
- 1金三银四春招特供|高质量面试攻略
- 2新版 Redis 将不再“开源”引争议:本想避免云厂商“白嫖”,却让开发者遭到“背刺”!_rsalv2
- 3前端js调取数据库总结_前端代码可以查数据库吗
- 4python3开发-AI智能联系人管理系统_.python3开发-ai智能联系人管理系统
- 5python matplotlib绘图技巧(1)-plt.legend()_plt legend nrow
- 6SystemVerilog Assertions应用指南 第一章(1.23章节 “intersect”运算符)_systemverilog assert intersect
- 7Flutter性能优化-WebView使用姿势
- 8Mysql查询:行转列与列转行_mysql 列转行
- 9LeetCode热题100刷题笔记_给定一个数组,某区间的收益为:这段区间的最小值*这段区间所有元素之和,现在需要你
- 10手把手教你写批处理
Google视觉机器人超级汇总:从RT、RT-2到AutoRT/SARA-RT/RT-Trajectory、RT-H_机器人 rt 1 解析 分析
赞
踩
前言
随着对视觉语言机器人研究的深入,发现Google的工作很值得深挖,比如RT-2
想到很多工作都是站在Google的肩上做产品和应用,Google真是科技进步的核心推动力,做了大量大模型的基础设施,服(推荐重点关注下Google deepmind的工作:https://deepmind.google/discover/blog/)
故有了本文,单独汇总Google在机器人领域的重大结果、进展
第一部分 RT-1:首个Transformer机器人
Google于22年年底,正式提出RT-1,其将“语言”和“视觉观察”映射到机器人动作视为一个序列建
模问题,然后使用transformer来学习这个映射
- 即Robotics Transformer 1,其项目地址:https://robotics-transformer1.github.io/,其paper地址(其v1 Submitted on 13 Dec 2022,至于v2 revised 11 Aug 2023):RT-1: Robotics Transformer for Real-World Control at Scale
- 通过将高维输入和输出(包括相机图像、指令和电机指令)编码为紧凑的token表示,供Transformer使用,可以在运行时进行高效的推理,使实时控制成为可能
which by encoding high-dimensional inputs and outputs, including camera images, instructions and motor commands into compact token representations to be used by the Transformer, allows for efficient inference at runtime to make real-time control feasible
1.1 策略学习方法上的选择:模仿学习
现在的目标是从视觉中学习机器人策略来解决语言条件任务
- 形式上,我们考虑一个顺序决策环境。在时间步长
时,策略
被提供一个语言指令
和一个初始图像观察
。 策略产生一个动作分布
,从中采样并应用于机器人的一个动作
- 这个过程持续进行,策略通过从学习的分布
中采样来迭代地产生动作
,并将这些动作应用于机器人。 交互在达到终止条件时结束
- 从起始步骤
的完整交互
被称为一个 episode。 在一个episode结束时,Agent将获得一个二进制奖励
,指示机器人是否执行了指令
至于在策略的学习上,最终使用的模仿学习方法
- 首先,可以使用Transformer来参数化策略
映射到输出序列
,使用自注意力层和全连接神经网络的组合
虽然Transformer最初是为文本序列设计的,其中每个输入和输出
表示一个文本token,但它们已经扩展到图像以及其他模态
且在使用Transformer学习映射之前,先将输入
映射到序列
- 其次,可以使用模仿学习。 模仿学习方法通过一个演示数据集D来训练策略
具体而言,我们假设可以访问一个由成功的(即最终奖励为1) N个剧集组成的数据集
我们使用行为克隆来优化π,通过最小化给定图像和语言指令时动作的负对数似然
总之,RT-1接收一系列短暂的图像和自然语言指令作为输入,并在每个时间步骤为机器人输出一个动作,为了实现这一目标

- 首先,通过ImageNet预训练的卷积网络和通过FiLM预训练的指令嵌入来处理图像和文本
- 然后通过Token Learner计算一组紧凑的token
- 最后通过Transformer对这些token进行关注并产生离散化的动作token
这些动作包括七个维度的手臂运动(x, y, z, roll, pitch, yaw, opening of the gripper),三个维度的底座运动(x, y, yaw)和一个离散维度,用于在控制手臂、底座或终止情节之间切换
最终,RT-1进行闭环控制,并以3 Hz的速率执行动作,直到它产生“终止”动作或达到预设的时间步限制
1.2 模型架构
简言之,RT-1基于transformer的基础上,将图像历史记录和任务描述作为输入,直接输出标记化的动作,接下来,按照下图中的自上而下的顺序描述模型的组成部分
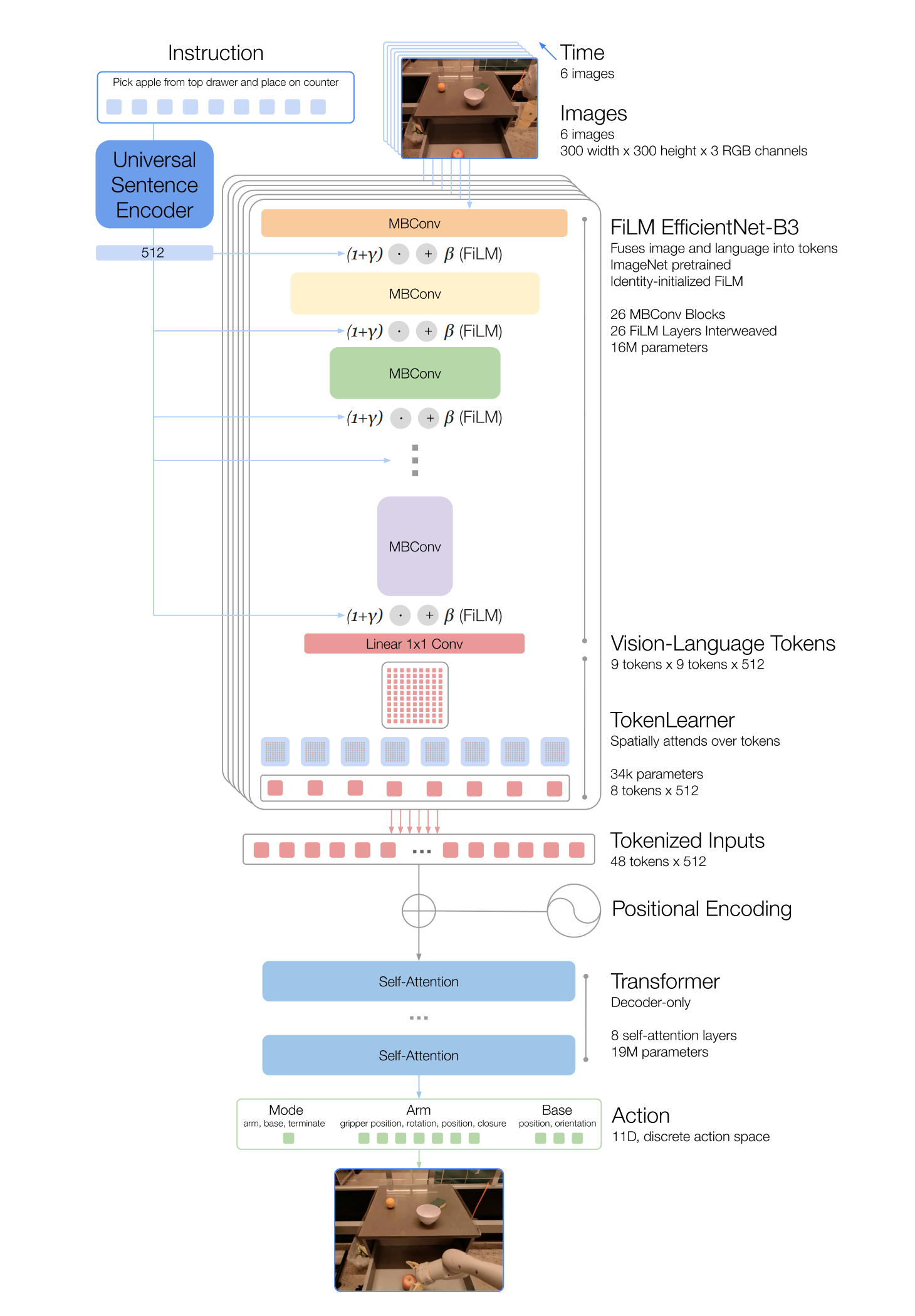
1.2.1 语言指令和图像的token化
RT-1架构依赖于对images和language instruction进行高效且紧凑的token化。 RT-1通过将images通过ImageNet预训练的EfficientNet-B3模型进行token化,将6个分辨率为300×300的图像作为输入,并从最后的卷积层输出形状为9×9×512的空间特征图(RT-1 tokenizes a history of 6 images by passingimages through an ImageNet pretrained EfficientNet-B3 (Tan & Le, 2019) model, which takes 6 images of resolution 300×300 as input and outputs a spatial feature map of shape 9×9×512 from the final convolutional layer.)
与Reed等人(2022)不同,我们不会将图像分块成视觉token,然后将其馈送到我们的Transformer主干中,相反,我们将EfficientNet的输出特征图展平为81个视觉token,然后将其传递给网络的后续,具体而言

- 为了包含语言指令(比如有的机器人模型比如Gato便不包含语言),我们将图像分词器(image tokenizer)与自然语言指令结合,以预训练的语言嵌入的形式进行条件处理,从而能够提取与任务相关的图像特征,并提高RT-1的性能
首先,通过通用句子编码器(Universal Sentence Encoder,by Cer等人,2018)对语言指令instruction进行嵌入(The instruction is first embedded via Universal Sentence Encoder)
- 通常情况下,在预训练网络的内部插入FiLM层会破坏中间激活,并抵消使用预训练权重的好处
为了克服这个问题,我们将生成FiLM仿射变换的密集层(和
)的权重初始化为零,使得FiLM层最初作为一个恒等变换,并保持预训练权重的功能
Normally, inserting a FiLM layer into the interior of a pretrained network would disrupt the intermediate activations and negate the benefit of using pretrained weights. To overcome this, we initialize the weights of the dense layers (fc and hC ) which produce the FiLM affine transformation to zero, allowing the FiLM layer to initially act as an identity and preserve the function of the pretrained weights.
我们发现,使用identity-initialized FiLM在从头开始初始化EfficientNet (没有ImageNet预训练)进行训练时,也能产生更好的结果,但并没有超过上述描述的初始化方法(We find that identity-initialized FiLM also produces better results when training with an EfficientNet initialized from scratch, without ImageNet pretraining, but it does not surpass the initialization described above)
图像分词器的架构如上图所示,最终通过FiLM EfficientNet-B3,RT-1的images和instruction tokenization总共有16M个参数,包括26层MBConv blocks和FiLM layers,输出81个vision-language tokens
1.2.2 Token Learner与Transformer解码
为了进一步压缩RT-1需要关注的token数量,从而加快推理速度,RT-1使用了Token Learner(Ryoo等,2021年)
Token Learner是一个逐元素的注意力模块,学习将大量token映射到较少的token中。 这使我们能够基于它们的信息对图像token进行软选择,仅将重要的token组合传递给后续的Transformer层
总之,TokenLearner的引入将经过预训练的FiLM-EfficientNet层输出的81个视觉token子采样到只有8个最终token,然后传递给我们的Transformer层

然后,每个图像的这8个token与历史中的其他图像连接起来,形成48个总token(且附加位置编码),以供RT-1的Transformer主干输入。Transformer是一个仅解码器的序列模型,具有8个自注意力层和19M个总参数,输出动作token
1.2.3 Action tokenization、Loss、Inference speed
为了对动作进行token化,RT-1中的每个动作维度都被离散化为256个箱子(To tokenize actions, each action dimension in RT-1 is discretized into 256 bins)
- 如前所述,我们考虑的动作维度包括七个变量,用于手臂运动(x, y, z, roll, pitch, yaw, opening of the gripper),基座的三个变量运动(x, y,偏航)和一个离散变量,用于在三种模式之间切换:控制手臂,基座或终止剧集
As mentioned previously, the action dimensions we consider include seven variables for the arm movement (x, y, z, roll, pitch, yaw, opening of the gripper), three variables for base movement (x, y, yaw) and a discrete variable to switch between three modes: controlling arm, base or terminating the episode. - 对于每个变量,我们将目标映射到256个箱子中的一个,其中箱子在每个变量的范围内均匀分布
For each variable, we map the target to one of the 256 bins, where the bins are uniformly distributed within the bounds of each variable.
此外,损失函数上,使用了先前基于Transformer的控制器(A generalist agent、Multi-game decision transformers)中使用的标准分类交叉熵熵目标和因果掩码
而推理速度上,与许多大型模型的许多应用不同,例如自然语言或图像生成,需要在真实机器人上实时运行的模型的一个独特要求是快速和一致的推理速度。考虑到执行指令的人类速度在这项工作中考虑的速度范围(我们测量为 2- 4秒),我们希望模型的速度不明显慢于此
根据我们的实验,这个要求对应于至少3Hz的控制频率,并且由于系统中的其他延迟,模型的推理时间预算要小于 100ms。这个要求限制了我们可以使用的模型的大小,最终采用了两种技术来加速推理:
- 通过使用Token-Learner(Ryoo等,2021)来减少预训练EfficientNet模型生成的令牌数量
- 仅计算这些token一次,并在未来的推理中重复使用它们。 这两种方法使我们能够将模型推理加速 2.4倍和 1.7倍
1.3 效果与不足
RT-1,使用包含超过130,000个示范的大型数据集对RT-1进行了训练,这些示范是在17个月内使用13个机器人收集的
- 证明了可以以97%的成功率执行超过700个指令,并且在任务、物体和环境的新情境中比先前发表的基准效果更好地进行泛化
- 还证明了RT-1可以成功吸收来自模拟和其他机器人形态的异构数据,而不会牺牲原始任务的性能,并且可以提高对新场景的泛化能力。
- 最后,我们展示了这种性能和泛化水平如何使我们能够在SayCan框架中执行非常长期的任务,最多可达50个步骤
虽然RT-1在数据吸收模型方面是迈向大规模机器人学习的一个有希望的步骤,但它也存在
一些限制
- 首先,它是一种模仿学习方法,继承了这类方法的挑战,比如可能无法超越示范者的表现
- 其次,对新指令的泛化仅限于先前看到的概念的组合,RT-1还不能泛化到完全没有见过的新动作
- 最后,现有的方法是在一组大型但不太灵巧的操作任务上展示的,后续计划继续扩展RT-1能够启用和泛化的指令集,以解决这一挑战
第二部分 RT-2:给VLM加上动作模态RT1,从而变成VLA
尽管之前的研究在包括机器人学在内的各种问题和设置上研究了VLMs,但Google
- 一方面,为了赋予VLMs预测机器人动作的能力,以来扩展其在机器人闭环控制中的能力,从而利用VLMs中已有的知
- 识实现新的泛化水平(While prior works study VLMs for a wide range of problems and settings including in robotics, our focus is on how the capabilities of VLMs can be extended to robotics closed-loop control by endowing them with the ability to predict robot actions, thus leveraging the knowledge already present in VLMs to enable new levels of generalizatio)
- 二方面,更为了使得模型权重可以完全共享在语言和动作任务之间,而不需要引入仅针对动作的模型层组件(we leverage VLMs that generate language, and the unified output space of our formulation enables model weights to be entirely shared across language and action tasks, without introducing action-only model layer components)
故于23年7 月,Google DeepMind宣布推出RT-1的进化版(使用上一代机器人模型RT-1的数据进行训练,数据上虽然没变,但训练方法大大增强了):RT-2(项目地址:https://robotics-transformer2.github.io/,paper地址:https://robotics-transformer2.github.io/assets/rt2.pdf)
其将视觉文本多模态大模型VLM具备的数学、推理、识别等能力和机器人比如RT-1的操作能力结合到一块了
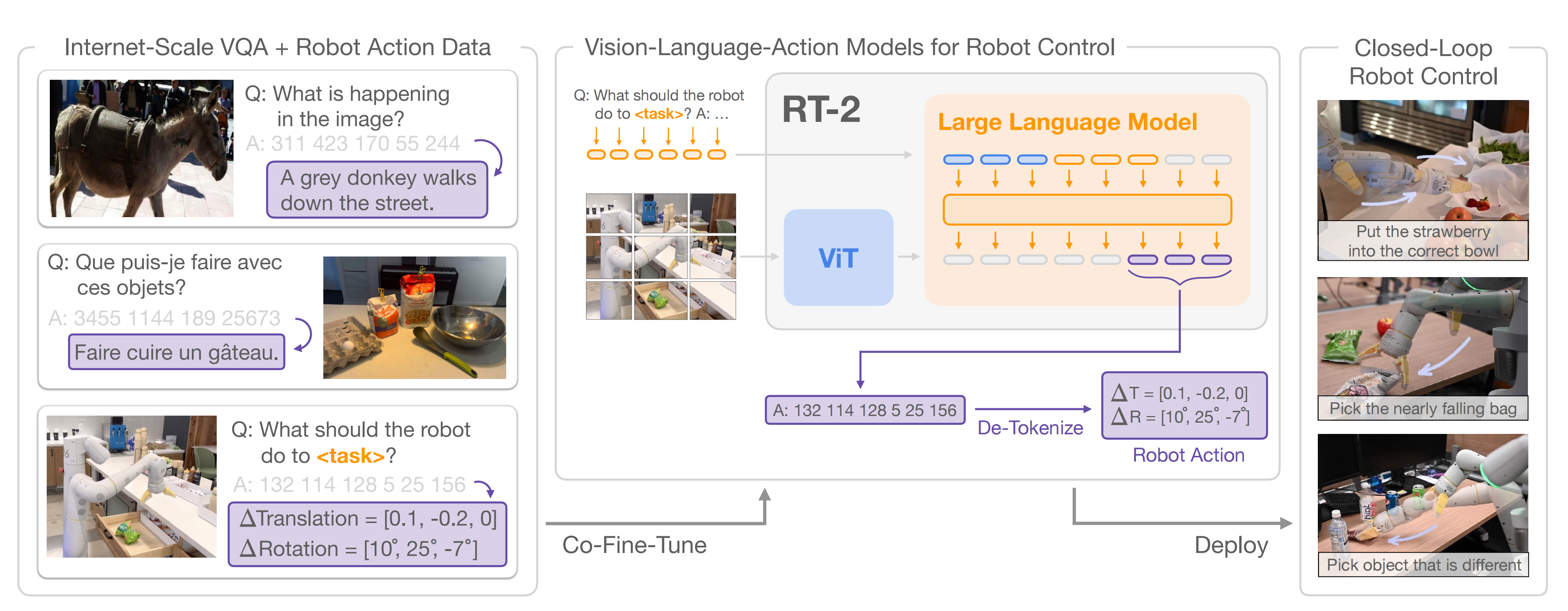
为了实现对「VLM之看听想」与「RT-1之操控」两者能力上的结合
- Google给视觉-文本大模型(VLM,比如5B和55B的PaLI-X、3B的PaLI以及12B的PaLM-E)增加了一个模态,叫做“机器人动作模态”,从而把它变成了视觉-文本-动作大模型(VLA),比如RT-2-PaLM-E和RT-2-PaLI-X
- 随后,将原本非常具体的机器人动作数据,转变成文本token,例如将转动度数、放到哪个坐标点等数据,转变成文本“放到某个位置”
这样一来,机器人数据也能被用到视觉-语言数据集中进行训练,同时在进行推理的过程中,原本的文本指令也会被重新转化为机器人数据,实现控制机器人等一系列操作
1.1 RT-2的三大能力:符号理解、推理、人类识别
其具备三大能力
- 符号理解(Symbol understanding),或者叫物体理解
能将大模型预训练的知识,直接延展到机器人此前没见过的数据上
例如机器人数据库中虽然没有“红牛”,但它能根据大模型预训练识所具备的知识中理解并掌握“红牛”的外貌,从而最终拿捏到所需物品 - 推理(Reasoning),这也是RT-2的核心优势,要求机器人掌握数学、视觉推理和多语言理解三大技能,比如


甚至能主动思考,比如给定指令「选择灭绝的动物」之后,它可以完成多个阶段的推理,从而最终抓取桌子上的塑料恐龙

- 人物识别(Human recognition)
比如只需要向对话一样下达命令:“将水递给泰勒·斯威夫特”,它就能在一堆图片中辨认出霉霉(Taylor Swift,美国当代歌手),送给她一罐可乐
1.2 VLMs for RT-2与机器人动作微调
1.2.1 VLMs for RT-2
- PaLI-X模型架构由ViT-22B组成,用于处理图像,可以接受
个图像序列,从而这
个token,其中
是每个图像的patches数量
The PaLI-X model architecture consists of a ViT-22B Dehghani et al. (2023) to process images, which can accept sequences of声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/413445
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

