
- 1Hive 拉链表实现方式(2种)_hive拉链表的实现过程sql
- 2NAPI 技术在 Linux 网络驱动上的应用和完善_cur_rx和dirty_rx
- 3计算机毕业设计(56)php小程序毕设作品之校园教室预约小程序系统_校园来访预约小程序毕设
- 4Gradle下载地址_gradle 下载地址
- 5MYSQL 5.5不支持字段类型为datetime且默认值为NOW()的建表语句_mysql5没有datetime类型吗
- 6Entity Framework 4.0之1:调用存储过程
- 7上海亚商投顾早餐FM/0810
- 8Ubuntu16.04下彻底卸载clion,安全可复原方法_linux卸载clion
- 9cornerstone 使用
- 10WSL2 安装踩坑_wsl2 reboot
达摩院FunASR实时语音听写服务软件包发布
赞
踩
7月初,FunASR社区发布了离线文件转写软件包,可以高精度、高效率、高并发的支持长音频离线文件转写,吸引了众开发者参与体验。应开发者需求,FunASR社区再次推出实时语音听写服务软件包,支持实时地进行语音转文字,同时也支持语音句尾用高精度的转写文字修正输出,输出文字带有标点,支持高并发多路请求。
(7月发布)FunASR离线文件转写软件包:
https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/docs/SDK_tutorial_zh.md
(8月发布)FunASR实时语音听写软件包:
https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/docs/SDK_tutorial_online_zh.md
▎实时语音听写软件包介绍
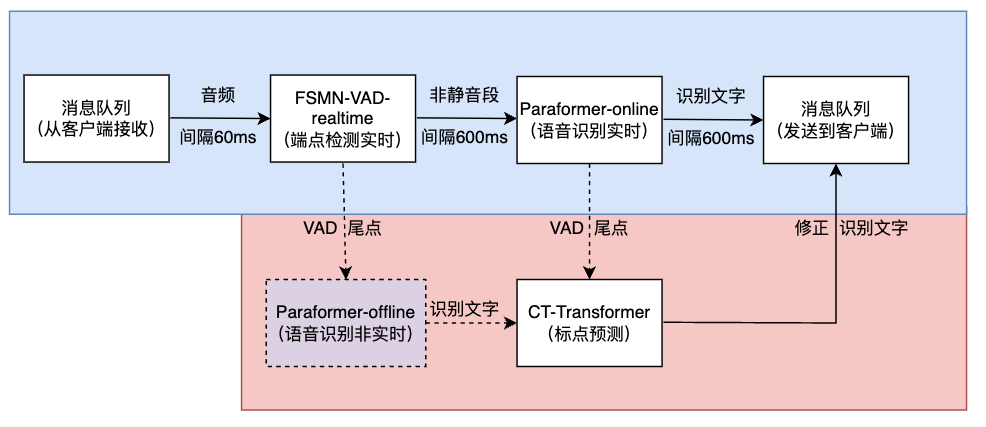
图1 FunASR实时语音听写服务架构图
FunASR实时语音听写服务包架构如图1所示,集成了实时语音端点检测模型(FSMN-VAD-realtime),语音识别实时模型(Paraformer-online),语音识别非流式模型(Paraformer-offline),标点预测模型(CT-Transformer)。采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,支持多路请求。
软件包同时支持websocket与grpc协议,支持以下几种推理配置(mode):
-
实时语音听写服务(ASR-realtime-transcribe)
客户端连续音频数据,服务端检测到音频数据后,每隔600ms进行一次流式模型推理,并将识别结果发送给客户端。同时,服务端会在说话停顿处,做标点断句恢复,修正识别文字。
-
非实时一句话转写(ASR-offline-transcribe)
客户端连续音频数据,服务端检测到音频数据后,在说话停顿处进行一次非流式模型推理,输出带有标点文字,并将识别结果发送给客户端。
-
实时与非实时一体化协同(ASR-realine&offline-twoPass)
客户端连续音频数据,服务端检测到音频数据后,每隔600ms进行一次流式模型推理,并将识别结果发送给客户端。同时,服务端会在说话停顿处,进行一次非流式模型推理,输出带有标点文字,修正识别文字。
>>便捷部署
FunASR社区提供了实时语音听写软件包一键部署方案,开发者可以通过funasr-runtime-deploy-online-cpu-zh.sh一键完成docker安装、镜像启动、服务部署,详见语音识别实时听写服务便捷部署教程
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

