
热门标签
热门文章
- 1基于深度学习、机器学习,神经网络,OpenCV,图像处理,卷积神经网络计算机毕业设计题目大全_基于神经网络的毕设题目
- 2使用python计算RMSR、MRE和R方、MAE_python实现rmse
- 3关于QWidget里的Widget::paintEvent (QPaintEvent * event)显示图片的问题(即qpainter.drawPixmap)_widget中paintevent无效
- 420240326 每日AI必读资讯_gatekeep ai 网址
- 5微信小程序的N种页面跳转方式(2024最新)_微信小程序页面跳转
- 6YOLOv8-seg 分割代码详解(一)Predict
- 7MATLAB 线性拟合直线示例 + MATLAB线性拟合中文文档(决定系数R^2公式与解释 与 带惩罚项的修改R^2)_matlab拟合直线
- 8爬虫实战——中国天气网数据_爬取天气预报的目的
- 9paddleocr的基本使用_paddleocr zlibwapi.dll
- 10word2vec原理详解及实战_word2vec原理与实战详解(一)
当前位置: article > 正文
大语言模型构建本地知识库用于问答_llm+embedding构建问答系统
作者:我家自动化 | 2024-04-02 06:23:35
赞
踩
llm+embedding构建问答系统
一.知识库架构图
本文基于langchain+milvus+llm对原先的知识库进行重新构建,整体的架构如下:

二.实现步骤
1.首先对已有的FAQ以及相应的规章制度文档进行梳理;
2.对重复的问题和答案进行合并;
3.使用embedding模型对问题和答案进行embedding;
4.将FAQ文档embeding后插入到向量数据库milvus中;
5.对用户输入的问题进行embedding;
6.对问题的embedding在向量数据库milvus中进行相似搜索相似距离小于0.2且前3的答案;
7.使用LLM对返回的结果进行总结;
8.输出LLM总结后的结果作为输出返回给用户;
三.实现结果
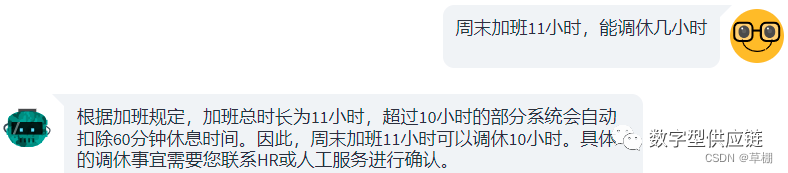
下面是使用m3e-base模型作为embedding模型,openai gpt3.5作为llm输出的结果:
原本的制度里面是:加班时长大于等于10小时,扣除60分钟的休息,加班时间在5-10小时,扣除30分钟的休息。
从结果可以看出llm能判别出11小时需要扣除60分钟的休息时间,且准确计算出调休10小时。
四.后续
后续我会对比llama,alpaca,chatglm等模型的效果;
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/351099
推荐阅读
相关标签

