
- 1web server apache tomcat11-17-default-servlet
- 2MMagic调试(训练)dreambooth_dreambooth数据集
- 3国密算法介绍
- 4Git分布式版本控制工具----代码托管(包含IDEA中使用)_idea git托管
- 5MongoDB安装教程—Ubuntu_ubuntu安装mongodb
- 6Linux:退出vim编辑模式_linux强制保存退出vim
- 7LLaMA-Factory微调(sft)ChatGLM3-6B保姆教程_llama-factory 微调chatglm3-6b
- 8使用阿里云镜像加速Rust与Cargo安装及更新_rust 阿里云 jingxiang
- 9【无标题】一、Pycharm上传本地代码到github 1、点击左上角的File,选择Settings,然后选择Version Control,点击出现的GitHub,点击“Add account”。_pycharm add gitlab account
- 10LSTM预测算法(股票预测 天气预测 房价预测)
豆瓣图书统计可视化分析_图书评价数据集
赞
踩
s此博客是建立于爬虫基础之上,首先我们需要对豆瓣网站的图书进行爬取,这里将不再展示爬取部分,直接进行数据清洗及可视化分析部分。
一.准备数据集
数据集在下方链接当中,如需请自取。
https://pan.baidu.com/s/146N5YQfE0hkkYm2JOZQsEg
- import pandas as pd
- import numpy as np
- import re
- import openpyxl
-
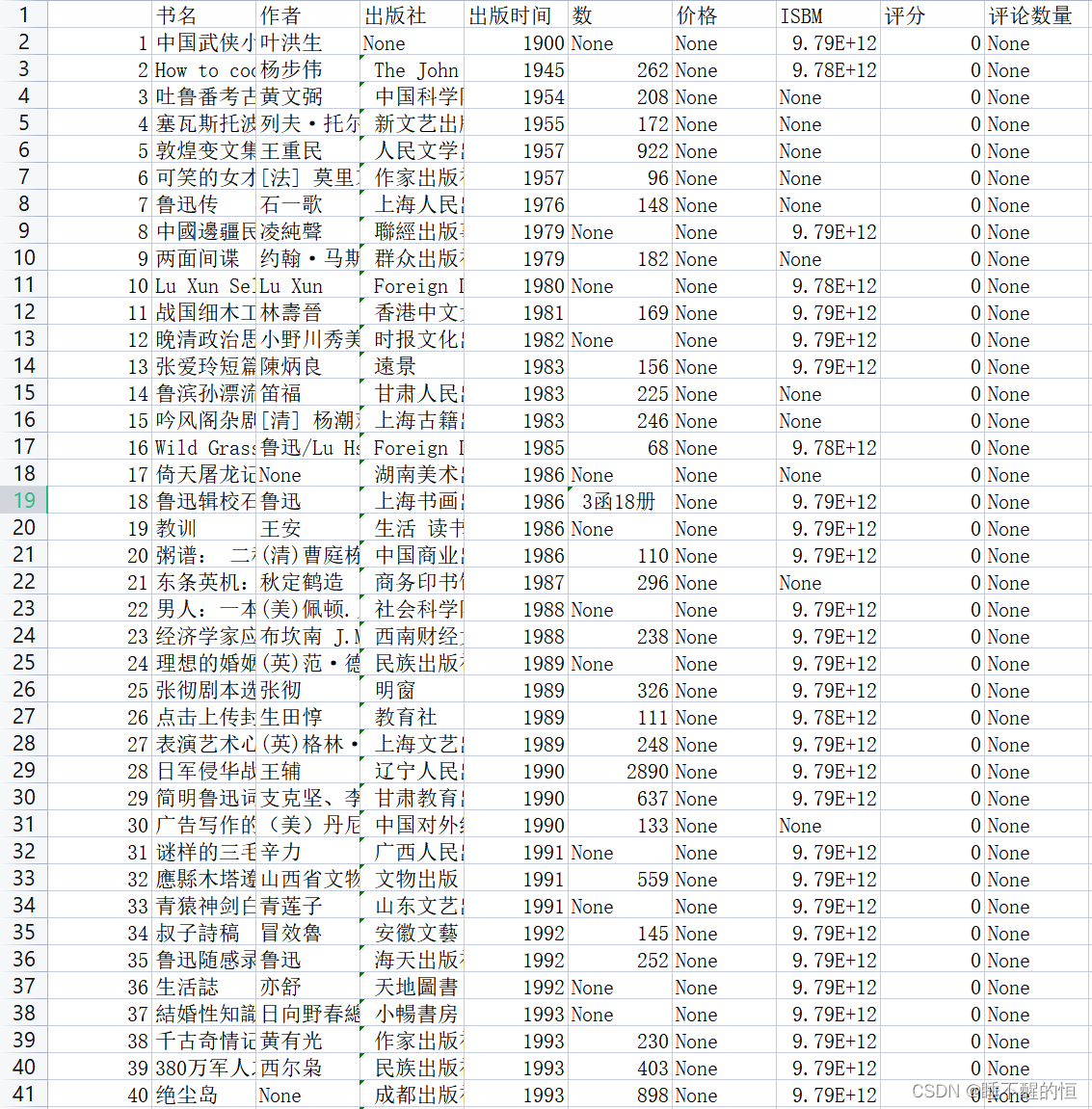
- df=pd.read_csv(r'book_douban.csv',index_col=0)
- print(df.head(10)) #打印前十行进行观察
输出结果:

二.数据清洗
大概流程如下:
在该数据集当中,因为存在大量“不规则”字符,我们在使用的第一步就需要将该大类数据清洗,并且补全一些缺失项数据。这样在接下来的分析及可视化过程当中才可以顺利进行。
1.重新命名
因为原数据集当中的第六列的标题为:“数”很抽象,所以我们的第一步清洗就将“数”重命名为“页数”
- df.rename(columns={'数':'页数'}, inplace=True)
- df.reset_index(drop=True, inplace=True)
- df.describe()
- print(df.iloc[:, 4])
输出结果:

观察可得,现在已经将“数”改为“页数”,接着我们将数据中的缺失值或空值删除或替换为其他值。
2.处理缺失值与空值
- #将'none'转换为null
- df = df.replace('None', np.nan)
-
- #查看缺失值情况
- print(df.isnull().sum())
-
- #去除'ISBM'列
- df = df.drop('ISBM', axis=1)
-
- #去除指定列含有空值的行
- df = df.dropna(subset=['作者','出版社','出版时间','页数','价格','评分','评论数量'], how='any')
-
- #重置索引
- df = df.reset_index(drop=True)
-
- #确认是否还有空值
- df.isnull().sum()

3.出版时间清洗

观察上述出版时间一列的数据可知,存在这许多不同的时间表达方式,但是为了之后对于时间的可视化描述,我们需要在这里对时间进行“归一”化。
代码如下:
- df['出版时间']=df['出版时间'].str.replace(' ','')
- for index,row in df.iterrows():
- num=re.findall('\d+',row[3])
- num=''.join(num)[0:4]
- df.iloc[index,3]=num
- # 将出版时间转换为整数型
- df.drop(df[df['出版时间'].str.len()!=4].index,axis=0,inplace=True)
- df['出版时间']=df['出版时间'].astype(np.int32)
- # 发现出版时间超出实际时间的数据,将其清除
- df.drop(df[df['出版时间']>2019].index,inplace=True)
3.检查页数一列的数据情况
清洗“页数”中存在乱码/不规则/标点情况
代码如下:
- df['页数'].str.contains('\.').value_counts()
- # 规范页数的格式,去除含有其他字符的数据比如‘.’
- df['页数']=df['页数'].apply(lambda x:x.replace(',','').replace(' ',''))
- df.drop(df[~(df['页数'].str.isdecimal())].index,axis=0,inplace=True)
-
- # 转换页数的格式
- df['页数']=df['页数'].astype(np.int32)
- df.drop((df[df['页数']==0]).index,inplace=True) # 清除页数为0的数据
4.对于评分,评论数量进行转型操作
代码如下:
- # 转换数据类型
- df['评分']=df['评分'].astype(float)
- df['评论数量']=df['评论数量'].astype(np.int32)
5.对于价格列的清洗
对于价格一列当中不是纯数据类型的数据全部剔除
- df['价格']=df['价格'].apply(lambda x:x.replace(',','').replace(' ',''))
- for r_index,row in df.iterrows():
- if row[5].replace('.','').isdecimal()==False:
- df.drop(r_index,axis=0,inplace=True)
- elif row[5][-1].isdecimal()==False:
- df.drop(r_index,axis=0,inplace=True)
对于价格小于1的数据剔除
df.drop(df[df['价格']<1].index,inplace=True)对于价格一列进行转型操作,更方便于计算。
df['价格']=df['价格'].astype(float)6.对于书名一列进行清洗
由于是汉语居多,所以我们此时只需清洗书名一样的数据
代码如下:
- df['书名'].value_counts()
- df['书名'].duplicated().value_counts()
- # 按照评论数量排名,然后去重,以保证数据可靠性
- df=df.sort_values(by='评论数量',ascending=False)
- df.reset_index(drop=True,inplace=True)
- # 对排序后的数据进行去重
- df.drop_duplicates(subset='书名', keep='first',inplace=True)
- df.reset_index(drop=True,inplace=True)
- # 查看是否还有重复的数据
- df['书名'].value_counts()
- # 清理后的数据
- df.to_excel(r'douban_book.xlsx',encoding='utf_8_sig')
-
输出结果:

7.出版书籍评分最高的为哪一个?
- #出版社评分最高计算:
- # 先统计各出版社的出版作品数量
- press=df['出版社'].value_counts()
- press=pd.DataFrame(press)
- press=press.reset_index().rename(columns={'index':'出版集团','出版社':'出版数量'})
- # 将出版作品数量大于200的出版社名称提取到列表中
- lst=press[press['出版数量']>200]['出版集团'].tolist()
- # 将列表中的出版社的作品平均分计算出来,并按照降序排序
- press_rank=df[df['出版社'].isin(lst)].groupby(by='出版社',as_index=False).agg(
- {'评分':np.mean}).sort_values(by='评分',ascending=False)
- # 保存为excel
- press_rank.to_excel(r'press_rank.xlsx', index=False, encoding='utf-8')
- # print(press_rank)
-
- # 打开xlsx文件
- workbook = openpyxl.load_workbook('press_rank.xlsx')
-
- # 选择需要读取数据的sheet
- sheet = workbook['Sheet1']
-
- # 读取第二行第二列的数据
- data1 = sheet.cell(row=2, column=1).value
- data_list = []
- for row in range(2, 7):
- data = sheet.cell(row=row, column=1).value
- data_list.append(data)
-
- # 输出读取到的数据
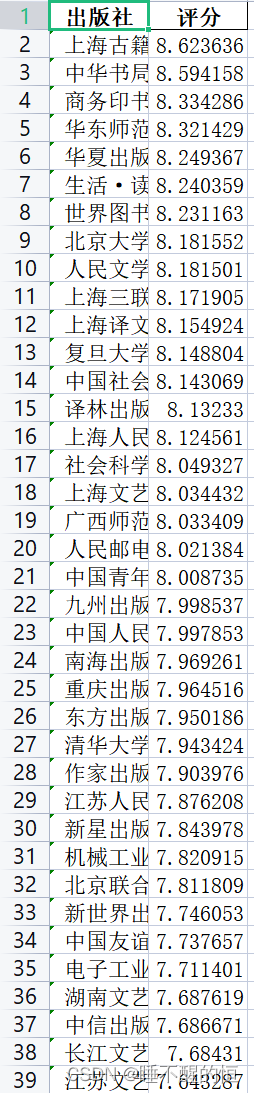
- print("出版社的书籍评分最高的为:",data1)
- print("排名表已经存于当前目录下press_rank.xlsx中")
- print("评分前五的出版社依次为:",data_list)
输出结果:

press_rank.xlsx:
8. 出版书籍最多的出版社是哪一个?
代码如下:
- df1=df[df['评论数量']>100]
- # 再提取出评分大于等于8的作品
- df1=df1[df1['评分']>=8]
- # 将过滤后的的作品按作者进行统计
- writer=df1['出版社'].value_counts()
- writer=pd.DataFrame(writer)
- writer.reset_index(inplace=True)
- writer.rename(columns={'index':'出版社','出版社':'发表数量'},inplace=True)
- writer.to_excel(r'chubanshe.xlsx', index=False, encoding='utf-8')
- workbook = openpyxl.load_workbook('chubanshe.xlsx')
-
- # 选择需要读取数据的sheet
- sheet1 = workbook['Sheet1']
-
- data2 = sheet1.cell(row=2, column=1).value
- data3 = sheet1.cell(row=2, column=2).value
- print("*************************************************************")
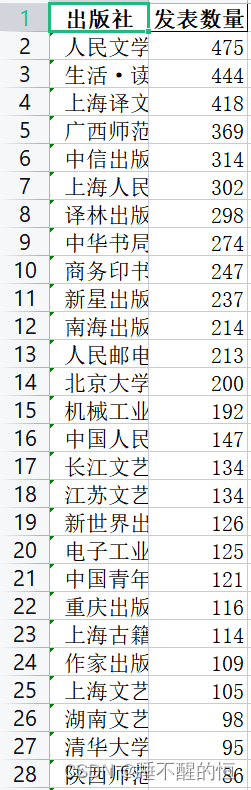
- print("出版书籍最多的出版社为:",data2)
- print("数量为:",data3)
- print("剩余排名可查看当前目录下chubanshe.xlsx")
输出结果:

chubanshe.xlsx:
9.价格最高的出版社是哪一个?
代码如下:
- df = pd.read_excel('book_douban1.xlsx')
-
- # 按照某一列进行排序
- df_sorted = df.sort_values('价格', ascending=False)
-
- # 将整体表格存入新的表格中
- df_sorted.to_excel('price.xlsx', index=False)
- workbook1 = openpyxl.load_workbook('price.xlsx')
-
- # 选择需要读取数据的sheet
- sheet2 = workbook1['Sheet1']
-
- data5 = sheet2.cell(row=2, column=1).value
- data7 = sheet2.cell(row=2, column=6).value
- print("*************************************************************")
- print("价格最高的出版社为:",data5)
- print("价格为:",data7)
输出结果:

三:可视化部分
这里将演示最简单的柱形图可视化,进阶可视化图将陆续更新。
对评分前 5名的出版社每年出版的图书数量画图进行比较分析。
代码如下:
- import openpyxl
- from collections import Counter
- import matplotlib.pyplot as plt
- from matplotlib import rcParams
-
- rcParams['font.sans-serif'] = ['SimHei'] # 设置正常显示中文标签
- rcParams['axes.unicode_minus'] = False # 解决负数坐标显示问题
-
- # 打开xlsx文件
- wb = openpyxl.load_workbook('book_douban1.xlsx')
-
- # 选择第一个sheet
- sheet = wb.active
-
- # 定义函数,用于生成柱状图
- def bar_chart(title, publisher):
- # 遍历第三列,输出包含publisher的行
- lis = []
- for row in sheet.iter_rows(min_row=2, min_col=3, values_only=True):
- if publisher in row:
- lis.append(row[1])
- # 使用Counter类进行计数
- counter = Counter(lis)
- # 将计数结果转换为两个列表
- x = list(counter.keys())
- y = list(counter.values())
-
- # 使用pyplot绘制柱状图
- plt.bar(x, y)
-
- # 添加图表标题和坐标轴标签
- plt.title(title)
- plt.xlabel('时间')
- plt.ylabel('出版数量')
-
- # 显示图表
- plt.show()
- # 调用函数生成各个出版社的柱状图
- bar_chart('上海古籍出版社', ' 上海古籍出版社')
- bar_chart('中华书局', ' 中华书局')
- bar_chart('商务印书馆', ' 商务印书馆')
- bar_chart('华东师范大学出版社', ' 华东师范大学出版社')
- bar_chart('华夏出版社', ' 华夏出版社')
-
-
-
-
-
结果展示:
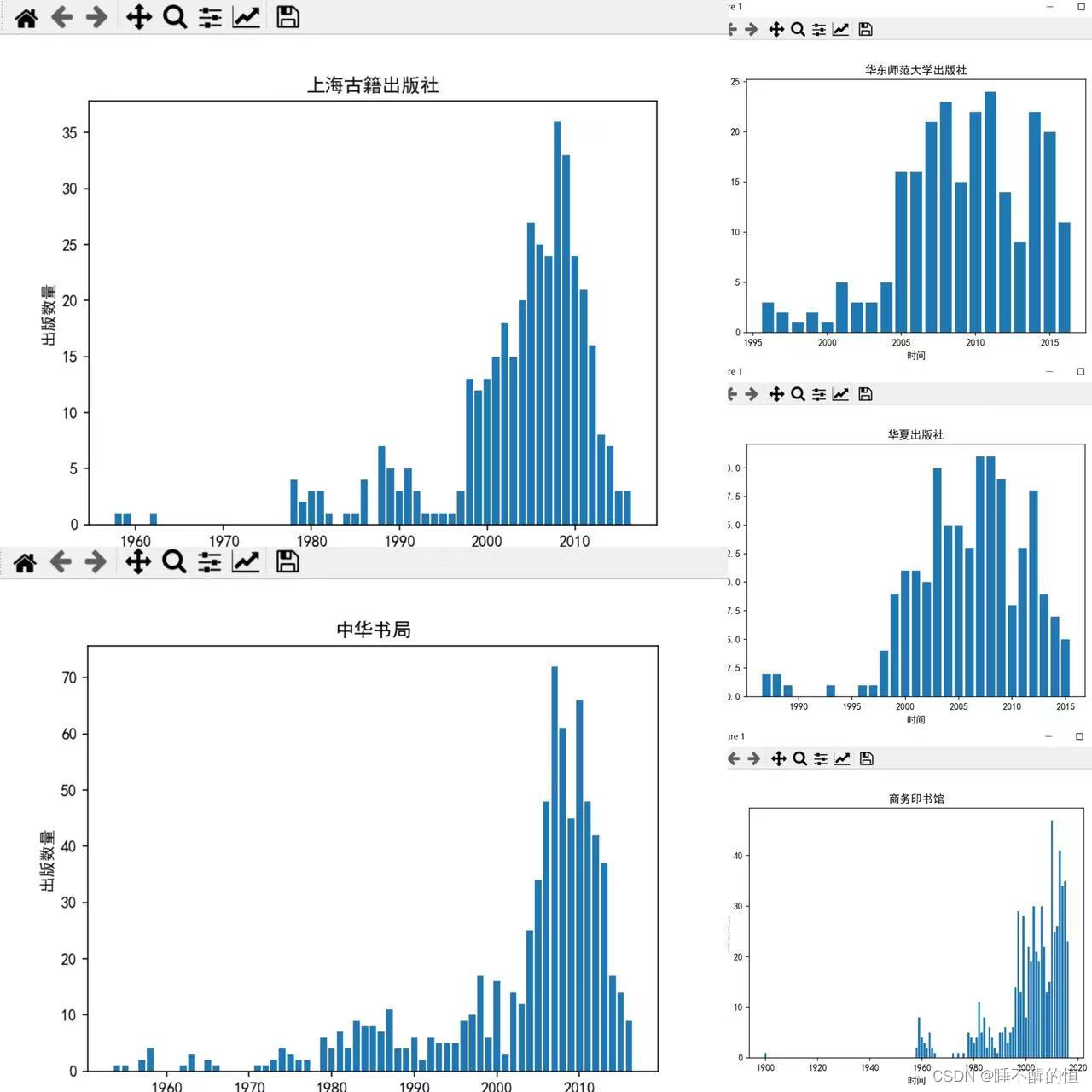
我采用最简单易懂的方式来绘制此柱形图,不会的朋友可以留言~

