
- 1基于Django机器学习算法房源可视化分析推荐系统的设计与实现(完整系统源码+数据库+详细文档+论文+部署教程)_django商品房数据分析论文
- 2clickhouse hbase性能对比_携程ClickHouse日志分析实践
- 3MySQL卸载与安装_mysqld uninstall
- 4Flink Checkpoint 机制深度解析:原理、注意事项与最佳实践
- 5突破编程_C++_网络编程(TCPIP 四层模型(传输层))
- 6冰蝎(Behinder)下载与安装以及连接测试_冰蝎下载
- 7ERNIE 3.0知识增强大模型_erniebot 论文
- 8计算机网络技术-Mooc_( )、( )、( )是osi协议的基础层次。
- 92023级学姐上岸瓜大网安及心态篇_东南网安916
- 10Azure AI 新发布了 9 种更逼真的对话 AI 声音
机器学习实战教程(二):线性回归_线性回归实战 这是一个关于初创企业的小数据集,由51行和5列组成。我们的目标是根
赞
踩
1.线性回归简介
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w’x+e,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
1.1 正态分布
正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution),最早由A.棣莫弗在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
以下两图来自网络 对于正态分布的理解更加简单:
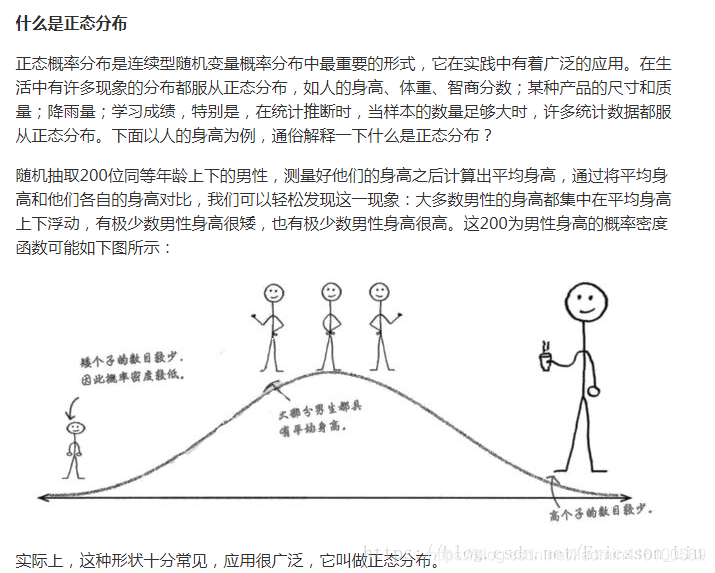


高斯函数是一种常见的概率密度函数,也被称为正态分布函数。具体地说,高斯函数描述了随机变量在某个区间内取值的概率密度,其形式为:
f
(
x
)
=
1
2
π
σ
2
e
−
(
x
−
μ
)
2
2
σ
2
f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}
f(x)=2πσ2
1e−2σ2(x−μ)2
其中,
μ 是均值,σ 是标准差。这个函数的图像呈钟形,且左右对称,最高点位于均值处,随着距离均值越远,函数值逐渐减小。
概率密度函数是用来描述随机变量分布情况的函数,而高斯函数是其中的一种形式。当随机变量服从正态分布时,其概率密度函数就是高斯函数。因此,可以将高斯函数看作是概率密度函数的一种特殊形式。
1.2 Linear Regression线性回归
它是最为人熟知的建模技术之一。线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。
线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
多元线性回归可表示为Y=a+b1X +b2X2+ e,其中a表示截距,b表示直线的斜率,e是误差项。多元线性回归可以根据给定的预测变量(s)来预测目标变量的值。
1.2.1 一元线程回归(简单线性回归)
在统计学中,线性回归是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。一个带有一个自变量的线性回归方程代表一条直线。我们需要对线性回归结果进行统计分析
回归线其实可以理解为一条直线,数学表示方式为:
Y=b0 + b1X+e
在统计学中,假设有一系列的自变量和因变量的统计数据,可以推算出最佳拟合的b0和b1
- Y - 表示因变量;
- X - 表示独立变量;
- b0 - 回归线的截距;
- b1 - 回归线的斜率 参考;
- e - 误差,预测值和真实值之间的误差;
假设我们将数据 (x1, y1),(x2, y2),(x3, y3)…….(xn, yn)的 n 个点拟合到上面的回归线上。

其中,ei 是第 i 个观测值与我们回归线预测值之间的差值。
比如 函数 y=3x+5 假设统计数据存在 (5,19),(1,9)。
其中b1=3就是斜率, b0=5就是截距, (5,19)就是第1个值 x1=5 y1=19。
如果明确了函数,当x1=5时 预测的值=3*5+5=20 。
ei=20-19=1 误差为1。
在线性回归中, 我们只有统计数据 下面蓝色的点即为统计数据。
我们需要通过这些蓝色的统计数据 计算出一条最佳的拟合线,计算出截距和斜率。

一般计算就是通过将所有数据的误差平方求和求的最小值也就是最佳的拟合方程

我们如何最小化平方误差总和(SSE)呢?
请记住,b1 和 b0 对我们来说仍然是未知的。
在最小二乘法中,我们通过选择 b1 和 b0 的值来最小化平方误差总和(SSE),如下:

最小二乘法最容易理解解释(https://www.matongxue.com/madocs/818.html)
关于最小二分法需要掌握数学中,导数,极限,偏导概念才能实现推导出该公式
一定要弄明白,请移步梯度下降法解决线性回归问题 :
https://blog.csdn.net/liaomin416100569/article/details/84644283
2.线性回归实践
这里因为懒于自己封装这些公式,使用sklearn已经实现的api来实现
2.1 sklearn数据集介绍
sklearn 的数据集有好多种
- 自带的小数据集(packaged dataset):sklearn.datasets.load_
- 可在线下载的数据集(Downloaded Dataset):sklearn.datasets.fetch_
- 计算机生成的数据集(Generated Dataset):sklearn.datasets.make_
- svmlight/libsvm格式的数据集:sklearn.datasets.load_svmlight_file(…)
- 从买了data.org在线下载获取的数据集:sklearn.datasets.fetch_mldata(…)
自带的小数据集(packageddataset):sklearn.datasets.load_
- 鸢尾花数据集:load_iris():用于分类任务的数据集
- 手写数字数据集:load_digits():用于分类任务或者降维任务的数据集
- 乳腺癌数据集load-barest-cancer():简单经典的用于二分类任务的数据集
- 糖尿病数据集:load-diabetes():经典的用于回归认为的数据集,值得注意的是,这10个特征中的每个特征都 已经被处理成0均值,方差归一化的特征值。
- 波士顿房价数据集:load-boston():经典的用于回归任务的数据集
- 体能训练数据集:load-linnerud():经典的用于多变量回归任务的数据集。
2.2 简单线性回归
这里使用sklearn中提供的波士顿房价 ,房价和房间数量的关系来演示简单线性回归,明显房间数量越多,面积越大,自然房价越高,成正向线性关系。
2.2.1 加载数据集
波士顿房价数据集特征介绍

编程加载数据处理
import numpy as np; import matplotlib.pyplot as plot; import sklearn.linear_model as lm; import sklearn.datasets as ds; import sklearn.model_selection as ms; """ 返回一个json数据(结构) data表示房价数据 target feature_names 表示每个列的字段名称 DESCR 是描述信息 filename:存储的数据文件的位置 关于该数据所有字段: CRIM:城镇人均犯罪率。 ZN:住宅用地超过 25000 sq.ft. 的比例。 INDUS:城镇非零售商用土地的比例。 CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0) NOX:一氧化氮浓度。 RM:住宅平均房间数。 AGE:1940 年之前建成的自用房屋比例。 DIS:到波士顿五个中心区域的加权距离。 RAD:辐射性公路的接近指数。 TAX:每 10000 美元的全值财产税率。 PTRATIO:城镇师生比例。 B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。 LSTAT:人口中地位低下者的比例。 MEDV:自住房的平均房价,以千美元计。 target是房价 以千美元计 """ bd=ds.load_boston(); #获取波士顿房价的所有特征数据 data=bd.data; #获取每行特征对应的房价 label=bd.target; #为了演示简单线性回归 获取一个特征 #RM:住宅平均房间数。 nox=data[: ,5:6] #将数据拆分成80%的训练数据 20%的测试数据 xtrain,xtest,ytrain,ytest=ms.train_test_split(nox,label,test_size=0.2,random_state=10) #将 [[4],[2]]这样的特征矩阵转换成 [4,2]这样的向量 绘制散点图 plot.scatter(xtrain[:,-1],ytrain,c="red") plot.show();

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
图像效果:

2,2.2使用线程回归计算系数和截距
使用sklearn的LinearRegression类实现机器训练和预测
#创建线程回归的类
lr=lm.LinearRegression();
lr.fit(xtrain,ytrain);
#系数也就是斜率
print(lr.coef_)
#截距
print(lr.intercept_)
plot.scatter(xtrain[:,-1],ytrain,c="red")
#绘制 80%的真实数据
plot.plot(xtrain[:,-1],xtrain[:,-1]*lr.coef_+lr.intercept_);
plot.show();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
得到的散点图和线性方程图下:

注意这里离线较远的点对数据的影响较大 可以选择过滤掉这些 y>50以上的数据
xtrain=xtrain[ytrain<50]
ytrain=ytrain[ytrain<50]
- 1
- 2
得到图像

2.3 多元线性回归
上面的简单线性回归仅仅是对房间数量一个特征做了预测其实房价本身是由多个因素引起的
多元线性回归模型的一般形式为
Yi=β0+β1X1i+β2X2i+…+βkXki+μi i=1,2,…,n
多元线性回归就是求出这个i个系数 β0是截距
编程实现
import numpy as np; import matplotlib.pyplot as plot; import sklearn.linear_model as lm; import sklearn.datasets as ds; import sklearn.model_selection as ms; bd=ds.load_boston(); #获取波士顿房价的所有特征数据 data=bd.data; #获取每行特征对应的房价 label=bd.target; #将数据拆分成80%的训练数据 20%的测试数据 xtrain,xtest,ytrain,ytest=ms.train_test_split(data,label,test_size=0.2,random_state=10) xtrain=xtrain[ytrain<50] ytrain=ytrain[ytrain<50] lr=lm.LinearRegression(); lr.fit(xtrain,ytrain); np.set_printoptions(suppress=True) #不使用科学计数法 #系数也就是斜率 print("所有的系数:"); print(lr.coef_) #截距 print(lr.intercept_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.3.1 关于系数的可解释性
执行上面的结果得到系数是:
[ -0.12246473 0.04796854 -0.05495153 0.3323236 -11.35521528
3.0899128 -0.00873784 -1.19747097 0.24873896 -0.0129233
-0.72951934 0.0096858 -0.41518496]
- 1
- 2
- 3
对这些系数进行排序
[ 4 7 10 12 0 2 9 6 11 1 8 3 5]
- 1
第4个特征是 [NOX:一氧化氮浓度。] 是 -11 是负向关系也就是说 NOX越大 房价也就会越低
第5个特征是 [ RM:住宅平均房间数。 ] 是3.08 是正向关系也就是说平均房间数越大 房价也就会越高

