
热门标签
当前位置: article > 正文
阿里又放大招 EMO:一张照片+音频即可生成会说话唱歌的视频_用声音驱动照片生成视频 阿里
作者:我家自动化 | 2024-03-24 16:13:27
赞
踩
用声音驱动照片生成视频 阿里
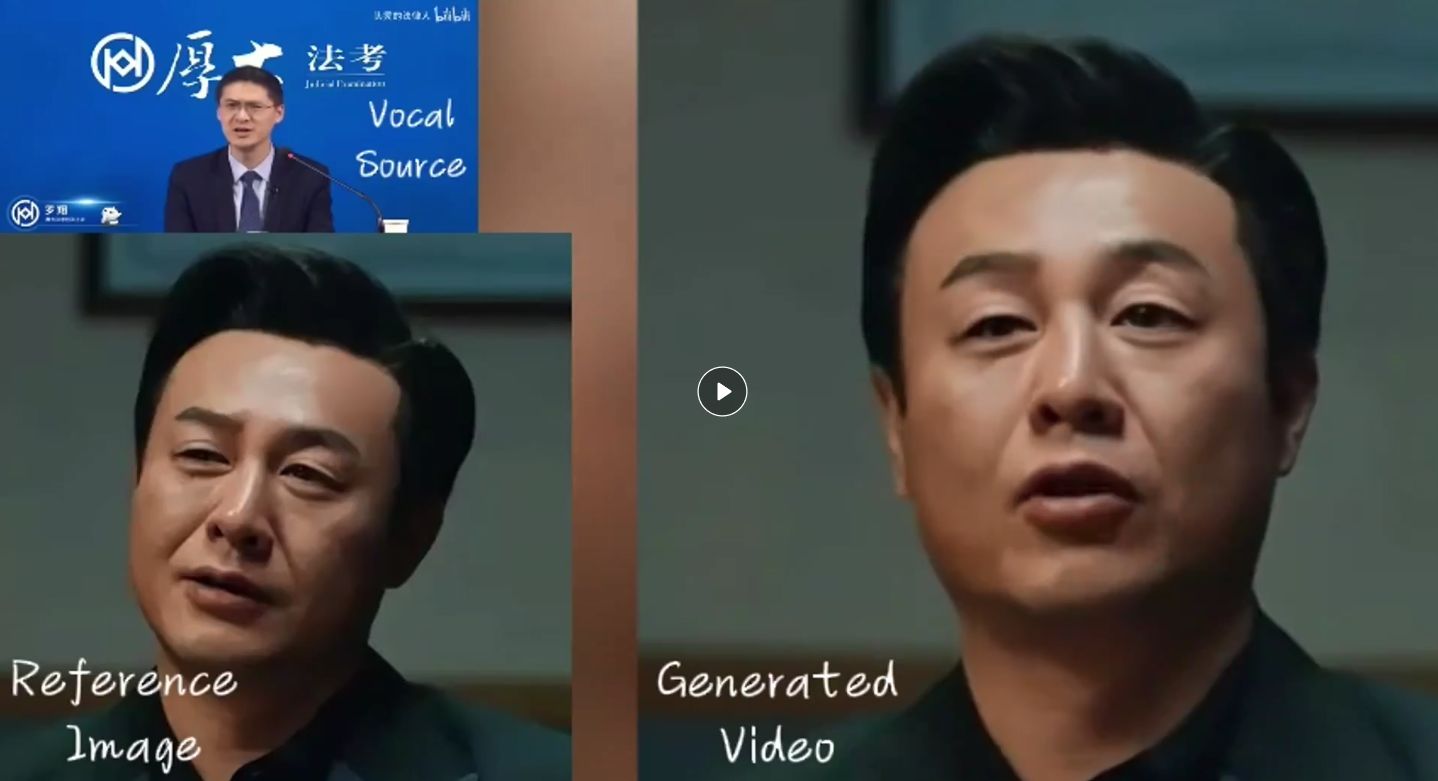
项目简介
你只需要提供一张你的照片+任意的音频文件,就能实现你说任何话或唱任何歌曲的动态视频。
同时生成视频的长度和你音频长度相匹配!
表情非常到位,支持任意语音、任意语速、任意图像。

主要特点和功能
1、音频驱动的人像视频生成: 利用单张参考图像和音频输入(如说话或唱歌),EMO能够生成具有表情变化和头部动态的虚拟人像视频。这意味着用户可以通过提供一张静态图片和相应的音频文件,来创造出说话或唱歌的动态视频。无论视频中的人物进行怎样的表情变化或头部动作,其基础特征都来源于这张参考图片。
2、表情丰富的动态渲染:EMO特别强调在视频中生成自然而富有表情的面部动作,能够捕捉到音频中情感的细微差别,并将其反映在人像的表情上,从而生成看起来自然、生动的面部动画。
3、多头部姿势支持: 除了面部表情外,EMO还能够根据音频生成多样的头部姿势变化,增加了视频的动态性和真实感。
4、支持多种语言和肖像风格: 该技术不限于特定语言或音乐风格,能够处理多种语言的音频输入,并且支持多样化的肖像风格,包括历史人物、绘画作品、3D模型和AI生成内容等。
5、快速节奏同步:EMO能够处理快节奏的音频,如快速的歌词或说话,确保虚拟人像的动作与音频节奏保持同步。
6、跨演员表现转换:EMO能够实现不同演员之间的表现转换,使得一位演员的虚拟形象能够模仿另一位演员或声音的特定表演,拓展了角色描绘的多样性和应用场景。

项目地址:humanaigc.github.io/emote-portrait…
论文:arxiv.org/abs/2402.17485
GitHub:github.com/HumanAIGC/EMO
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/303501
推荐阅读
相关标签

