- 1【深度强化学习】(3) Policy Gradients 模型解析,附Pytorch完整代码_policy gradient pytorch
- 2国外软件测试方法,ATE软件测试方法研究及实现
- 3自定义注解实现复杂情况的幂等校验(接口防重提交)_接口新增 幂等校验
- 420240114 每日AI必读资讯
- 5(附源码)计算机毕业设计SSM智慧景区一体化售票系统_公园售票系统流程图
- 6Redis 高可用与集群_高可用集群redis服务器
- 7猴子吃桃问题_猴子吃桃子10天问题
- 8牛啊牛啊!仅凭这份《Android核心面试题笔记》,去美团三面,已OC_美团三面android
- 9Python开发者年度调研:一半Python用户也用JS,2/3选择Linux系统
- 10基于Pytorch搭建分布式训练环境_pytorch 分布式环境的集群部署
【网安AIGC专题10.11】论文1:生成式模型GPT\CodeX填充式模型CodeT5\INCODER+大模型自动程序修复(生成整个修复函数、修复代码填充、单行代码生产、生成的修复代码排序和过滤)_codex+codet
赞
踩
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
10.11分享论文1:Automated Program Repair in the Era of Large Pre-trained Language Models
《llm在程序修复中的应用》
马兴宇学长分享论文,深入浅出,简洁明了
写博客记录这篇论文的分享
论文总结
主要是将主流的预训练代码专项的大模型应用到了代码修复领域,包括生成式大模型和填充式大模型
方法上并没有什么创新点,都是比较主流的模型和方法。
实验量比较大,涉及多个预训练模型的不同角度对比,包括代码修复准确率、代码生成结果的熵等等内容、以及与传统的NMT模型例如seq2seq等模型对比。
背景知识介绍
语言模型
类似于输入法,输入前几个字,自动推荐后面可能衔接哪些内容
现在主要的语言模型有单向语言模型和双向语言模型:
1、单向语言模型就是正向预测,即已知前面的文本信息预测下一个字。
按顺序处理输入文本的每个单词或字符,并依赖于先前处理的文本信息来预测下一个单词或字符。这种模型通常用于诸如序列标注、命名实体识别和文本分类等任务。
2、双向语言模型就是可以利用上下文信息来预测。
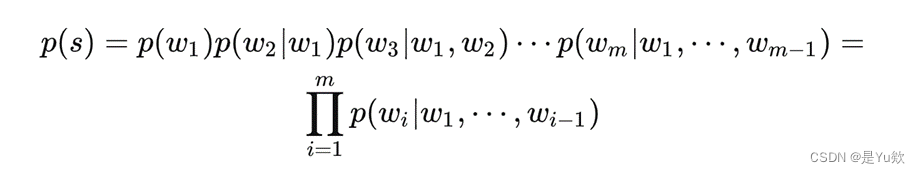
双向语言模型
双向语言模型适合做语言理解,不适合做生成任务。
双向语言模型有很多,最主流的双向语言模型BERT,后续的类似模型几乎都是基于该结构上调整,只是预训练目标不同
BERT也是最主流的掩码语言模型或自编码语言模型,主要基于Transformer的Encoder模块实现
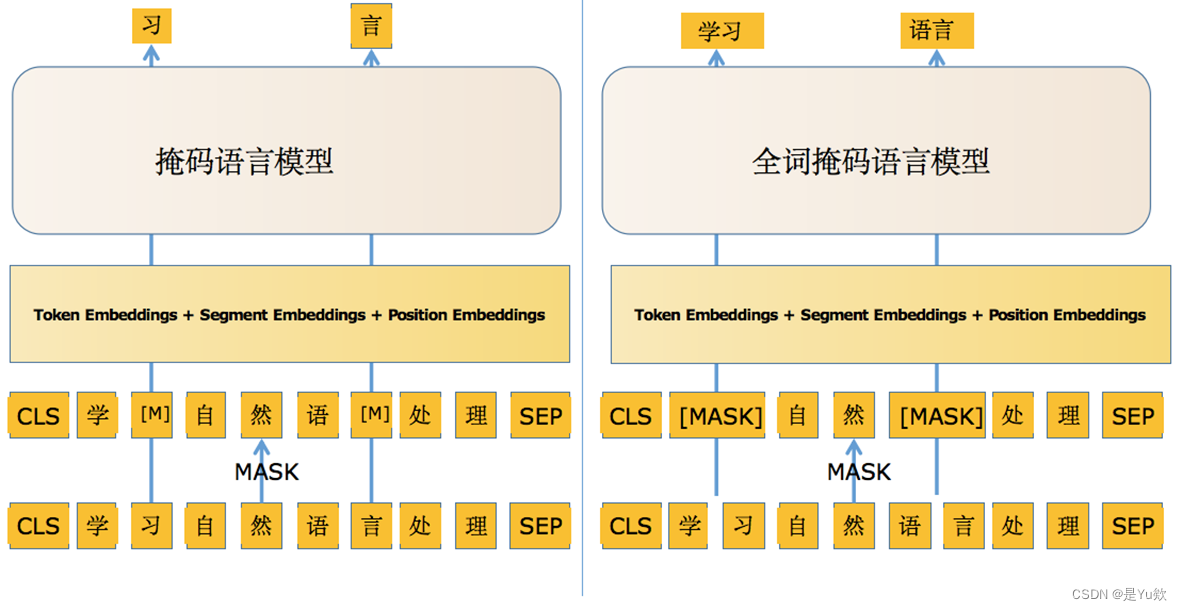
单向语言模型
目前比较主流的大模型都是基于单向语言模型,也就是Transformer的Decoder模块
因为单向语言模型更适合生成任务,而现在主流的大模型例如ChatGPT、LLAMa所执行的所有任务均可以被归类为生成任务。
基于Encoder和Decoder架构的预训练模型由于参数量和推理速度原因也很少被选择作为基座模型。
自动程序修复(APR)
技术
自动程序修复(APR):旨在帮助开发人员发现和修复程序中存在的漏洞,目前广泛使用的自动程序修复技术主要是基于专家手工指定的模板和基于学习方式的程序修复。
1)基于模板修复方式:比较依赖于专家手工制定的模板,而模板获取通常较难,且难以准确的设计。
2)基于学习的方式则需要依赖于大量的标注数据集,标注数据集的获取成本很高,也会对效果带来一定的影响。
发展
1、传统基于专家手工指定模板和规则
2、借鉴NMT方法,基于可学习的神经网络,训练修复模型,如Seq2Seq、Transformer等
3、基于预训练大模型,做有监督微调或者不训练模型直接做zero-shot、few-shot等任务,如代码专项模型:starcoder、codex、codeBert等
论文
概述
该论文将APR技术与LLMs进行结合,进行了广泛的研究,LLMs由于在海量数据上进行了训练,因此具备大量的知识,可以用来做zero-shot以及few-shot等工作,从而不需要训练就可以具备代码漏洞检测与修复功能,大大提升了代码修复与检测技术的效率。
论文选择了9个最新的LLMs,包括生成模型和填充模型,大小从125M到20B不等。设计了3种不同的修复方式来评估使用LLMs生成补丁的不同方式
1)生成整个修复函数:输入是一个有bug的函数,输出是修复后的函数
2)根据前缀和后缀填充代码块:也就是前面提到的预测mask位置的输出
3)输出单行修复
模型选择
生成式模型
GPT-Neo、GPT-J,GPT-NeoX、CodeX
填充式模型
CodeT5、INCODER、CodeX
方法
生成整个修复函数
生成整个修复函数就是将有bug的函数直接输入给模型,然后模型输出修复后的数据,但是由于预训练模型的预训练数据里没有APR数据,所有直接给喂数据,效果可能不好,所以作者又构建了前缀模板来做in-context learning,这里作者用的是one-shot

修复代码填充
作者参考掩码语言模型思路,将错误代码行视为mask然后使用掩码语言模型对mask位置进行预测,得到正确代码输出,掩码语言模型可以利用双向的上下文信息

单行代码生产
单行代码生成就是只生成错误地方的那一行代码
作者这里即用了:
1、上下文去预测掩码位置的输出
2、基于生成式的模型去生成单行,生成单行后就停止生成,然后拼接上后缀代码
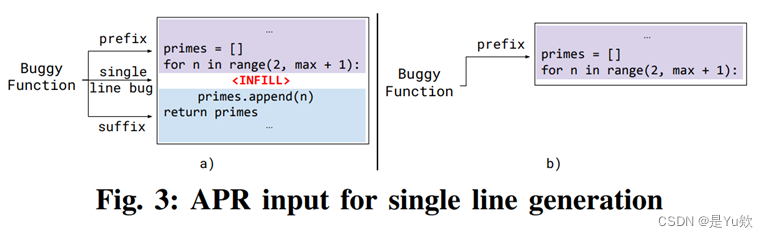
生成的修复代码排序和过滤
作者利用
1、预训练模型中默认的核采样参数,来生成多个修复后的代码
2、再利用熵来对生成的代码进行排序,熵可以代表生成代码的natural,作者选用熵低的,也就是生成的代码越符合人类思维。
3、最后再过滤掉编译失败的和语法错误的等数据
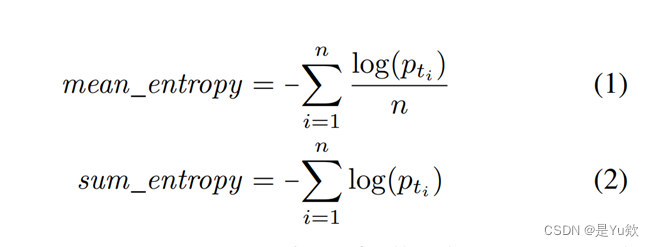
实验
实验数据集
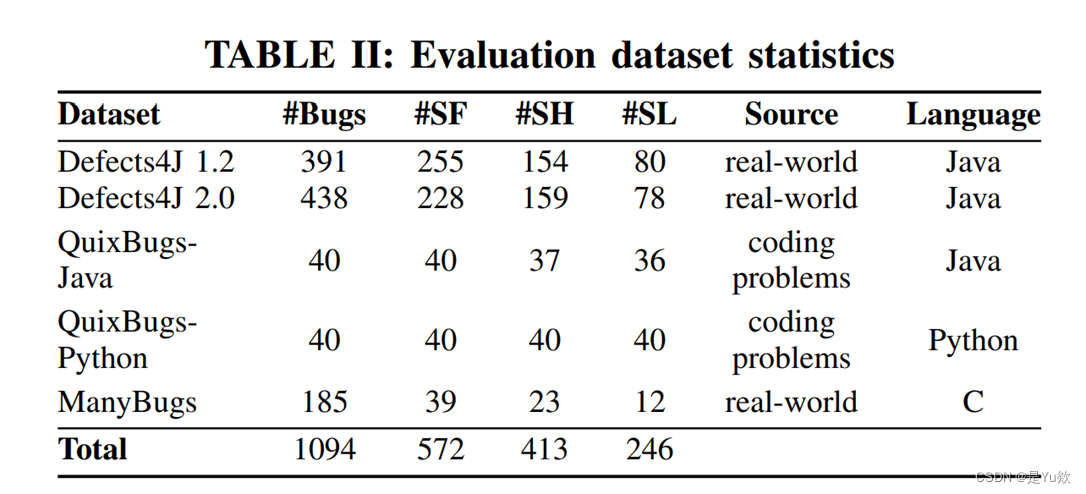
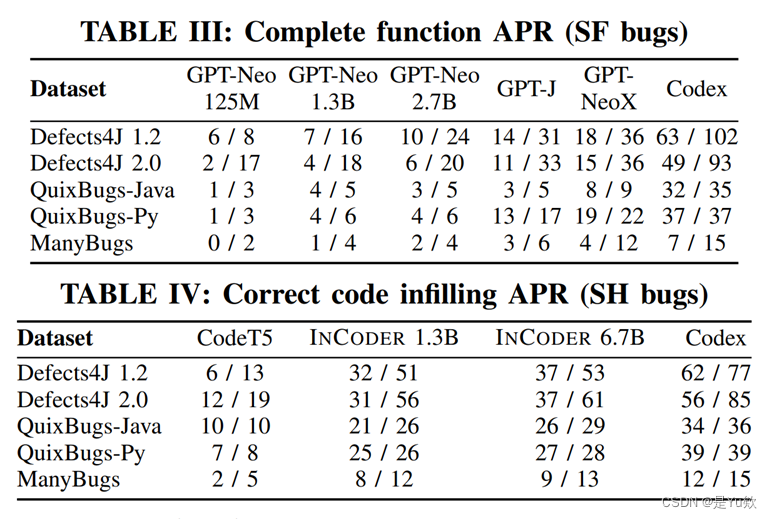
实验结果对比
实验量比较大,涉及多个预训练模型的不同角度对比,包括:
1、代码修复准确率
2、代码生成结果的熵等等内容
3、以及与传统的NMT模型例如seq2seq等模型对比
这里没有一一展示实验结果。