
- 1华为官方推荐:学习鸿蒙开发高分好书,这6本能帮你很多!_鸿蒙开发 推荐 书籍
- 2ELF文件中得section(.data .bss .text .altinstr_replacement、.altinstr_aux)_.section .datar, data
- 3ssm的maven坐标_ssm maven 坐标
- 4MySQL存储引擎详解(一)-InnoDB架构_mysql引擎innodb
- 5(一)使用AI、CodeFun开发个人名片微信小程序_ai生成小程序代码
- 6求助:R包安装失败_cannot open compressed file description
- 74款超好用的AI换脸软件,一键视频直播换脸(附下载链接)
- 8【深度学习】激活函数(sigmoid、ReLU、tanh)_sigmoid激活函数
- 9操作系统的程序内存结构 —— data和bss为什么需要分开,各自的作用_为什么分bss和data
- 10记一次 Docker Nginx 自定义 log_format 报错的解决方案_log_format" directive no dyconf_version config in
[机器学习笔记] 支持向量机SVM 和逻辑回归LR的异同_lr+svmpython实现
赞
踩
参考: https://www.cnblogs.com/zhizhan/p/5038747.html
为什么把SVM和LR放在一起进行比较?
一是因为这两个模型应用广泛。
二是因为这两个模型有很多相同点,在使用时容易混淆,不知道用哪个好,特别是对初学者。
相同点
- 都是线性分类器。本质上都是求一个最佳分类超平面。
- 都是监督学习算法。
- 都是判别模型。通过决策函数,判别输入特征之间的差别来进行分类。
常见的判别模型有:KNN、SVM、LR。
常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。
不同点
1) 本质上是损失函数不同
LR的损失函数是交叉熵:
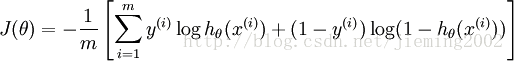
SVM的目标函数:
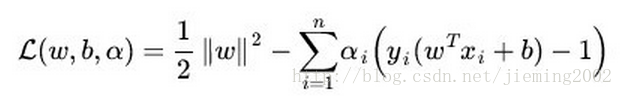
【【是不是看到公式就头痛?一大堆符号,都不知道什么意思。其实,公式都是有规律的,复杂公式是由简单公式组成的,最简单的是加减乘除法。
逻辑回归基于概率理论,假设样本为正样本的概率可以用sigmoid函数(S型函数)来表示,然后通过极大似然估计的方法估计出参数的值。
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面。
2) 两个模型对数据和参数的敏感程度不同
SVM考虑分类边界线附近的样本(决定分类超平面的样本)。在支持向量外添加或减少任何样本点对分类决策面没有任何影响;
LR受所有数据点的影响。直接依赖数据分布,每个样本点都会影响决策面的结果。如果训练数据不同类别严重不平衡,则一般需要先对数据做平衡处理,让不同类别的样本尽量平衡。
3) SVM 基于距离分类,LR 基于概率分类。
SVM依赖数据表达的距离测度,所以需要对数据先做 normalization;LR不受其影响。
4) 在解决非线性问题时,支持向量机采用核函数的机制,而LR通常不采用核函数的方法。
SVM算法里,只有少数几个代表支持向量的样本参与分类决策计算,也就是只有少数几个样本需要参与核函数的计算。
LR算法里,每个样本点都必须参与分类决策的计算过程,也就是说,假设我们在LR里也运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。尤其是数据量很大时,我们无法承受。所以,在具体应用时,LR很少运用核函数机制。
5) 在小规模数据集上,Linear SVM要略好于LR,但差别也不是特别大,而且Linear SVM的计算复杂度受数据量限制,对海量数据LR使用更加广泛。
6) SVM的损失函数就自带正则,而 LR 必须另外在损失函数之外添加正则项。

红框内就是L2正则。

