
热门标签
热门文章
- 1Python自动化测试【软件测试最全教程(附笔记、学习路线)】,看完即就业_自动化测试课程
- 2基于jsp(java)高校学生考勤管理系统设计与实现_基于jsp的高校靠勤管理系统的设计与实现
- 3【Node.js】json-server
- 45分钟了解啥是数仓_大数据数仓的作用
- 5【AIGC调研系列】MiniMax 稀宇科技的abab 6.5 系列模型与国外先进模型相比的优缺点_稀宇科技 abab大模型的特点
- 6Idea双击打不开(macbook)_macbook idea 双击图标没反应
- 7微信小程序post和get请求_微信小程序 get请求
- 8《汇编语言(第四版)》王爽 第十章 CALL和RET指令_汇编语言王爽第四版 电子书
- 9使用IntelliJ IDEA进行Android应用开发_idea开发android教程
- 10看了下雷军的两份个人简历,的确厉害。。。_雷军履历对比法
当前位置: article > 正文
spark3.0.0单机模式安装
作者:我家自动化 | 2024-04-25 11:44:12
赞
踩
spark3.0.0单机模式安装
注:此安装教程基于hadoop3集群版本
下载安装包
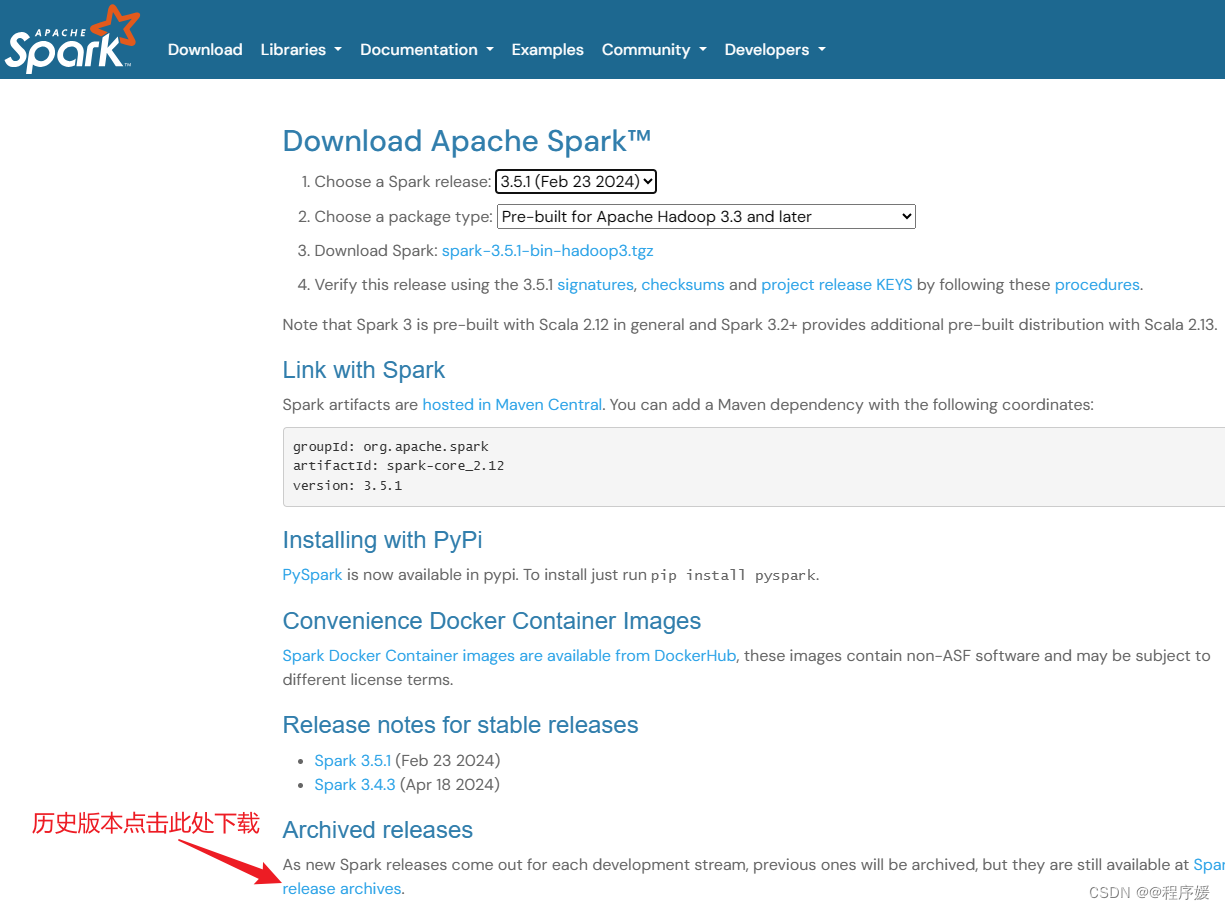
下载spark3.0.0版本,hadoop和spark版本要对应,否则会不兼容
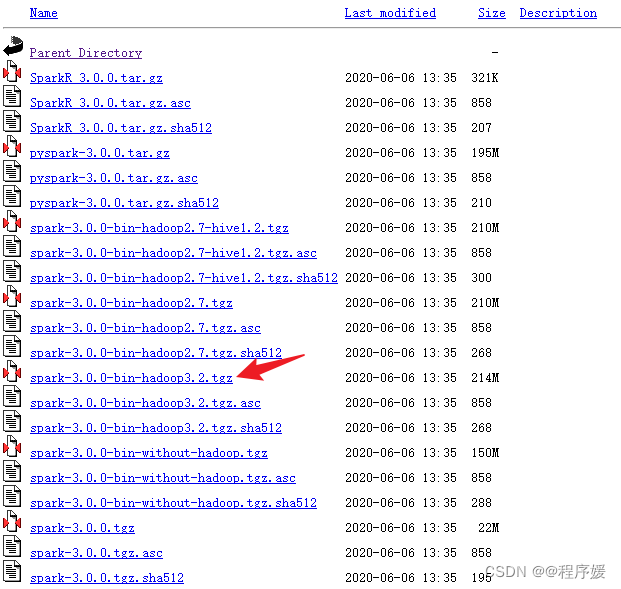
用xftp上传Linux虚拟机,上传目录/bigdata(可修改)

解压
tar -zxvf /bigdata/spark-3.0.0-bin-hadoop3.2.tgz 添加软链接(可选)
ln -s /bigdata/spark-3.0.0-bin-hadoop3.2.tgz /bigdata/spark修改环境变量
- sudo vim /etc/profile
-
- export SPARK_HOME=/bigdata/spark
- export $PATH:$SPARK_HOME/bin
别忘记source /etc/profile
修改spark配置文件
- cd /bigdata/spark
- cp ./conf/spark-env.sh.template ./conf/spark-env.sh
- vim ./conf/spark-env.sh
添加以下内容,/bigdata/hadoop就是hadoop的路径,可根据自己的实际情况修改
export SPARK_DIST_CLASSPATH=$(/bigdata/hadoop/bin/hadoop classpath)验证是否安装成功
run-example SparkPi 2>&1 | grep "Pi is" 这是一个求Π的示例程序,输出如下
![]()
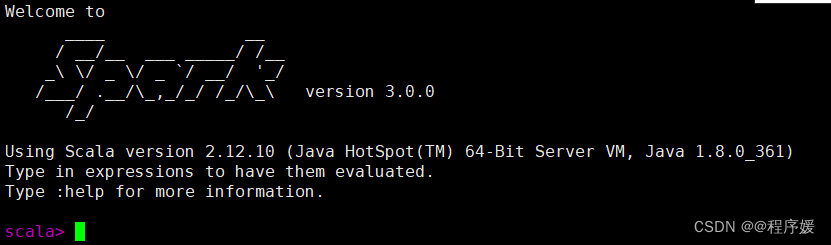
打开spark shell终端
spark-shell如下图
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/485087
推荐阅读
相关标签

