
- 1ssm基于安卓的健身appcgua5【独家源码】计算机毕业设计问题的解决方案与方法_基于ssm个性化健身助手平台选题背景
- 2基于昇腾AI异构计算架构CANN的通用目标检测与识别一站式方案初体验_cann异构计算架构
- 3vue3.0项目中:如何调用后端接口?_vite请求后端接口
- 4linux运行bat文件命令_让Linux终端同时运行多个Linux命令
- 5手机安卓Termux安装MySQL数据库【公网远程数据库】_手机 mysql
- 6CasaOS一个轻量级的家庭云系统
- 7SQL语言快速入门_spl 快速入门
- 8el-tree 插槽的筛选
- 9java中判断是否是今天,返回时间的字符串_java判断是当天返回时间不是则加上日期
- 10固定收益证券是什么
人工智能产生的幻觉问题真的能被看作是创造力的另一种表现形式吗?_生成式人工智能幻觉
赞
踩
OpenAI的首席执行官山姆·奥特曼(Sam Altman)曾声称,人工智能产生的“幻觉”其实未尝不是一件好事,因为实际上GPT的优势正在于其非凡的创造力。
目录
一.幻觉问题的概念
人工智能的幻觉问题是指其在没有充分训练数据支持的情况下自信地做出的响应。这种响应可能是由于数据不完备、存在偏见或过于专业化等因素导致的。以下是详细介绍:
- 内在幻觉:指AI大模型生成的内容与其输入内容之间存在矛盾,即生成的回答与提供的信息不一致。这种错误往往可以通过核对输入内容和生成内容来相对容易地发现和纠正。
- 外在幻觉:指的是生成内容的错误性无法从输入内容中直接验证。这种错误通常涉及模型调用了输入内容之外的数据、文本或信息,从而导致生成的内容产生虚假陈述。外在幻觉难以被轻易识别,因为虽然生成的内容可能是虚假的,但模型可以以逻辑连贯、有条理的方式呈现,使人们很难怀疑其真实性。就比如我想AI提问,刘翔在那一年获得了乒乓球冠军?它可能会回答2004年,但实际上刘翔并没有获得过乒乓球赛的冠军,而AI的这种自信来源于它不会对提问者的假设条件进行判断,它认为你给出它的前提条件是正确的,从而基于这种情况结合自身所掌握的数据捏造出一个有悖于事实的答案
当人们说GPT致幻时,他们指的就是这种对事实的篡改。但是幻觉这一概念也暗示着,GPT在别的时候可以准确地描述事实。不幸的是,这加剧了人们对大型语言模型工作原理的误解,而这种误解往往会在一项技术变得安全或危险时产生区别。我们倒不如说GPT的所作所为统统应归于“幻觉”范畴,因为这些模型中根本不存在“非幻觉”状态(即根据某种外部感知来检查某事物的有效性)。在它们的世界里,答案不分对错,目标也没有意图。



二.幻觉产生的原因
研究人员将AI幻觉归因于高维统计现象和训练数据不足等因素。一些人认为,被归类为“幻觉”的特定“不正确”的AI反应可能由训练数据证明是合理的。然而,其他人对这些发现提出了质疑,并认为人工智能模型可能偏向于肤浅的统计数据,导致在现实世界场景中做出不可靠的反应。
在自然语言处理中,幻觉通常被定义为“生成的内容,这些内容与提供的源内容无关或不忠实”。文本和表示之间的编码和解码错误会导致幻觉。产生不同反应的人工智能训练也可能导致幻觉。较大的数据集可能会产生参数知识问题,如果系统对其硬连线知识过于自信,则会产生幻觉。


三.幻觉的分类
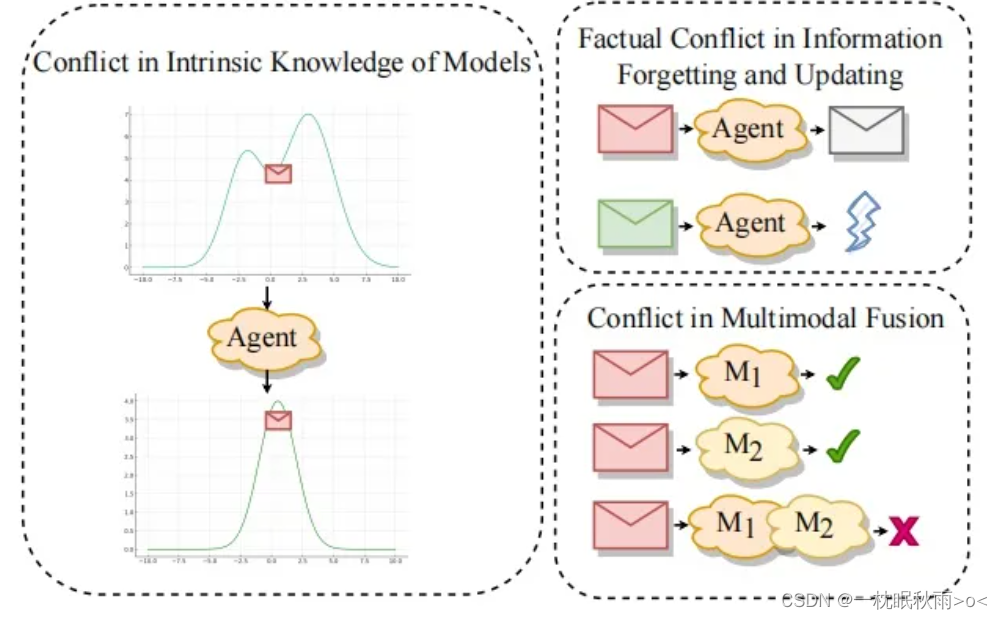
- 模型内在知识冲突:模型在输出时,与输入提示或上下文存在冲突。比如,语言模型在生成一句话时,前面的单词与后面的单词语义不连贯。视觉语言模型在描述图像时,可能会将图像中的物体错误地识别出来。
- 信息遗忘与更新冲突:模型遗忘之前掌握的事实知识,无法吸收新的信息。比如,语言模型在回答一个问题时,会错误地输出与问题无关的内容。这是因为模型“遗忘”了问题的语义,无法正确理解问题。
- 多模态融合冲突:来自不同模态的信息融合时,可能会互相干扰导致错误输出。比如,图像与文本信息融合时,图像中的文本可能会影响模型对整个场景的理解。



四.减轻AI的幻觉问题到底应如何着手
- 数据方面:使用高质量的数据进行训练,如详细注释的数据集,可以减少模型的“幻觉”。
- 模型训练方面:采用合适的训练技术和损失函数,如指令微调、对比学习等,也可以减少模型的“幻觉”。
- 模型推理后处理方面:使用外部知识库辅助推理,或利用后处理技术修改模型的输出结果,使输出更符合人类偏好。
访问实时信息:一种可能的解决方案是让人工智能系统能够访问来自互联网的实时信息。这将允许人工智能将其响应与可用的最新数据进行交叉检查。例如,如果人工智能系统被问及特定位置的天气,它可以使用实时天气数据来准确响应。然而,这种方法也有其自身的挑战,包括数据隐私问题以及人工智能系统从互联网访问和传播虚假信息的风险。
与搜索引擎集成:另一个潜在的解决方案是将人工智能系统与搜索引擎集成。这将使人工智能能够在提供响应之前快速搜索,确保其答案基于最相关和最新的可用信息。但是,这种方法也有其局限性。搜索引擎可能只是有时提供准确的信息,人工智能系统可能仍然需要帮助来区分可靠的来源和不可靠的来源。
改进的训练数据:提高用于训练人工智能系统的训练数据的质量和多样性也有助于缓解人工智能幻觉的问题。为人工智能提供更广泛的数据可能会更好地提供准确可靠的响应。
高级算法:开发能够更好地理解问题上下文并提供更准确答案的高级算法也会有所帮助。这些算法可以设计成识别人工智能何时即将产生幻觉,并提示它询问更多信息或承认它不知道答案。








