- 1【Unity学习笔记】b站Unity架构课Unity3D 商业化的网络游戏架构(高级/主程级别)_unity3d 商业化的网络游戏架构(高级/主程级别)
- 2地图比例尺与空间分辨率之间的关系_地图比例尺,分辨率,dpi之间的关系
- 3Fastadmin框架,服务器搭建环境
- 4辅警考试怎么搜题答案?八个受欢迎的搜题分享了 #学习方法#学习方法#媒体
- 5模型实战(12)之YOLOv8实现车牌识别:高精度+速度+权重分享_yolo8 predict 识别车牌
- 6模拟退火算法求解TSP问题-python实现_tsp退火算法python
- 7Axure元件库的使用_axure组件库使用
- 8JavaWeb学习路线(总结自尚硅谷雷神SSM|极其详细|思路清晰|适合入门/总复习)
- 9软件测试未来主要发展的5个趋势
- 10uniapp里面tabbar自定义的方法_uniapp 自定义tabbar
使用免费算力对gemma进行微调(以gemma 2b的LORA微调为例)
赞
踩

gemma介绍
Gemma是Google推出的一系列轻量级、最先进的开放模型,基于创建Gemini模型的相同研究和技术构建。提供了 2B 和 7B 两种不同规模的版本,每种都包含了预训练基础版本和经过指令优化的版本。所有版本均可在各类消费级硬件上运行,无需数据量化处理,拥有高达 8K tokens 的处理能力:
它们是文本到文本的、仅解码器的大型语言模型,提供英语版本,具有开放的权重、预训练的变体和指令调优的变体。
Gemma模型非常适合执行各种文本生成任务,包括问答、摘要和推理。它们相对较小的尺寸使得可以在资源有限的环境中部署,例如笔记本电脑、桌面电脑或您自己的云基础设施,使每个人都能获得最先进的AI模型,促进创新。
Github地址:https://github.com/google/gemma_pytorch
论文地址:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
本次以Google的colab为例进行演示,当然以kaggle的免费算力也一样(本来打算用kaggle没有成功,后期更新)
前期准备
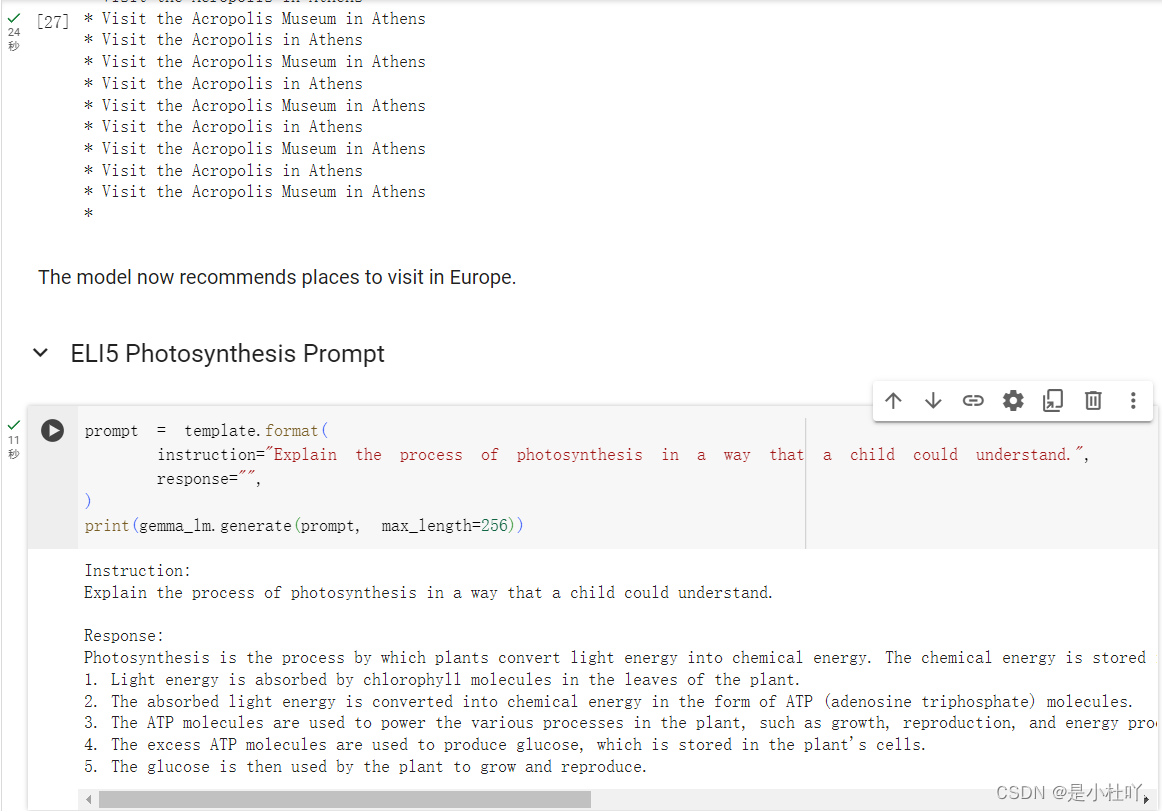
- 在kaggle上使用Google的colab打开
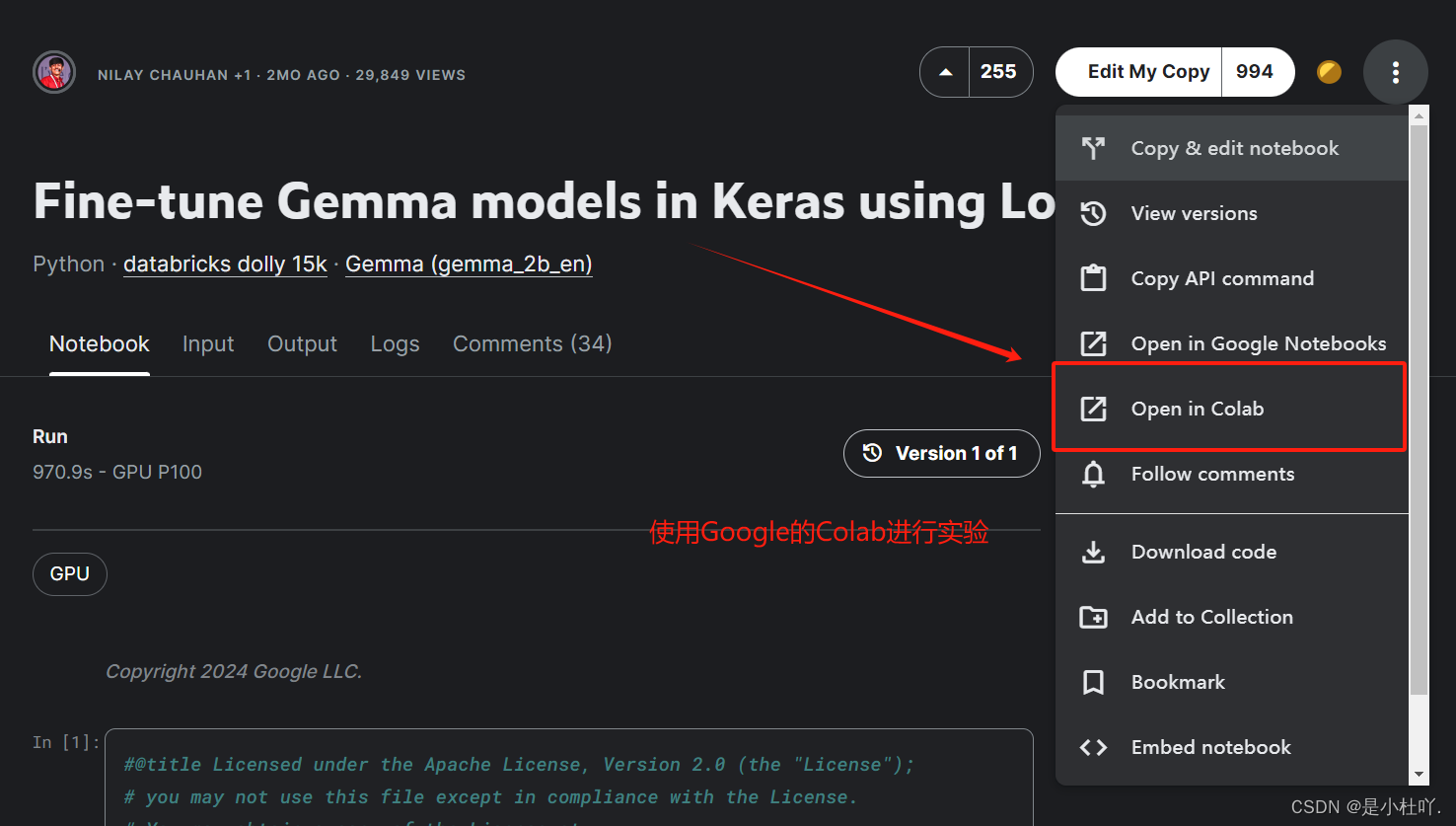
- 连接免费提供的T4 GPU 作为算力
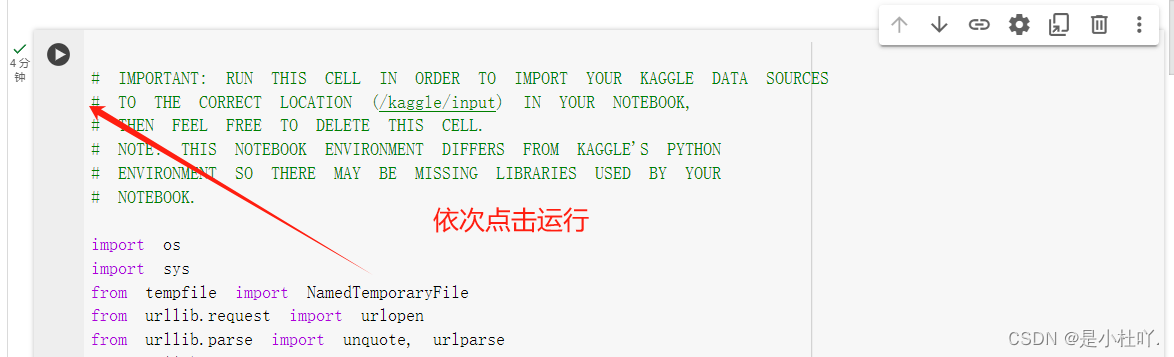
下载模型
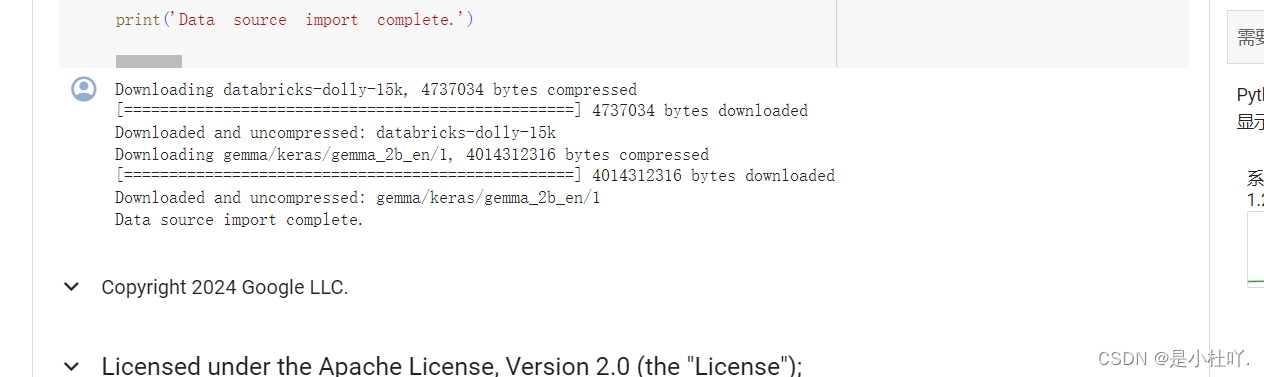
下载依赖,不过版本冲突(该错误消息表明 tf-keras 版本 2.15.1 要求 TensorFlow 版本小于 2.16 但大于或等于 2.15,而您安装了 TensorFlow 版本 2.16.1,这与此要求不兼容。)先暂时不用管,看后续会不会有bug
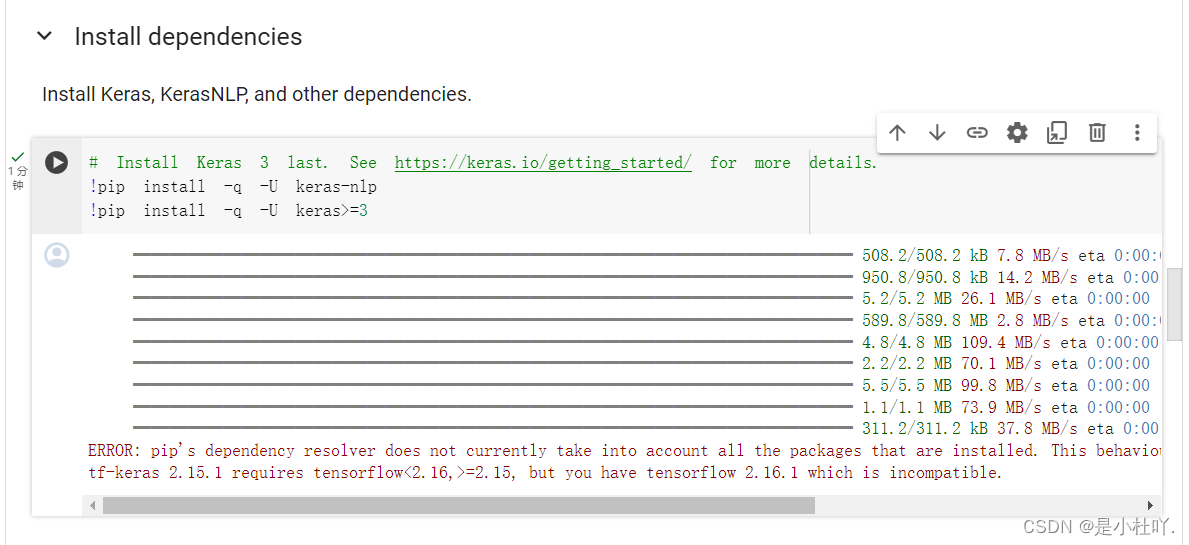
- 然后就是依次点击运行,代码块前后也会有注释
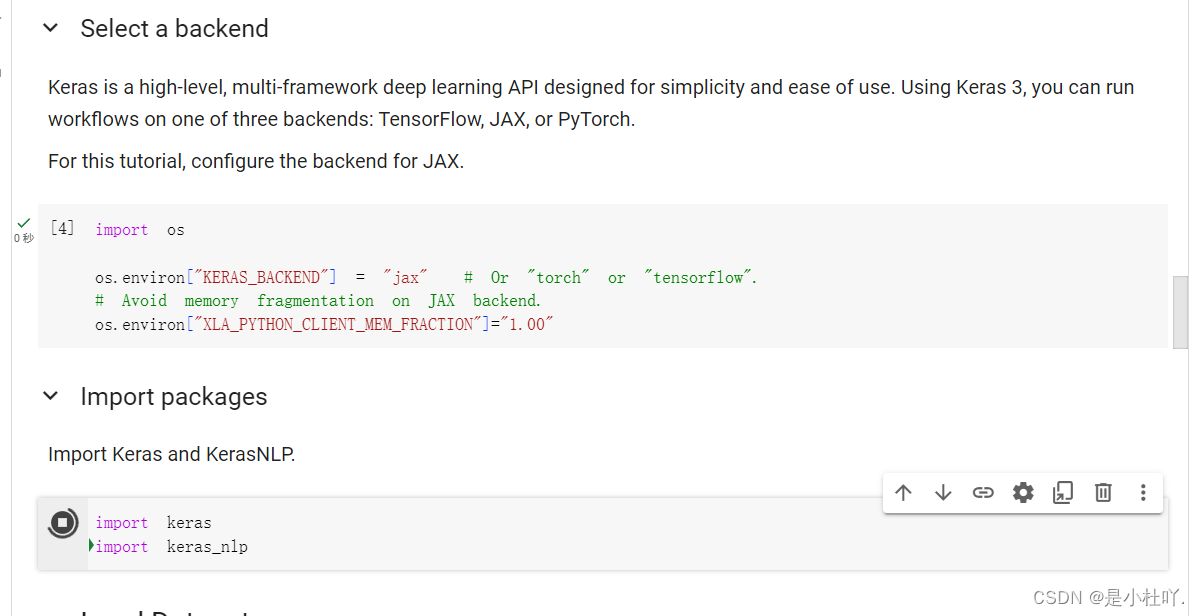
加载模型时报错,因为缺少身份验证而无法从kaggle获取资源,需要将kaggle的api密钥替换成自己的
进入kaggle登录自己账号,点击头像----Settings----Create new Token
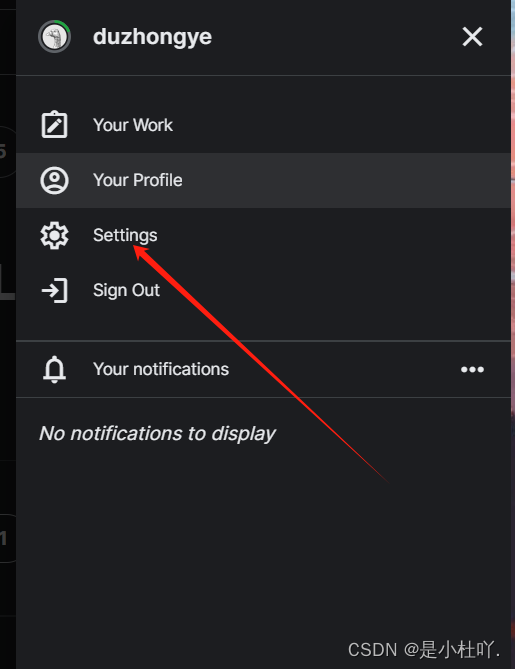
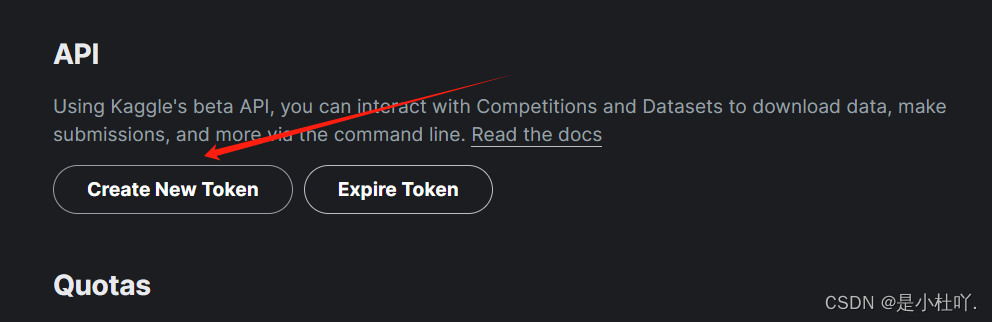
创建.kaggle文件夹,并放入自己的密钥,如图

- 在此之前要加入kaggle相关语句,如图
!pip install -q kaggle
!chomd 600 ~/.kaggle/kaggle.json
- 1
- 2

-
然后要将图中所示位置的路径换成模型config文件所在的文件夹路径,否则报错
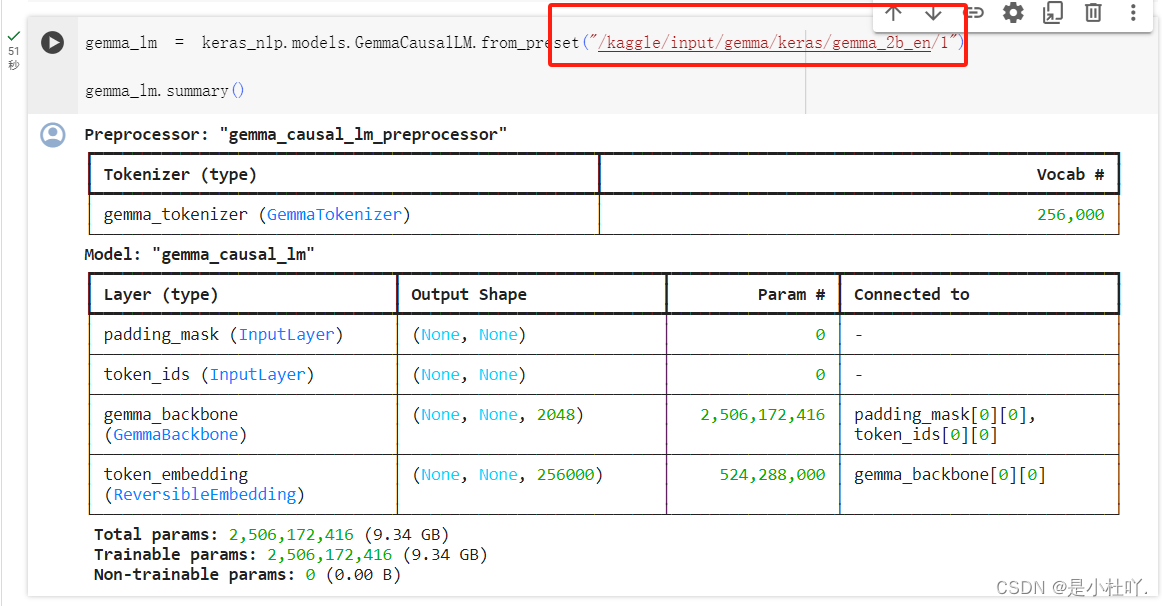
-
接下来就是微调前的推理了,我们可以看到gpu利用率显著升高
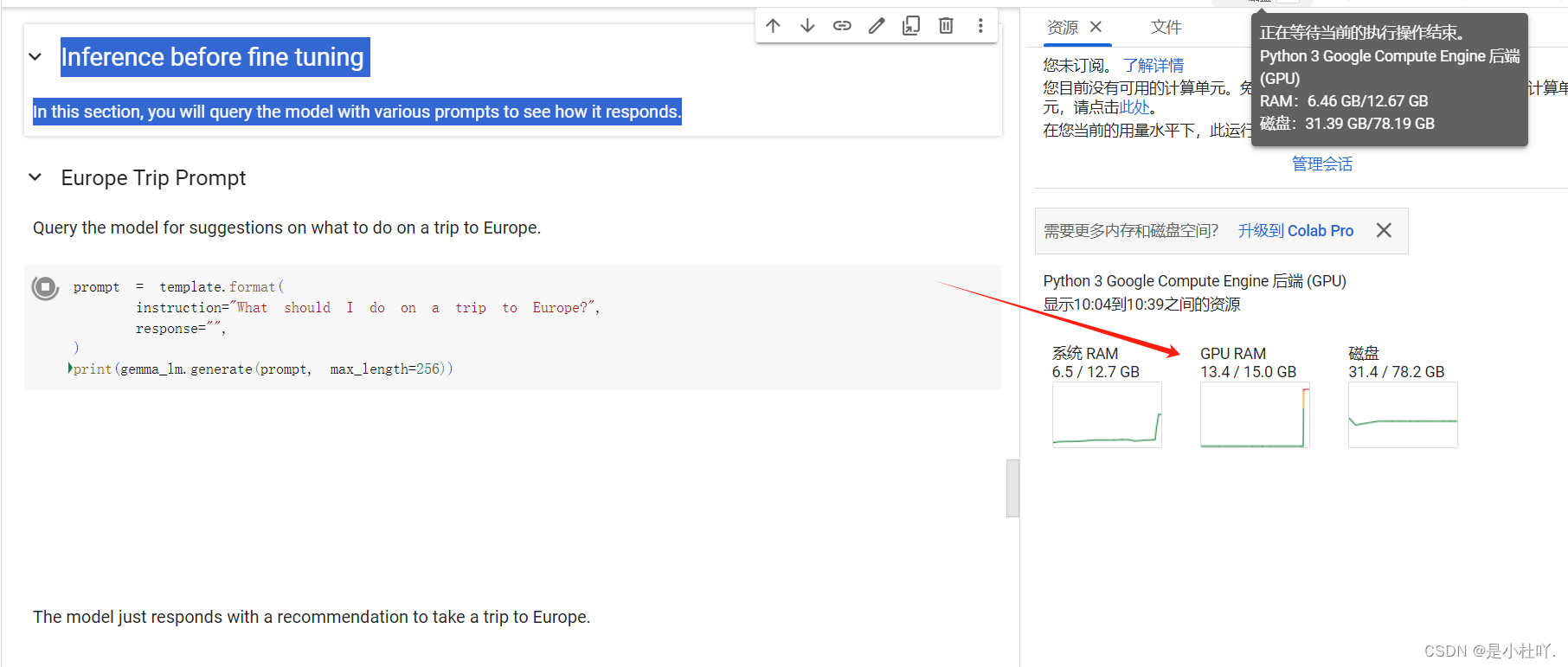
- 再往下走就是微调了,这里是LoRA微调
(请注意,启用 LoRA 会显着减少可训练参数的数量(从 25 亿减少到 130 万)。)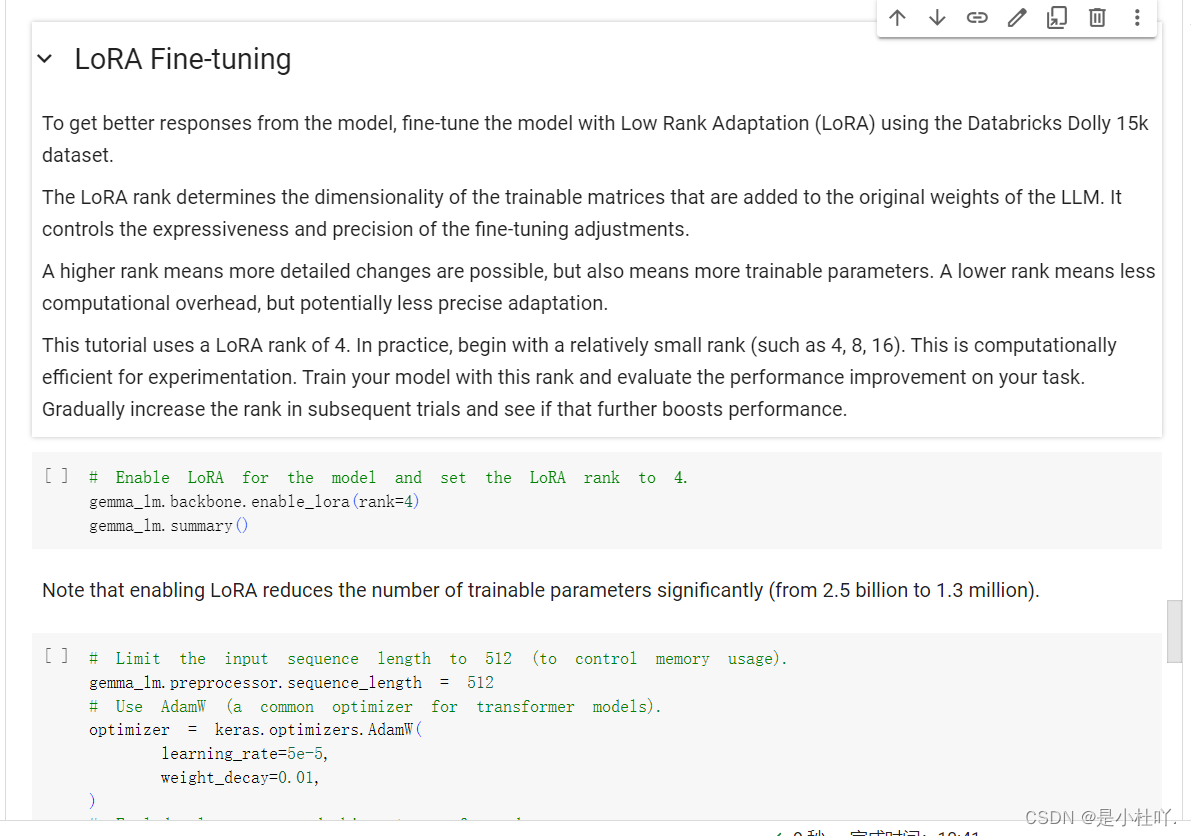
- 以下是官方给出的提示:
*为了从模型中获得更好的响应,请使用 Databricks Dolly 15k 数据集通过低秩适应 (LoRA) 微调模型。 LoRA 等级决定了添加到 LLM 原始权重的可训练矩阵的维数。 它控制微调调整的表现力和精度。 更高的排名意味着可以进行更详细的更改,但也意味着更多可训练的参数。 较低的等级意味着较少的计算开销,但可能不太精确的适应。 本教程使用 LoRA 等级 4。在实践中,从相对较小的等级开始(例如 4、8、16)。 这对于实验来说计算效率很高。 使用此排名训练您的模型并评估您的任务的性能改进。 在后续试验中逐渐提高排名,看看是否会进一步提高性能。*
启用微调:
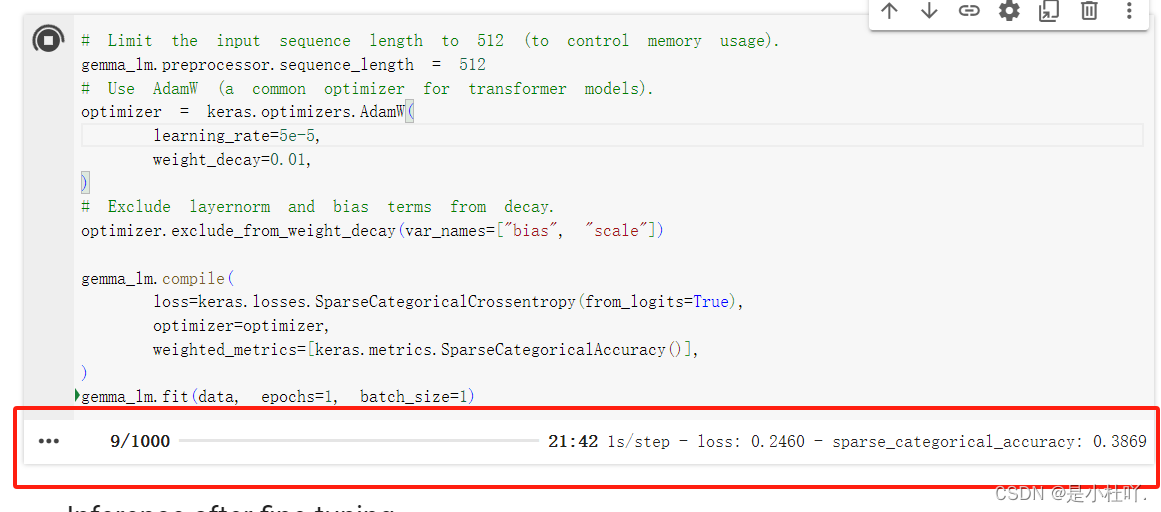
微调的参数,数据集等内容根据自己实际情况来替换即可
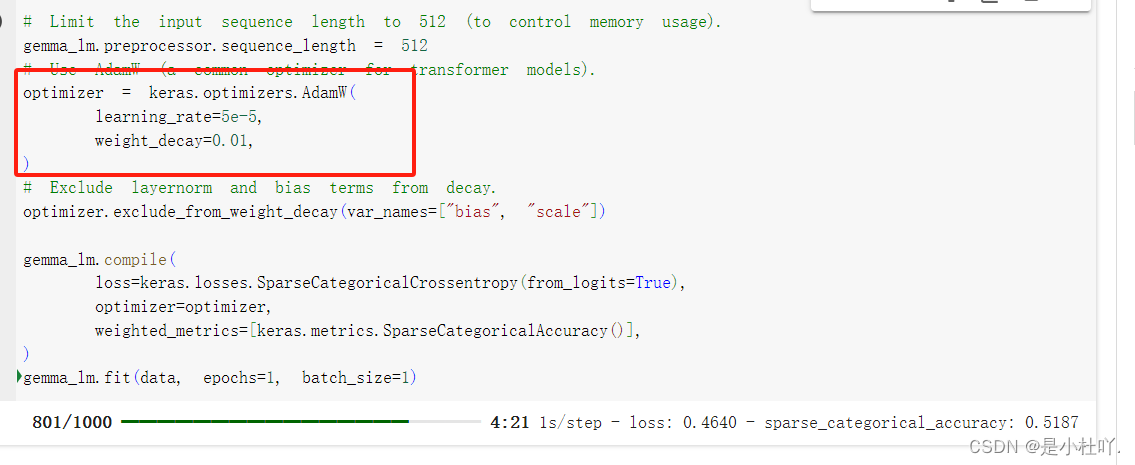
微调结束!!
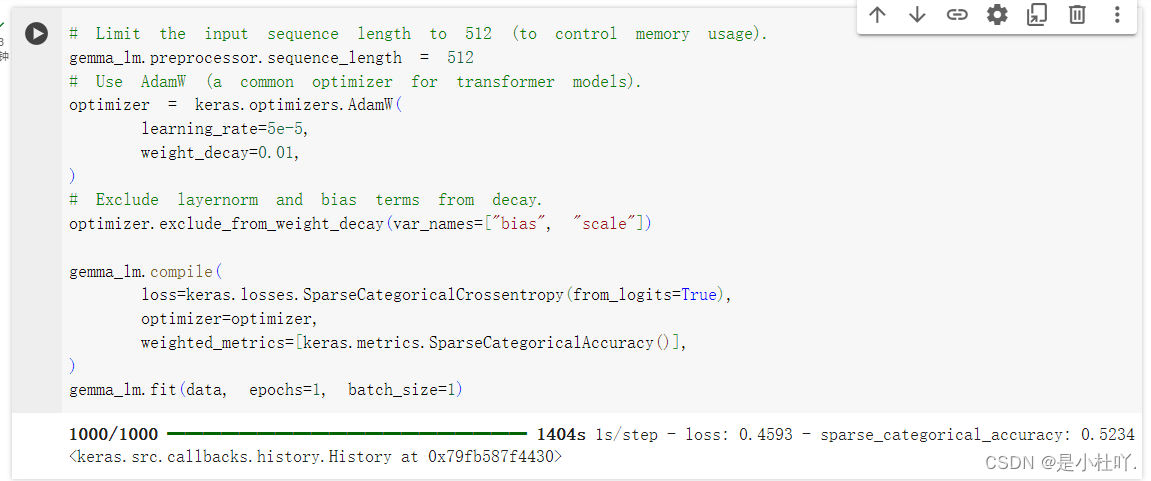
微调之后的推理:
- 完美运行!