
热门标签
热门文章
- 13.1、决策树算法_决策树算法连续变量坐标 (1.4) (1.6) (3.1) (3.8 (6.6) (7.2) (7.
- 2代码随想录笔记|C++数据结构与算法学习笔记-二叉树(二)|二叉树层序遍历、226.翻转二叉树
- 3ubuntu16.04使用全记录_bantu更新软件
- 4华三 h3c STP生成树保护配置_stp loop-protection
- 5rk3399 android7.1.2 edp屏幕调试_panel-simple.c
- 6PWA 入门指南:理解与构建现代化 Web 应用
- 7如何白嫖最新版BurpSuite Pro_burpsuite professional免费激活
- 8lighting 光照简介(个人笔记)_indirect multiplier
- 9Shell之Sed命令-yellowcong_sed -i命令详解
- 10阿里云原生:如何熟悉一个系统
当前位置: article > 正文
从Hugging Face中下载数据集、模型到本地_下载huggingface上的数据库
作者:我家自动化 | 2024-04-06 07:41:29
赞
踩
下载huggingface上的数据库
1、查看本地代理
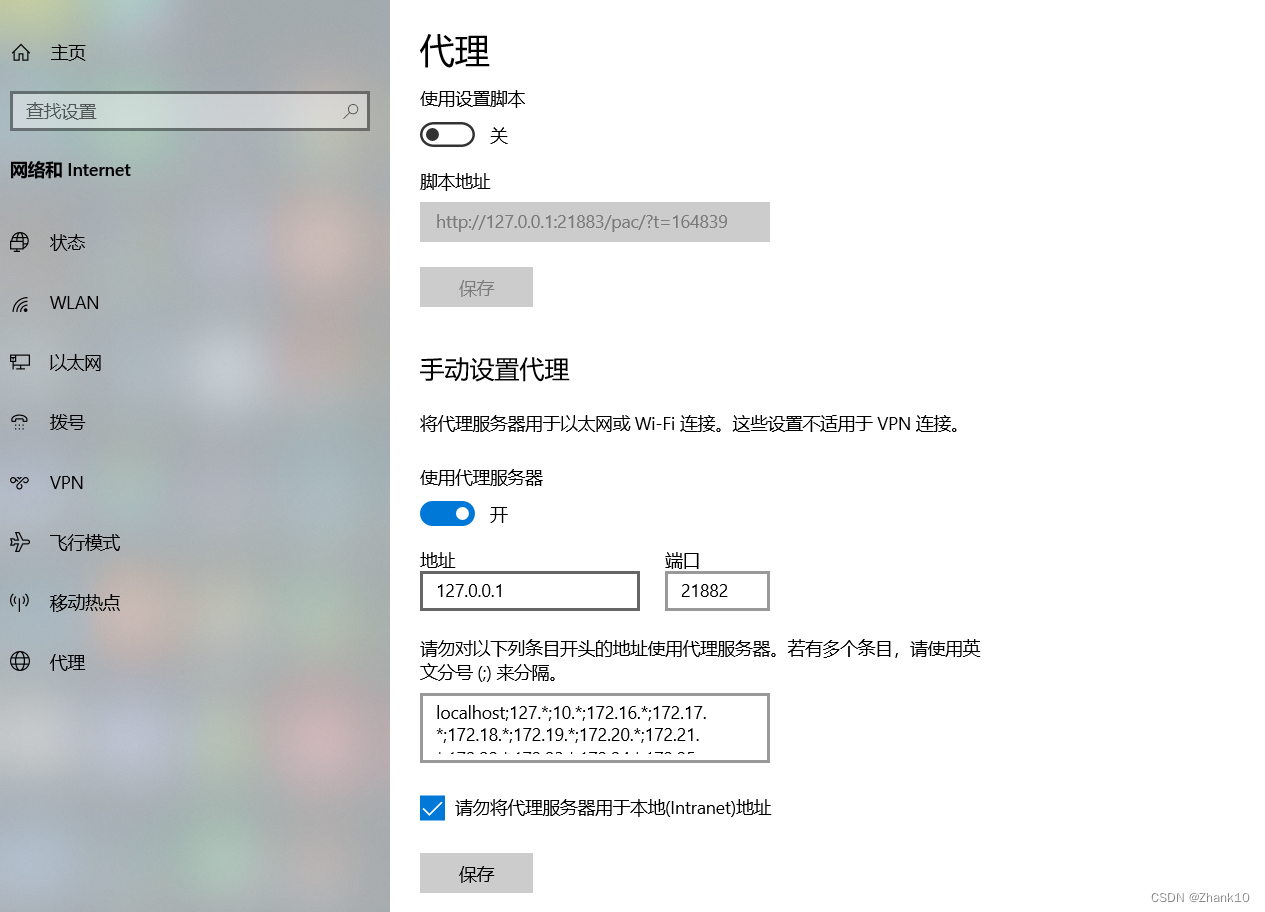
2、下载数据集
将https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M数据集下载到本地
import os import json from datasets import load_dataset ###设置代理,本地vpn os.environ["http_proxy"] = "http://127.0.0.1:21882" os.environ["https_proxy"] = "http://127.0.0.1:21882" dataset = load_dataset("YeungNLP/firefly-train-1.1M") dataset.save_to_disk("dataset/Salesforce/dialogstudio") # 保存到该目录下 print(len(dataset['train'])) print(dataset['train'][3]) with open('./dataset/data.json', 'w', encoding='utf-8') as fp: num = 0 for i in range(len(dataset['train'])): if dataset['train'][i]['kind'] == 'Couplet': fp.write(json.dumps({'input': dataset['train'][i]['input'], 'output': dataset['train'][i]['target']}, ensure_ascii=False)) fp.write('\n') num += 1 print(f"已写入{num}条")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
数据类型如下:
上述代码只读取对联数据,结果如下:

3、下载模型
3.1、直接下载到本地并加载
from transformers import T5Tokenizer, T5ForConditionalGeneration
os.environ["http_proxy"] = "http://127.0.0.1:21882"
os.environ["https_proxy"] = "http://127.0.0.1:21882"
# 首先,下载并保存tokenizer和模型
tokenizer = T5Tokenizer.from_pretrained("t5-small", cache_dir="./t5_model_v1")
model = T5ForConditionalGeneration.from_pretrained("t5-small", cache_dir="./t5_model_v1")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果如下:

3.2、从Hugging Face中手动下载指定好的模型文件到本地并加载
from transformers import T5Tokenizer, T5ForConditionalGeneration
import os
os.environ["http_proxy"] = "http://127.0.0.1:21882"
os.environ["https_proxy"] = "http://127.0.0.1:21882"
tokenizer = T5Tokenizer.from_pretrained("t5_model_v2")
model = T5ForConditionalGeneration.from_pretrained("t5_model_v2")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下载模型如下配置:
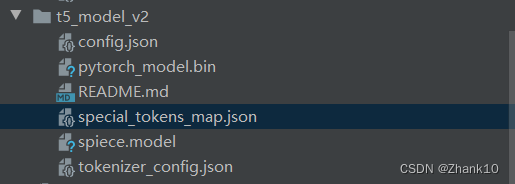
结果如下:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/370635
推荐阅读
相关标签

