
- 1备战第15届蓝桥杯的同学注意了!蓝桥算法双周赛开始了!_第十五届蓝桥杯青少年
- 2git命令之fetch_your branch is up to date with 'origin/dev'.
- 3PyTorch小技巧:使用Hook可视化网络层激活(各层输出)
- 4【机器学习-周志华】学习笔记-第十二章
- 5大模型微调技术(Adapter-Tuning、Prefix-Tuning、Prompt-Tuning(P-Tuning)、P-Tuning v2、LoRA)_adapter tuning
- 6解决Expected all tensors to be on the same device, but found at least two devices, cuda:0
- 7全面解读:人工智能AI是什么_ai解读
- 8《算法设计与分析》复习
- 9【团队协作开发】从Gitee中克隆项目到IDEA并实现代码更新提交教程(新手)_怎么从gitee上拉取项目到idea
- 10计算机网络基础知识(五)——什么是TCPUDP协议?图文并茂的方式对两大传输层协议进行从头到尾的讲解_什么是tcp/udp协议栈
大数据之Hudi数据湖_基本概念_文件布局_存储方式_.parquet文件和.log文件_以及文件查找过滤方式_布隆过滤---大数据之Hudi数据湖工作笔记0006
赞
踩
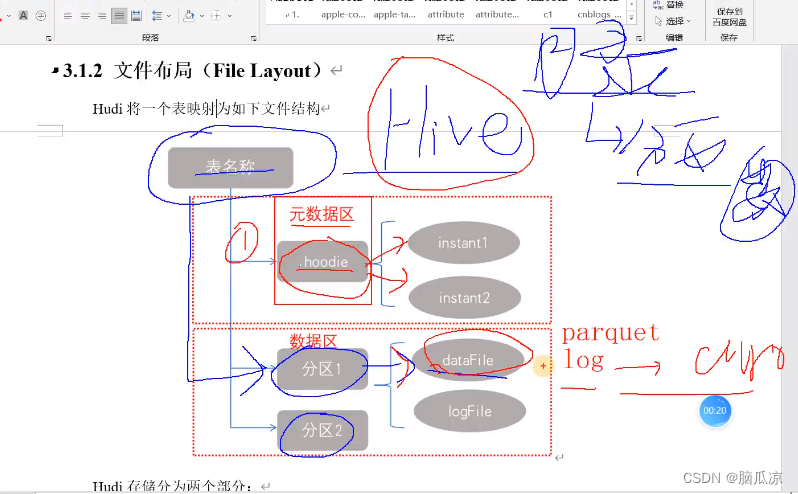
先来说一下,hudi的文件存储格式,首先跟hive一样,hudi,也是按照分区进行存储,
这里对于hive来说一个分区就是一个目录,那么在hudi中也是这样,一个分区一个目录,这个目录中放的只有两种文件,一种是列式存储的文件,parquet 文件 还有一种是行式存储的log文件,log文件用的是阿弗罗格式的,avro格式的文件.
然后在hudi中除了有分区以为,还有一个元数据,元数据是.hoodie格式的,元数据里面就包含了一个的instant 时刻对吧用来做timeline用的.
所以hudi中文件存储就是,一个表,对应数据区和元数据区,元数据区,就是存放了timeline信息的.hoodie文件.
然后数据区,就是按照分区,也就是按照目录存放的数据文件.
还有一点跟hive不同,hudi是用文件在自身存储的,这些分区数据和元数据,hive是依赖外部的比如mysql来存储这些信息的.所以这方面hudi会快一些.

然后我们去看一下,首先启动Hadoop集群,然后

去hdfs去看一下这些是hudi的表

我们打开一个表

可以看到表中有上面我们说的.hoodie这个元数据存储文件
还有2022 09-02 这个对吧,这个就是数据分区,当然这里
可以看到是按照天进行分区的

点击开一个数据分区我们进去看看 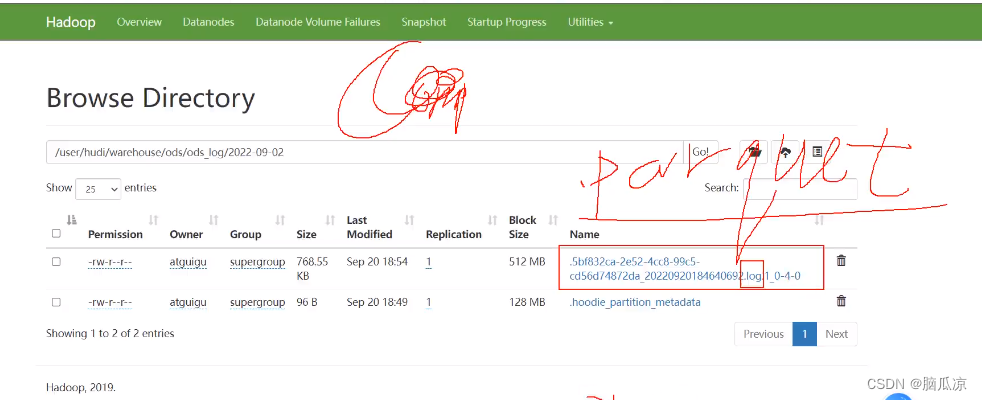
可以看到分区中,里面有个.log文件对吧里面是阿弗罗格式的数据avro
然后,其实还应该有个parquet格式的,列式存储数据
这个需要执行了competion合并操作以后才会有
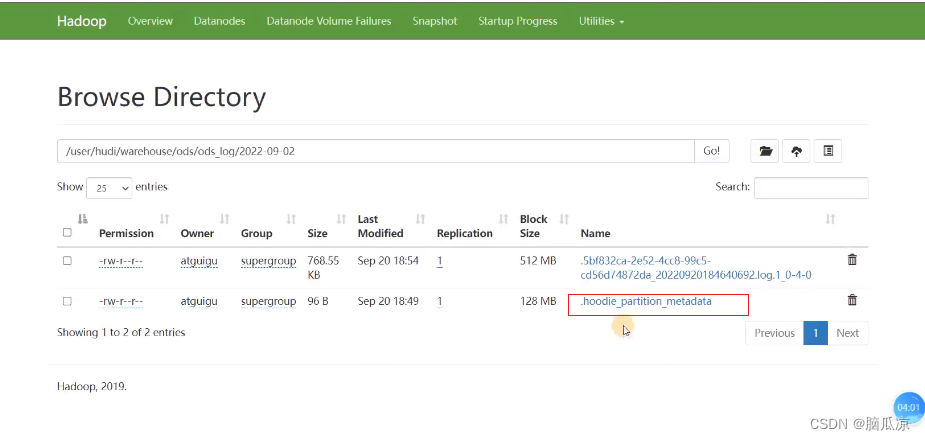
然后我们再看这里面还有个分区的元数据的一个数据
.hoodie_partition_metadata
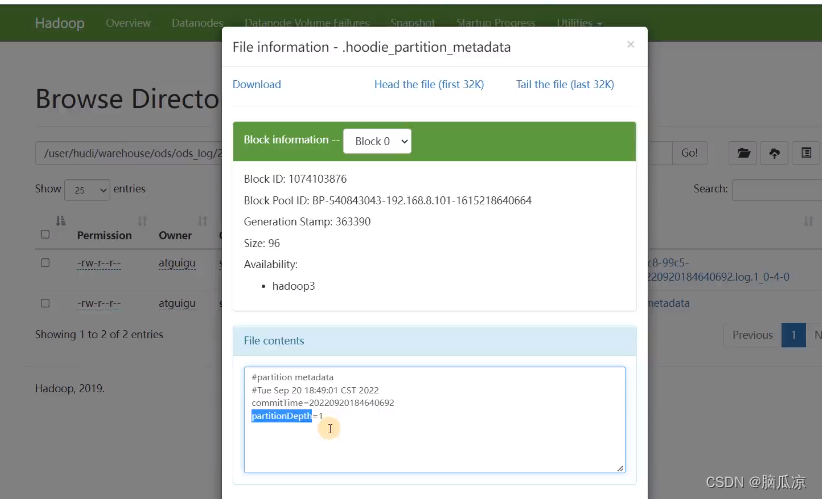
点开以后可以看到,里面存了,比如这个分区的创建时间对吧,还有
partitionDepth分区深度,因为可以有子分区,这里分区深度是1,没有子分区
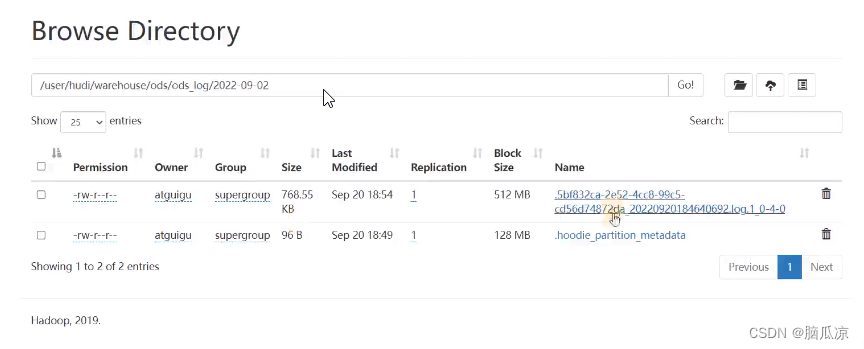
然后我们再打开log文件看看,

可以看到这个就是log文件中放的avro格式的数据了

然后我们再看看这个hoodie,元数据文件
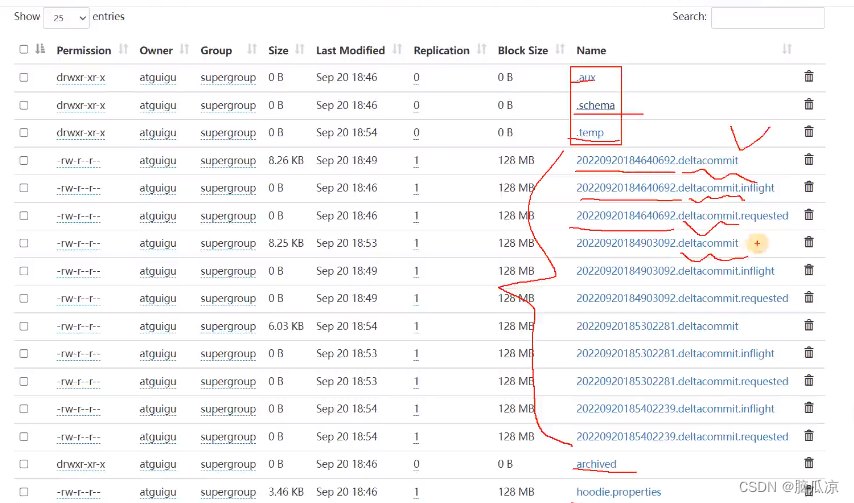
可以看到这个文件中有很多的文件对吧,这个文件其实就是timeline文件,
可以看到我们说INSTANT文件分为,action,time,state三个属性,可以看到
这里的比如第二个
20220920184640692.deltacommit.inlight
这里的20220920184640692就是当前时间精确到毫秒
deltacommit就是动作增量提交对吧
inlight就是状态,对应的几个状态之前博文有说

可以看到几乎就是三个状态,大小是0的两个,一个是开始提交

可以对应下这个状态.
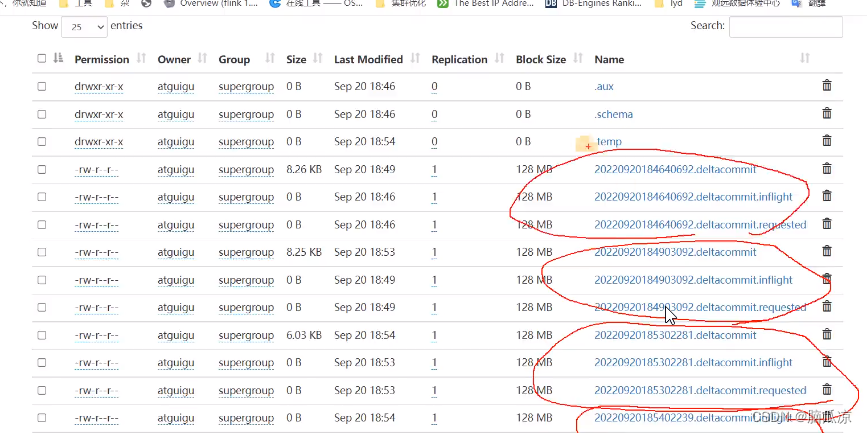
可以看到几乎都是3个状态对吧,那个,后面没有东西的
20220920184640692.deltacommit
这个就表示已完成那个状态了,可以看到文件大小内容也有了

然后我们就可以来总结一下,hudi的文件布局

可以看到hudi存储分两个不分,这里的元数据信息中,有个归档目录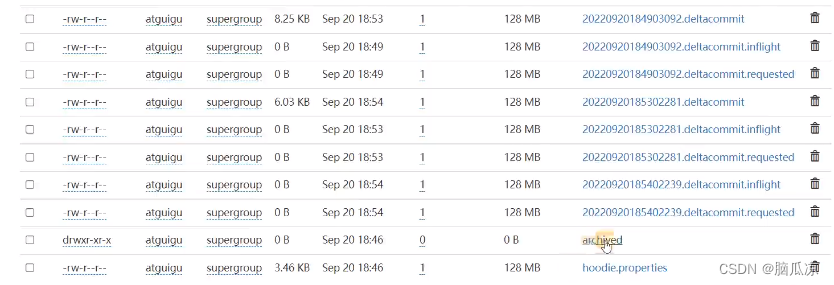
可以看到其实就是archived这个目录,其他的我们都已经上面说了.
然后我们再来看她的文件管理

可以看到hudi,将表对应的分区,比如上面是一个分区,我们知道一个分区中包含多个,.parquet类型的数据,和.log类型的数据文件
那么hudi会把这些.parquet文件和.log文件进行一下分组,一个组,就叫做一个FileGroup,
然后每个FileGroup都有自己的唯一的ID标识
然后一个FileGroup中可以包含多个FileSlice,表示一个个的文件分片,
那么一个文件片中再包含,就是包含.parquet和.log文件了
一个文件片中会包含一个.parquet文件和多个.log文件
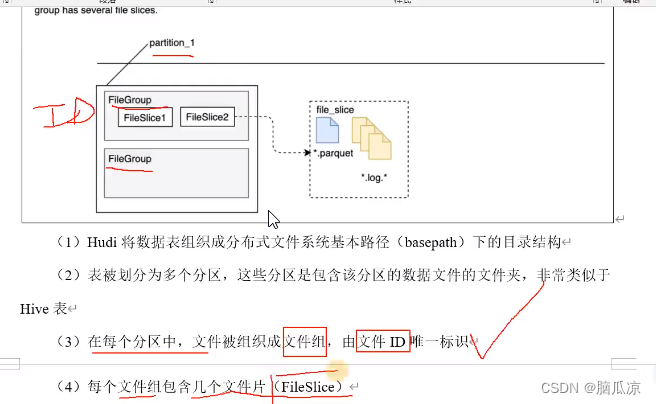
可以看到文件会被组织成文件组,对吧一个文件组都会有一个唯一的ID
可以看到一个分区中有多个文件组,然后每个文件组中,包含多个文件分片,上面的FileSlice1就表示一个文件片,然后对应的,fileSlice文件片中,包含的就是具体的,数据了,比如.log文件存放增量数据,这个.parquet文件存放具体的列式数据文件。

然后这里的.log文件要知道,实际上就是,存放,增量的信息,比如类似mysql的binlog一样,增删改的信息,然后COW,就是copy on write 就是复制的那些数据是没有这个log文件的.

可以看到。parquet文件和。log文件的介绍
这个.parquet表示的是.在某个时刻提交的所有的内容.当然如果文件合并也会产生一个包含合并后的最新的.parquet文件的
这个.log文件表示MOR表中的增量,增删改日志记录数据
注意这个MOR表是HUDI引入的一种新的表的类型.
这里的compaction操作:会合并.parquet文件和基本的log文件,产生新的文件片.
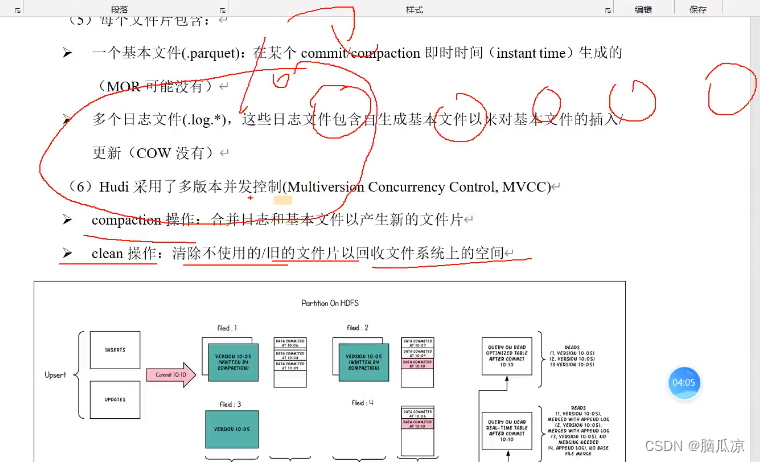
比如产生了10次合并,那么每一次会产生一个新的文件片,每个文件片,包含了之前所有的数据了,所以,旧的一些文件片,就可以根据策略回收

然后我们来看一下,hudi是如何来更新表的,这里他找某条数据,用的是布隆过滤
布隆过滤可以查看,一篇关于布隆过滤算法的文章,其他的博文:
积累工作中常见算法_布隆过滤器_Bloom Filter_你说有那不一定有_2023-10-18 11:21:55_定时更新_打个时间戳---算法面试题001

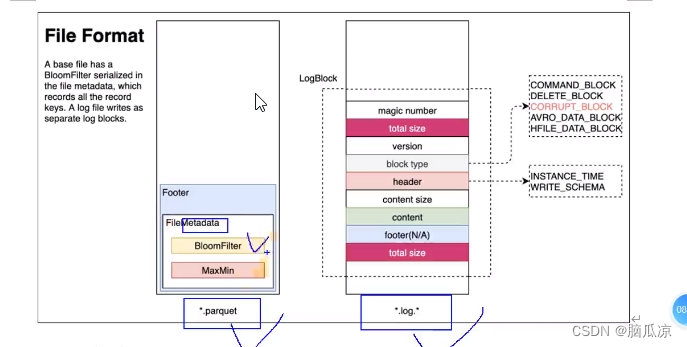
然后通过这个图我们可以清楚的看到.parquet文件和.log文件这两种文件的情况,可以看到这个.parquet文件中有个footer这个一看,用来记录了一个叫filemetadata数据,这个数据中记录了,
数据内容的查找方式,可以是BloomFilter对吧.
然后.log文件上面也提到了,可以包含什么信息,这里了解一下就可以了


