
- 1Python 天气 简单 数据分析及可视化_天气数据怎么进行泛化的
- 2ChatGLM-6B 在 ModelWhale和本地 平台的部署与微调教程_modelwhale chatglm
- 3Gradient Obfuscation Gives a False Sense of Security in Federated Learning 论文记录---数据生成
- 4微软&卡内基梅隆大学:无外部干预,GPT4等大语言模型难以自主探索
- 52023哈工大软件工程考研 | 395+251 | 个人经验分享
- 6Centos/Ubuntu离线部署清华chatGLM(特别详细,十分钟搞定)_清华大模型只能用ubuntu系统吗
- 7【论文阅读笔记】SAM-Adapter: Adapting Segment Anything in Underperformed Scenes
- 8RAG 全链路评测工具 —— Ragas_ragas算法
- 9NLP研究入门之道:走近NLP学术界_naacl审稿周期
- 10Gensim:TF-IDF_gensim tfidf
神奇的算法:HashMap(哈希映射)_hashmap算法
赞
踩
1.什么是HashMap?
HashMap,又称哈希映射或散列图。是一个用于储存键—值对(key-value)的集合,每个键—值对又称Entry,将这些Entry储存在一个数组里,这个数组就为HashMap。
一般初始的HashMap为空,如上图所示。
而HashMap最主要有两种方法:Put和Get方法。

2.HashMap的Put方法
Put方法就是将任意数据插入到HashMap中:
hashMap.put(“Mike”,0);
但是我们需要一个哈希函数来取得存入HashMap里的位置Index:
index = hash(“Mike”);
一般来说初建HashMap的时候默认长度为2的4次方幂,也就是hashMap.length=16。所以当越来越多的数据存进去的时候,难免会发生hash冲突,也就是index发生冲突:
这时候我们需要用上链表来解决这个问题,俗称拉链哈希。在这里,hashMap里的每一个元素不仅仅只有一个Entry,也可以存在多个Entry。当后面储存进来的数据的index与原有数据的index发生冲突时,使用“尾插法”创建链表,后来的Entry为链表的“头节点”,且通过next指向下一个Entry。
当然,也可以使用“头插法”来解决hash冲突,只不过实际应用中一般后来存储的数据使用频率相比于先前的数据要高,所以“尾插法”创建链表使用比较广泛。

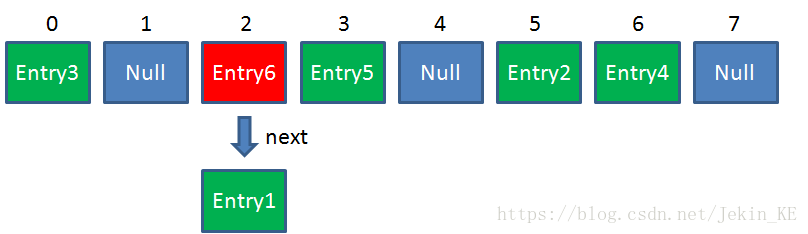
3.HashMap的Get方法
Get方法就是通过Key的值来查找hashMap里相对应的数据:
index = hash(“Mike”);
如果对应的index上有多个Entry,则顺着链表的顺序向下查找,直到找到相应的数据为止。
4.如何确定HashMap的index?
首先,我们需要知道hashMap的初始默认长度为16,可以通过手动或自动进行拓展hashMap的长度,并且Resize必须为2的次方幂。
为什么Resize必须为2的次方幂?
因为确定index需要用位运算的方法:
index = hashCode & (hashMap.length-1);
此时默认情况下 hashMap.length-1 = 15,二进制为1111,假设存入一个数据,计算其hashCode为26437,二进制为0110 0111 0011 0101,两者做与运算得出的二进制为0101,十进制为7,则index = 7。
假如Resize不为为2的次方幂,则 hashMap.length-1 得出的二进制数可能为0110,0001,0100等,此时如果和数据的hashCode值做与运算极易出现index冲突,即hashMap中某些元素为null,某些元素有多个Entry,这大大降低了hashMap的使用性能。
5.关于计算HashCode的方法
在上面我们提到确定HashMap的index时需要用到hashCode,那什么是hashCode?hashCode是根据数据对象的地址或者字符串或者数字算出来的int类型的数值。而对于数据对象中的每一个域a,我们需要通过其类型来计算对应的hashCode:
Ⅰ.如果为Boolean类型,则:a ? 0 : 1
Ⅱ.如果为char类型,则:( int ) a
Ⅲ.如果为Long类型,则:( int )(a^(a >>> 32))
Ⅳ.如果为Double类型,则先通过 double.doubleToLongBits( a ) 将其转换成long类型,再进行进一步转换。
具体计算方法可参照此处:
https://blog.csdn.net/lyx2007825/article/details/7846674
6.HashMap的容量扩展(Resize)
HashMap的容量是有限的。所以当数据不断的插入就会逐渐产生越来越多的hash冲突,这会降低hashMap的性能,所以我们需要对hashMap进行Resize操作。
在进行Resize操作时,我们需要了解两个决定hashMap实际长度的因素:
1.InitialCapacity(初始容量)
2.LoadFactor(负载因子)
其中InitialCapacity是定义给hashMap里数组的容量,默认设置为2的次方幂;LoadFactor表示一个散列表的空间的使用程度,LoadFactor越大则会降低空间开销,但提高查找成本。反之,LoadFactor越小则会对空间造成浪费。
为了在时间和空间中能够寻找一种平衡,设置初始大小时应当使LoadFactor处于0.5~1之间,考虑预计的Entry在Map及其负载系数。所以一般默认LoadFactor = 0.75f。
于是hashMap.Size的计算公式为:
HashMap.Size = InitialCapacity * LoadFactor
一旦hashMap需要Resize时,index就会出现改变,这时候不能盲目的往后扩容而不进行数据位置的更新,必须进行Rehash,也就是重新计算index并存入更新后的hashMap中。
7.HashMap的线程安全性
实际上,hashMap只有在单线程下是安全的。一旦处于高并发及多线程的情况下就会出现死锁的情况。
为什么会出现死锁的情况?先来看看Rehash的源代码:
void transfer(Entry[] newTable,boolean rehash){
int newCapacity = newTable.length;
for (Entry<K,V>e:table){
while (null != e){
Entry<K,V> next = e.next;
if(rehash){
e.hash = null == e.key ? 0:hash(e.key);
}
int i = indexFor(e.hash,newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
假设此时有线程A和线程B同时对一个含有链表hashMap进行rehash操作,这时候需要进行遍历hashMap;当线程B执行到 Entry<K,V> next = e.next; 这一步代码时会被挂起,此时线程A会一直执行rehash操作,完毕后将替换旧表并存入内存之中。
这时候重点来了!
此时线程B解挂,会继续执行rehash操作(按照旧表的结构进行rehash),但是此时线程A所构建的hashMap已经替换旧表。假若新的hashMap里元素中Entry只有一个则没有影响,关键是hashMap中存在链表的时候,旧表中链表为:Entry2->Entry1,线程A rehash之后链表结构为:Entry1->Entry2,但此时线程B按照旧表的结构进行rehash,当执行到 newTable[i] = e; e = next; 这两步时:
newTable[i] = Entry2
e = Entry1
Entry2.next = Entry1
Entry1.next = Entry2
出现了环形链表,也就是死锁。
8.HashMap在高并发下出现死锁的解决办法
Ⅰ.改用hashTable方法
在hashTable方法中,使用了synchronized关键字,这是JAVA中一个内置锁的加锁机制,此时在多线程的情况下,每一个线程在进行rehash操作的时候机会将整个hashMap进行加锁,直到该线程操作执行完毕才能解锁。
但是,如果整个hashMap很大并且在并发线程数量多的时候使用这个方法,就会大大降低性能。所以比较适合线程数量不多的情况下。
Ⅱ.改用ConcurrentHashMap方法
在用这个方法之前,需要了解一个概念:segment
实际上Segment是一个小型的HashMap ,其中也包含一个HashEntry数组。换而言之,ConcurrentHashMap是一个双层哈希表,ConcurrentHashMap里每一个Entry下也包含一个hashMap。之所以这样设计,优势主要在于: **让每个segment的读写是高度自治的,segment之间互不影响。这称之为“锁分段技术”;**相比于hashTable方法来说,并不需要将整个hashMap进行加锁,只需要将每个segment加锁,让多线程在进行Put操作的时候能够将锁的粒度保持地尽量地小,提高频率。
注:该文章图片均来源于公众号——程序员小灰(非本人公众号),感兴趣的可以关注一下!

