
- 1Pycharm配置Copilot一直waiting for github authentication_pycharm copilot一直等待链接
- 2陕西师《c语言程序设计》作业,南开19秋学期(1709、1803、1809、1903、1909)《C语言程序设计》在线作业【满分答案】...
- 3CentOS 7离线安装Keepalived_centos离线安装keepalive
- 4基础篇:Linux 常用命令总结_vv linux
- 5MAC如何安装多版本jdk(以8,17为例)_mac 下载jdk17 多版本
- 6基于轻量级YOLOv5模型开发构建鸟巢检测识别分析系统_yolov5鸟巢
- 7Mastering the JSFL: 利用JSFL进行批处理操作(批量发布,交换元件,修改AS代码等等)_an jsfl
- 8Python3 基础语法:字符串(String)_python3 string
- 9canvas基础
- 10Azure mysql内网_用Azure VM + Azure Database for MySQL搭建Web服务
动手学强化学习-Actor-Critic算法_self.actor(states).gather(1, actions)
赞
踩
先说说REINFORCE算法的局限性:由于采用蒙特卡洛方法进行估计,REINFORCE算法的梯度估计的方差很大,可能会造成一定程度上的不稳定,同时蒙特卡洛采样法需要在序列结束后进行更新,这同时也要求任务具有有限的步数。
而Actor-Critic算法就是考虑拟合一个值函数替代蒙特卡洛方法来指导策略进行学习,在策略梯度中,可以把梯度写成下面这个更加一般的形式: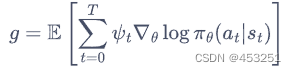
其中,![]() 我们使用时序差分残差
我们使用时序差分残差![]() 来知道策略梯度进行更新
来知道策略梯度进行更新
我们将Actor-Critic分为两个部分:Actor(策略网络)和Critic(价值网络):
①Actor要做的是与环境交互,并在Critic价值函数的指导下最大化目标,而时序差分残差是由时序差分目标和价值函数相减得到,而我们知道时序差分目标是用来估计当前状态价值的,而时序差分目标同时也可以用于估计Q值,价值函数就是Critic网络的输出值,是一个价值函数,所以时序差分残差在一定意义上可以理解成优势函数A,而Actor要做的就是最大化优势函数A,而我们知道优势函数A他是Critic网络输出的一个函数,所以,这才有了Actor网络是在Critic的指导下进行优化。
②Critic要做的就是与环境交互收集的数据学习一个价值函数,这个价值函数会判断当前状态什么动作是好的,什么动作是不好的,进而帮助Actor进行策略更新,他要优化的就是价值函数估计的准确性。
理解了两个网络之后,两个网络的更新方式也就显而易见了,Actor网络需要最大化目标,所以要加上负号,而Critic网络需要保证预测的准确性,所以需要最小化均方误差损失函数。
我们采用车杆环境来进行试验
导入库
- import gym
- import torch
- import torch.nn.functional as F
- import numpy as np
- import matplotlib.pyplot as plt
- import rl_utils
首先定义策略网络PolicyNet,这与REINFORCE算法相同
- class PolicyNet(torch.nn.Module):
- def __init__(self,state_dim,hidden_dim,action_dim):
- super(PolicyNet,self).__init__()
- self.fc1=torch.nn.Linear(state_dim,hidden_dim)
- self.fc2=torch.nn.Linear(hidden_dim,action_dim)
-
- def forward(self,x):
- x=F.relu(self.fc1(x))
- return F.softmax(self.fc2(x),dim=1)
接下来定义价值网络ValueNet,其输入是某个状态,输出则是状态的价值
- class ValueNet(torch.nn.Module):
- def __init__(self,state_dim,hidden_dim):
- super(ValueNet,self).__init__()
- self.fc1=torch.nn.Linear(state_dim,hidden_dim)
- #价值网络用来判定当前状态这个动作的好坏,所以显然输入是状态,输出层为1层,输出价值
- self.fc2=torch.nn.Linear(hidden_dim,1)
-
- def forward(self,x):
- x=F.relu(self.fc1(x))
- return self.fc2(x)
下面定义Actor-Critic算法
- class ActorCritic:
- def __init__(self,state_dim,hidden_dim,action_dim,actor_lr,critic_lr,gamma,device):
- #策略网络
- self.actor=PolicyNet(state_dim,hidden_dim,action_dim).to(device)
- #价值网络
- self.critic=ValueNet(state_dim,hidden_dim).to(device)
- #策略网络优化器
- self.actor_optimizer=torch.optim.Adam(self.actor.parameters(),lr=actor_lr)
- #价值网络优化器
- self.critic_optimizer=torch.optim.Adam(self.critic.parameters(),lr=critic_lr)
- self.gamma=gamma
- self.device=device
-
- def take_action(self,state):
- state=torch.tensor([state],dtype=torch.float).to(self.device)
- probs=self.actor(state)
- action_dist=torch.distributions.Categorical(probs)
- action=action_dist.sample()
- return action.item()
-
- def update(self,transition_dict):
- states=torch.tensor(transition_dict['states'],dtype=torch.float).to(self.device)
- actions=torch.tensor(transition_dict['actions']).view(-1,1).to(self.device)
- rewards=torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1,1).to(self.device)
- next_states=torch.tensor(transition_dict['next_states'],dtype=torch.float).to(self.device)
- dones=torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1,1).to(self.device)
-
- #时序差分目标,他用来估计Q(s,a)
- td_target=rewards+self.gamma*self.critic(next_states)*(1-dones)
- #self.critic(states)用来估计V(s)
- #所以时序差分误差实际上是优势A
- td_delta=td_target-self.critic(states) #时序差分误差
- #动作概率分布的对数
- log_probs=torch.log(self.actor(states).gather(1,actions))
- #策略梯度,即动作损失函数
- #detach()是一个函数,它的作用是创建一个新的张量,其中的值与原始张量相同,但不会计算梯度,即分离梯度
- #在这种情况下,detach()函数被用来分离td_delta张量的计算图,以便在计算损失时不对其进行梯度计算,也就是求偏导时不考虑他
- #策略网络的损失函数只与策略网络的输出以及动作的选择有关,与判定动作好坏的值函数是无关的,因此我们需要分离值函数的梯度
- #而这里的两个变量td_delta以及td_target都是关于值函数的变量,所以我们需要将其分离
- #确保价值网络的更新不会影响策略网络的更新
- #我们需要深刻理解一下价值网络是如何帮助策略网络进行动作好坏的判断的
- #其实这里,优势A是价值网络输出的函数,而策略网络是在最大化优势A,这就是价值网络对策略网络的影响
- #也就是价值网络让策略网络最大化优势A也就是最大化每个动作的回报,但是他本身并不影响策略(也就是动作的选取)
- #所以价值网络不能影响策略网络的参数更新,所以有关价值网络输出的两个变量都需要进行分离
- actor_loss=torch.mean(-log_probs*td_delta.detach())
- #均方差误差损失函数
- #同样需要看神经网络的作用,策略网络希望最大化优势A,所以损失函数需要加负号
- #而价值网络希望输出的价值更加精确,即最小化损失函数,所以不需要加负号
- critic_loss=torch.mean(F.mse_loss(self.critic(states),td_target.detach()))
- self.actor_optimizer.zero_grad()
- self.critic_optimizer.zero_grad()
- actor_loss.backward() #计算策略网络的梯度
- critic_loss.backward() #计算价值网络的梯度
- self.actor_optimizer.step() #更新策略网络的参数
- self.critic_optimizer.step() #更新价值网络的参数

设置超参数,开始试验
- actor_lr = 1e-3
- critic_lr = 1e-2
- num_episodes = 1000
- hidden_dim = 128
- gamma = 0.98
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
- "cpu")
-
- env_name = 'CartPole-v0'
- env = gym.make(env_name)
- env.seed(0)
- torch.manual_seed(0)
- state_dim = env.observation_space.shape[0]
- action_dim = env.action_space.n
- agent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
- gamma, device)
-
- return_list = rl_utils.train_on_policy_agent(env, agent, num_episodes) #rl_utils是动手学强化学习自带的库,里面包含了对在线策略,离线策略,经验回放池,优势函数估计等的封装

绘图
- episodes_list = list(range(len(return_list)))
- plt.plot(episodes_list, return_list)
- plt.xlabel('Episodes')
- plt.ylabel('Returns')
- plt.title('Actor-Critic on {}'.format(env_name))
- plt.show()
-
- mv_return = rl_utils.moving_average(return_list, 9)
- plt.plot(episodes_list, mv_return)
- plt.xlabel('Episodes')
- plt.ylabel('Returns')
- plt.title('Actor-Critic on {}'.format(env_name))
- plt.show()
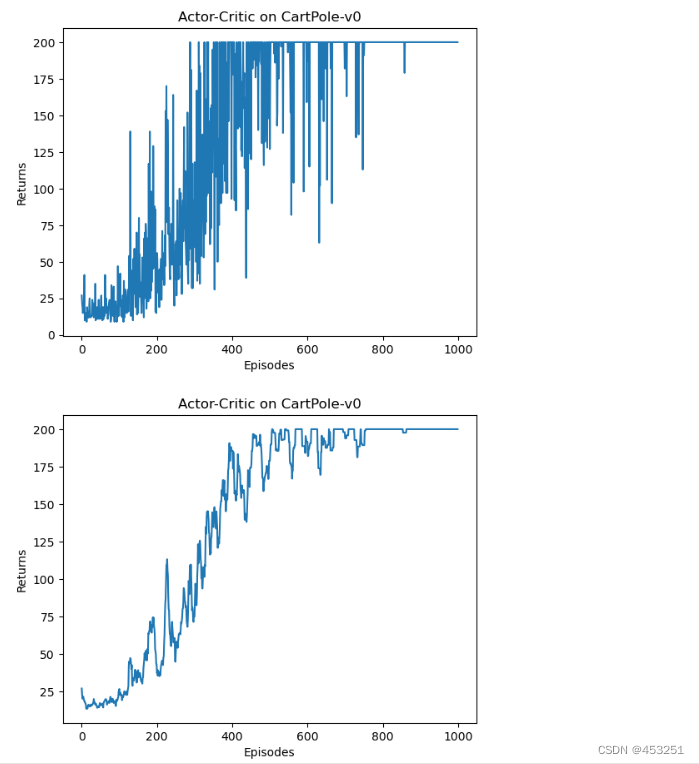
根据实验结果我们可以发现,Actor-Critic 算法很快便能收敛到最优策略,并且训练过程非常稳定,抖动情况相比 REINFORCE 算法有了明显的改进,这说明价值函数的引入减小了方差。

