
- 1应届生简历怎么写?应届生制作简历注意事项有哪些?_应届生简历制作
- 2RSA中e n生成publicKey_n e 转 publickey
- 3Protecting World Leaders Against Deep Fakes(CVPR 2020)
- 4什么是人工智能?人工智能的本质是什么?
- 5sqlserver、mysql、oracle 的区别_mysql sqlserver oracle区别
- 6Mac更改网络设置时,要求频繁输入系统登录密码_networksetup正在尝试修改系统网络配置
- 7关于QGroundControl的软件架构的理解
- 8AAPT2 编译报错 AAPT2 error_aapt2.exe w 11-10 16:50:25 8592 17084 loadedarsc.c
- 9UI-1_layui和element ui区别
- 10H3C交换机MAC绑定
与Sora同架构!Stable Diffusion 3重磅发布!一切都更逼真了!
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!

整理 | 屠敏
转载自:CSDN(ID:CSDNnews)
大模型领域,每家公司都在争分夺秒。在文生图这条赛道上,面对 Midjourney、DALL-E 的围攻,2 月 22 日,初创公司 Stability AI 宣布推出下一代 AI 图像生成器——Stable Diffusion 3(简称 SD3),以开放权重的形式为图像带来高保真度。

提示词: 史诗级动漫作品:一位巫师在夜晚的山顶上向黑暗的天空施放宇宙咒语,咒语上写着“Stable Diffusion 3”,由五彩缤纷的能量组成

用上了和 Sora 同架构的 Stable Diffusion 3
时下 Stability AI 并没有发布有关 Stable Diffusion 3 的诸多细节,也没有带来最新的技术报告详解,但是这不影响它的一些亮眼表现。
其一,Stable Diffusion 3 模型的参数范围从 800M(小于常用 Stable Diffusion 1.5 版本)到 8B (大于 Stable Diffusion XL 版本)不等。
这一尺寸范围允许模型的不同版本在各个设备譬如从智能手机到服务器上本地运行。要想使用,你可能仍然需要一个强大的 GPU 和一个用于机器学习工作的设置。
其二,Stable Diffusion 3 之所以被称之为“最强大的文本到图像模型”,是因为自 Stable Diffusion 3 使用了类似 OpenAI Sora 的技术,即扩散 Transformer 架构。其中,“基于 Transformer 的可扩展扩散模型 DiT”由领导 Sora 项目成员之一的 Will Peebles 和纽约大学任助理教授谢赛宁二人于 2022 年首创,但是于 2023 年进行了修订,现在已经达到可扩展性。通过增加 Transformer 的深度和宽度,以及改变输入图像的分块方式,DiT 模型能够生成具有高质量和细节的图像。
基于此,Stable Diffusion 3 大大提高了多主题提示、图像质量和拼写能力(文字渲染)的性能。
除此之外,该模型还采用了“flow matching”技术。该模型可以通过学习如何从随机噪音顺利过渡到结构化图像来生成图像。它不需要模拟流程中的每一步,而是专注于图像创建应遵循的整体方向或流程,同样可以在不增加太多开销的情况下提高质量。
在 X 社交平台上,Stability AI CEO Emad Mostaque 也进一步补充道:
- 它使用了一种新型扩散 Transformer(与 Sora 类似),并结合了 flow matching 和其他改进。
- 它利用了 Transformer 的改进,不仅能进一步扩展,还能接受多模式输入。
- 更多技术细节即将发布
- 将以开放形式发布,预览版旨在提高其质量和安全性,就像稳定版一样
- 它将与完整的工具生态系统一起推出
- 这是一个利用最新硬件的新平台,有各种尺寸可供选择
- 支持视频、3D 等功能
- 需要更多 GPU
至于对于如何把控 Stable Diffusion 3 的安全问题,该公司在公告中写道:“我们相信安全、负责任的人工智能实践。这意味着我们已经采取并将继续采取合理的措施,防止坏人滥用 Stable Diffusion 3。当我们开始训练模型时,安全就开始了,并持续到测试、评估和部署的整个过程。为了准备这个早期预览版,我们引入了许多保护措施。通过与研究人员、专家和我们的社区不断合作,我们希望在模型公开发布时能够进一步诚信创新。”

同一提示词下,SD3 vs Bing(DALL-E)vs Midjourney
值得注意的是,在没有完全掌控 AI 工具之前,其背后的研发公司都不敢贸然将其开放。Stability AI 也是如此,所以想要尝试的小伙伴,需要先提交申请进入候补名单:https://stability.ai/stablediffusion3
我们也可以从 Stability 网站和相关社交媒体账户上发布的样本来看,其生成效果似乎与目前其他最先进的图像合成模型大致相当,包括业界已有的 DALL-E 3、Adobe Firefly、Imagine with Meta AI、Midjourney 和 Google Imagen。
从生成图片的效果上来看,过去排版一直也是 Stable Diffusion 的一个弱点,包括上述提及到几款文生图大模型最近也在致力于解决这个问题。在 Stable Diffusion 3 中,它提供了比之前更好的排版。
“这要归功于 Transformer 架构和额外的文本编码器,现在可以使用完整的句子和连贯的风格”,Emad Mostaque 说道。这一点也可以从下面示例中明显感知此模型的进化。
提示词:电影照片,教室的桌子上放着一个红苹果,黑板上用粉笔写着 "不成功便成仁"(go big or go home)。
不难看出 Stable Diffusion 3 生成的图片真的有电影的质感:
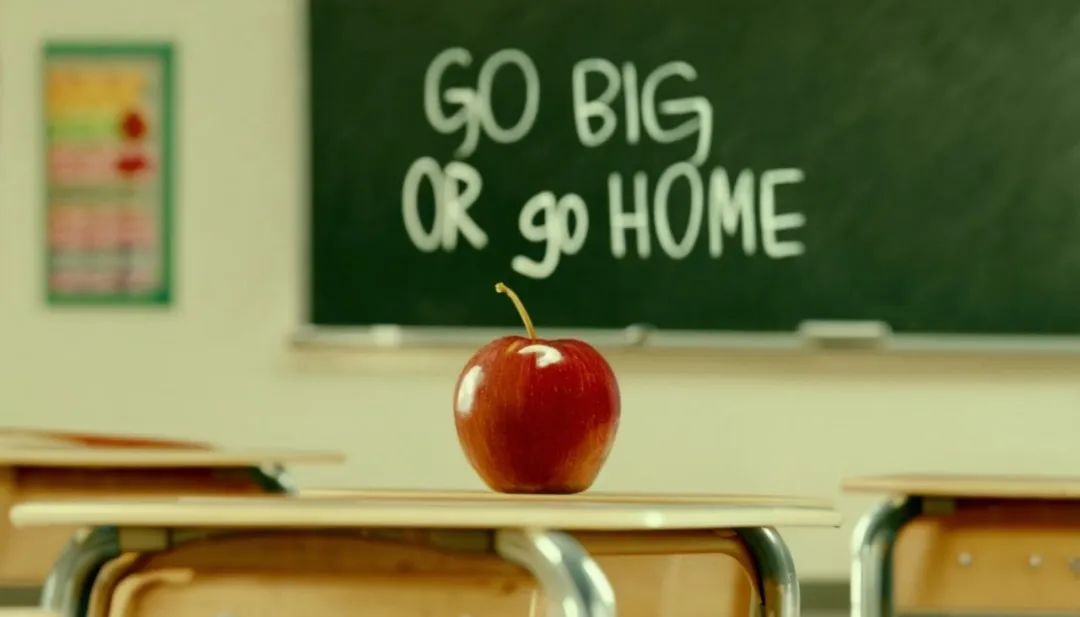
相同提示下 Midjourney v6.0 的表现:

提示:一幅画中包含宇航员骑着一只猪,穿着蓬蓬裙,撑着一把粉红色的伞,猪旁边的地上有一只戴着高帽的知更鸟,角落里有 "Stable Diffusion"的字样。
Stable Diffusion 3 自动调整,把"Stable Diffusion"的字样好似设置成了水印。

与 Bing 相同的提示:

同一提示下的 DALLE-3:

Midjourney 6:

提示:变色龙在黑色背景上的摄影棚照片特写
Stable Diffusion 3 非常生动:

也有用户直接分享了具有相同的提示 Gemini Advanced/Ultra 生成效果:

Stable Diffusion 3 也能够很好地处理很多文本:

提示:一张 90 年代台式电脑放在办公桌上的照片,电脑屏幕上写着“欢迎”。

DALL-E:

创作没有瓶颈,生成的图像和真实的相片难以分辨:



动画风格的同样不在话下:

对于未来,Stability AI CEO Emad Mostaque 还透露,在获得 SD3 这样的基础模型之后,接下来关于控制、组合、协作等多功能特性也会随之而至,正如下面视频所示,可以直接对图片中的某一个事物进行优化替换,未来可期!
最后,就在 Stable Diffusion 3 发布的同时,这一领域的重要参与者 Google 也宣布,因为在发现自家的大模型 Gemini 生成不准确的历史图像后,它将暂停该工具生成人物图像的功能。
这也引发了不少人的担忧,“这些东西变得越来越令人印象深刻(也更可怕)。不知道解决方案是什么,或者是否有解决方案,但我真的希望能够有一种方法来验证图像/视频是人工智能生成的。根据我对 Deepfakes 工作方式的理解,这基本上是不可能的(因为你用来检测人工智能的相同工具被用来确保它不会被检测为人工智能。)”。
至今为止,似乎的确没有什么准确的方法来辨别内容是否是 AI 生成的还是真实创作的,未来也需要技术、教育、法规等多方面的制度完善来规避诸多潜在的问题。
整体而言,Stable Diffusion 3 的落地,也让很多 AI 从业者倍感期待,“对于一直坚持使用文生图工具的用户来说,Stable Diffusion 3 看起来比 Midjourney V6 更好。它至少与 DALL·E 3 有部分相似之处,这对开放式设计来说可能是巨大的进步。”
还有网友评论道:“期待未来能出一个渲染中文文字的模型”。

对此感兴趣的小伙伴,也可以通过下方链接加入候选名单:https://stability.ai/stablediffusion3
来源:
https://stability.ai/news/stable-diffusion-3
https://twitter.com/StabilityAI/status/1760656767237656820
扩散模型交流群成立
- 扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
- ▲扫码或加微信号: CVer444,进交流群
- CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
-
- ▲扫码加入星球学习
- ▲点击上方卡片,关注CVer公众号
- 整理不易,请点赞和在看

