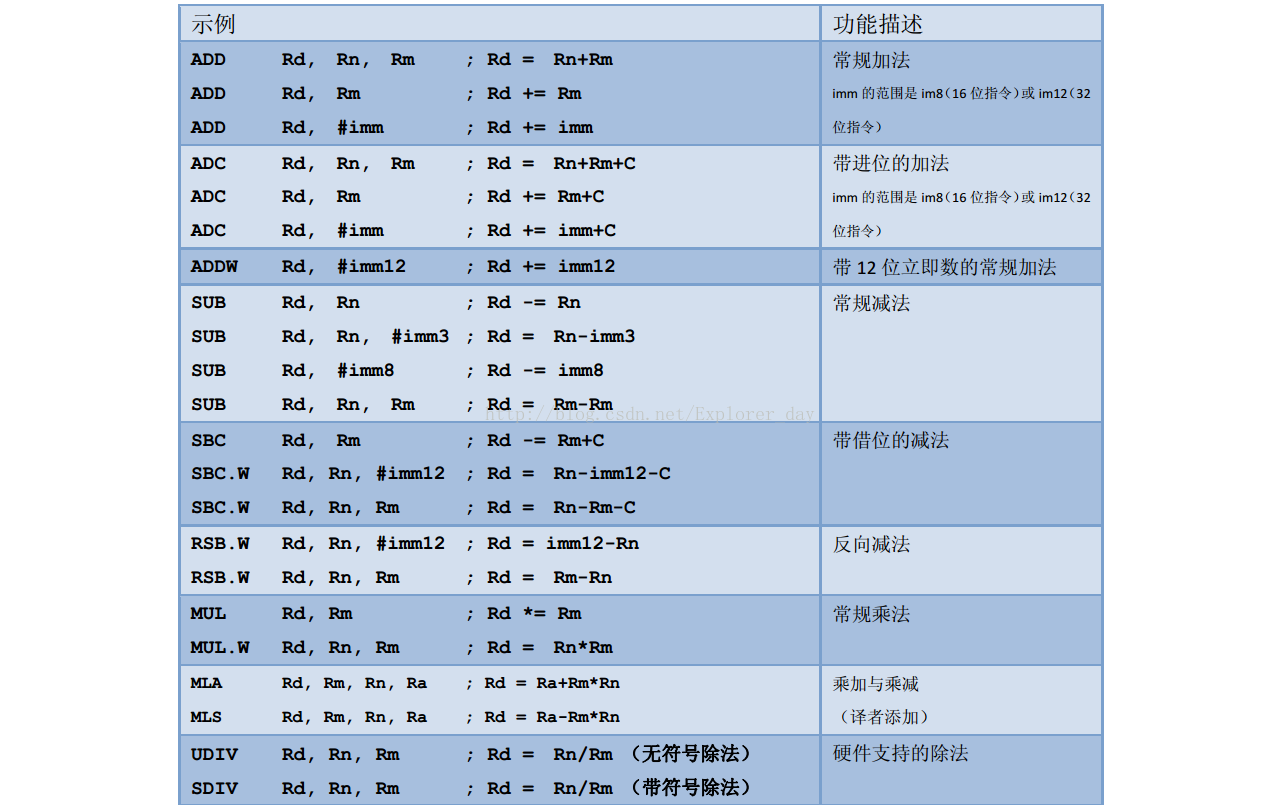
3、Cortex-CM3还片载了硬件乘法器,支持乘加/乘减运算,并能产生64位的值。

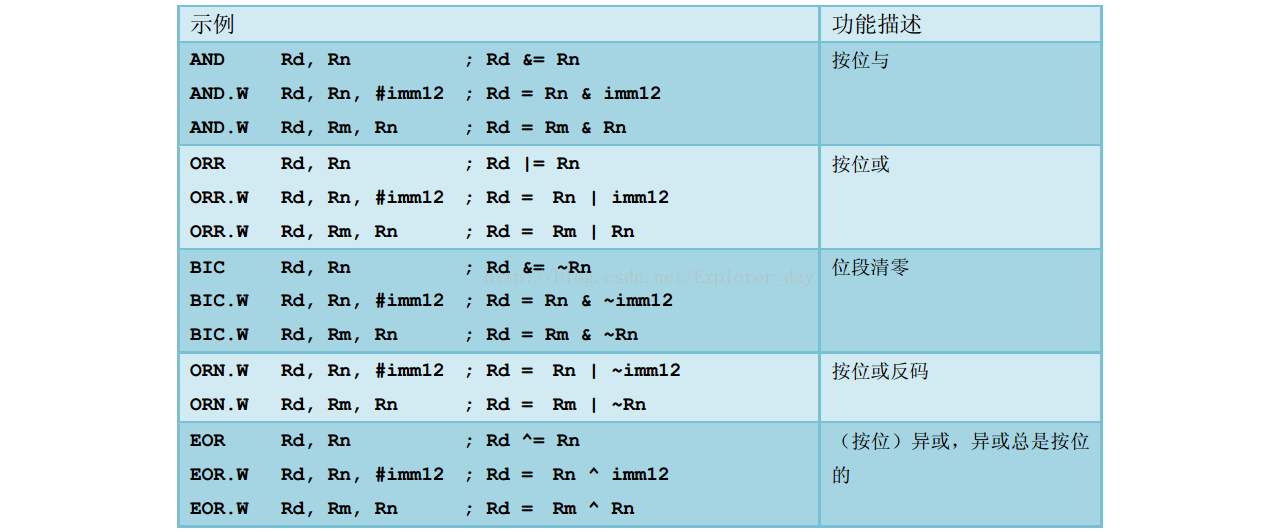
4、逻辑运算
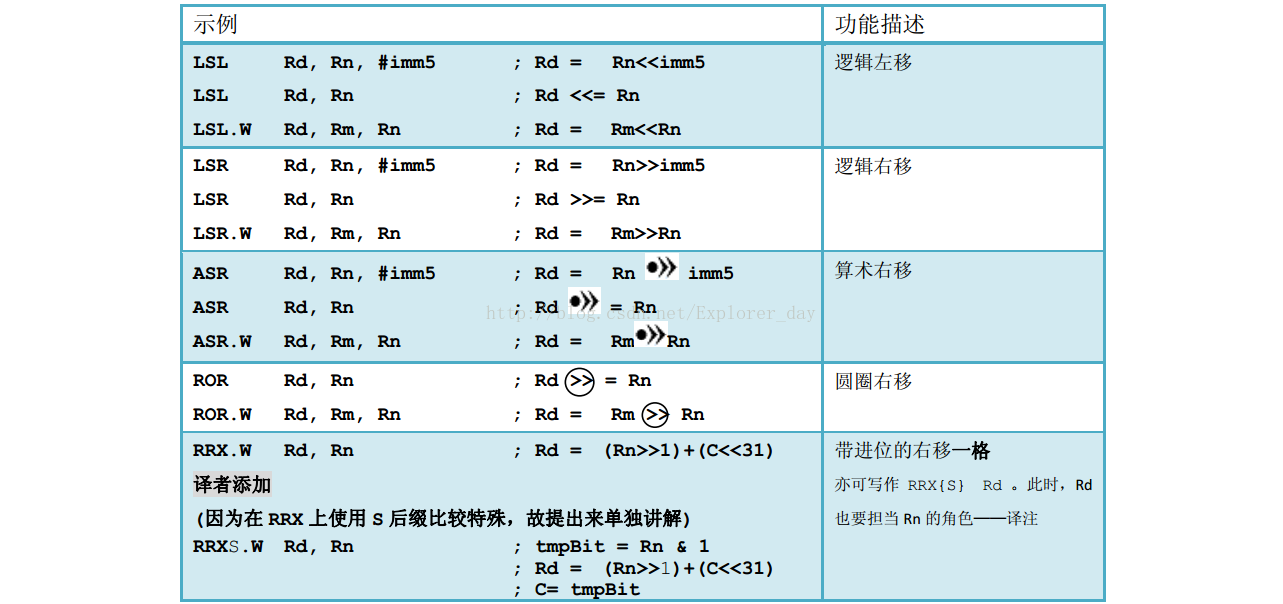
5、移位(支持多种组合)运算和循环运算
6、带符号扩展指令

7、数据序转指令

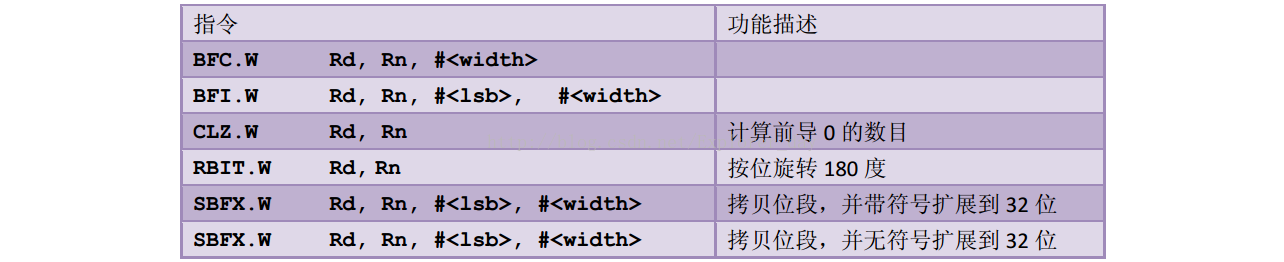
8、位段处理及把玩指令
三)、汇编语言:子程序呼叫与无条件转移指令
1、最基本的无条件转移指令有两条:
B Label ;转移到Label处对应的地址
BL reg ;转移到有寄存器reg给出的地址
2、呼叫子程序时,需要保存返回地址,正点的指令是:
BL Label ;转移到Label处对应的地址,并且把转移前的下条指令地址保存到LR
BLX reg ;转移到由寄存器reg给出的地址,根据REG的LSB切换处理器的状态,并且把转移前的下条指令地址保存到LR
注意:、使用BLX要注意,其改变状态的功能。因此确保reg的lsb必须为1,以确保不会进入ARM状态。
3、以PC为目的寄存器的MOV和LDR指令也可以实现转移,常见的形式有:
MOV PC, R0 ; 转移地址由R0给出
LDR PC, [R0] ; 转移地址存储在R0所指向的存储器中
POP {..., PC] ; 把返回地址以弹出堆栈的方式送给PC,从而实现转移
LDMIA SP!, {..., PC ; POP另一种等效写法
注意:使用这些方式必须保证送给PC的值是奇数(LSB=1)。
四)、标志位与条件指令
1、在应用程序状态寄存器中有5个标志位,但只有4个被条件转移指令参考。绝大多数ARM的条件转移指令根据他们来决定是否转移。
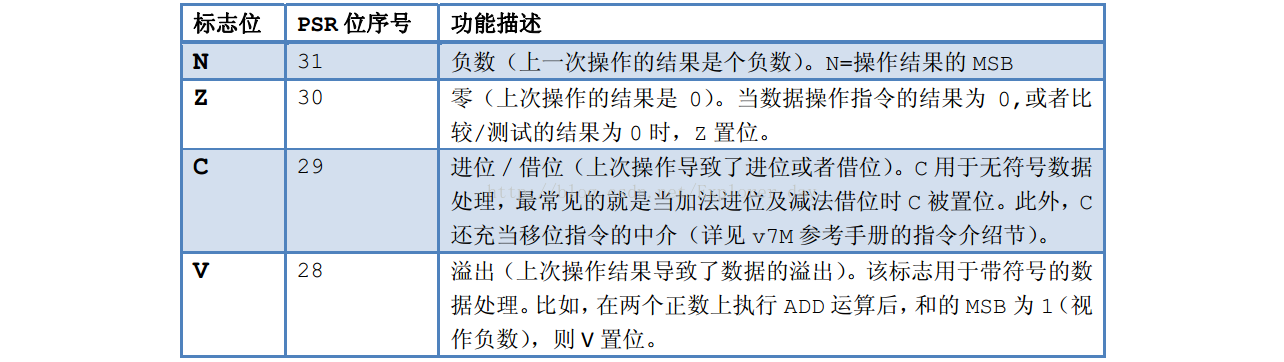
2、在ARM中数据操作指令可以更新这4个标志位。这些标志位除了可以当条件转移的判断之外,还能再一些场合下作为指令是否执行的依据。或者在移位操作中充当各种中介
角色。
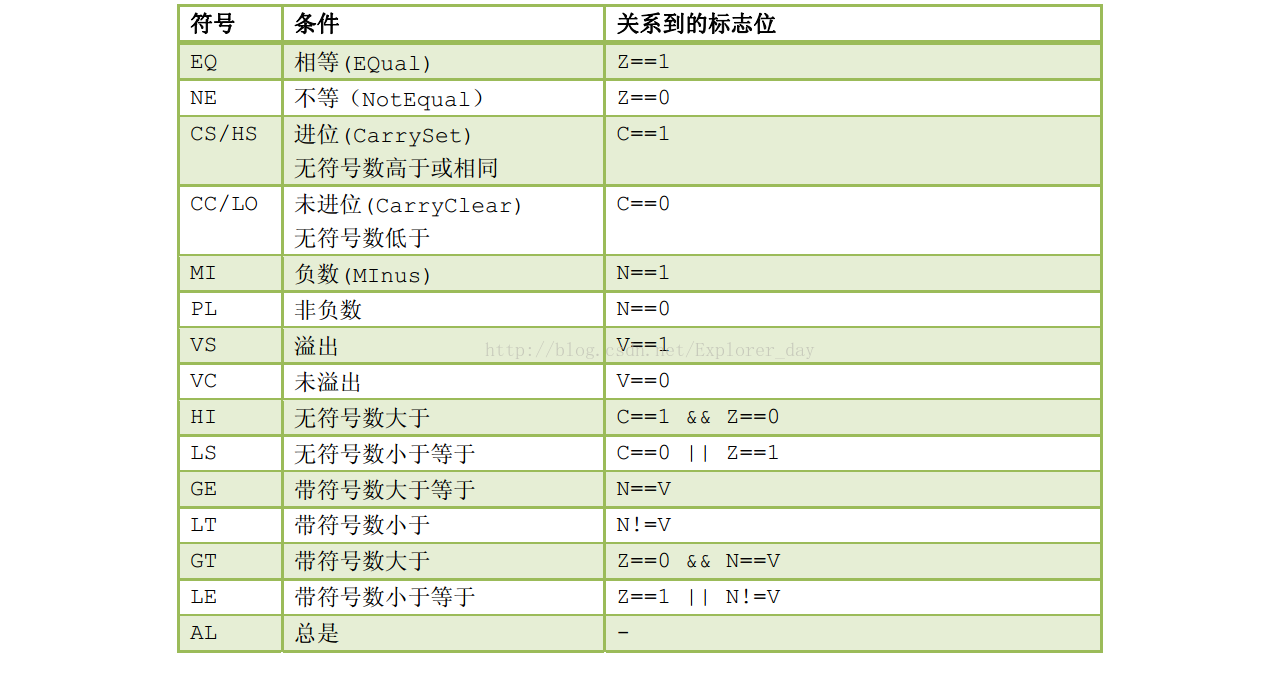
3、担任条件转移和条件执行的依据时,这4个标志位既可以单独使用,也可以组合使用,以产生15种判断依据:
4、在Cortex-CM3中,下列指令可以更新PSR的标志:
1)、16位算术逻辑指令。
2)、32位带S后缀的算术逻辑指令。
3)、比较指令和测试指令。
4)、直接写PSR/APSR(MAR指令)。
五)、汇编语言:指令隔离指令和存储器隔离指令

六)、汇编指令:饱和运算
1、Cortex-CM3的饱和运算指令分为两种:带符号的饱和运算以及无符号饱和运算。
2、饱和运算指令

六、Cortex-CM3中一些有用的新指令
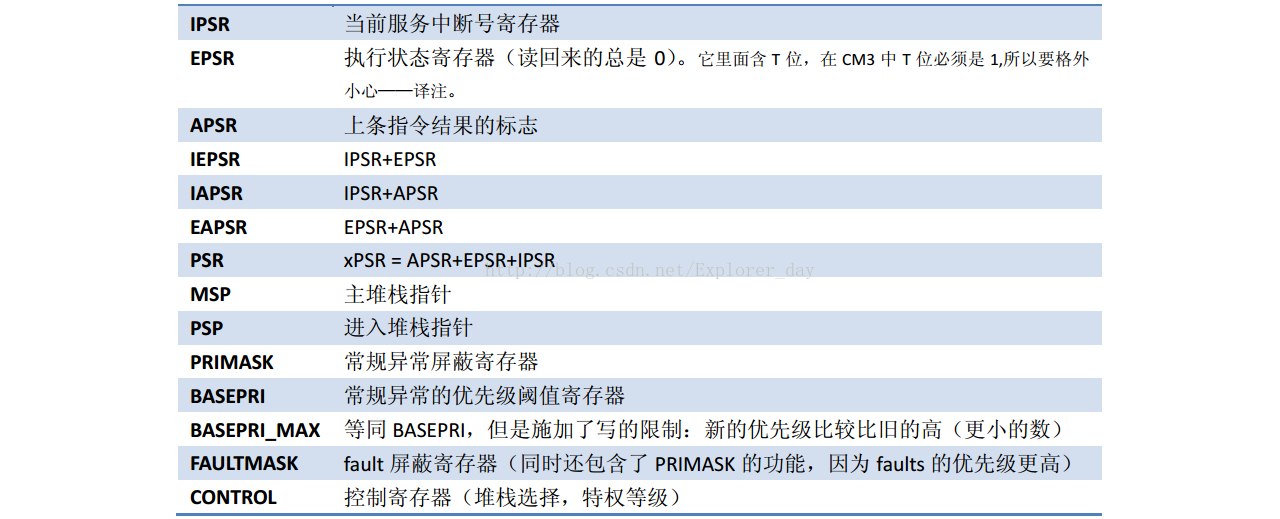
1、MSR和MRS
1)、这两条指令是访问特殊功能寄存器的指令,必须在特权下访问,出APSR外。
2)、指令语法如下:
MRS <Rn>, <SReg> ; 加载特殊功能寄存器的值到Rn
MSR <SReg>, <Rn> ; 存储Rn的值到特殊功能寄存器的值
3)、SReg可以是下表中的一个
2、IF-THEN
1)、IF-THEN指令围成一个块,里面最多4条指令,它里面的指令可以条件执行。
2)、IT使用形式:

3、CBZ和CBNZ
1)、比较并条件跳转指令专为循环结构的优化而设,它只能做向前跳转。
2)、格式为

4、SDIV和UDIV
1)、32位硬件除法指令。
2)、格式

3)、运算结果是Rd = Rn / Rm。
5、REV,REVH,REV16以及REVSH
1)、REV反转32位整数中的字节序,REVH则以半字节为单位反转,且只反转低半字节。
2)、REVSH在REVH的基础上,还把反转后的半子做带符号的扩展。
3)、语法

6、RBIT
1)、RBIT比以前的REV之流更为精细,它是按位反转的,相当于把32位整数的二进制表示法水平旋转180°。此指令在处理串行比特流大有用处。
2)、格式
RBIT.W Rd, Rn
7、SXTB,SXTH,UXTB,UXTH
1)、这四条指令是为了优化C的强制数据类型转换而设的,把数据宽度转换为处理器喜欢的32位长度。
2)、语法

3)、对于SXTB/SXTH,数据带符号位扩展成32位整数。对于UXTB/UXTH,高位清0。
8、BFC/BFI,UBFX/SBFX
1)、这四个指令是Cortex-CM3提供的位段操作指令。
2)、BFC(位段清零)指令把32位整数任意一段连续的二进制位S清0,语法格式为:
BFC Rd, #lsb, #width
3)、BFI(位段插入指令),则把某寄存器按LSB对齐的数据,拷贝到另一个寄存器的某个位段中,其格式为:
BFI.w Rd, Rn, #lsb, #width
4)、UBFX/SBFX都是位段提取指令,语法格式为:
UBFx.w Rd, Rn, #lsb, #width
SBFX.w Rd, Rn, #lsb, #width
9、LDRD/STRD
1)、Cortex-CM3在一定程度上支持对64位整数,其中LDRD/STRD就是为64位整数的数据传输而设置的。
2)、格式:

10、TBB,TBH
1)、TBB(查表跳转字节范围的偏移量)指令和TBH(查表跳转半字节范围的偏移量)指令,分别用于从一个字节数组表中查找偏移地址,和从半字节数组表中查找偏移地
址。TBB的跳转范围为255*2+4=514,TBH的跳转范围为65535*2+4=128kb+2。
2)、TBB语法格式
TBB.W [Rn, Rm] ;PC+=Rn[Rm]*2
3)、TBH语法格式
TBH.W [Rn, 2*Rm] ;PC+=Rn[2*Rm]*2
一、存储器系统的功能概览
1、Cortex-CM3存储器系统功能
1)、存储器映射是预定义的,并且还规定好了那个位置使用那条总线。
2)、Cortex-CM3的存储器系统支持“位带”操作。
3)、Cortex-CM3存储器系统支持非对齐访问和互斥访问。
4)、Cortex-CM3的存储器系统支持both大端配置和小端配置。
二、存储器映射
1、Cortex-CM3只有一个单一固定的存储器映射。这极大方便了软件在各种Cortex-CM3单片机间的移植。
2、存储器的一些位置用于调试组件等私有外设,这个地址被称为“私有外设区”。私有外设区的组件包括:
1)、闪存地址重载及断点单元(FPB)。
2)、数据观察点单元(DWT)。
3)、指令跟踪宏单元(ITM)。
4)、嵌入式跟踪宏单元(ETM)。
5)、跟踪端口接口单元(TPIU)。
6)、ROM表。
3、Cortex-CM3的地址空间是4GB,程序可以在代码区,内部SRAM区以及RAM区执行。4GB粗线条划分:

1)、内部SRAM区的大小是512MB,用于让芯片制造商连接片上的SRAM,这个区通过系统总线来访问。在此区的下部,有一个1MB的位带区,该位带区还有一个对应的
32MB的“位带别名区”,容纳了8M个“位变量”。位带区对应的是最低的1MB地址范围,而位带别名区里面的每个字对应位带区的一个比特。位带操作只适用于数据访问,
不适用与取指操作。
2)、地址空间另一个512范围由片上外设(的寄存器)使用。这个区也有一条32MB的位带别名,以便于快捷的访问外设寄存器。
3)、还有两个1GB的范围,分别用于连接外部RAM和外部设备,它们之间没有位带。两者的区别在于外部RAM区允许执行指令,而外设设备区则不允许。
4)、最后剩下0.5GB的地带是Cortex-CM3内核所在区域,包括系统级组件,内部私有外部总线S,外部私有外部总线S,以及由提供者定义的系统外设。
5)、私有外部总线有两条
I、AHB外设总线,只用于Cortex-CM3内部的AHB设备,它们是:NVIC,FPB,DWT和ITM。
II、APB外设总线,即用于Cortex-CM3内部的APB设备,也用于外部设备
6)、NVIC所处的区域叫做“系统控制空间(SCS)”在SCS里面还有SysTick、MPU以及代码调试控制所用的寄存器:

三、存储器访问属性S
1、Cortex-CM3为存储器做了映射之外,还为存储器的访问规定了4中属性:
1)、可否缓冲(Bufferable)
2)、可否缓存(Cacheable)
3)、可否执行(Executable)
4)、可否共享(Shareable)
2、如果配置了MPU,则可以通过它配置不同的存储区,并且覆盖缺省的访问属性。
四、存储器的缺省访问许可
1、Cortex-CM3有一个缺省的访问许可,它能防止使用户代码访问系统控制存储空间,保护NVIC,MPU等关键组件。缺省访问许可在以下条件时生效:
1)、没有配置MPU。
2)、配置了MPU,但是MOPU被除能。
2、存储器的缺省访问许可

四、位带操作
一)、简介
1、支持位带操作后,可以使用普通的加载/存储指令来对单一的比特进行读写。在Cortex-CM3中,有两个区实现了位带。其中一个是SRAM区的最低1MB,第二个则是片内外
设区的最低1MB范围。这两个区的地址除了可以像普通的RAM使用外,它也都有自己的“位带别名区”,位带别名区把每个比特膨胀成一个32位的字。
1)、位带区与别名区的膨胀对应关系图A

2)、位带区与别名区的膨胀对应关系图B

2、Cortex-CM3用如下术语来表示位带存储的地址区
1)、位带区:支持位带操作的地址区。
2)、位带别名:对别名地址的访问最总作用到位带区的访问上。(注意:这中途有一个地址映射过程)
3、在位带区中每个比特都都映射到别名地址区的一个字——这是只有LSB有效的字。当一个别名地址被访问时,会先把改地址变换成位带地址。
1)、对于读操作,读取位带地址中的一个字,再把需要的位右移到LSB,并把LSB返回。
2)、对于写操作,把需要写的位左移到对应的位序号处,然后执行一个原子的“读-改-写”过程。
4、支持位带操作的两个内存区的范围是:
1)、0x2000_0000-0x000F_FFFF(SRAM区中的最低1MB)和0x4000_0000-0x400F_FFFF(片上外设区中的最低1MB)。
2)、对于SRAM位带区的某个比特,记它所在字节地址为A,位序号为n,则该比特在别名区的地址是:

3)、对于片上外设位带区的某个比特,记它所在字节地址为A,位序号为n,则该比特在别名区的地址是:

5、位带地址映射
1)、SRAM区中的位带地址映射

2)、片上外设区中的位带地址映射

二)、位带操作的优越性
1、位带操作对硬件I/O密集型的底层程序提供了很大方便。
2、位带操作可用来化简跳转的判断。是代码更整洁。
3、在多任务中用于实现共享资源在任务间的“互锁”访问。
三)、其他数据长度上的位带操作
1、位带操作并不限于以字为单位的传送。亦可以按半子节和字节为单位传送。
五、在C语言中使用位带操作
1、C编译器中并没有直接支持位带操作。欲在在C中使用位带操作,最简单的做法就是#define一个位带别名区的地址。为了简化位带操作,也可以定义一些宏。
2、当使用位带功能时,要访问的变量必须用vollatile来定义。
六、非对齐数据传送
1、Cortex-CM3支持在单一的访问中使用非(地址)对齐的传送,数据存储器的访问无需对齐。
2、非对齐传送实例

3、在Cortex-CM3中,非对齐的数据传送只发生在常规的数据传送指令中,其他的指令则不支持:
1)、多个数据的加载存储(LDM/STM)。
2)、栈堆操作(PUSH/POP)。
3)、互斥访问(LDREX/STREX)。
4)、位带操作。
4、应该养成好习惯,总是保持地址对齐。为此可以变成NVIC,使之监督地址对齐。
七、互斥访问
1、在Cortex-CM3中,用互斥体访问取代了ARM处理器中的SWP指令。
2、互斥访问的理念同SWP非常相似,不同点在于:在互斥访问操作下,允许互斥体所在的总线被其他master访问,也允许被其他运行在本机上的任务访问,但是Cortex-CM3
能驳回有可能导致竟态条件的互斥访问。
3、互斥访问分为加载/存储,相应的指令为LDREX/STREX,LDREXH/STREXH,LDREXB/STREXB,分别对应于字/半字/字节
4、使用方式(以LDREX/STREX为例)
1)、语法格式

2)、LDREX指令与LDR相同。而STREX不同,STREX指令的执行是可以被驳回的。
I、当处理器同意执行STREX,Rxf的值会被存储到(Rn+Offset)处,并且把Rd的值更新。
II、若处理器驳回了STREX的执行,则不会发生存储动作,并且把Rd的值更新为1。
3)、驳回规则:只有在LDREX执行后最近的一条STREX才能成功执行。其他情况下,驳回此STREX
I、中途有其他STR指令执行。
II、中途有其他的STREX执行。
4)、当时用互斥访问时,LDREX/STREX指令必须成对使用。
八、端模式
1、Cortex-CM3支持both小端模式和大端模式。在绝大多数情况下,Cortex-CM3都是用小端模式——为了避免不必要的麻烦,推荐使用小端模式。
2、Cortex-CM3中对大端模式的定义与ARM7的不同(小端定义都相同)。在ARM7中大端模式称为“字不变大端”,而在Cortex-CM3中,使用的是“字节不变大端”。
1)、Cortex-CM3的字节不变大端:存储器视图

2)、Cortex-CM3的字节不变大端:在ABH上的数据

3)、ARM7字节不变大端:在ABH上的数据

3、在Cortex-CM3,是在复位时确定使用那种端模式的,且运行时不得改变。指令预取永远使用小端模式,在配置控制存储空间的访问也永远小端模式(包括NVIX,FPB之
流)。另外外部私有总线地址区0xE0000000至0xE00FFFFF也永远使用小端模式。

