
- 1从入门到精通,鸿蒙(HarmonyOS)正确的学习路线_鸿蒙学习
- 2ubuntu20.04搭建lamp环境 +制作网页_ubuntu20.04服务器搭建自己的个人网站
- 3web布局——说清楚fixed布局
- 4数据结构-算法的空间复杂度(1.2)_long long fib(int n)
- 5Android studio Failed to load JVM DLL_android studio failed to download jdk
- 6推特社交机器人分类
- 7U3D光源烘培光照贴图和light probes_lmuv
- 8StackLayout布局_stacklayout 布局
- 9基于CNN意图识别_识别客户意图 神经网络
- 10语言模型在知识图谱与问答系统中的应用
【深度学习】【NLP】如何得到一个分词器,如何训练自定义分词器:从基础到实践_如何训练分词器
赞
踩
在自然语言处理(NLP)领域,分词是一个重要的预处理步骤,它将文本切分成有意义的子词或标记。合适的分词工具可以对NLP任务产生深远的影响,而如何训练一个自定义分词器也是一个关键的课题。本篇博客将引导您了解不同分词算法,深入探讨分词工具的原理,然后演示如何使用Python代码训练自己的分词器。
什么是分词?
分词是将文本划分为更小的单元,如单词、子词或标记的过程。在中文分词中,这些单元通常是词汇,而在英文中,可以是单词或子词。分词是NLP的基础,它对文本的理解和处理具有关键作用。
分词算法
在NLP中,有多种分词算法可供选择。以下是一些常见的分词算法,这些分词算法各有其优势,取决于具体的应用场景和需求。以下是它们的一些特点:
-
BPE(Byte-Pair Encoding):
- 优势:BPE是一种无监督算法,能够适用于多种语言,包括中文和英文。它基于字符级别的处理,对于分词的划分灵活性较高,适用于不同领域的文本。
- 中英文混合分词:BPE可以用于中英文混合分词,但需要适当调整参数和词表来满足中文语言的需求。
-
WordPiece:
- 优势:WordPiece是一种基于BPE的算法,它在选择字符对合并时考虑标记的可能性。这使得它在处理NLP任务时表现更好,如机器翻译和文本生成。对于英文和中文等多语言情境,WordPiece通常具有很好的性能。
- 中英文混合分词:WordPiece同样适合中英文混合分词,而且在考虑标记的可能性时,能更好地处理多语言文本。
-
Unigram:
- 优势:Unigram采用概率模型来选择标记,这使得它能够生成带概率的多个子词分段。这对于语言生成任务或需要模糊匹配的场景可能有益。
- 中英文混合分词:Unigram同样可以用于中英文混合分词,但需要注意参数设置和模型训练。
-
SentencePiece:
- 优势:SentencePiece结合了BPE和Unigram的优点,可以从原始文本开始训练分词模型,适用于多种语言。它非常灵活,适用于多样化的文本处理需求,包括中英文。
- 中英文混合分词:SentencePiece同样适合中英文混合分词,并且容易进行多语言训练。
关于哪个更适合中英文一起的分词,选择取决于具体情况。WordPiece和SentencePiece通常被认为对于多语言处理更强大,因为它们考虑到了标记的可能性,这对于处理多语言文本的一致性和性能提升有好处。 Unigram和BPE也可以用于中英文混合分词,但可能需要更多的调整和参数设置来满足特定需求。最终的选择应基于实际需求和性能测试。
使用Python训练分词器
以下是使用Python训练自定义分词器的步骤:
步骤1:选择分词算法
首先,选择适合您需求的分词算法。如果需要针对特定语料库或任务训练分词器,可以考虑使用SentencePiece来灵活满足需求。
步骤2:准备训练语料
收集和准备训练语料,这是训练自定义分词器的基础。语料库的大小和质量将影响分词器的性能。
步骤3:配置分词器参数
针对所选的分词算法,配置参数,如词表大小、字符覆盖率等。这些参数的选择应根据语料和任务的特点来确定。
步骤4:训练分词器
使用选择的分词算法和参数,训练自定义分词器。这通常涉及编写Python代码来调用分词库的API,并传递训练语料。
步骤5:测试和使用分词器
训练完成后,测试分词器的性能,确保它能够有效切分文本。然后,您可以将训练好的分词器用于NLP任务,如文本分类、情感分析等。
代码示例:使用SentencePiece训练分词器
下面是一个使用SentencePiece库来训练分词器的Python代码示例:
import sentencepiece as spm
# 训练SentencePiece模型
spm.SentencePieceTrainer.train(
input='corpus.txt', # 输入文件
model_prefix='custom_tokenizer', # 模型前缀
vocab_size=5000, # 词汇表大小
model_type='unigram', # 模型类型
# 其他参数...
)
# 加载训练好的模型
sp = spm.SentencePieceProcessor()
sp.load('custom_tokenizer.model')
# 使用分词器
text = "这是一个示例句子"
tokens = sp.encode_as_pieces(text)
print(tokens)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在训练一个分词器时,下面是一些重要的参数,其中一些参数对模型的性能和行为产生显著影响:
-
model_type:模型类型,可以选择BPE、char、word、unigram。这决定了分词器使用哪种分词算法。不同类型适用于不同的任务和文本类型。
-
vocab_size:词汇表大小,这个参数决定了词表中包含多少标记。太小的词汇表可能导致词汇覆盖不足,而太大的词汇表可能会增加训练时间。
-
character_coverage:指定模型中覆盖的字符数,通常设置为一个小数,如0.9995。这可以帮助控制词汇表的大小。
-
max_sentence_length:最大句子长度,决定了句子在分词时的最大长度。过长的句子可能需要截断或拆分。
-
num_threads:进程个数,控制训练时的并行度,影响训练速度。
-
unk_id、bos_id、eos_id、pad_id:这些参数定义了特殊标记的ID。例如,unk_id表示未知标记的ID,bos_id表示句子的开头,eos_id表示句子的结尾,pad_id表示填充标记。
-
split_by_unicode_script、split_by_number、split_by_whitespace、split_digits:这些参数用于控制在哪些情况下进行拆分,例如,是否在不同的字符脚本之间、数字之间、空格之间、数字和字母之间拆分。
-
use_all_vocab:是否使用所有词汇。设置为0时,只使用出现频率高的标记。
这些参数是分词器训练中的关键配置,它们直接影响模型的性能和行为。根据具体任务和语料库,你需要谨慎选择和调整这些参数以获得最佳的分词效果。不同的参数设置可能适用于不同的应用场景,因此需要根据需求进行实验和调整。
这段代码演示了如何使用SentencePiece来训练一个自定义分词器,加载模型,并将其应用于文本。
HuggingFace的Tokenizers也实现了分词算法,具体使用可以参考如下:
from tokenizers import (ByteLevelBPETokenizer,
BPETokenizer,
SentencePieceBPETokenizer,
BertWordPieceTokenizer)
tokenizer = SentencePieceBPETokenizer()
tokenizer.train(["../blog_test.txt"], vocab_size=500, min_frequency=2)
output = tokenizer.encode("This is a test")
print(output.tokens)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分词算法的训练要素,如何训练好
在训练大模型分词器时,有几个关键因素需要考虑,这些因素可以总结如下:
-
词表大小设置:词表大小应该与语料库的大小匹配。具体的设置可以参考一些大型模型,如ChatGPT和Chinese-LLaMA模型,它们通常采用词表大小在5万到13万之间。合理的词表大小直接影响了模型参数数量和训练速度。较大的词表可能需要更多的资源来训练和部署,但能够更好地覆盖不同领域和语言的内容。
-
语料库的充实性:语料库的质量和数量对分词器的性能至关重要。使用丰富和多样化的语料库可以更好地适应各种领域和专业术语,以产生更符合通用语义的切分结果。特别是在垂直领域或特殊领域的应用中,充足的领域特定语料库对于保持高质量的分词结果非常重要。
-
词汇量大小的平衡:选择词汇表的大小需要在模型质量和效率之间取得平衡。较大的词汇表可以提高模型的语言表示能力,但也会增加模型的参数量。在拥有足够计算资源和充足语料库的情况下,可以考虑使用较大的词汇表以提高模型的性能。
合并分词表
由transformers库的教程https://transformers.run/intro/2021-12-11-transformers-note-2/也可以得知:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenizer.save_pretrained("./models/bert-base-cased/")
- 1
- 2
- 3
调用 Tokenizer.save_pretrained() 函数会在保存路径下创建三个文件:
special_tokens_map.json:映射文件,里面包含 unknown token 等特殊字符的映射关系;
tokenizer_config.json:分词器配置文件,存储构建分词器需要的参数;
vocab.txt:词表,一行一个 token,行号就是对应的 token ID(从 0 开始)。
博客https://blog.51cto.com/u_16116809/6321388提到一个tips:LLaMA模型预训练中文语料特别少,可以把中文学到的vocab.txt分词表加入到原有的里面,我理解,special_tokens_map.json是通用的,tokenizer_config.json里面写的一些分词算法配置如果中英文一样也就无所谓,所以就能合并vocab.txt分词表。
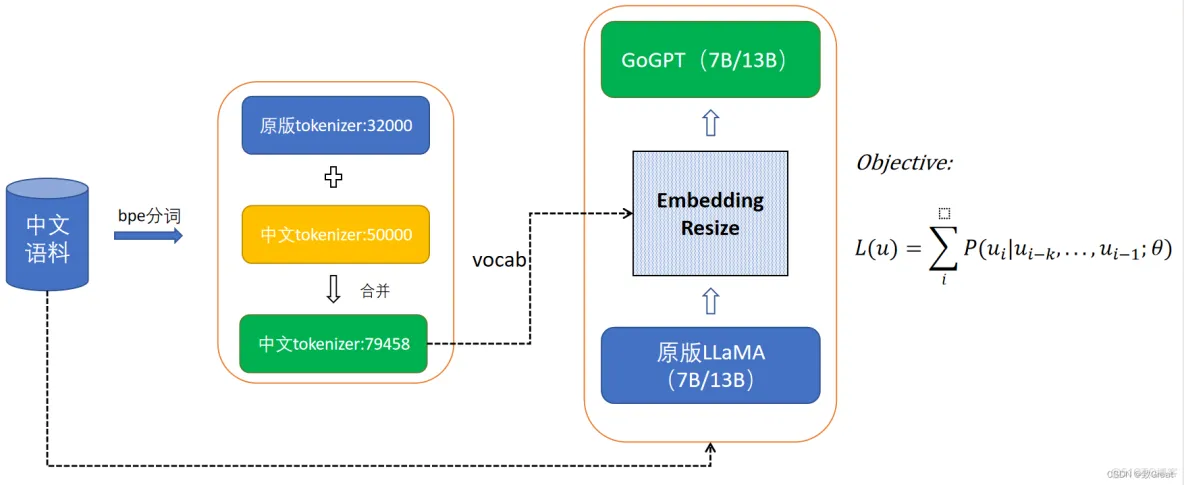
baichuan-7B 的分词
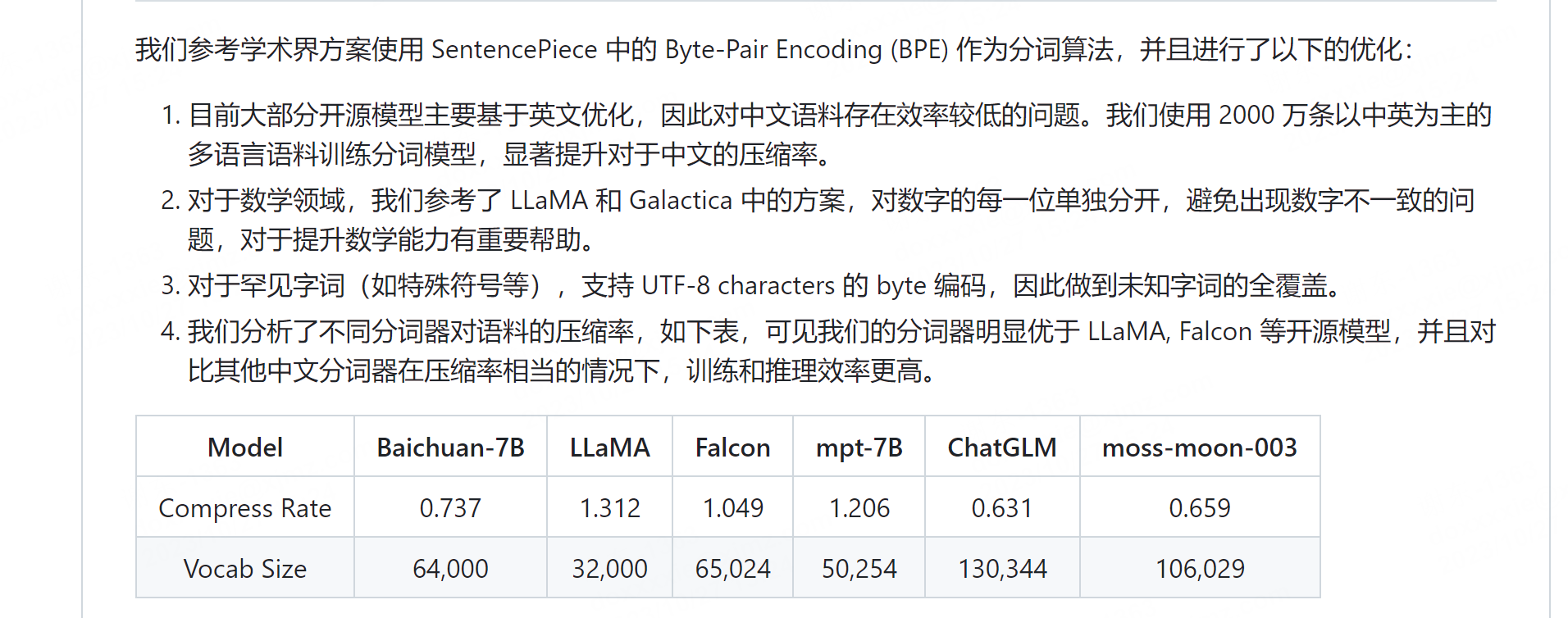
看得出来,针对不同领域,分词算法也是一个研究点,baichuan-7B看起来还是挺厉害的:
https://github.com/baichuan-inc/baichuan-7B#%E5%88%86%E8%AF%8D
通义千问
https://modelscope.cn/organization/qwen
https://huggingface.co/Qwen/Qwen-7B-Chat
智谱
https://github.com/THUDM/ChatGLM2-6B
参考:
https://blog.51cto.com/u_16116809/6321388
https://github.com/yanqiangmiffy/how-to-train-tokenizer
https://github.com/baichuan-inc/baichuan-7B#%E5%88%86%E8%AF%8D

