一、大模型开发整理流程
1.1、什么是大模型开发
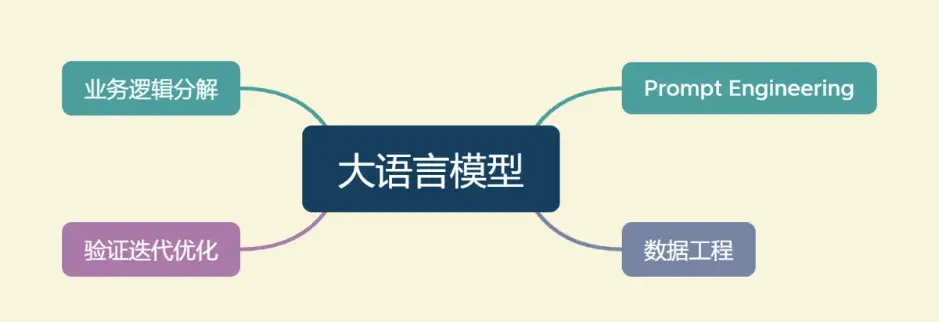
我们将开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。
开发大模型相关应用,其技术核心点虽然在大语言模型上,但一般通过调用 API 或开源模型来实现核心的理解与生成,通过 Prompt Enginnering 来实现大语言模型的控制,因此,虽然大模型是深度学习领域的集大成之作,大模型开发却更多是一个工程问题。
在大模型开发中,我们一般不会去大幅度改动模型,而是将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务,而不会将精力聚焦在优化模型本身上。