
热门标签
热门文章
- 1Android Studio 连接夜神模拟器的方法_android studio连接夜神模拟器
- 2【访问网络资源出错】不允许一个用户使用一个以上用户名与服务器或共享资源的多重连接
- 3git clone报错:remote: Support for password authentication was removed on August 13, 2021._get clone remote: support for password authenticat
- 4idea使用Spring Initializer创建springboot项目的坑【保姆级教学】
- 5【大模型专区】Text2Video-Zero—零样本文本到视频生成(上)
- 6神经网络深度学习梯度下降算法优化
- 7最新chatGPT镜像网站入口
- 8BigDecimal类的加减乘除(解决double计算精度问题)_bigdecimal怎么和double相乘
- 9Zookeeper Zab 协议解析——算法整体描述(一)_解析整体描述
- 10海外版抖音怎么下载?如何快速完成下载并注册TikTok账号?
当前位置: article > 正文
kafka 高吞吐设计分析
作者:我家自动化 | 2024-04-10 11:17:32
赞
踩
kafka 高吞吐设计分析
说明
- 本文基于 kafka 2.7 编写。
- @author blog.jellyfishmix.com / JellyfishMIX - github
- LICENSE GPL-2.0
概括
支撑 kafka 高吞吐的设计主要有以下几个方面:
-
网络 nio 主从 reactor 设计模式
-
顺序写。
-
零拷贝。
producer
- producer 开启压缩后是批量压缩,broker 不解压没有解压消耗,consumer 批量拉取并解压,实现端到端压缩。
broker
网络 nio 主从 reactor 设计模式
- nio 主从 reactor 模式和 tomcat, netty 类似。nio 主从 reactor 模式请见文章: https://blog.csdn.net/weixin_43735348/article/details/128445926
- 采用主从 reactor 的原因: acceptor 线程专门负责建立连接, selector 线程。acceptor 和 selector 线程资源隔离,且两个资源各自可以根据压力扩展线程数。
顺序读写
- kafka 写日志文件的时候用的是追加消息的形式,只在文件尾部顺序写消息。读时在文件头部顺序读取消息。不涉及修改消息,所以不需要随机写。
- 这样的设计即使用的是传统机械硬盘,访问速度也快。操作系统和硬件对顺序写和顺序读有优化,具体采用的是后写和预读(读时连带读出附近的页)。另外机械硬盘磁针寻址也对顺序读写更友好,对于机械硬盘大概顺序写比随机写快 3 个数量级。
零拷贝
- 非零拷贝发送数据过程: 用户执行系统调用读磁盘,用户态切换成内核态。硬盘上的数据通过 DMA 读入内核空间后,cpu 拷贝至用户空间,切换回用户态。执行网络 IO 系统调用,用户态切换成内核态,cpu 拷贝数据至内核空间(socket 缓存),通过 DMA 写入网卡。
- 存在两次 cpu 拷贝和两次内核态用户态切换浪费。
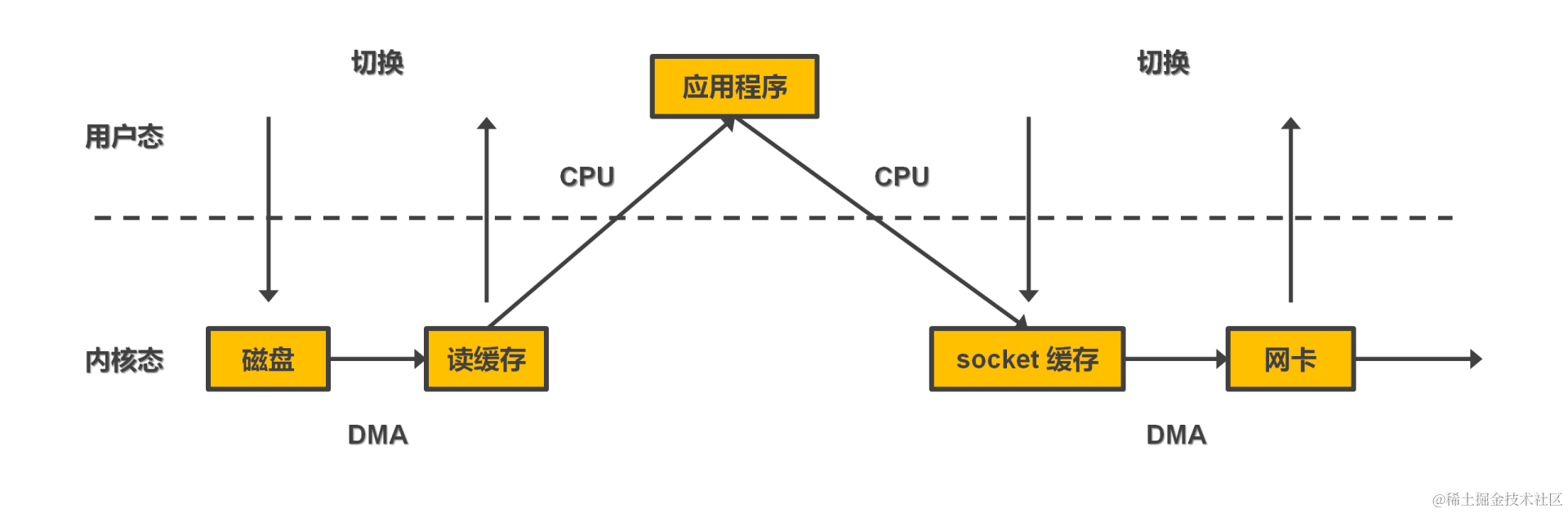
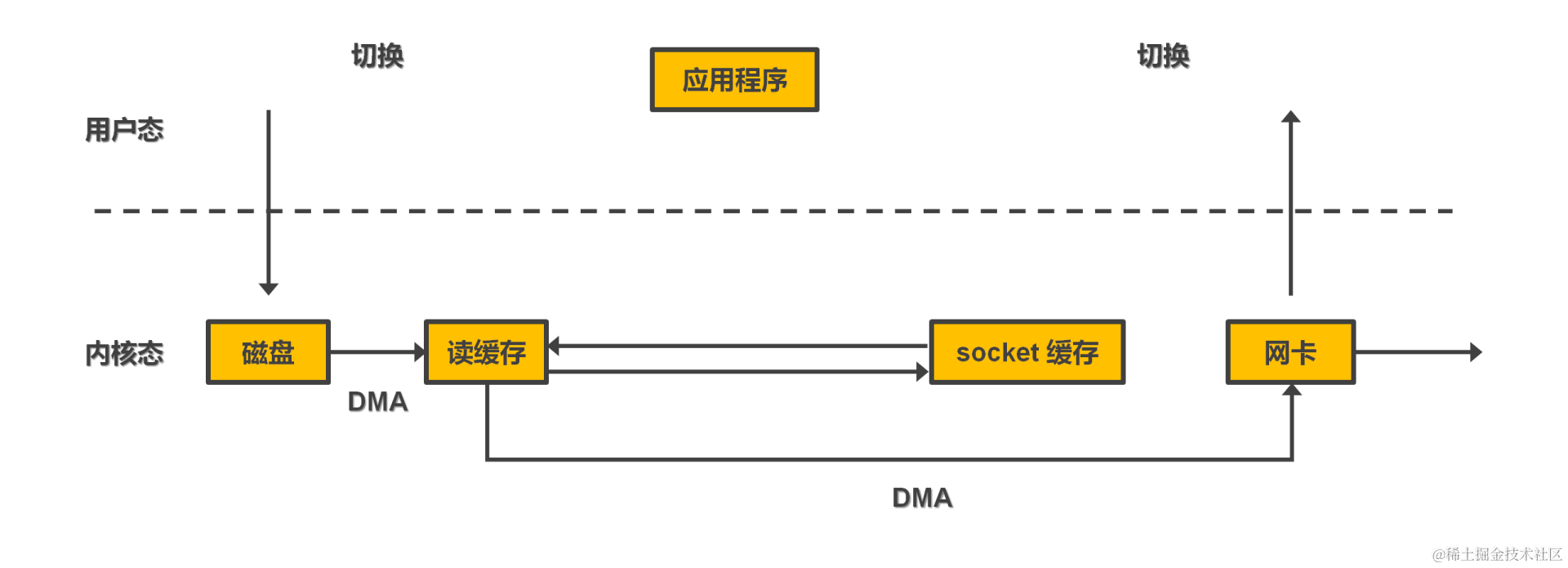
- 零拷贝基于操作系统提供的系统调用 – sendfile()。用户执行系统调用切换至内核态,DMA 从硬盘拷贝数据至内核空间,socket 缓存写入内核空间中数据的地址等描述信息。由 DMA 把数据从内核空间传递至网卡。这样可节约两次 cpu 的拷贝开销。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/398368
推荐阅读
相关标签

