
- 1教你如何使用esp8266接入华为云物联网平台(IOTDA)(Arduino IDE开发)
- 2渗透测试-木马免杀的几种方式_渗透免杀方法
- 3#33 mystrcpy_实现字符串的拷贝。 void my_strcpy(char * destination,char *
- 4C++:类的封装_c++类封装
- 5感知喜怒哀乐:用深度学习构建声音情感传感器
- 6服务器的负载均衡_负载均衡服务器
- 7蓝桥杯重点(C/C++)_蓝桥杯c++帮助文档
- 8Linux:入门篇
- 9写一个Python程序计算身体质量指数BMI_p106 实例代码5.2, 计算bmi
- 10leetcode:84. 柱状图中最大的矩形面积_leetcode 84
013:实战爬取三个翻译网站掌握Ajax表单提交_def fanyi(kw): }req = request(url,
赞
踩
本篇内容由易到难,涉及到ajax-form表单数据提交及md5解密
一共有三个翻译网络。我们要实现的是找到翻译的接口,打造我们自己的翻译软件。首先是
爬取百度翻译:
打开百度翻译,来获取我们的url

我们先确定我们的url:
经过尝试发现

数据跟随我们的输入同步更新

这个搜索框,是一个ajax请求的form表单

我们打开network
发现了如图几个(XHR)也就是Xml-HttpResponse
打开sug
发现sug最下面有一个formData。
里面的a就是我们在框中输入的a。为了确认我们再次更换搜索值。

这说明sug的url就是我们要找的url。

发现url为:https://fanyi.baidu.com/sug
确定好我们的url之后,开始构建我们的Request。
接口有了,我就直接发代码了。
from urllib import request,parse #导入urllib库
import json #导入json
def translateall(word): #定义一个名为翻译的函数
#模拟浏览器设置请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64)"
" AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/63.0.3239.132 Safari/537.36"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

#data里面的就是我们要传入的参数
data = { 'kw':word } data_str = parse.urlencode(data) #用parse把data转换拼接 url = 'https://fanyi.baidu.com/sug' req = request.Request(url = url , headers= headers, data = bytes(data_str,encoding='utf-8')) #构造请求体 response = request.urlopen(req).read().decode('utf-8') #请求页面信息 # print(response) obj = json.loads(response) #把json格式的解码出来 # print(obj) # print(obj['data']) for item in obj['data']: #然后截取我们所需的数据 item = item['k']+item['v'] print("------------------------------------------------------------------------------") print(item) if __name__ == '__main__': while True: word = input("请输入单词:") translateall(word)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23


这个案例很简单。接下来我们来爬取下金山词霸。
爬取金山词霸:
首先还是来确定我们要获取信息页面的url。
打开金山词霸网页。金山词霸跟百度翻译很类似。我长话短说。重点放在第三个项目上。好,
观察页面信息


打开network


接口url已经找到。
直接发代码吧,这个跟第一个相似度太高了。
第三个案例才是重点。
from urllib import request,parse import json class Translateall(): def __init__(self,word): self.word = word self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64)" " AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/63.0.3239.132 Safari/537.36" } self.data = { 'f': 'auto', 'a': 'auto', 'w': word } def translateall(self): data_str = parse.urlencode(self.data) url = 'http://fy.iciba.com/ajax.php?a=fy' req=request.Request(url =url,headers= self.headers,data= bytes(data_str,encoding='utf-8')) response = request.urlopen(req).read().decode('utf-8') obj = json.loads(response) if obj['status']==0: item = obj['content']['word_mean'] print(word,":",item) elif obj['status'] ==1: item = obj['content']['out'] print(word,":",item) else: return word def run(self): self.translateall() if __name__ == '__main__': while True: print("----------------欢迎使用金山词霸------------------") word = input("请输入单词:") trans=Translateall(word).run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
爬取有道词典:
爬取有道词典的难度算得上是很高了。
下面我来一步一步解析,如何获取我们想要的数据。
打开官网。

来找我们的接口。

发现了url:
我们要通过这个url去获取数据。


Formdata中有一大堆的数据。
通过不断的输入关键词,我们来观察formdata中不同的数据



对比发现,其中有三条数据是一直在改变的。
我们想要构造data,就必须要知道这三条是什么信息。
不要慌,找规律的时候不能着急。
分别把信息提取出来。

通过观察,是不是发现每列的ts和他的salt都很像。就短了一位。

然后每列的salt最前面的数字都是一样的。
根据经验来看,这很有可能是一个时间戳。我们打印一下当前时间。
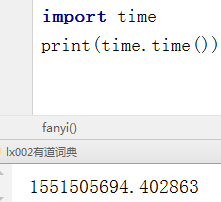
是不是很像啊

看来着就是一个更改过的时间戳了。
那我们的salt就是: salt = int(time.time() *10000)
而ts比salt少一位。
ts就是: ts= int(time.time() *1000)
还有一条数据需要我们解析。

首先来看这三个sign,除了长度一样外,看起来毫无任何关系。
我们lenth一下长度,发现都是32位的。
而这种类型的很像我们md5中的hash加密
so我们来试试。
构造一个hash函数。
下面编写我们的代码进行尝试:
from urllib import request,parse import hashlib,time,json def getMD5(value): aa = hashlib.md5() aa.update(bytes(value,encoding="utf-8")) sign = aa.hexdigest() return sign def fanyi(): salt = int(time.time() *10000) ts = int(time.time() * 1000) value = "fanyideskweb" + word + str(salt) + "p09@Bn{h02_BIEe]$P^nG" url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' data= { "i":word, "from":"AUTO", "to":"AUTO", "smartresult":"dict", "client":"fanyideskweb", "salt":salt, "sign":getMD5(value), "ts":ts, "bv":"5933be86204903bb334bf023bf3eb5ed", "doctype":"json", "version":"2.1", "keyfrom":"fanyi.web", "action":"FY_BY_REALTIME", "typoResult":"false" } data_str = parse.urlencode(data) headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', # "Accept - Encoding":"gzip, deflate, br", 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Length': len(data_str), 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'OUTFOX_SEARCH_USER_ID=42474381@10.168.1.241; JSESSIONID=aaawRmNTElH3Q4_wUlzKw; OUTFOX_SEARCH_USER_ID_NCOO=1959109122.590772; ___rl__test__cookies=1550905970008', 'Host': 'fanyi.youdao.com', 'Origin': 'http://fanyi.youdao.com', 'Referer': 'http://fanyi.youdao.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest' } req = request.Request(url=url,data=bytes(data_str,encoding='utf-8'),headers=headers) content = request.urlopen(req).read().decode('utf-8') content = json.loads(content) try: sss = content["translateResult"][0][0] ddd = content["smartResult"]["entries"] print(' ',sss["src"],":",sss["tgt"]) # print(' ',str(ddd).replace('\\r\\n','…').replace("\''",'')) for i in ddd: print(' ',i) except Exception as e: print(word) print() if __name__ == '__main__': while True: print("--------------------欢迎使用有道词典------------------") word = input("请输入单词:") fanyi()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
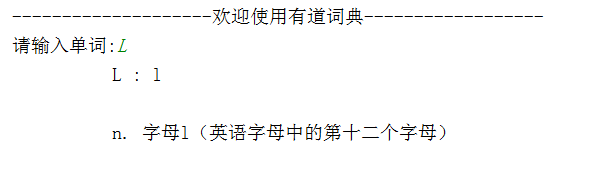
ok了

