
- 1如何使用mysql ,建库,建表,案例。小张张带你0基础学习。_mysql建库建表样例
- 23分钟,利用ChatGPT4+剪映,快速制作短视频_chatgpt4.0制作视频
- 3Gitlab本地上传时,账号密码输入错误后,无法再次输入,错误详情:Authentication failed for ‘http://192.168.137.128:8090/root‘_git authentication failed之后如何重新输账号密码
- 4如何开发一个属于自己的人工智能语言大模型?_大语言模型智能体 应该怎么做
- 5axios的介绍及配置多个服务器url_使用axios请求多个服务器地址,如何设置baseurl
- 6spring boot: 使用MyBatis从hive中读取数据
- 7Docker搭建MinIO私有对象存储
- 8小程序 微信统计表格_秒应小程序群报名接龙表格
- 9android studio 下载gradle慢_gradle-8.4-src.zip
- 10django连接mysql数据库_django mysql
阿里云Stable Diffusion操作教程_阿里云stable diffusion模型云端
赞
踩
大家好,我是雄雄,欢迎关注微信公众号:雄雄的小课堂

前言
Stable Diffusion是⼀种深度学习模型,主要⽤于将⽂本描述转化为详细的图像,也可以应⽤于其他图像处理任务 。 这个模型由创业公司Stability AI 与学术研究者合作开发,使⽤了⼀种称为潜在扩散模型(LDM)的扩散模型。最近正好有个活动,参与体验了下阿里云的Stable Diffusion,再此记录一下遇到的问题。
区域功能
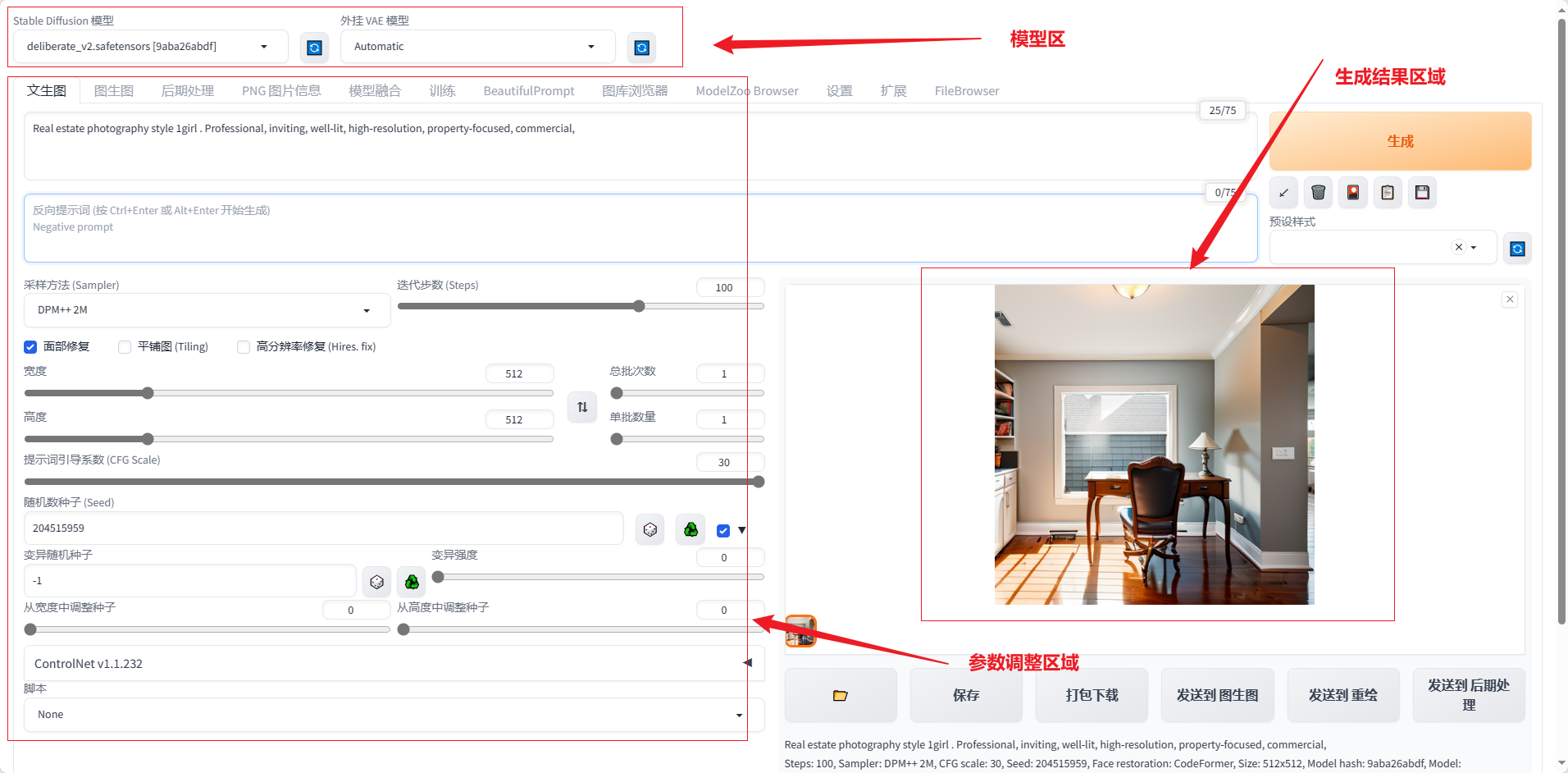
从大的方向,我们可以分为如上三个功能块,分别为:模型区、参数调整区以及生成结果区域,下面我们来分别看一下以上三个区域功能如何使用,尤其是参数调整区,核心中的核心,参数调好了,结果就是想要的,参数调整不好了,结果奇丑无比。
何为prompt?
- 在⼈⼯智能领域,Prompt 是⼀个⾮常重要的概念。它是⼀段⽂本或语句,⽤于指导机器学习模型⽣成特定类型、主题或格式的输出。
- ⼴义的讲,Prompt是指⽤户输⼊的⽂本或图像信息,⽬的是知道模型根据⼀些特定的需求⽣成艺术作品。
- ⽂⽣图主要以⽂字来实现这个沟通过程,图⽣图还可以依赖图⽚来传达信息,但图⽣图中也需要⽤到⽂字信息,⽽且同样重要。
- Prompt 的主题⾮常⼴泛,可能包括作品主题、画⻛、形象特点以及⼀些具体包含的要素
- 不同的 Prompt 分别向AI描绘了画⾯⻛格、⼈物体貌、服饰特点、场景内容和⼀些额外的修饰性元素
对于自然语言上特化训练的模型,建议使用描述物体的橘子座位提示词,补课太过于复杂,不然机器不一定能理解,可能会导致在解析上出现偏差
注意
一般来说,靠前的词汇权重会高。所以,最想实现的效果,在最前面写上,紧接着后面跟上修饰词,多个提示提之间用英文的逗号隔开(逗号前权重高)
文生图
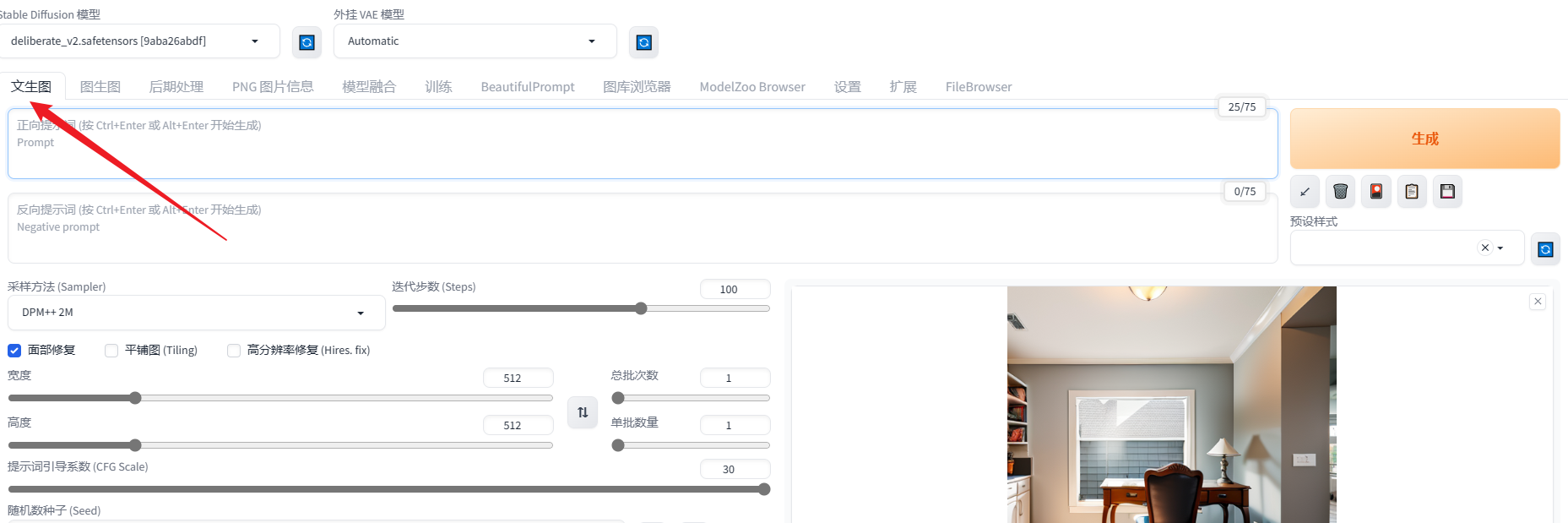
内容提示词
文生图的精髓在于提示词,提示词写的好,效果就越好,提示词写的不好,效果图就不好。
比如内容型的提示词,我们可以这样写:
1. 人物主体特征:
服饰穿搭 white dress
发型发⾊ blonde hair, long hair
五官特点 small eyes, big mouth
⾯部表情 smile
肢体动作 stretching arms
2. 场景特征:
室内、室外 indoor / outcloor
⼤场景 forest, city, street
⼩细节 tree, bush, white flower
3. 环境光照:
⽩天⿊夜 day / night
特定时段 morning, sunset
光环境 sunlight, bright, dark
天空 blue sky, starry sky
4. 画幅视角:
距离 close-up, distant
⼈物⽐例 full body, upper body
观察视⻆ from above, view of back
镜头类型 wide angle, Sony A7
5. 通用高画质
best quality, ultra-detailed, masterpiece, hires, 8k
6.特定搞分辨率类型
extremely detailed CG unity 8k wallpaper(超精细的8K Unity游戏CG)
unreal engine rendered (虚幻引擎渲染)
7.花粉提示词
插画风: ilustration, painting, paintbrush
二次元:anime, comic, gamre CG
写实系:photorealistic, realistic, photograph
温馨提示:”
必要的时候,可以借助chatgpt来实现提示词的罗列,比如:我们么想要绘制一幅女孩在咖啡馆里看书的画面,但不知道如何描述这个场景,那么我们借助chatgpt来提供灵感,如下:

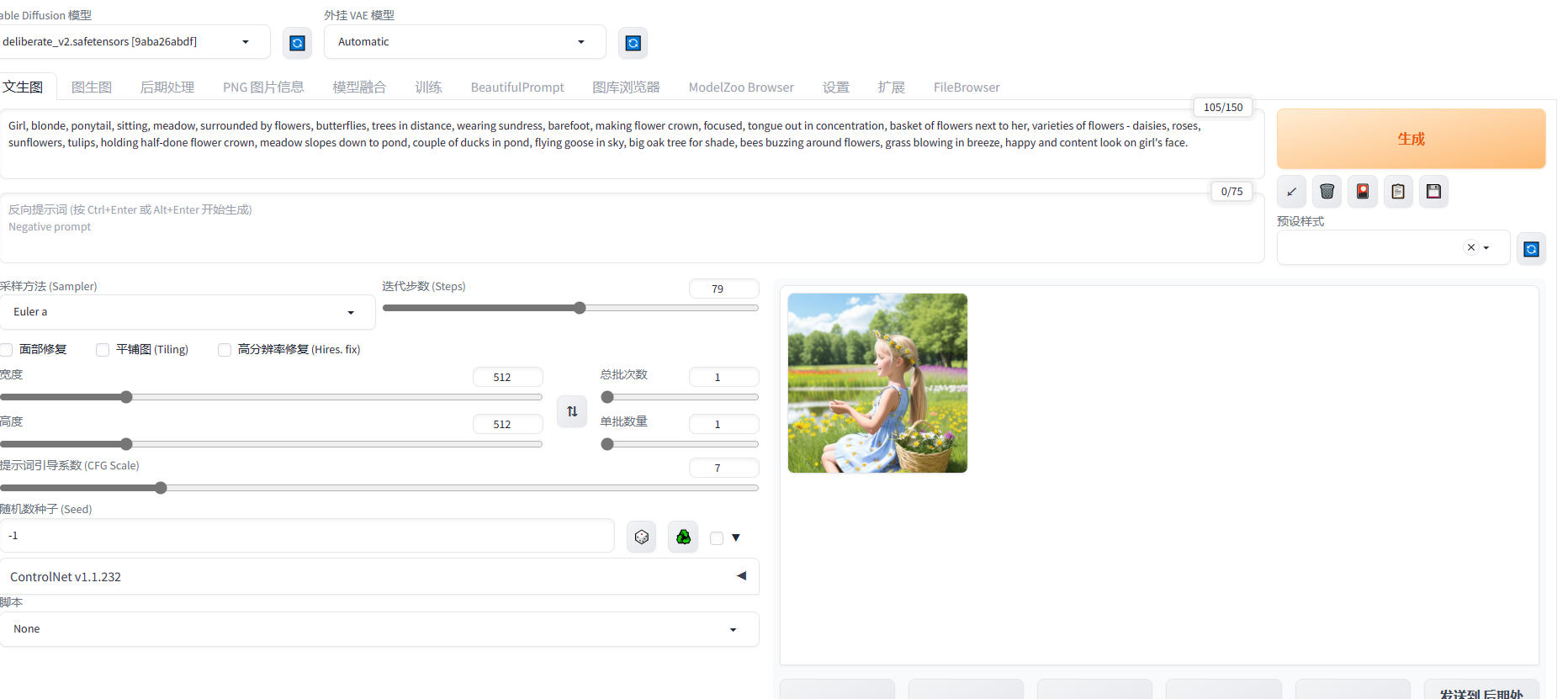

可以看出来,生成的内容,还是很不错的。
反向提示词
上面我们介绍了下正向提示词,但是我们可以看到界面上还有个反向提示词的概念,那么,什么是反向提示词?
正向提示词内输⼊的东⻄是想要⽣成的作品,
反向提示词内输⼊的是不希望画⾯⽣成的内容。
鉴于我们所使⽤的多种模型包含⼤量训练图⽚,其中可能存在⼤量低质量图像信息,因此我们需要通过输⼊反向提示词来排除这些内容。
我们可以将常见的一些反向提示词整理出来输入上去:
lowers, error, cropped, worst quality, low quality, jpeg artifacts, out of frame, watermark, signature
- 1
- 以任务肖像的反向提示词为例:畸形的,丑陋的,残缺的,毁坏的,不好的⽐例
deformed, ugly, mutilated, disfigured, text, extra limbs, face cut, head cut, extra
fingers, extra arms, poorly drawn face, mutation, bad proportions, cropped head, malformed limbs, mutated hands, fused fingers, long neck
- 1
- 2
- 照片类图片的反向提示词:插图 绘画 素描 艺术 草图
illustration, painting, drawing, art,
sketch
- 1
- 2
采样器
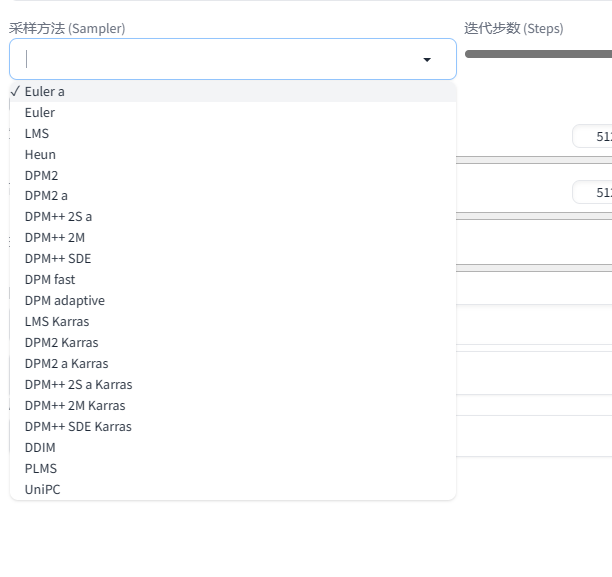
就是这个地方的选项,可以看到,有非常之多…一时都无从下手。其实我们常用的就三种,分别为:
- Euler a :插画⻛格,ICON,⼆次元图像,⼩场景
- DPM++2S a Karras:写实⼈像,复杂场景刻画
- DDIM:写实⼈像,复杂场景刻画
DPM系列更接近真实世界的效果,Euler 系列会让真实感减弱同事更加富有艺术感
各个采样器之间的对比如下图所示:

迭代步数 (Steps)
⼀般来说采样迭代步数保持在 18-30 左右即可。低的采样步数会导致画⾯计算不完整,⾼的采样步数仅在细节处进⾏优化,对⽐输出速度得不偿失。默认值为25,可以适应于大部分的生产场景。
那么,我们应该如何选择迭代步数呢?下面是一些参考建议:
- 如果正在测试新的提示,并希望快速得到结果以便调整你的输入,使用10-15
- 当找到喜欢的提示词后,将迭代步数调整到25
- 如果正在创建一个人脸、有毛皮的动物活任何具有详细文理的主题,而你觉得生成的图像缺少一些这些细节,可以试着将其调整到40
面部修复
为恢复脸部缺陷⽽训练的附加模型。
平铺图
将⽣成的图⽚拼接在⼀起
高分辨率修复 (Hires. fix)
通俗来说,就是以重新绘制的⽅式对图像进⾏放⼤,并且在放⼤的同时补充⼀些细节。
宽高设置
默认为512512,我们这边可以设置800800的,效果要相对好点儿。
单批次数和单批数量
单批次数:代表生成的批次
单批数量:代表每批生成的图像数量
如果我们将单批次数设置为2,单批数量设置为4,则出来的图片数量就为2*4=8张。(建议生成的批次高点,单批数量少点儿,这样速度快)
提示词引导系数 (CFG Scale)
该值越低时,产⽣越有创意的结果;反之如果该参数越⾼会使得SD尽量去⽣成与Prompt ⼀致的结果。
一般选择7就行。
CFG ⽐例可以分为不同的范围:
- CFG 2 - 6:富有创意,但可能过于扭曲且不符合prompt。对于短prompt可能会很有趣且有⽤
- CFG 7 - 10:推荐⽤于⼤多数提示。创造性和引导⽣成之间的良好平衡
- CFG 10 - 15:prompt很详细且清晰的描述了希望图像看起来像什么时
- CFG 16 - 20:通常不推荐,除⾮prompt⾮常详细。可能会影响连贯性和质量
- CFG > 20:⼏乎从不适⽤
随机数种子 (Seed)
- 当输⼊-1 或点击旁边的骰⼦按钮时,⽣成的图像是完全随机的,没有任何规律可⾔
- 当输⼊其他随机数值时,就相当于锁定了随机种⼦对画⾯的影响,这样每次⽣成的图像只会有微
⼩的变化 - 因此,使⽤随机种⼦可以控制⽣成图像的变化程度,从⽽更好地探索模型的性能和参数的影响

