
- 1Python学习笔记——removebg库之抠图
- 2Air test 下载安装教程_airtest下载
- 3vue axios数据请求的两种请求头,一种是JSON序列化对象,一种是formData,这两种格式的处理方式_axios application/json
- 4matlab 工具函数 —— normalize(归一化数据)_matlab normalize函数
- 5java中几种JSON库的解析速度对比_不同机器json解析效率差异巨大 java
- 6鸿蒙应用runtime,鸿蒙OS初探
- 7Oauth2.0 自定义响应值以及异常处理_oauth2自定义异常
- 8Jaeger docker部署实操_jaeger docker 部署
- 9[力扣每日一题]1004. 最大连续1的个数 III_一个数组和一个k,数组a{1,1,1,0,0,1,1,0},k=2,能让最多k个0变为1,问连续1最
- 10鸿蒙2.0内核安卓,鸿蒙2.0终于来了,可否与安卓一战?
Raft 与 Zab 对比_zab算法与raft算法的区别
赞
踩
0 一致性问题
一致性算法在实现状态机这种应用时,有哪些常见的问题:
-
1 leader选举
-
1.1 一般的leader选举过程
选举的轮次 选举出来的leader要包含更多的日志- 1
- 2
- 3
-
1.2 leader选举的效率
会不会出现split vote?以及各自的特点是?- 1
-
1.3 加入一个已经完成选举的集群
怎么发现已完成选举的leader? 加入过程是否对leader处理请求的过程造成阻塞?- 1
- 2
- 3
-
1.4 leader选举的触发
谁在负责检测需要进入leader选举?- 1
-
-
2 上一轮次的leader
- 2.1 上一轮次的leader的残留的数据怎么处理?
- 2.2 怎么阻止之前的leader假死的问题
-
3 请求处理流程
-
3.1 请求处理的一般流程
-
3.2 日志的连续性问题
-
3.3 如何保证顺序
-
3.3.1 正常同步过程的顺序
-
3.3.2 异常过程的顺序
follower挂掉又连接 leader更换- 1
- 2
- 3
-
-
3.4 请求处理流程的异常
-
-
4 分区的处理
下面分别来看看Raft和ZooKeeper怎么来解决的
1 leader选举
为什么要进行leader选举?
在实现一致性的方案,可以像base-paxos那样不需要leader选举,这种方案达成一件事情的一致性还好,面对多件事情的一致性就比较复杂了,所以通过选举出一个leader来简化实现的复杂性。
1.1 一般的leader选举过程
更多的有2个要素:
- 1.1.1 选举轮次
- 1.1.2 leader包含更多的日志
1.1.1 选举投票可能会多次轮番上演,为了区分,所以需要定义你的投票是属于哪个轮次的。
- Raft定义了term来表示选举轮次
- ZooKeeper定义了electionEpoch来表示
他们都需要在某个轮次内达成过半投票来结束选举过程
1.1.2 投票PK的过程,更多的是日志越新越多者获胜
在选举leader的时候,通常都希望
选举出来的leader至少包含之前全部已提交的日志
自然想到包含的日志越新越大那就越好。
通常都是比较最后一个日志记录,如何来定义最后一个日志记录?
有2种选择,一种就是所有日志中的最后一个日志,另一种就是所有已提交中的最后一个日志。目前Raft和ZooKeeper都是采用前一种方式。日志的越新越大表示:轮次新的优先,然后才是同一轮次下日志记录大的优先
-
Raft:term大的优先,然后entry的index大的优先
-
ZooKeeper:peerEpoch大的优先,然后zxid大的优先
ZooKeeper有2个轮次,一个是选举轮次electionEpoch,另一个是日志的轮次peerEpoch(即表示这个日志是哪个轮次产生的)。而Raft则是只有一个轮次,相当于日志轮次和选举轮次共用了。至于ZooKeeper为什么要把这2个轮次分开,这个稍后再细究,有兴趣的可以一起研究。- 1
但是有一个问题就是:通过上述的日志越新越大的比较方式能达到我们的上述希望吗?
特殊情况下是不能的,这个特殊情况详细见上述给出Raft算法赏析的这一部分
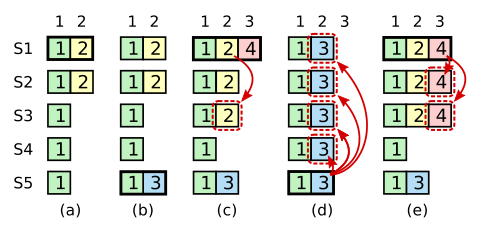
这个案例就是这种比较方式会选举出来的leader可能并不包含已经提交的日志,而Raft的做法则是对于日志的提交多加一个限制条件,即不能直接提交之前term的已过半的entry,即把这一部分的日志限制成未提交的日志,从而来实现上述的希望。
ZooKeeper呢?会不会出现这种情况?又是如何处理的?
ZooKeeper是不会出现这种情况的,因为ZooKeeper在每次leader选举完成之后,都会进行数据之间的同步纠正,所以每一个轮次,大家都日志内容都是统一的
而Raft在leader选举完成之后没有这个同步过程,而是靠之后的AppendEntries RPC请求的一致性检查来实现纠正过程,则就会出现上述案例中隔了几个轮次还不统一的现象
1.2 leader选举的效率
Raft中的每个server在某个term轮次内只能投一次票,哪个candidate先请求投票谁就可能先获得投票,这样就可能造成split vote,即各个candidate都没有收到过半的投票,Raft通过candidate设置不同的超时时间,来快速解决这个问题,使得先超时的candidate(在其他人还未超时时)优先请求来获得过半投票
ZooKeeper中的每个server,在某个electionEpoch轮次内,可以投多次票,只要遇到更大的票就更新,然后分发新的投票给所有人。这种情况下不存在split vote现象,同时有利于选出含有更新更多的日志的server,但是选举时间理论上相对Raft要花费的多。
1.3 加入一个已经完成选举的集群
- 1.3.1 怎么发现已完成选举的leader?
- 1.3.2 加入过程是否阻塞整个请求?
1.3.1 怎么发现已完成选举的leader?
一个server启动后(该server本来就属于该集群的成员配置之一,所以这里不是新加机器),如何加入一个已经选举完成的集群
- Raft:比较简单,该server启动后,会收到leader的AppendEntries RPC,这时就会从RPC中获取leader信息,识别到leader,即使该leader是一个老的leader,之后新leader仍然会发送AppendEntries RPC,这时就会接收到新的leader了(因为新leader的term比老leader的term大,所以会更新leader)
- ZooKeeper:该server启动后,会向所有的server发送投票通知,这时候就会收到处于LOOKING、FOLLOWING状态的server的投票(这种状态下的投票指向的leader),则该server放弃自己的投票,判断上述投票是否过半,过半则可以确认该投票的内容就是新的leader。
1.3.2 加入过程是否阻塞整个请求?
这个其实还要看对日志的设计是否是连续的
-
如果是连续的,则leader中只需要保存每个follower上一次的同步位置,这样在同步的时候就会自动将之前欠缺的数据补上,不会阻塞整个请求过程
目前Raft的日志是依靠index来实现连续的- 1
-
如果不是连续的,则在确认follower和leader当前数据的差异的时候,是需要获取leader当前数据的读锁,禁止这个期间对数据的修改。差异确定完成之后,释放读锁,允许leader数据被修改,每一个修改记录都要被保存起来,最后一一应用到新加入的follower中。
目前ZooKeeper的日志zxid并不是严格连续的,允许有空洞- 1
1.4 leader选举的触发
触发一般有如下2个时机
- server刚开始启动的时候,触发leader选举
- leader选举完成之后,检测到超时触发,谁来检测?
- Raft:目前只是follower在检测。follower有一个选举时间,在该时间内如果未收到leader的心跳信息,则follower转变成candidate,自增term发起新一轮的投票,leader遇到新的term则自动转变成follower的状态
- ZooKeeper:leader和follower都有各自的检测超时方式,leader是检测是否过半follower心跳回复了,follower检测leader是否发送心跳了。一旦leader检测失败,则leader进入LOOKING状态,其他follower过一段时间因收不到leader心跳也会进入LOOKING状态,从而出发新的leader选举。一旦follower检测失败了,则该follower进入LOOKING状态,此时leader和其他follower仍然保持良好,则该follower仍然是去学习上述leader的投票,而不是触发新一轮的leader选举
2 上一轮次的leader
2.1 上一轮次的leader的残留的数据怎么处理?
首先看下上一轮次的leader在挂或者失去leader位置之前,会有哪些数据?
- 已过半复制的日志
- 未过半复制的日志
一个日志是否被过半复制,是否被提交,这些信息是由leader才能知晓的,那么下一个leader该如何来判定这些日志呢?
下面分别来看看Raft和ZooKeeper的处理策略:
- Raft:对于之前term的过半或未过半复制的日志采取的是保守的策略,全部判定为未提交,只有当当前term的日志过半了,才会顺便将之前term的日志进行提交
- ZooKeeper:采取激进的策略,对于所有过半还是未过半的日志都判定为提交,都将其应用到状态机中
Raft的保守策略更多是因为Raft在leader选举完成之后,没有同步更新过程来保持和leader一致(在可以对外处理请求之前的这一同步过程)。而ZooKeeper是有该过程的
2.2 怎么阻止上一轮次的leader假死的问题
这其实就和实现有密切的关系了。
- Raft的copycat实现为:每个follower开通一个复制数据的RPC接口,谁都可以连接并调用该接口,所以Raft需要来阻止上一轮次的leader的调用。每一轮次都会有对应的轮次号,用来进行区分,Raft的轮次号就是term,一旦旧leader对follower发送请求,follower会发现当前请求term小于自己的term,则直接忽略掉该请求,自然就解决了旧leader的干扰问题
- ZooKeeper:一旦server进入leader选举状态则该follower会关闭与leader之间的连接,所以旧leader就无法发送复制数据的请求到新的follower了,也就无法造成干扰了
3 请求处理流程
3.1 请求处理的一般流程
这个过程对比Raft和ZooKeeper基本上是一致的,大致过程都是过半复制
先来看下Raft:
- client连接follower或者leader,如果连接的是follower则,follower会把client的请求(写请求,读请求则自身就可以直接处理)转发到leader
- leader接收到client的请求,将该请求转换成entry,写入到自己的日志中,得到在日志中的index,会将该entry发送给所有的follower(实际上是批量的entries)
- follower接收到leader的AppendEntries RPC请求之后,会将leader传过来的批量entries写入到文件中(通常并没有立即刷新到磁盘),然后向leader回复OK
- leader收到过半的OK回复之后,就认为可以提交了,然后应用到leader自己的状态机中,leader更新commitIndex,应用完毕后回复客户端
- 在下一次leader发给follower的心跳中,会将leader的commitIndex传递给follower,follower发现commitIndex更新了则也将commitIndex之前的日志都进行提交和应用到状态机中
再来看看ZooKeeper:
- client连接follower或者leader,如果连接的是follower则,follower会把client的请求(写请求,读请求则自身就可以直接处理)转发到leader
- leader接收到client的请求,将该请求转换成一个议案,写入到自己的日志中,会将该议案发送给所有的follower(这里只是单个发送)
- follower接收到leader的议案请求之后,会将该议案写入到文件中(通常并没有立即刷新到磁盘),然后向leader回复OK
- leader收到过半的OK回复之后,就认为可以提交了,leader会向所有的follower发送一个提交上述议案的请求,同时leader自己也会提交该议案,应用到自己的状态机中,完毕后回复客户端
- follower在接收到leader传过来的提交议案请求之后,对该议案进行提交,应用到状态机中
3.2 日志的连续性问题
在需要保证顺序性的前提下,在利用一致性算法实现状态机的时候,到底是实现连续性日志好呢还是实现非连续性日志好呢?
- 如果是连续性日志,则leader在分发给各个follower的时候,只需要记录每个follower目前已经同步的index即可,如Raft
- 如果是非连续性日志,如ZooKeeper,则leader需要为每个follower单独保存一个队列,用于存放所有的改动,如ZooKeeper,一旦是队列就引入了一个问题即顺序性问题,即follower在和leader进行同步的时候,需要阻塞leader处理写请求,先将follower和leader之间的差异数据先放入队列,完成之后,解除阻塞,允许leader处理写请求,即允许往该队列中放入新的写请求,从而来保证顺序性
还有在复制和提交的时候:
- 连续性日志可以批量进行
- 非连续性日志则只能一个一个来复制和提交
其他有待后续补充
3.3 如何保证顺序
具体顺序是什么?
这个就是先到达leader的请求,先被应用到状态机。这就需要看正常运行过程、异常出现过程都是怎么来保证顺序的
3.3.1 正常同步过程的顺序
- Raft对请求先转换成entry,复制时,也是按照leader中log的顺序复制给follower的,对entry的提交是按index进行顺序提交的,是可以保证顺序的
- ZooKeeper在提交议案的时候也是按顺序写入各个follower对应在leader中的队列,然后follower必然是按照顺序来接收到议案的,对于议案的过半提交也都是一个个来进行的
3.3.2 异常过程的顺序保证
如follower挂掉又重启的过程:
-
Raft:重启之后,由于leader的AppendEntries RPC调用,识别到leader,leader仍然会按照leader的log进行顺序复制,也不用关心在复制期间新的添加的日志,在下一次同步中自动会同步
-
ZooKeeper:重启之后,需要和当前leader数据之间进行差异的确定,同时期间又有新的请求到来,所以需要暂时获取leader数据的读锁,禁止此期间的数据更改,先将差异的数据先放入队列,差异确定完毕之后,还需要将leader中已提交的议案和未提交的议案也全部放入队列,即ZooKeeper的如下2个集合数据
-
ConcurrentMap outstandingProposals
Leader拥有的属性,每当提出一个议案,都会将该议案存放至outstandingProposals,一旦议案被过半认同了,就要提交该议案,则从outstandingProposals中删除该议案- 1
-
ConcurrentLinkedQueue toBeApplied
Leader拥有的属性,每当准备提交一个议案,就会将该议案存放至该列表中,一旦议案应用到ZooKeeper的内存树中了,然后就可以将该议案从toBeApplied中删除- 1
然后再释放读锁,允许leader进行处理写数据的请求,该请求自然就添加在了上述队列的后面,从而保证了队列中的数据是有序的,从而保证发给follower的数据是有序的,follower也是一个个进行确认的,所以对于leader的回复也是有序的
-
如果是leader挂了之后,重新选举出leader,会不会有乱序的问题?
- Raft:Raft对于之前term的entry被过半复制暂不提交,只有当本term的数据提交了才能将之前term的数据一起提交,也是能保证顺序的
- ZooKeeper:ZooKeeper每次leader选举之后都会进行数据同步,不会有乱序问题
3.4 请求处理流程的异常
一旦leader发给follower的数据出现超时等异常
- Raft:会不断重试,并且接口是幂等的
- ZooKeeper:follower会断开与leader之间的连接,重新加入该集群,加入逻辑前面已经说了
4 分区的应对
目前ZooKeeper和Raft都是过半即可,所以对于分区是容忍的。如5台机器,分区发生后分成2部分,一部分3台,另一部分2台,这2部分之间无法相互通信
其中,含有3台的那部分,仍然可以凑成一个过半,仍然可以对外提供服务,但是它不允许有server再挂了,一旦再挂一台则就全部不可用了。
含有2台的那部分,则无法提供服务,即只要连接的是这2台机器,都无法执行相关请求。
所以ZooKeeper和Raft在一旦分区发生的情况下是是牺牲了高可用来保证一致性,即CAP理论中的CP。但是在没有分区发生的情况下既能保证高可用又能保证一致性,所以更想说的是所谓的CAP二者取其一,并不是说该系统一直保持CA或者CP或者AP,而是一个会变化的过程。在没有分区出现的情况下,既可以保证C又可以保证A,在分区出现的情况下,那就需要从C和A中选择一样。ZooKeeper和Raft则都是选择了C。

