
热门标签
热门文章
- 1【C语言】每日一题,快速提升(1)!
- 2git修改了用户名和密码提示 Access denied 错误_git修改密码后拒绝访问
- 3【华为OD机考 统一考试机试C卷】开源项目热度榜单(C++ Java JavaScript Python C语言)_华为od机考 开源项目热度榜单
- 4git同步某一分支的指定提交版本到指定分支上_git推送特定版本到指定分支
- 5CV最新论文|4月10日 arXiv更新论文合集_员工管理制度
- 6Hadoop环境的安装及配置_hadoop 3.3.5 pubkeyauthentication yes
- 7Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!_stable diffusion运行提示expected all tensors to be on
- 8阿里Weex框架Android平台初体验_阿里 android 框架
- 9SpringCloud入门(微服务调用 OpenFeign)——从RestTemplate到OpenFeign & OpenFeign的相关配置 & 源码的分析和请求流程拆解_openfeign调用
- 10[管理与领导-102]:经营与管理的关系:攻守关系;武将文官关系;开疆拓土与守护城池的关系;战斗与练兵的关系;水涨船高,水落船低的关系。_管理之攻守战略
当前位置: article > 正文
主题模型简介(Topic Models)_主题模型由来
作者:我家自动化 | 2024-04-15 02:58:13
赞
踩
主题模型由来
主题模型简介(Topic Models)
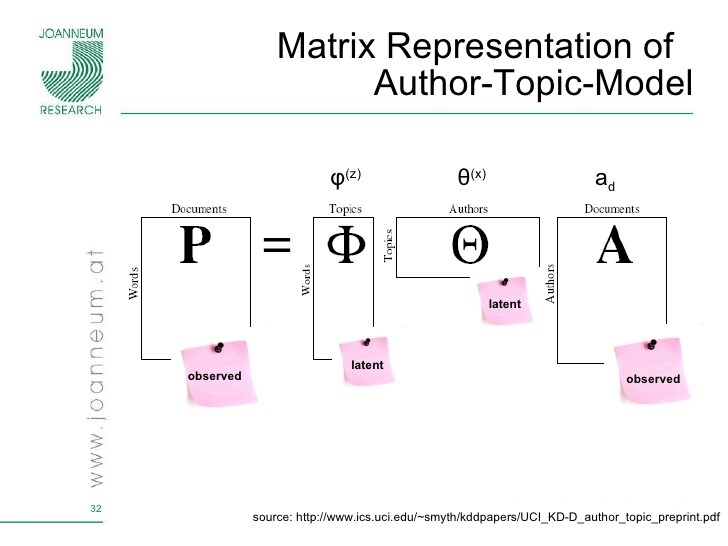

要想更好地管理当今爆炸式的电子文档档案,需要使用新的技术或工具来处理自动组织、搜索、索引和浏览大型电子文档集合。在当今机器学习和统计学研究的基础上,利用层次概率模型在文档集合中发现单词模式的新技术被开发出来。这些模型叫做“主题模型”。模式的发现往往反映了潜在的主题,这些主题被联合起来形成文档,例如分层概率模型很容易被推广到其他类型的数据中;主题模型被用来分析文字之外的很多东西例如图像、生物数据、测量信息和数据。
主题建模的核心在于发现单词使用的模式和关联具有相同模式的文档。所以,主题模型的思想是可以与文档一起工作的术语,而这些文档是主题的混合体,其中主题是单词上的概率分布。换言之,主题模型是文档的生成模型。它指定了一个生成文档的简单概率过程。通过选择一种主题分布来创建一个新的文档。随后,文档中的每个单词都可以根据分布随机选择一个主题。然后从主题中抽取一个单词。
主题建模始于一种称为潜在语义分析(LSA)的线性代数方法:找到文档术语矩阵的最佳低秩近似。虽然这些方法在最近几年重新兴起,但我们将重点放在概率方法上,它是直观的、工作良好的,并且很容易扩展(正如我们在后面的许多章节中看到的那样)。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/425499
推荐阅读
相关标签

