
- 1docker centos7离线安装ElasticSearch单机版
- 2ios 自己创建的动态frameworks 怎么发布_iOS 打包签名,你真的懂吗?
- 3Windows XP超强50招
- 4OpenHarmony媒体子系统媒体引擎组件_openharmony媒体子系统架构到硬件抽象适配层
- 5基于Python的BeautifulSoup库爬取电影、图书、音乐数据的数据分析系统设计与实现_使用beautifulsoup库爬取电影数据的实验报告
- 6Python 迁移学习实用指南:1~5_迁移学习 python
- 7东方 - 二分查找和二分答案_1894 - 二分查找左侧边界
- 8NLP常见任务及评估指标_nlp评价指标
- 9MySql概述及其性能说明_大量使用mysql,性能能否支撑后续发展,文档如何解释
- 10微信小程序相关面试题_微信小程序思考题
grad-cam实现可视化|mmselfsup自监督|保姆级教学
赞
踩
大家好,这里是【来一块葱花饼】,这次带来了grad-cam实现可视化(以mmselfsup的自监督为主)的技术分享,十分全面,与你分享~
1.grad-cam原理
Grad-CAM是使用任何目标概念的梯度(比如分类类别中的某一类的logits,甚至是caption任务中的输出),流入最后的卷积层,生成一个粗略的定位图来突出显示图像中用于预测的重要区域。
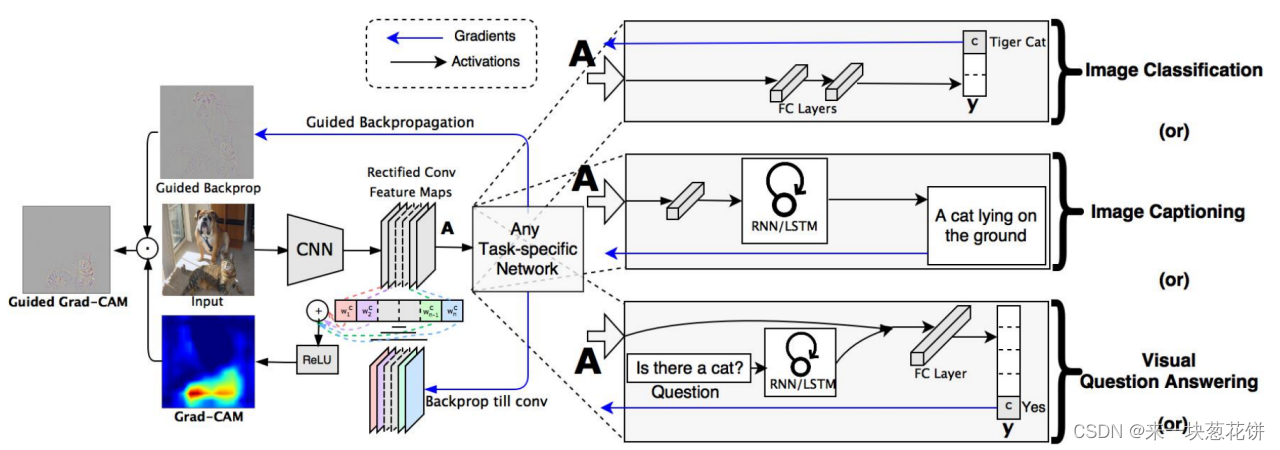
概述:给定一个图像和一个感兴趣的类别(例如,“虎猫”或任何其他类型的可微输出)作为输入,我们通过模型的CNN部分向前传播图像然后通过特定于任务的计算来获得该类别的原始分数。
除了所需的类(老虎cat)外,所有类的梯度都被设置为零,它被设置为1。这个信号是t当反向传播到感兴趣的修正卷积特征图,我们将其结合起来计算粗粒-cam定位(蓝色热图),它表示模型必须关注的位置做出特定的决定。最后,我们将热图与引导反向传播点乘,得到高分辨率和特定于概念的引导重力-cam可视化。
2.计算方法
首先计算c类别的的模型得分对于某个卷积层的梯度,同时在对于上述过程得到的梯度信息,在每个channel维度上对各像素值取平均(类似Global Average Pooling),得到神经元重要性权重,如下公式所示:
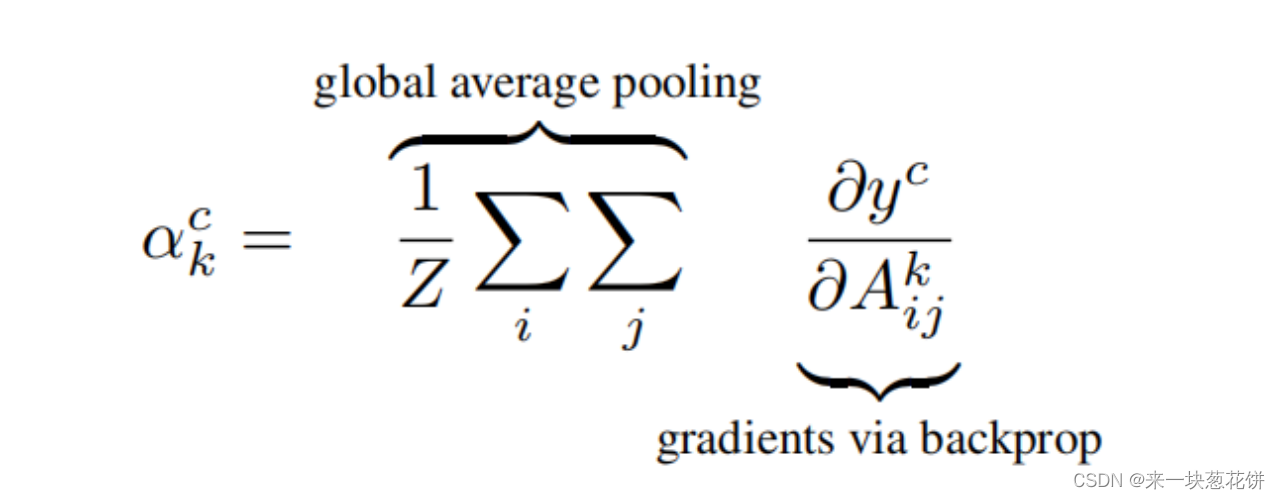
其中Z代表特征图的像素个数,Aij代表第k个特征图的(i,j位置的像素值)
我们首先计算类c,yc(在softmax之前)的分数梯度,关于卷积层的特征地图激活Ak
利用上述得到的神经元重要性权重对选定的卷积层的特征进行加权,如下公式所示:
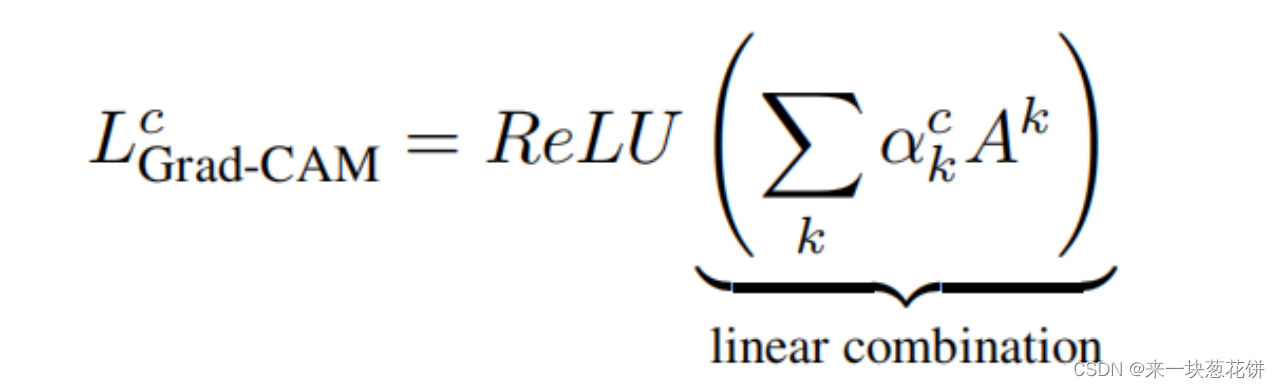
值得注意的是这里加权后输出的粗糙热力图是和选择的卷积层的特征大小一致,随后经过ReLU操作得到热力图,目的是只考虑对类别 c 有正影响的像素点。
3.操作分析
grad-cam,先计算类别c的得分y,关于特征图信息的梯度,这里用到了可视化特征层后面的神经网络信息、以及分类结果。所以就算只可视化某一层,也要用到后面的层计算梯度。而且要用到最后的分类的分数,所以要用到finetune最后的分类器得到的结果。
然后用这个梯度信息,对该层特征图进行加权求和就得到了热力图。
对selfsup可视化,要使用整个完整网络以及最后的分类信息,可视化层可以是fc之前的层也可以是backbone的norm层
所以,还是得用完整的model传入
4.代码开发
之前的进展:
mm的cam扩展是给mmdetection的,mmself不能用。然后我就用了cam的开源脚本pytorch-to-cam。
原先的pytorch-to-cam 使用deit的vit来做可视化。
我想着导入mmself-mocov3的model,但是mm的model会报错,报错很多。
最后我用的方法是:因为官方cam脚本用的是vit最后一个模块的第一个norm层,所以我将mocov3的vit最后一个模块的norm层的参数覆盖了官方model的vit-norm层的参数
相当于,使用我们的参数,使用开源脚本原先的model,最后得到了可视化图
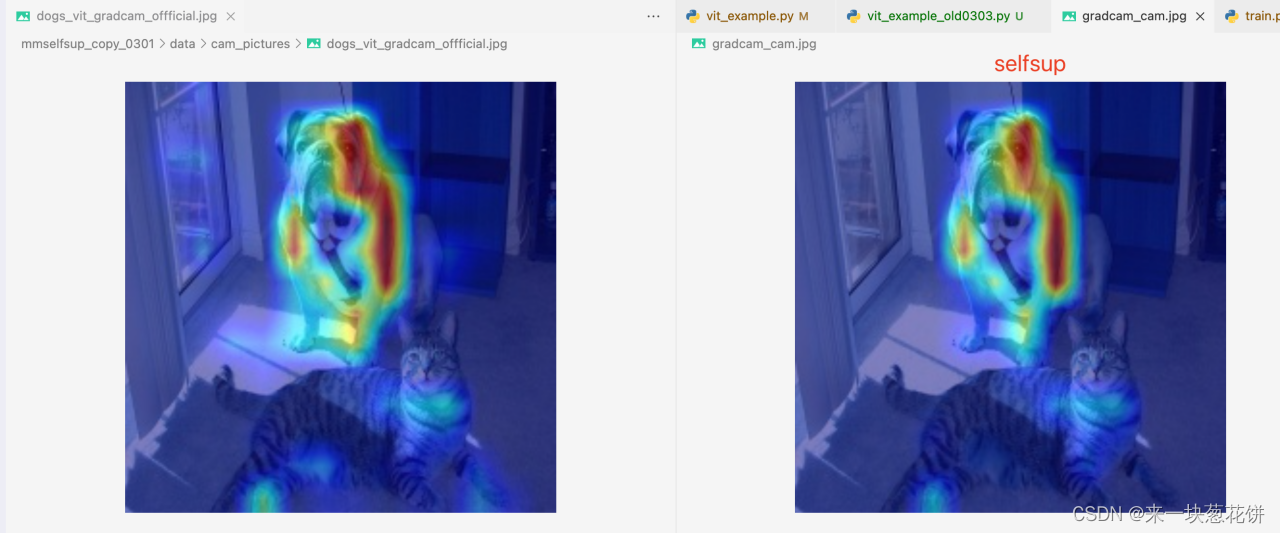
但是这样区别太小了。。而且也不符合grad-cam的原理
TODO:
i. 先尝试init后的完整的mmcv的model(但是还没传入pth的参数),看看会不会报错。。
不报错就好,就按下面的方法来:
一种方法是能否将pth的参数在这里传入model
一种方法是,能否将之前用的runner之前的、经过ddp、已经传入pth参数的model,转为正常的model,再使用
ii.如果传入mmcv的model报错。。。那就只能改mmcls的vis_cam了,主要是将mocov3注册进去使用
参考链接:
github上搜索pytorch-grad-cam(由于网页屏蔽,这里就不放上链接了)
最后代码修改:
0.使用debug调试
使用下游任务的时候,本地环境内存不够,所以使用debug模式,配置launch.json后,进行调试/开发
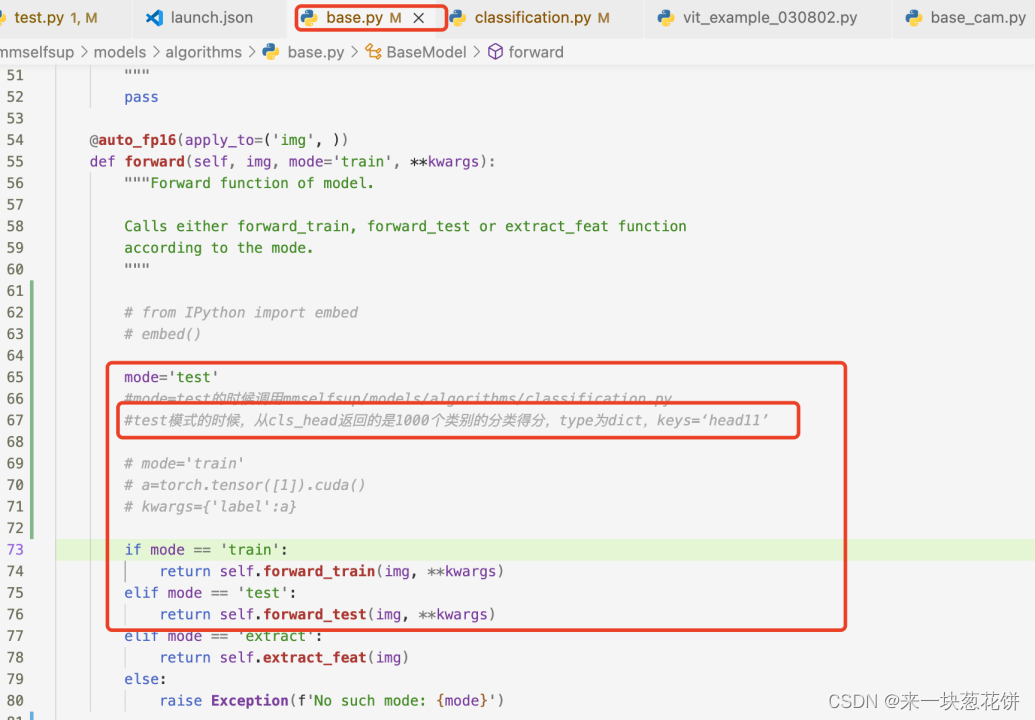
1.更改中间数据处理形式,保留对应信息
#使用该脚本,需要在/anaconda3/envs/mmselfNew/lib/python3.6/site-packages/pytorch_grad_cam/base_cam.py
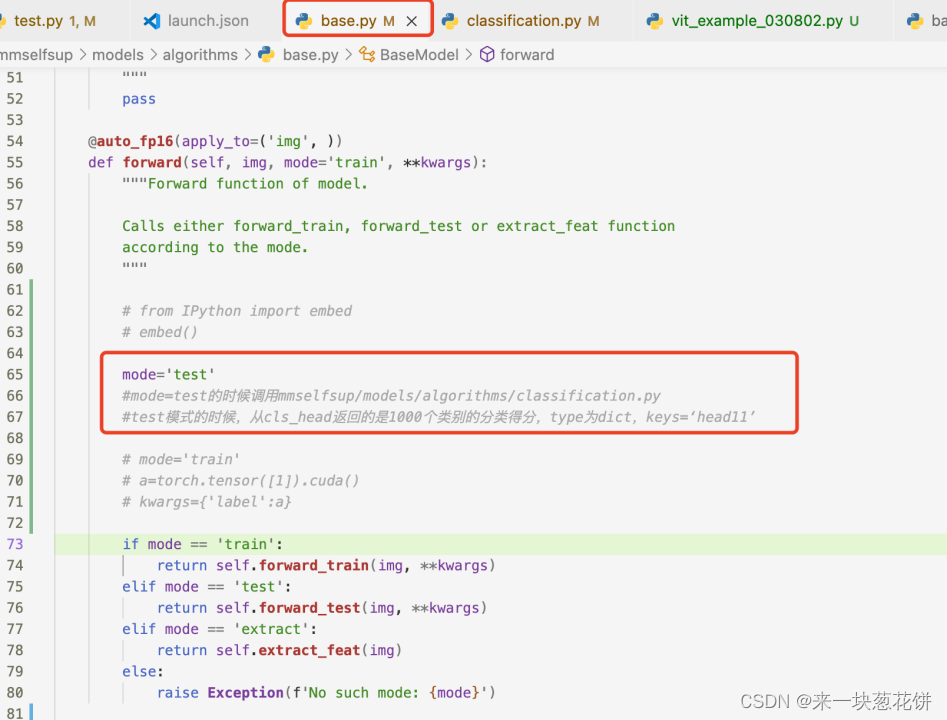
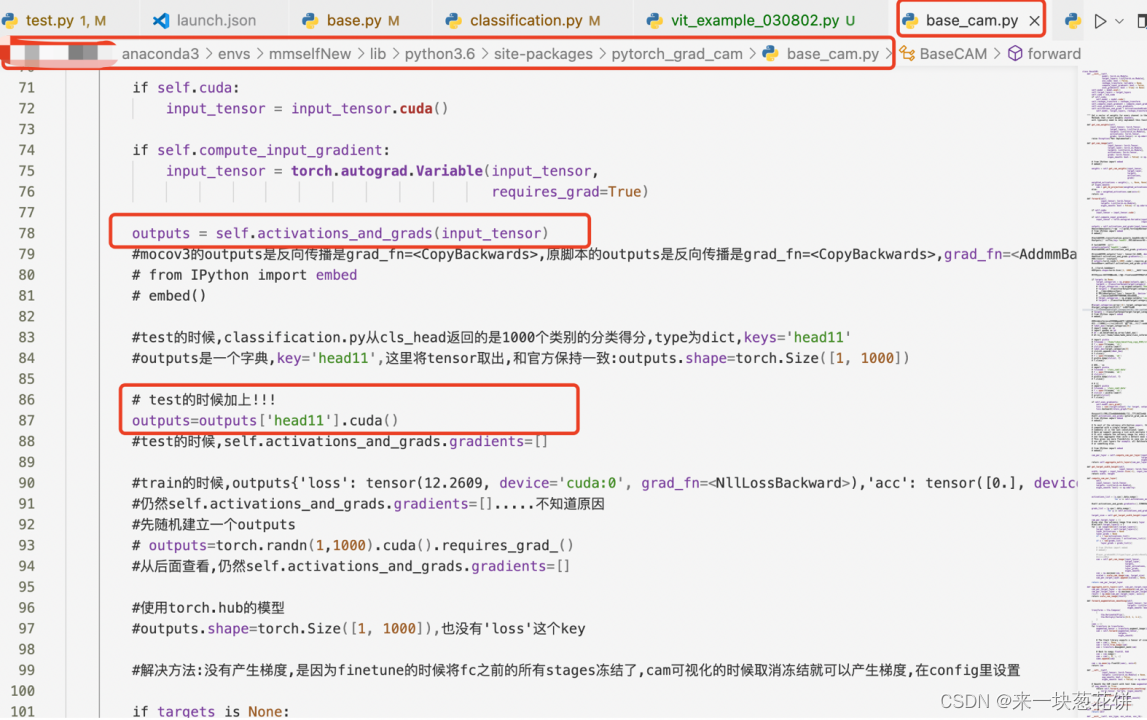
#注释掉87行的outputs=outputs['head11'].cuda()
- 1
- 2
2.进行梯度计算
grad-cam在前向计算之后,获得各类别的得分,使用特征图信息对其计算梯度。
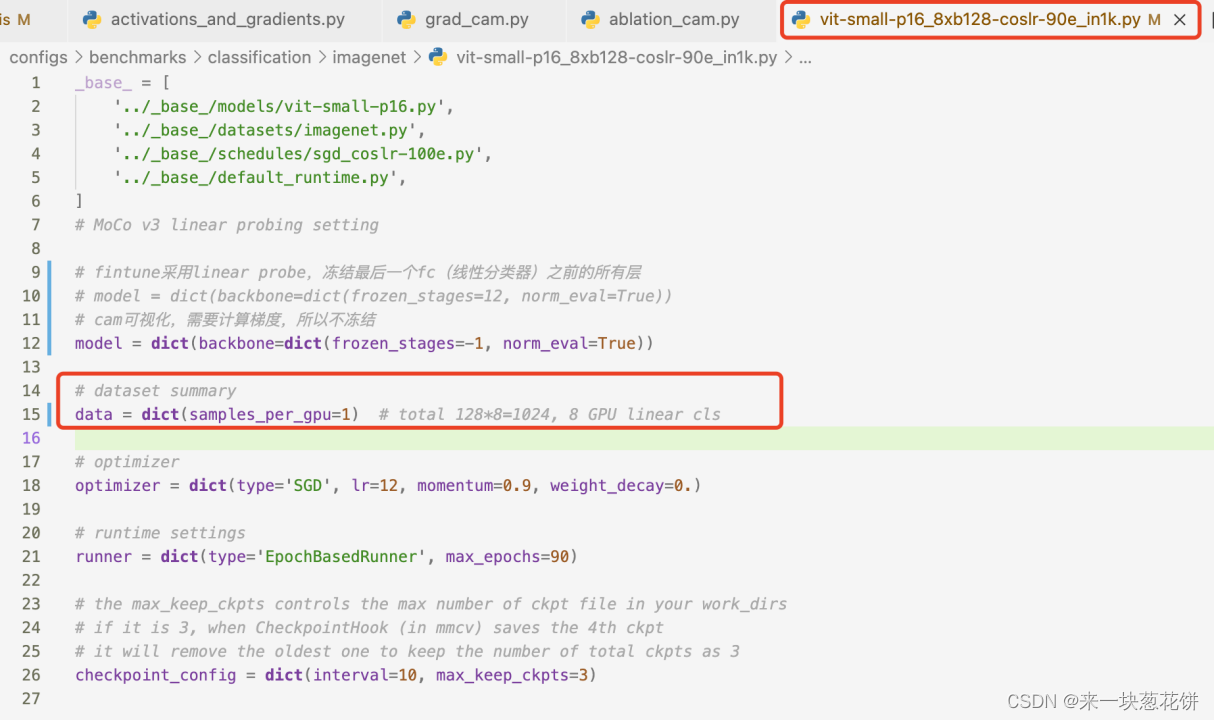
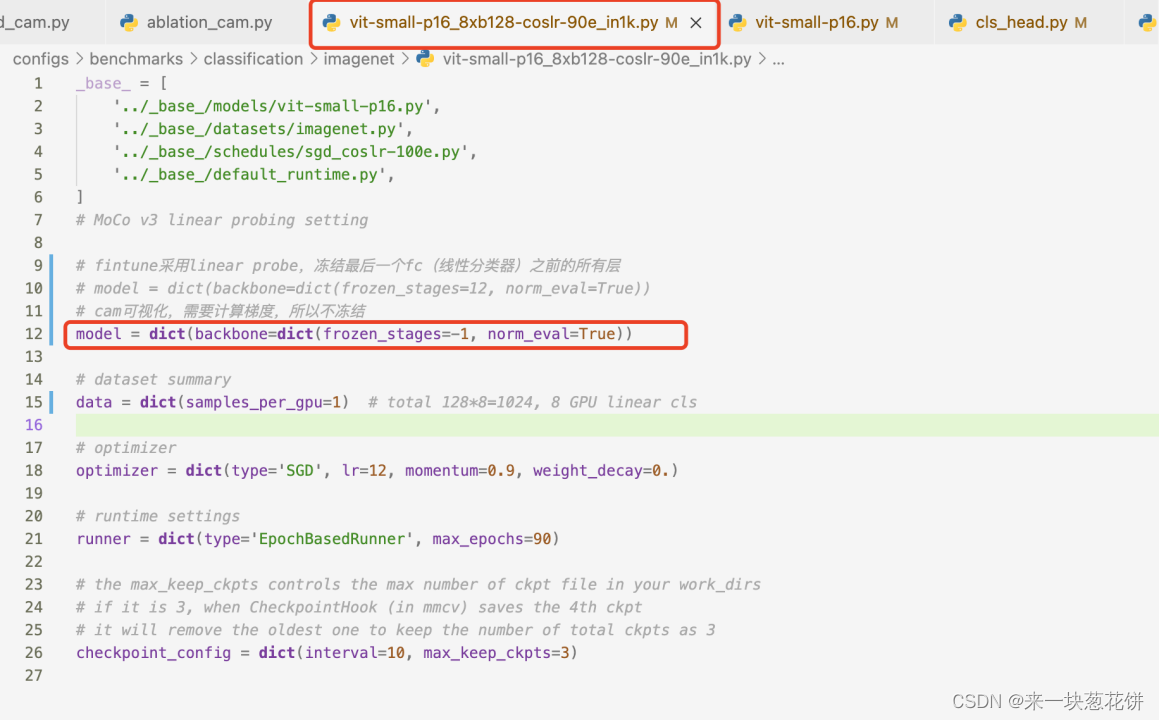
但是mmself的mocov3进行fintune采用linear probe,冻结最后一个fc(线性分类器)之前的所有层
cam可视化,需要计算梯度,要取消冻结
3.修改mocov3代码
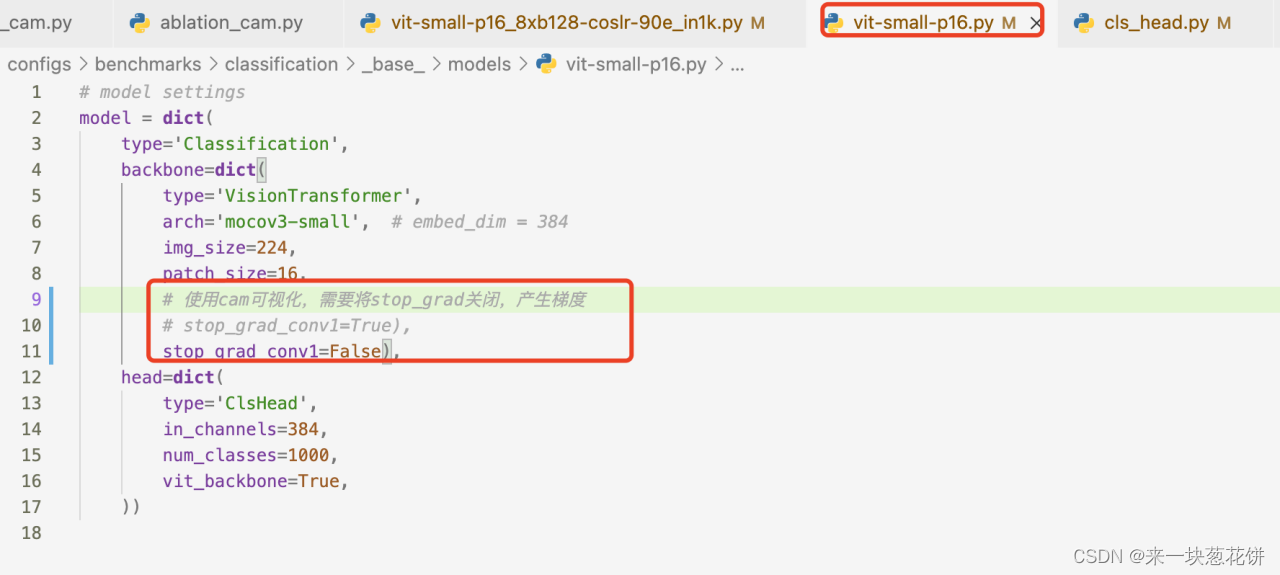
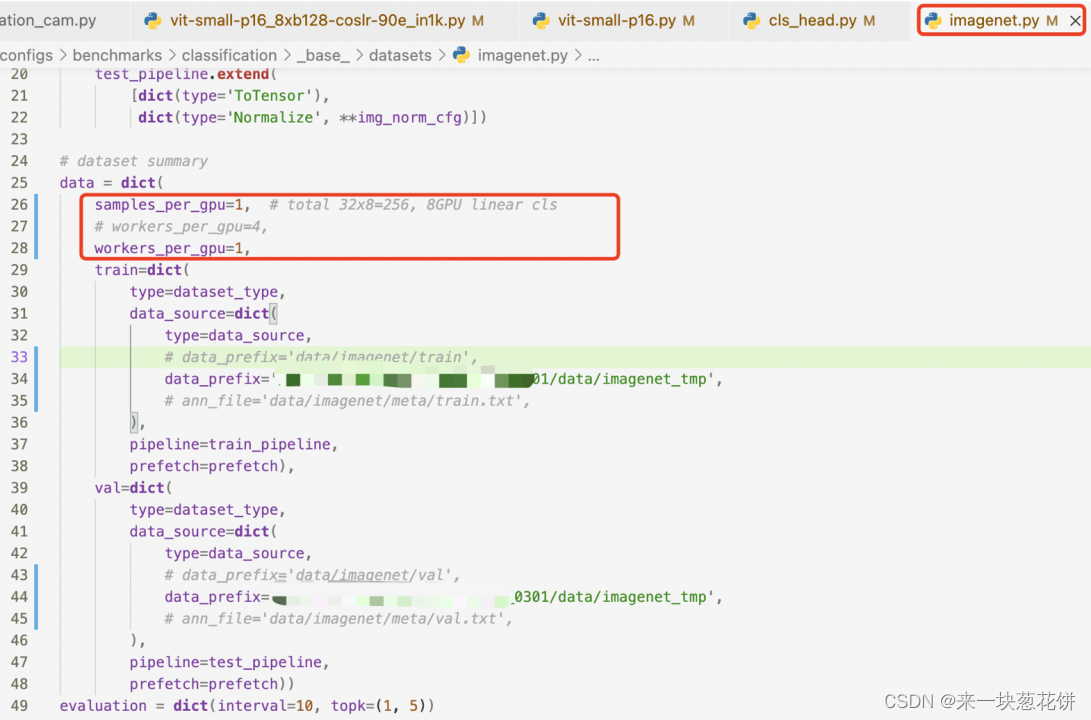

最终使用:
使用tools/test.py,将导入pth参数后的模型传入cam脚本
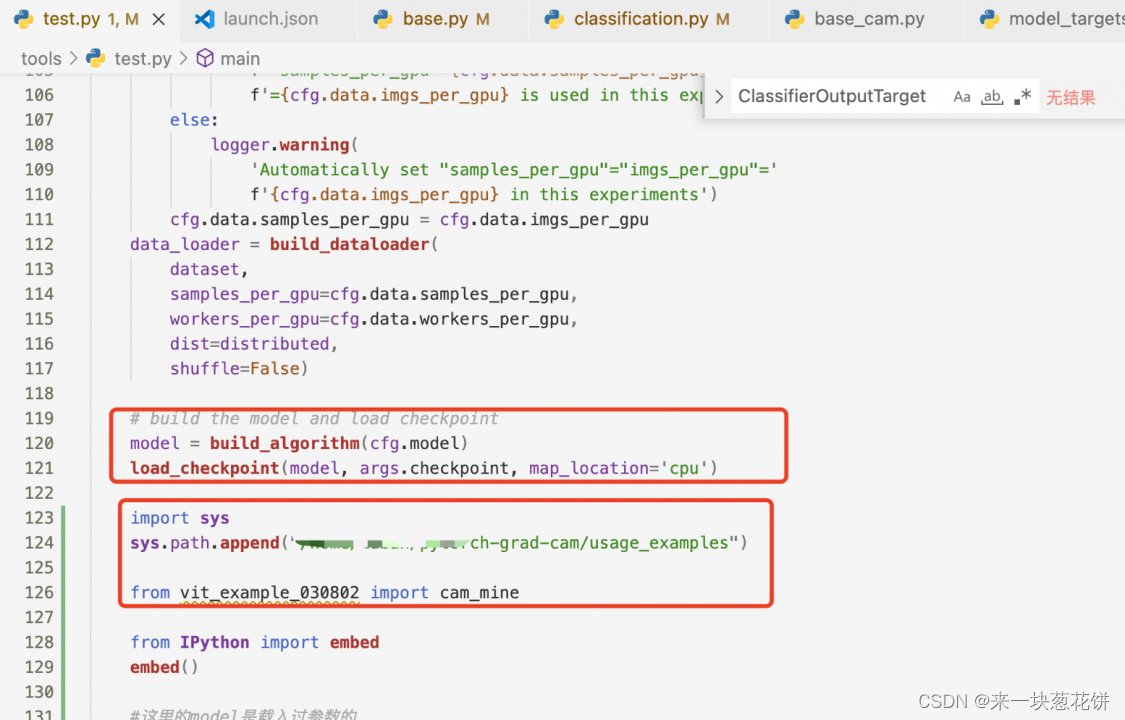
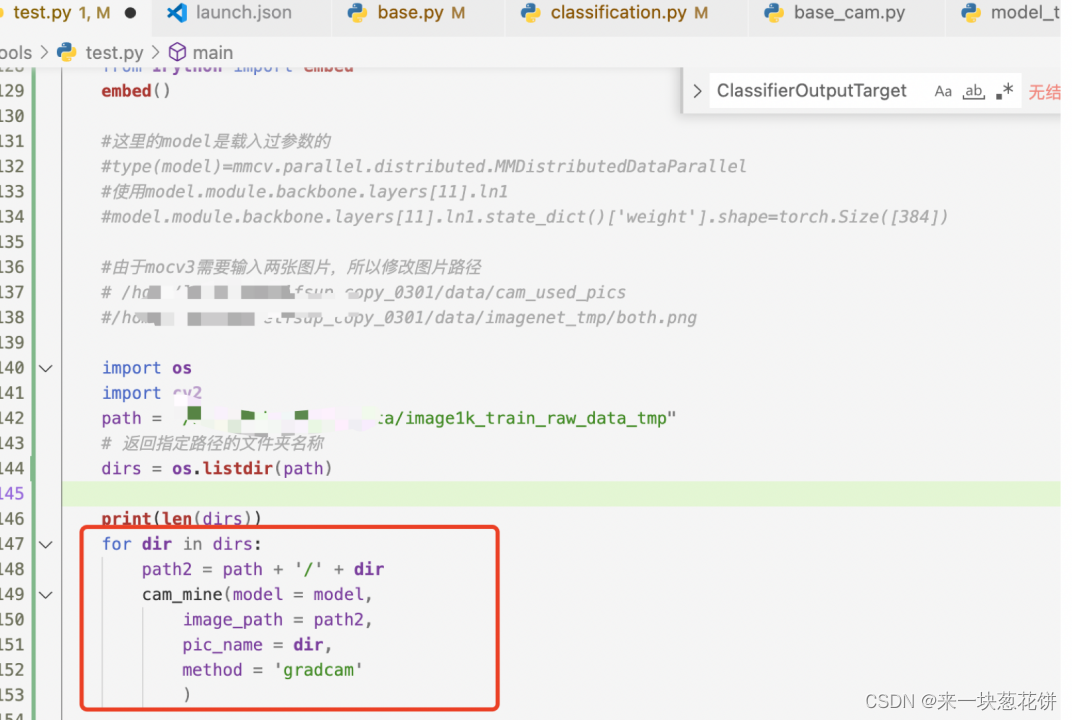
cam脚本:
/pytorch-grad-cam/usage_examples/vit_example_origin.py
#原始脚本
/pytorch-grad-cam/usage_examples/vit_example_030802.py
#实现selfsup的可视化
#将init初始化后的model直接传入,直接计算grad-cam
/pytorch-grad-cam/usage_examples/vit_example_030803.py
#本脚本用来对官方的model(deit,全监督)进行可视化#/anaconda3/envs/mmselfNew/lib/python3.6/site-packages/pytorch_grad_cam/base_cam.py
#将上面文件87行的outputs=outputs['head11'].cuda()注释掉即可,其他不用改
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.效果分析
1)Vision Transformers 选择哪个 target_layer
由于最终分类是在最后一个注意块中计算的类标记上完成的,输出最后是类别,输出对应的梯度为 0,所以我们应该选择最终注意力块之前的任何层。
这里我们选择vit-backbone的最后一个transformer模块的norm层,该norm层在最后的fc之前。
2)使用deit作为对照组
全监督使用Vision Transfomer (Deit Tiny)。deit对vit经过改进,是一种目前效果较好的vit。
使用deit_tiny_patch16_224对应的pth模型。
model = torch.hub.load('facebookresearch/deit:main',
'deit_tiny_patch16_224', pretrained=True)
- 1
- 2

我们使用的模型是:经过finetune的mocov3模型
也是使用imagenet2012

3)对特征层可视化
使用grad-cam,对backbone最后的的fc(线性分类器)前的norm层进行特征图可视化,显示分类得分最高的类别的特征图可视化效果。
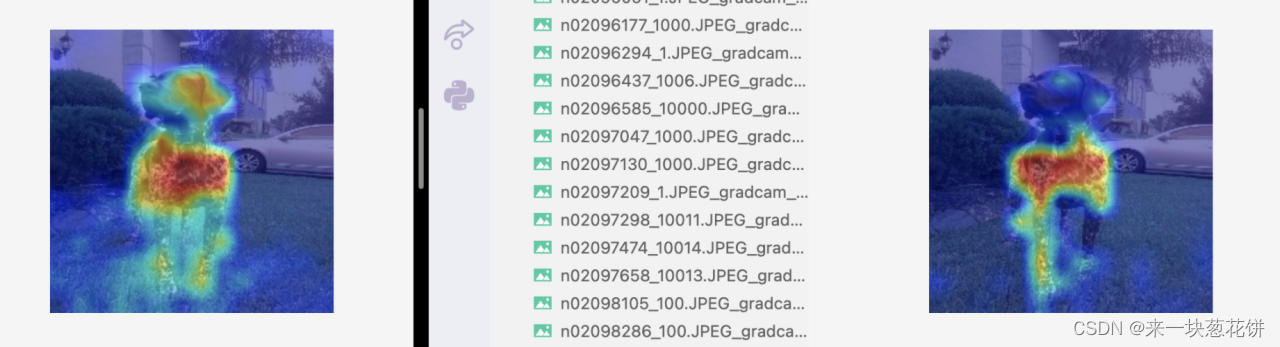
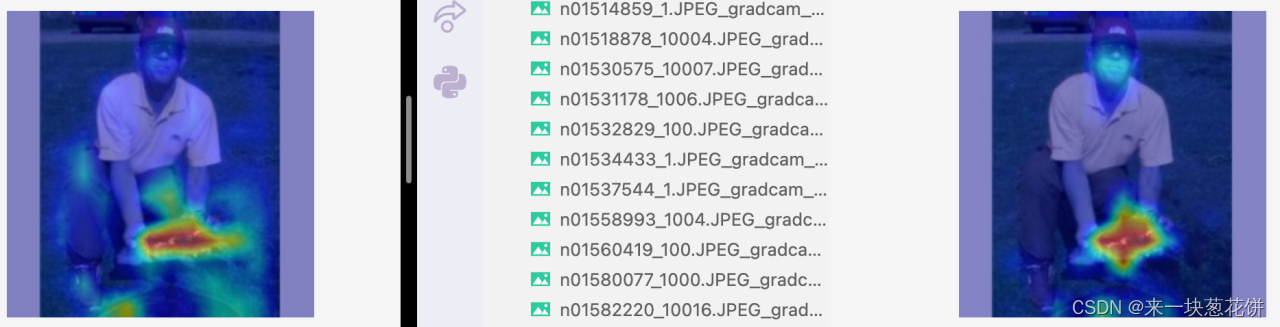
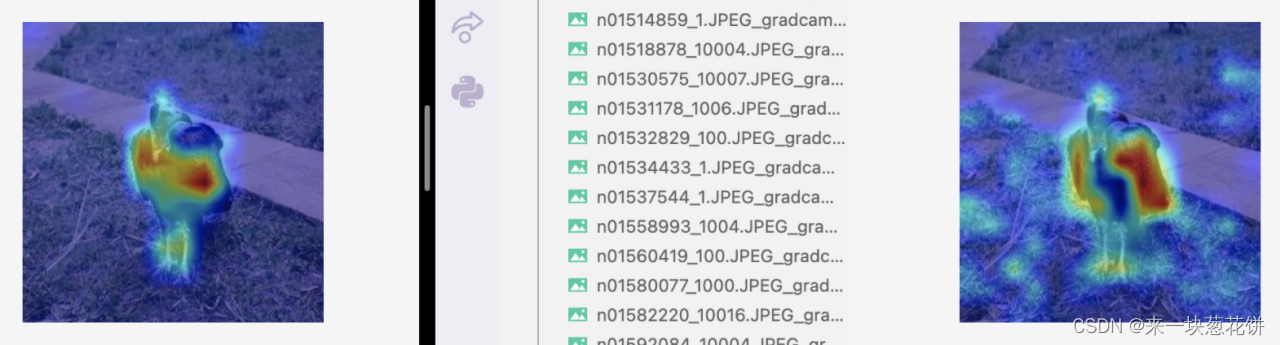
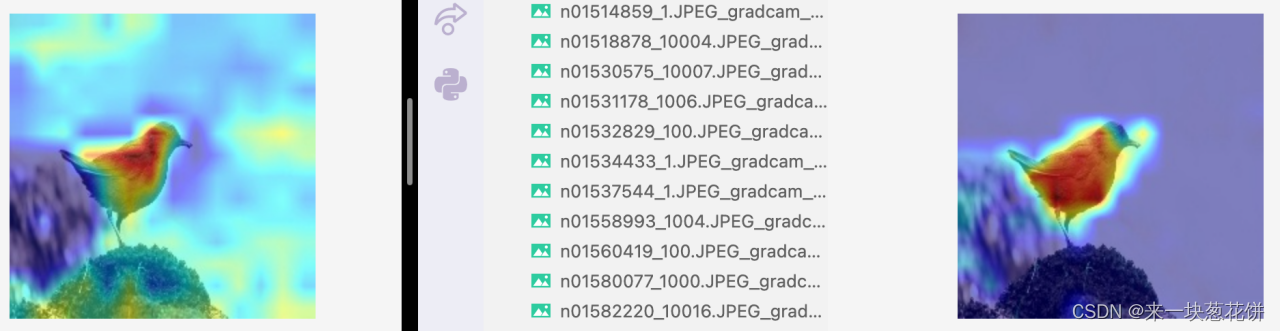
4)结果分析(左图为mocov3-selfsup,右图为deit-全监督)
全监督acc@1=71.5% ,自监督acc@1=70.4% 。我们用的两个模型的性能是接近的。
自监督对object整体的感知更好,并且有较好的边界感
对于一些物体数目少、场景简单、遮挡少的图片,自监督能更好的找到物体,全监督对应的特征图可视化则没有这么好的边界感、容易出现“注意力涣散”
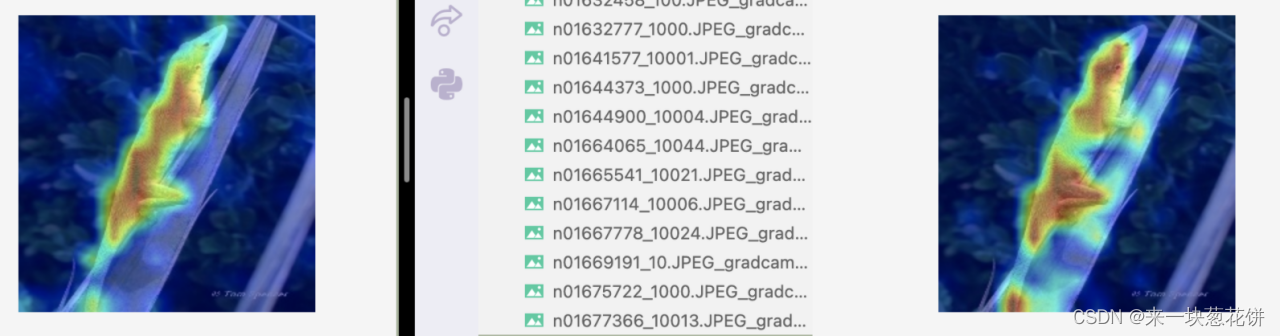
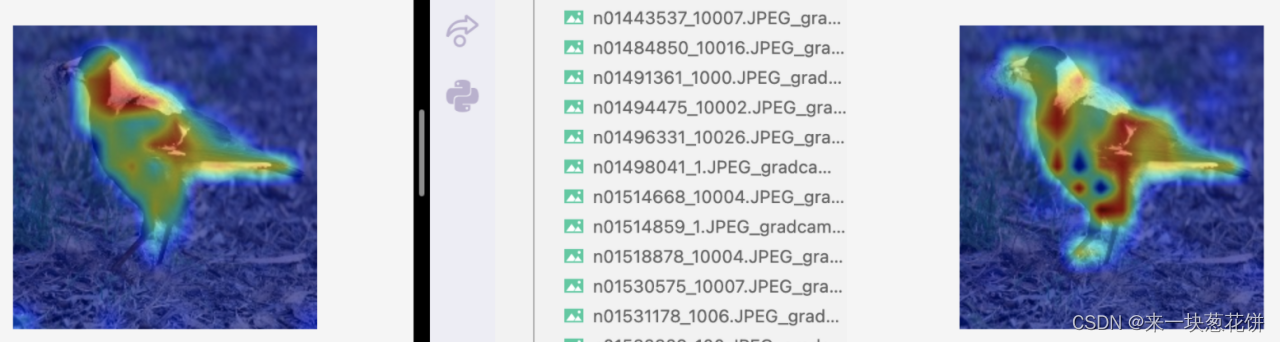
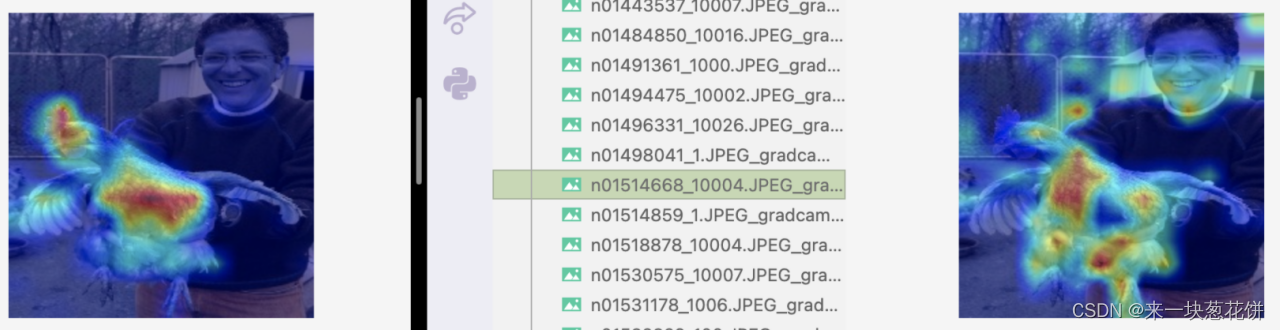
但是对于复杂场景,有遮挡的情况,selfsup会差一些
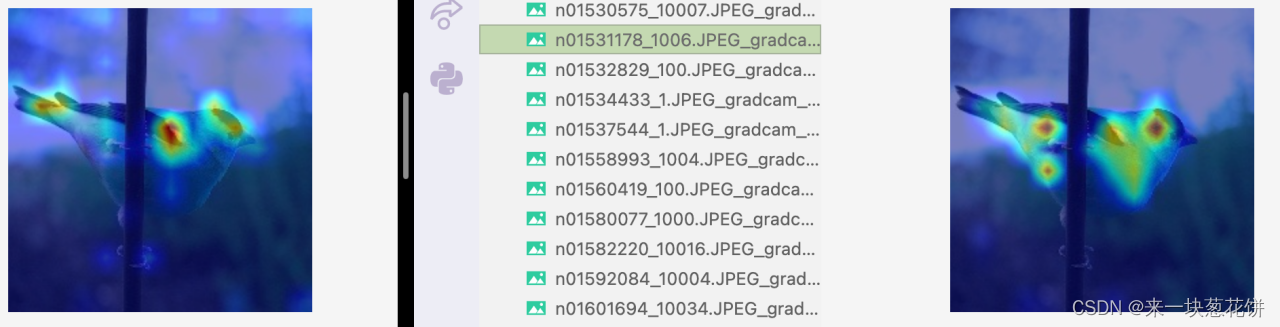
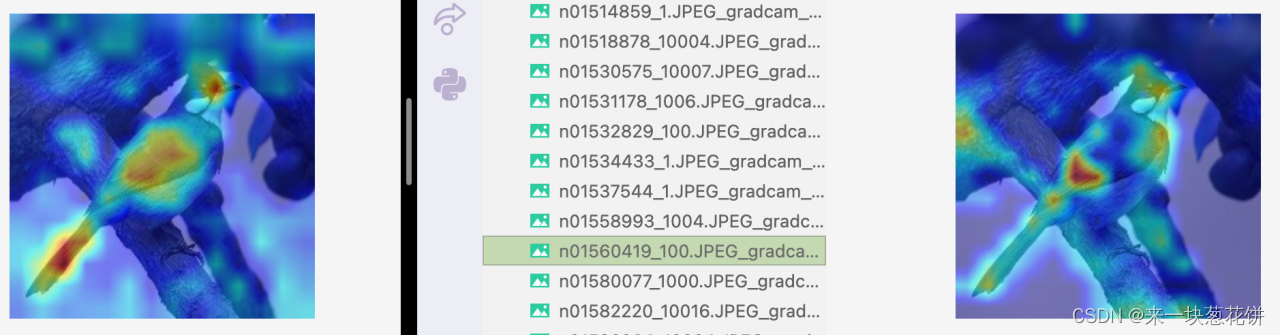
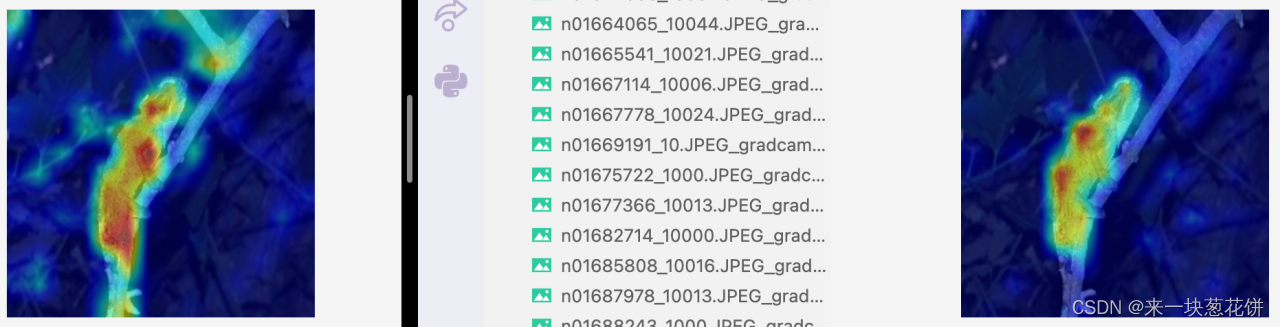
比如这张图,场景稍微复杂、包含树枝、光线较暗。
自监督的一些注意力容易关注到周围
但是从object(变色龙)的整体来看,自监督相比全监督,更好的关注到了object的整体
6.统计正确分类和错误分类的可视化
可视化把分类对的和分类错的都可视化一些,系统对比一下
对比的目的是,看看正确的是什么样子、错误的错在哪里。
这里使用推理后的结果(输出为每个类别的得分),先挑出错误分类的序号,然后按顺序找到正确分类的类别序号进行计算
大部分错分都是将类别分为临近的类,比如将一种鱼分为另一种鱼,而不至于将鱼分为鸡。少部分是关注到了object以外的部分,导致错分。很多正确的和错误的类别标号其实都很接近,imagenet中很多相连的类都是很接近的类别。
这也符合训练的策略,finetune采用Linear Evaluation,只更新最后的fc分类器的参数,而将前面的参数都冻。最后finetune只训练了90个epoch、并没有让loss收敛,所以fc肯定是没有完全训练好的。这也是为什么自监督比起全监督有更好的特征图、但是依旧错分的原因,因为fc没有训练收敛。

7.总结
总而言之,自监督能更好的关注到物体的整体,并且特征图能有更好的边界感,在绝大部份的图片上都有好的效果。在一些场景复杂、有遮挡的图片上,自监督会差一些。

