
- 1基于深度学习、机器学习,神经网络,OpenCV,图像处理,卷积神经网络计算机毕业设计题目大全_基于神经网络的毕设题目
- 2使用python计算RMSR、MRE和R方、MAE_python实现rmse
- 3关于QWidget里的Widget::paintEvent (QPaintEvent * event)显示图片的问题(即qpainter.drawPixmap)_widget中paintevent无效
- 420240326 每日AI必读资讯_gatekeep ai 网址
- 5微信小程序的N种页面跳转方式(2024最新)_微信小程序页面跳转
- 6YOLOv8-seg 分割代码详解(一)Predict
- 7MATLAB 线性拟合直线示例 + MATLAB线性拟合中文文档(决定系数R^2公式与解释 与 带惩罚项的修改R^2)_matlab拟合直线
- 8爬虫实战——中国天气网数据_爬取天气预报的目的
- 9paddleocr的基本使用_paddleocr zlibwapi.dll
- 10word2vec原理详解及实战_word2vec原理与实战详解(一)
目标检测——YOLOv7(十三)_yolov7 结构重参数化
赞
踩
简介:
继美团发布YOLOV6之后,YOLO系列原作者也发布了YOLOV7。主要从两点进行模型的优化:模型结构重参化和动态标签分配。
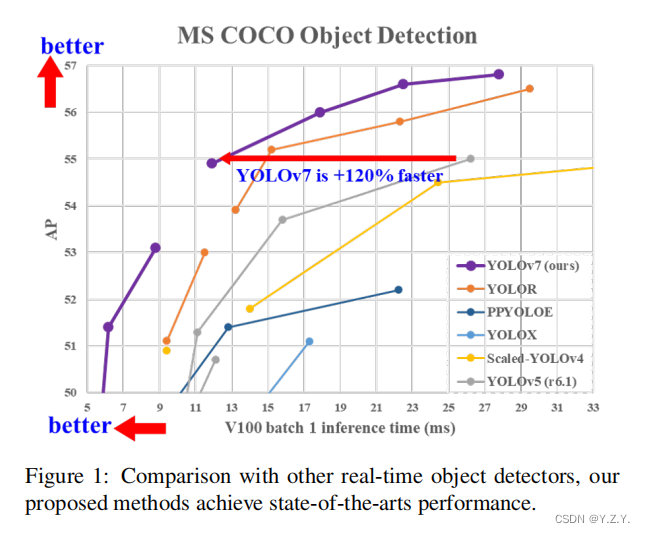
YOLOv7的特点是快!相同体量下比YOLOv5精度更高,速度快120%,比YOLOX快180%。
Github地址:https://github.com/WongKinYiu/yolov7
论文地址:https://arxiv.org/abs/2207.02696
作者给的算法性能如下图:
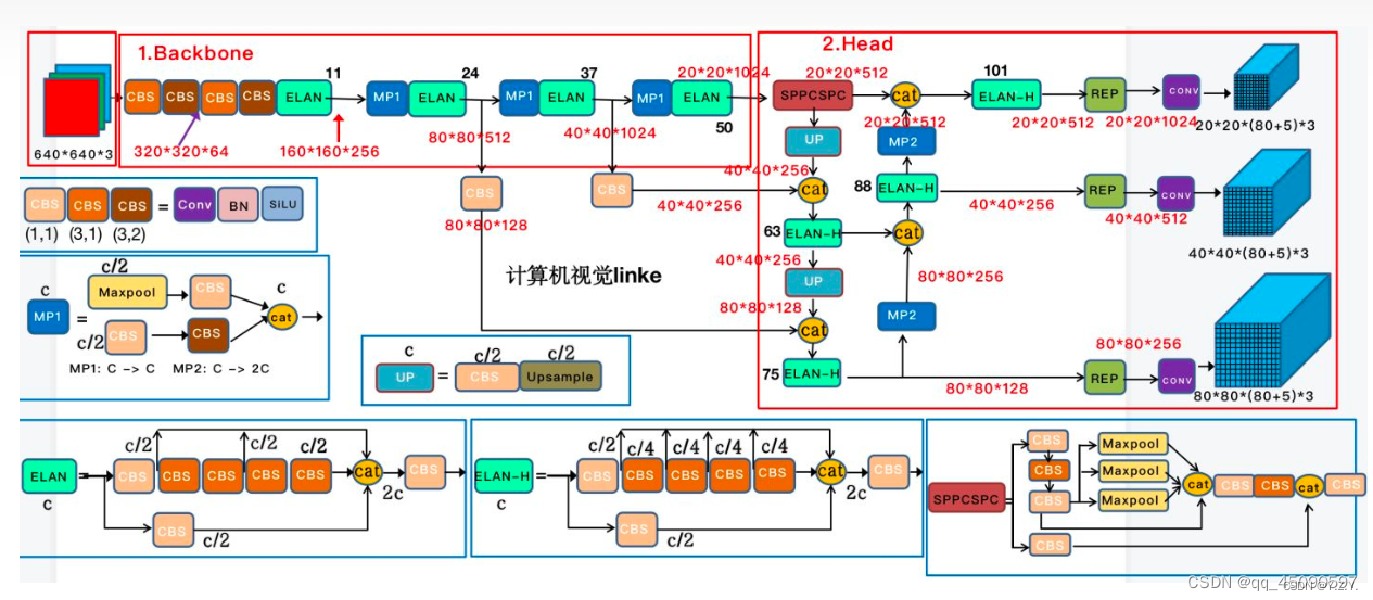
网络结构
核心原理详解:
1、Input:
整体复用YOLOV5的预处理方式和相关源码,唯一需要注意的是,官方主要是在640640和12801280这样的相对较大的图片上进行的训练和测试。
2、Backbone:
首先是经过 4 层卷积层,CBS 主要是 Conv+BN+SiLU 构成,在图中用不同的颜色表示不同的 size 和 stride, 如 (3, 2) 表示卷积核大小为 3 ,步长为 2。经过 4个 CBS 后,特征图变为 160×160×128 大小。
随后会经过论文中提出的 ELAN 模块,ELAN 由多个 CBS 构成,其输入输出特征大小保持不变,通道数在开始的两个 CBS 会有变化, 后面的几个输入通道都是和输出通道保持一致的,经过最后一个 CBS 输出为需要的通道。
MP1层输入输出通道相同,输出长宽为输入长宽的一半。

综述整个backbone层由若干BConv层、E-ELAN层以及MPConv层交替减半长宽,增倍通道,提取特征。
3、 Head:
YOLOV7 head 其实就是一个 pafpn 的结构,和之前的YOLOV4,YOLOV5 一样。区别在于将 YOLOV5 中的 CSP 模块换成了ELAN-H 模块,同时下采样变为了MP2层。ELAN-H和 backbone 中的 ELAN 稍微有点区别就是 cat 的数量不同,通道数减半。
重参数化卷积
重参化技术是模型在推理时将多个模块合并成一个模块的方法,其实就是一种集成技术。常见的重参化技术有:
- 一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。
- 一种是对不同迭代次数下模型权重进行加权平均。
虽然RepConv在VGG上取得了很不错的效果,但将它直接应用于ResNet和DenseNet或其他骨干网络时,它的精度却下降得很厉害。作者就是用梯度传播路径的方法来分析,因为RepConv结合了3×3卷积,1×1卷积,和在一个卷积层中的identity连接,可是这个identity破坏力ResNet的残差连接以及DenseNet的跨层连接,为不同的特征图提供了更多的梯度多样性。
因此,作者认为,在同时使用重参化卷积和残差连接或者跨层连接时,不应该存在identity连接,而且作者还分析重参数化的卷积应该如何与不同的网络结构相结合以及设计了不同的重参数化的卷积。
重参数化的作用:在保证模型性能的条件下加速网络,主要是对卷积+BN层以及不同卷积进行融合,合并为一个卷积模块。
辅助头检测
YOLOv7中,将head部分的浅层特征提取出来作为Aux head(辅助头),深层特征也就是网络的最终输出作为Lead head(引导头),如图b所示。
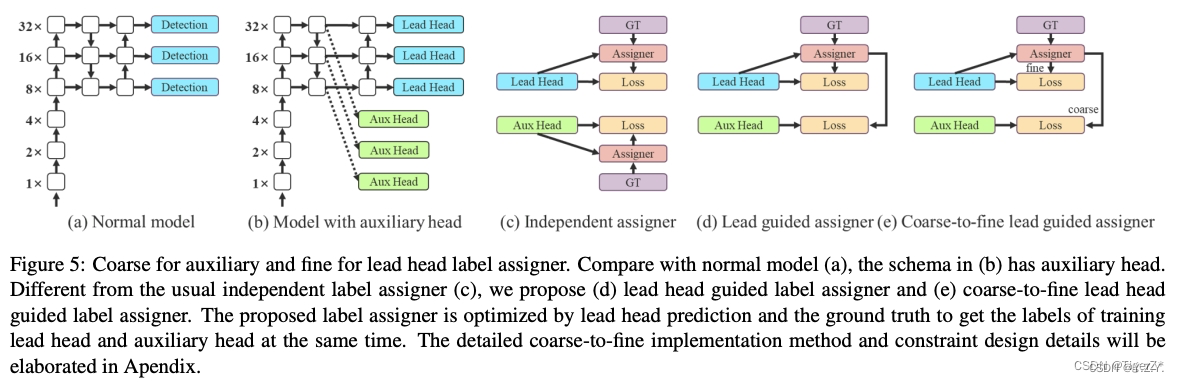
在计算损失时:
- 图c的策略是,lead head和aux head分别、单独计算损失,最终相加
- 图d的策略是,lead head单独计算损失,aux head将lead head匹配得到的正样本作为自己的正样本,并计算损失,最终相加(占比不同)
- 图e的策略是,lead head单独计算损失,aux head将lead head匹配得到的正样本(这里是粗匹配,也就是选择GT框中心点所在网格的上下左右4个邻域网络作为正样本筛选区域)作为自己的正样本,并计算损失,最终相加(占比不同)
动态标签分配
在网络的训练中,标签分配通常是指GT,这个是硬标签,但近年来,需要研究者会利用网络的推理结果来结合GT,去生成一些软标签,如IOU。
在YOLOv7中,有辅助头也有引导头,在训练时,它们二者都需要得到监督。因此,需要考虑如何为辅助头和引导头进行标签分配。因此在这里,作者提出了一种新的标签分配方法,是以引导头为主,通过引导头的推理来指引辅助头和自身的学习。
首先使用引导头的推理结果作为指导,生成从粗到细的层次标签,分别用于辅助头和引导头的学习。
- Lead head guided label assigner 引导头引导标签分配 引导头引导标签分配是根据引导头的预测结果和GT进行一系列优化计算来生成软标签,然后软标签作为辅助头和引导头的优化方向来训练模型。这样是由于引导头本身具备比较强的学习能力,因此由此产生的软标签应该更能代表源数据与目标之间的分布和相关性,而且还可以将这种方式当作是一种广义上的余量学习。通过让较浅的辅助头直接学习引导头已经学习到的信息,然后引导头就更能专注于学习到它还没有学习到的剩余信息。
- Coarse-to-fine lead head guided label assigner 从粗到细的引导头引导标签分配 Coarse-to-fine引导头使用到了自身引导头的推理结果GT来生成软标签,进而引导标签进行分配。然而,在这个过程中会生成两组不同的软标签,即粗标签和细标签, 其中细标签与引导头在标签分配器上生成的软标签是一样的,粗标签是通过允许更多的网格作为正目标,不单单只把gt中心点所在的网格当成候选目标,还把附近的三个也加进来了,增加正样本候选框的数量,以降低正样本分配的约束。因为辅助头的学习能力没有指导头强,所以为了避免丢失需要学习的信息,就提高辅助头的召回率,对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。
但是如果粗标签的附加权重和细标签的附加权重差不多,那么在最终预测时就可能产生错误的先验结果。因此,为了使那些超粗的正网格影响更小,会在解码器中设置限制,来使超粗的正网格无法完美地产生软标签。通过以上的机制,允许在学习过程中动态调整细标签和粗标签的重要性,使细标签的始终优于粗标签。
总结
总的来说,在模型的结构上,yolov7的模型搭建延续了yolov5的手法,提出了ELAN的一个新颖concat结构和一个新颖的MP降维结构。同时,在部分版本中使用上了Rep结构(将3x3卷积,1x1卷积,残差链接)拓扑组合在一起。
对于正负样本的匹配上,使用了yoloX的SimOTA匹配方法,与yolov5的匹配方法进行融合。也就是simOTA中的第一步“使用中心先验”替换成“yolov5中的策略”,提供了更加精确的先验知识。同时还额外使用了辅助头。
但是无论是yolov6还是yolov7都使用了SimOTA的匹配方法,足以说明SimOTA的正负样本匹配策略是先进的。辅助头在宏观上也提供了一个额外的思路,就是在中间过程也可以进行一个损失计算,作为一个辅助的损失。这个辅助损失在结构计算上完全与正常的检测头计算损失相同,只是分配的权重不一样就可以了,这个权重比也可以作为是一个超参数调节。
而yolov6和yolov7也不约而同的都看上了参数重结构化的思路,也就是RepConv。说明这种训练过程和验证过程解耦的思路,可以改变网络的拓扑结构,从而加快推理速度,实现更快更强的目标检测算法。

