
PyTorch单机多卡分布式训练(源代码讲解)_pytorch单机多卡训练
赞
踩
一、几个比较常见的概念:
rank: 多机多卡时代表某一台机器,单机多卡时代表某一块GPU
world_size: 多机多卡时代表有几台机器,单机多卡时代表有几块GPU
local_rank: 多机多卡时代表某一块GPU, 单机多卡时代表某一块GPU
单机多卡的情况要比多机多卡的情况常见的多。
DP:适用于单机多卡(=多进程)训练。算是旧版本的DDP
DDP:适用于单机多卡训练、多机多卡。
二、常见的多gpu使用方法:
模型并行和数据并行。模型并行是指将模型分成几个部分,然后在不同gpu上训练,适用于模型很大的情况;数据并行是指将数据分成几个部分,然后在不同gpu上训练,适用于数据很大的情况。一般我们见到的都是数据并行

三、解决两个问题
(1)解决问题一:数据集如何在多个gpu之间分配?两个工具:DistributedSampler,BatchSampler
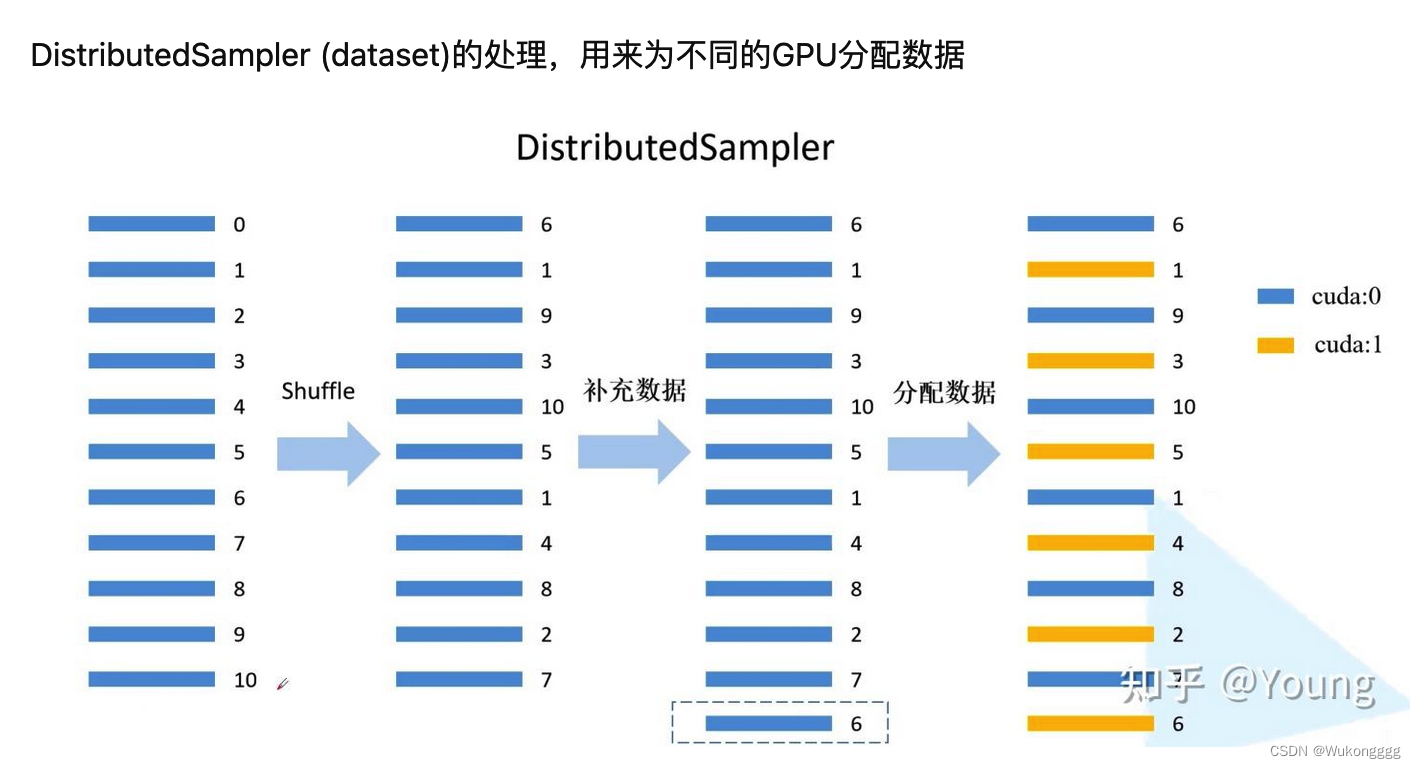
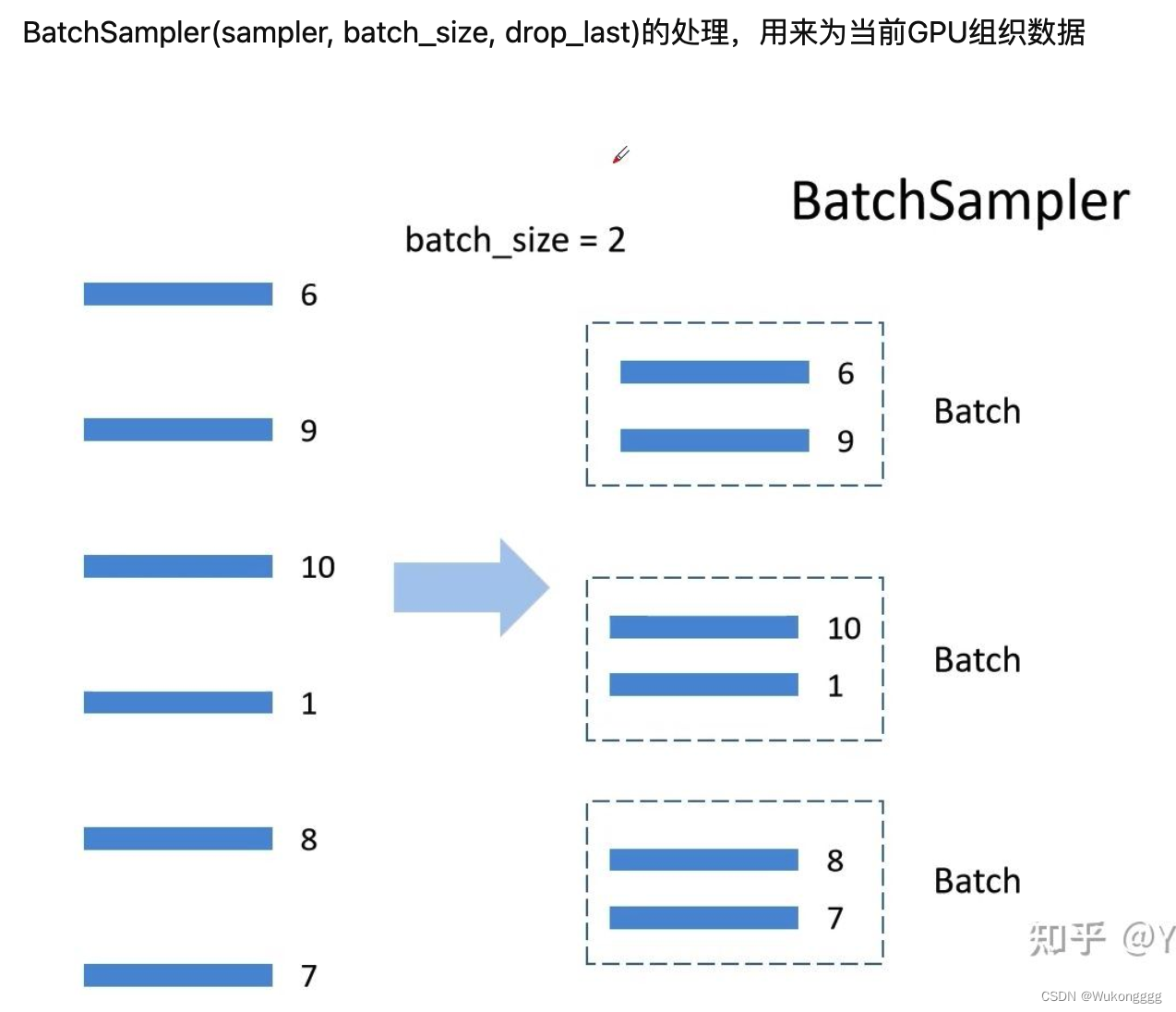
(2)解决问题二:不同gpu上训练的梯度,要在每一次迭代的时候求一次平均,并不是gpu各训练各的,涉及误差梯度如何在不同设备间通信
*同步bn:标准化需要有均值和方差,假设有两个gpu,分别为cuda0、1,每块gpu上训练的数据为bs=2,共有2+2=4。在bn层进行标准化时,要先计算每个gpu内部的均值和方差,再加和求得所有gpu的均值和方差—这种整体的均值和方差更接近真实数据集的均值和方差。只有当不冻结(冻结则只训练连接层,而连接层无bn层)、模型中有bn层时才适用同步bn。
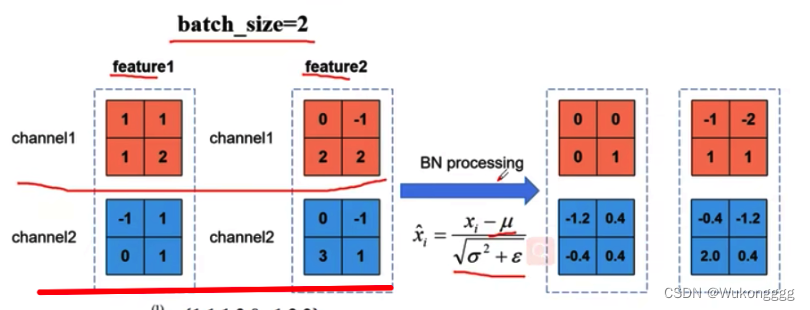
(bn层是让每个通道单独标准化,然后再叠放在一起)
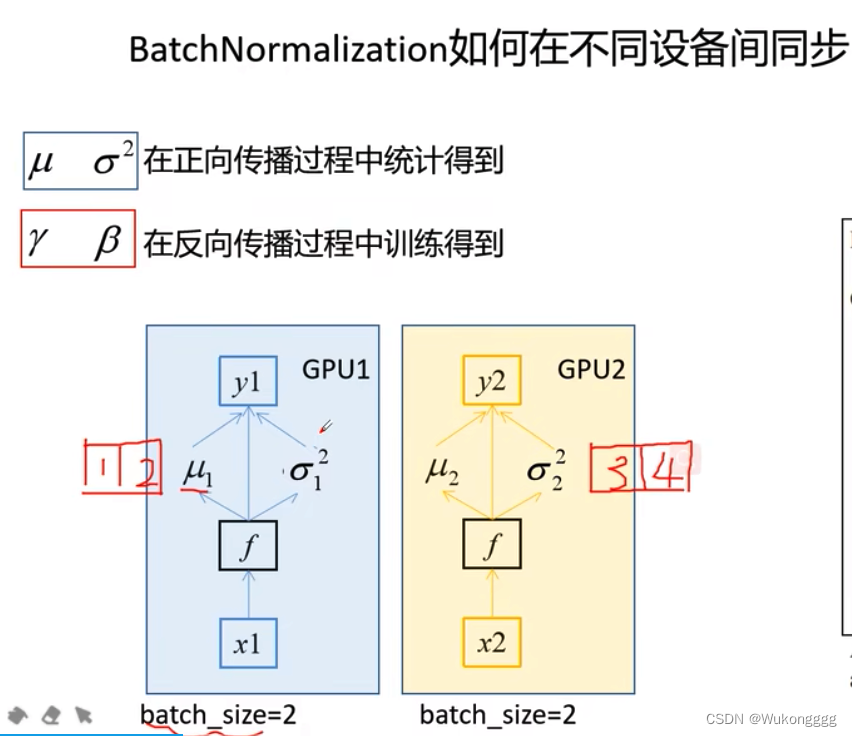
(不同gpu分别计算均值和方差,再求和反映数据集整体情况)
四、源码解读
1、源码见:GitHub - WZMIAOMIAO/deep-learning-for-image-processing: deep learning for image processing including classification and object-detection etc.
主要文件有:
train_multi_gpu_using_launch.py(主文件)
train_eval_utils.py(定义了train_one_epoch、evaluate两个重要方法)
distributed_utils.py(一些工具函数)
2、下面开始从train_multi_gpu_using_launch.py开始讲解:
步骤如下:
1、传入参数(num_classes;epochs;batch-size;lr;lrf;syncBN;weights;freeze-layers;device;world-size;dist-url)
dist-url: 分布式训练的url ,默认是env://
2、main方法:
init_distributed_mode初始化各进程环境:(rank、world_size、gpu+启动分布式模式args.distributed为True+对当前进程set_device指定使用的GPU+设置dist_backend为'nccl'+初始化进程组init_process_group+barrier同步所有的进程)
设置rank、device、batch_size、weights_path + 学习率lr要根据GPU的数量(ws)进行倍增 + checkpoint_path
在第一个进程中:SummaryWriter初始化tensorboard+如果没有权重文件./weights就新建一个
+划分数据集(train和val的图片路径、label路径)+确认参数类别数量是否与模型相等+实例化数据集dataloader
+多线程(workers)+DataLoader创建train_loader和val_loader+实例化模型
+实例化模型model,并将模型传送到gpu上 + 重头训练要让所有的gpu初始化参数一样,统一使用第一个进程的初始化参数 + 当训练所有层且有bn层时设置同步bn
+DistributedDataParallel转为DDP模型,使得模型能够在各个gpu设备中进行通信
+初始化optim + 初始化Scheduler + 遍历每个epoch(shuffle打乱顺序 + train_one_epoch见下方 + step学习率 + evaluate见下方,所有gpu预测正确的数量然后计算准确率)
+tb_writer打印第一个GPU的信息 + 删除临时缓存文件(checkpoint_path) + cleanup销毁进程组
train_multi_gpu_using_launch.py 代码如下:
- import os
- import math
- import tempfile
- import argparse
-
- import torch
- import torch.optim as optim
- import torch.optim.lr_scheduler as lr_scheduler
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
-
- from model import resnet34
- from my_dataset import MyDataSet
- from utils import read_split_data, plot_data_loader_image
- from multi_train_utils.distributed_utils import init_distributed_mode, dist, cleanup
- from multi_train_utils.train_eval_utils import train_one_epoch, evaluate
-
- def main(args):
- if torch.cuda.is_available() is False:
- raise EnvironmentError("not find GPU device for training.") #如果没有多gpu就会报错
-
- # 初始化各进程环境。init_distributed_mode函数见multi_train_utils/distributed_utils.py
- init_distributed_mode(args=args)
-
- rank = args.rank
- device = torch.device(args.device)
- batch_size = args.batch_size
- weights_path = args.weights
- # 学习率要根据GPU的数量进行倍增:在训练的过程中,损失梯度决定下降的方向,学习率决定下降的步长。如果有两块gpu,前进的综合步长为:平均学习率*2
- args.lr *= args.world_size
-
- checkpoint_path = ""
-
- if rank == 0: # 在第一个进程中:打印args参数信息,并实例化tensorboard,新建权重文件。通常保存、打印这些操作只用在第一个进程做就行了,其他进程不用做
- print(args)
- print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
- tb_writer = SummaryWriter() #初始化一个tensorboard
- if os.path.exists("./weights") is False: #如果没有权重文件就新建一个
- os.makedirs("./weights")
-
- #划分数据集(train和val的图片路径、label路径)+确认参数类别数量是否与模型相等+实例化数据集dataloader
- train_info, val_info, num_classes = read_split_data(args.data_path)
- train_images_path, train_images_label = train_info
- val_images_path, val_images_label = val_info
-
- # check num_classes
- assert args.num_classes == num_classes, "dataset num_classes: {}, input {}".format(args.num_classes,
- num_classes)
-
- data_transform = {
- "train": transforms.Compose([transforms.RandomResizedCrop(224),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
- "val": transforms.Compose([transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
-
- # 实例化训练数据集
- train_data_set = MyDataSet(images_path=train_images_path,
- images_class=train_images_label,
- transform=data_transform["train"])
-
- # 实例化验证数据集
- val_data_set = MyDataSet(images_path=val_images_path,
- images_class=val_images_label,
- transform=data_transform["val"])
-
- # DistributedSampler (dataset)的处理,用来为不同的GPU分配样本索引(注意,没法平分就会用第一个数据来补充)
- train_sampler = torch.utils.data.distributed.DistributedSampler(train_data_set)
- val_sampler = torch.utils.data.distributed.DistributedSampler(val_data_set)
-
- # 将样本索引每batch_size个元素组成一个list。BatchSampler用来为当前GPU组织数据(此处以bs=2为例)。drop_last=True为将剩下来未能形成整组的数据打包成一组(比如剩了一个数据落单,是要直接扔掉还是直接算成一组,用drop_last决定)
- #注意验证集数据无需经过BatchSampler。
- train_batch_sampler = torch.utils.data.BatchSampler(
- train_sampler, batch_size, drop_last=True)
-
- nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
- if rank == 0:
- print('Using {} dataloader workers every process'.format(nw)) #每个进程(process)中会使用几个线程(workers)来加载数据
- train_loader = torch.utils.data.DataLoader(train_data_set,
- batch_sampler=train_batch_sampler,#通过BatchSampler来采样
- pin_memory=True,
- num_workers=nw,
- collate_fn=train_data_set.collate_fn)
-
- val_loader = torch.utils.data.DataLoader(val_data_set,
- batch_size=batch_size,
- sampler=val_sampler, #val_sampler就只是经过了DistributedSampler
- pin_memory=True,
- num_workers=nw,
- collate_fn=val_data_set.collate_fn)
-
- # 实例化模型,并将模型传送到gpu上
- model = resnet34(num_classes=num_classes).to(device)
-
- # 如果存在预训练权重则载入
- if os.path.exists(weights_path):
- weights_dict = torch.load(weights_path, map_location=device)
- load_weights_dict = {k: v for k, v in weights_dict.items()
- if model.state_dict()[k].numel() == v.numel()}
- #遍历权重字典的每一层,然后再看权重的参数个数是否相同。结果就是全连接层的参数不符合,全连接层的权重不会被导入,因为本例中用到了预训练。
- model.load_state_dict(load_weights_dict, strict=False)
- else:
- checkpoint_path = os.path.join(tempfile.gettempdir(), "initial_weights.pt")
- # 如果不存在预训练权重,需要将第一个进程中的初始化权重保存,然后其他进程载入,保持初始化权重一致。
- # 注意,多gpu训练的时候,一定要保证所有进程的初始化参数时一样的,后面才能对所有进程求得的参数求和等等处理,得到整体数据的参数。
- if rank == 0:
- torch.save(model.state_dict(), checkpoint_path)
-
- dist.barrier()
- # 这里注意,一定要指定map_location参数,否则会导致第一块GPU占用更多资源
- model.load_state_dict(torch.load(checkpoint_path, map_location=device))
-
- # 是否冻结权重
- if args.freeze_layers: #只有连接层的参数要训练。
- for name, para in model.named_parameters():
- # 除最后的全连接层外,其他权重全部冻结
- if "fc" not in name:
- para.requires_grad_(False) #只有全连接层需要训练权重, para.requires_grad为true。其它层为false
- else:#所有层的参数都要训练。只有训练带有BN结构的网络时使用SyncBatchNorm才有意义,会将所有bn层变为具有同步功能的bn。
- if args.syncBN:
- # 使用SyncBatchNorm后训练会更耗时,对所有gpu上的batch计算均值和方差,再整体综合,再传递给下个batch。但会带来速度上的下降
- model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
-
- # 转为DDP模型:包装model,使得模型能够在各个gpu设备中进行通信。
- model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
-
-
-
-
- # optimizer
- pg = [p for p in model.parameters() if p.requires_grad] #遍历每一层。只有全连接层满足 if p.requires_grad。pg是输出的需要训练的参数
- optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005) #momentum动量;weight_decay正则项
- # Scheduler https://arxiv.org/pdf/1812.01187.pdf
- lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine余弦退火学习率
- scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
-
- for epoch in range(args.epochs): #迭代每一轮
- train_sampler.set_epoch(epoch)
- #set_epoch是官方定义的函数。使多个 epoch 的数据能够在一开始DistributedSampler组装的时候就shuffle打乱顺序。 否则,dataloader迭代器产生的数据将始终使用相同的顺序。
-
- mean_loss = train_one_epoch(model=model,
- optimizer=optimizer,
- data_loader=train_loader,
- device=device,
- epoch=epoch)
- # train_one_epoch函数见 multi_train_utils/train_eval_utils.py
-
- scheduler.step() #更新学习率
-
- sum_num = evaluate(model=model,
- data_loader=val_loader,
- device=device) #所有gpu预测正确的数量的总和
- #evaluate方法见multi_train_utils/train_eval_utils.py。
- acc = sum_num / val_sampler.total_size#正确数量/总数量=准确率
-
- if rank == 0:
- print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
- tags = ["loss", "accuracy", "learning_rate"]
- tb_writer.add_scalar(tags[0], mean_loss, epoch) #保存mean_loss到tb_writer
- tb_writer.add_scalar(tags[1], acc, epoch) #保存acc到tb_writer
- tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch) #保存lr到tb_writer
-
- torch.save(model.module.state_dict(), "./weights/model-{}.pth".format(epoch)) #保存当前epoch模型权重
-
- # 删除临时缓存文件:见上方,在选择预训练权重时,如果不预训练而是重头训练,将第一个进程中的初始化权重保存为checkpoint_path,为了所有gpu保持初始化权重一致。
- #该文件是临时文件,训练完可以删了
- if rank == 0:
- if os.path.exists(checkpoint_path) is True:
- os.remove(checkpoint_path)
-
- cleanup() #销毁进程组,释放资源。cleanup方法见multi_train_utils/distributed_utils.py
-
-
- if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--num_classes', type=int, default=5)
- parser.add_argument('--epochs', type=int, default=30)
- parser.add_argument('--batch-size', type=int, default=16)
- parser.add_argument('--lr', type=float, default=0.001)
- parser.add_argument('--lrf', type=float, default=0.1) #因子。最终结果是最初的0.1倍。
- # 是否启用SyncBatchNorm
- parser.add_argument('--syncBN', type=bool, default=True)
-
- # 数据集所在根目录
- # https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
- parser.add_argument('--data-path', type=str, default="/home/wz/data_set/flower_data/flower_photos")
-
- # resnet34 预训练官方权重下载地址
- # https://download.pytorch.org/models/resnet34-333f7ec4.pth
- parser.add_argument('--weights', type=str, default='resNet34.pth',
- help='initial weights path')
- parser.add_argument('--freeze-layers', type=bool, default=False) #是否冻结,冻结则仅仅训练全连接层。
- # 不要改该参数,系统会自动分配
- parser.add_argument('--device', default='cuda', help='device id (i.e. 0 or 0,1 or cpu)')
- # 开启的进程数(注意不是线程),不用设置该参数,会根据nproc_per_node自动设置
- parser.add_argument('--world-size', default=4, type=int,
- help='number of distributed processes')
- parser.add_argument('--dist-url', default='env://', help='url used to set up distributed training')
- opt = parser.parse_args()
-
- main(opt) #调用main方法,见上方

2.1 train_one_epoc model.train+CrossEntropyLoss+mean_loss清零+optimizer梯度清零+主进程设置进度条tqdm +遍历data_loader:(前向传播model获得pred,结合labels计算loss+对所有gpu上的loss进行求和得loss+整个训练过程的滑动损失均值mean_loss(返回出去)+在进程0中打印平均loss+无法收敛设置warning+step参数optimizer+optimizer参数清零) +synchronize同步多gpu进度
- def train_one_epoch(model, optimizer, data_loader, device, epoch):
- model.train()
- loss_function = torch.nn.CrossEntropyLoss()
- mean_loss = torch.zeros(1).to(device)
- optimizer.zero_grad() #清空优化器梯度信息
-
- # 在进程0中打印训练进度。单gpu即只有一个进程,该进程就是主进程。如果是多gpu中打印进度条,也只会在主进程中打印进度条,其他进程不会打印进度条
- if is_main_process():
- data_loader = tqdm(data_loader, file=sys.stdout) #tqdm用来添加一个进度提示信息
-
- for step, data in enumerate(data_loader):#enumerate返回值有两个,一个是序号,一个是数据(包含训练数据和标签),参数1是设置从1开始编号。每一步 loader (step)释放一小批数据(data)用来学习
- images, labels = data #遍历数据,分为图像、标签
-
- pred = model(images.to(device)) #图像传入设备,model前向传播得到输出。
-
- loss = loss_function(pred, labels.to(device))#输出和真实标签,求损失。此处的损失是当前gpu上,针对当前批次的batch计算出来的损失
- loss.backward() #反向传播
- loss = reduce_value(loss, average=True)#单gpu训练没有这一步。这一步是多gpu上,对所有gpu上的loss进行求和。
- #reduce_value函数见multi_train_utils/distributed_utils.py
- mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # 整个训练过程的滑动损失均值=在历史平均损失的基础上,加上最新损失再求平均
-
- # 在进程0中打印平均loss
- if is_main_process():
- data_loader.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))
- #为进度条tqdm增加前缀信息。 desc:进度条的描述信息,也称进度条的前缀
- if not torch.isfinite(loss): #如果损失无穷大,就会warning然后终止训练
- print('WARNING: non-finite loss, ending training ', loss)
- sys.exit(1)
-
- optimizer.step() #更新参数
- optimizer.zero_grad() #参数清空
-
- # 等待所有进程计算完毕:如果使用多gpu,要同步一下多个gpu之间的进度
- if device != torch.device("cpu"):
- torch.cuda.synchronize(device)
-
- return mean_loss.item() #返回该轮的平均损失值
2.2 evaluate model.eval+sum_num清零+在进程0中打印验证进度+ +遍历data_loader:(前向传播model获得pred,结合labels计算预测正确的个数sum_num) +synchronize同步多gpu进度+计算多gpu的所有正确个数sum_num(返回出去)
- @torch.no_grad()
- def evaluate(model, data_loader, device):
- model.eval() #验证模式
-
- # 用于存储预测正确的样本个数(每个gpu会独立计算分配到该设备上数据,预测正确的总个数)
- sum_num = torch.zeros(1).to(device) #默认为0
-
- # 在进程0中打印验证进度。同train
- if is_main_process():
- data_loader = tqdm(data_loader, file=sys.stdout)
-
- for step, data in enumerate(data_loader):
- images, labels = data
- pred = model(images.to(device))
- pred = torch.max(pred, dim=1)[1] #求得预测概率最大的数,其对应的索引
- sum_num += torch.eq(pred, labels.to(device)).sum() #eq使得相同为1,不同为0.sumnum为当前批次的相同的个数
-
- # 等待所有进程计算完毕
- if device != torch.device("cpu"):
- torch.cuda.synchronize(device)
-
- sum_num = reduce_value(sum_num, average=False) #多gpu下要取均值(所有正确样本个数的均值)
-
- return sum_num.item() #预测正确的数量的总和
学习率lr要根据GPU的数量(ws)进行倍增(图解)
reference:
PyTorch单机多卡分布式训练 - 知乎
pytorch多GPU并行训练教程_哔哩哔哩_bilibili。
(后续有空我会将代码上传至github)

