
热门标签
热门文章
- 1Spring Boot 集成 RabbitMQ(一)
- 2(超详细)2022年最新版java 8( jdk1.8u321)安装教程_java8下载
- 3libVLC 视频抓图
- 4Google C++ Style Guide_you need to specify reason=string when using boole
- 5NetworkX与GraphScope的性能对比
- 647.在ROS中实现global planner(3)- 使用A*实现全局规划_globalplanner 切换astar
- 7Java面试八股文(2023最新)--SpringBoot面试题_八股文 spring boot面试题
- 8python宿舍管理系统_基于微信小程序的学生宿舍管理系统的设计与实现
- 9全栈自主可控!移动云边缘智能小站EIS新突破_全新云边一体小站
- 10libero开发流程(1)_libero联合modelsim
当前位置: article > 正文
文本与文本处理(一)_文本处理包括哪些内容
作者:我家自动化 | 2024-04-06 15:01:09
赞
踩
文本处理包括哪些内容
前言:
多媒体:

多媒体是融合两种或两种以上表示媒体的一种人机交互式信息交流和传播的媒体。
多媒体技术:
将多种媒体信息通过计算机进行数字化采集、编码、存储、传输、处理和再见等,使多媒体信息建立逻辑连接,并集成一个具有交互性的系统。
一、字符的编码
计算机应用=使用计算机进行信息处理

其中,文字信息处理是涉及面最广的一种计算机应用,几乎与任何领域任何人都有关。
(一)计算机文字处理的过程
- 文字信息在计算机中称为“文本”(text),文本是计算机中最常用的一种数字媒体
- 文本由一系列 “字符”(character)组成,每个字符均使用二进制编码表示
文本在计算机中的处理过程是:
输入(输入码输入计算机)->存储(机内码存储)->编辑
(
word,wps 等软件)->显示(字形码,显示)

(二)字符在计算机中的表示
(1)西文字符的编码——ASCII码
( 1)西文是表音文字(拼音文字),它由拉丁字母、数字、标点符号以及一些特殊符号所组成(2) ASCII 码:美国信息交换标准码①、ASCII 字符集包含 96 个可打印字符和 32 个控制字符, 一共能表示 128 个字符②、 采用 7 个二进位进行编码,是高位位置用 0 表示,共一个字节 8 位。③、 计算机中使用 1 个字节存储 1 个 ASCII 字符,单字节表示。④、常用字符的 ASCII 码: 0=48;A=65;a=97;a-A=32D=20H。 (D 为十进制,H 为十六进制数)⑤、 大写字母可以通过加 32D 得到对应的小写字母。A+32=97=a。( D 为十进制,H 为十六进制数)⑥、 小写字母可以通过减 32D 得到对应的大写字母。a-32=65=A。 (D 为十进制,H 为十六进制数)⑦、ASCII 码值排序:符号(()+-*/等)< 数字(0~9) < 符号(:;<=>?) < 大写字母(A~Z) < 小写字母(a~z)
存在问题:
- 字符集太小(只有128个字符)
- 不同国家和地区使用不同的字符集及其编码,互不兼容
- 东亚地区使用的大字符集无法编码
(2)常用的汉字编码字符集
(1)国家标准:GB2312-1980( GB2312-80):简体中文为主。( 2)汉字扩充规范:GBK:支持繁体中文。( 3)UCS/Unicode 多文种大字符集也包含汉字:UTF-8,UTF-16:多种文字符号,支持简繁中文。( 4)国家标准 GB18030-2005:繁简体中文,与 UCS/Unicode 编码标准接轨。( 5)港澳台使用的汉字编码字符集 CNS 11643(BIG 5 ,“大五码”):繁体中文
(3)GB2312汉字编码字符集(7445个)

(1)
GB2312 字符三个部分构成(汉字:6763 个;字符:682 个):
①、字母、数字和种符号(
682 个):拉丁字母、俄文、日文平假名与片假名、希腊字母、汉语拼音等
②、一级汉字(
3755 个):按汉语拼音排列
③、二级汉字(
3008 个):按偏旁部首排列
(
2)一个 GB2312 汉字使用 2 个字节(
16 位)表示,即双字节表示。
(
3)每个字的最高位均为 1,双 1 表示。
(
4)每个汉字或符号都有一个确定位置,该位置的区号和位号就是这个汉字的“区位码”。区位码的区位
和码位各自的取值范围是 1~94。
(
5)
区位码+2020H=国标码;
国标码+8080H=机内码;
区位码+A0A0H=机内码。
注意,题目可能给出是十进制的区位码,比如4907D,需要将其转换成16进制数,一个字节一个字
节转哦,49D=31H,07D=07H。然后再进行计算机内码(逢十六进1)
(
6)
GB2312-1980 汉字字数太少,缺少繁体字,无法满足人名、地名、古籍整理、古典文献研究等应用
的需要;与 ASCII 码不兼容。
GB2312的不足:
汉字字数太少,缺少繁体字,无法满足人名、地名、古籍整理、古典文献研究等应用的需要;与ASCII码不兼容。


(4)UCS/Unicode 多文种大字符集
(1) 为了实现全球数以千计的不同语言文字的统一编码
(2) ISO 将全球所有文字字母和符号集中在一个字符集中统一编码(目前共 154 套书写符号,约 14.4 万个字符) ,称为 UCS/Unicode
(3)它不兼容我国的任何编码标准。
(4)UCS/Unicode 的编码方案:
①、尽量与已有编码标准兼容
②、包含有中、日、韩、越统一整理出来的约 12 万个表意文字(称 CJKV 汉字)
③、允许有若干不同的编码方案, 常用的两种是:
UTF-8:单字节可变化编码,应用于 Linux、Web 网页,电子邮件等
UTF-16:双字节可变长编码,Windows,Mac,Java 等

(5)GB18030汉字编码标准——2005年
(1)为了既能与 UCS/Unicode 编码标准接轨
(2)GB18030 实质上是 UCS/Unicode 字符集的另一种编码方案
①、单字节编码(
128 个)表示 ASCII 字符
②、双字节编码(23940 个)表示汉字,与 GBK(以及 GB2312)保持向下兼容
③、四字节编码(约 158 万个)用于表示 UCS/Unicode 中的其他字符
(3)GB18030 目前已在我国信息处理产品中强制贯彻执行
(4)支持繁体汉字。
(5)GB18030 与 GB2312、GBK 兼容的汉字编码标准
(6)GB18030-2000 收录了 27533 个汉字,GB 18030-2005 共收录汉字 70,244 个。
GB18030实质上是UCS/Unicode字符集的另一种编码方案:
- 单字节编码(128个)表示ASCII字符
- 双字节编码(23940个)表示汉字,与GBK(以及GB2312)保持向下兼容,GBK不再使用
- 四字节编码(约158万个)用于表示 UCS/Unicode中的其他字符
(6)Big 5 码 ——港澳台标准汉字字符集,只有繁体字。
(7)几种汉字编码的对比


二、文本输入方法





(1)
键盘输入(人工输入)
:
①、数字编码,使用一串数字表示汉字,如电报码、区位码等,
②、字音编码, 如智能 ABC、微软拼音、搜狗拼音等
③、字形编码,如五笔字形和表形码等,
④、形音编码,吸取字音和字形的优点,不易掌握。
(2)
非键盘输入
①、联机手写输入(人工输入)
②、语言输入(人工输入)
③、光学字符识别(自动识别输入)
④、条形码、磁卡、IC 卡、RFID 识别(自动识别输入)

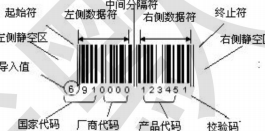
![]()





声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/372636
推荐阅读
相关标签

