
- 1ElasticSearch 搜索引擎_es搜索引擎
- 2计算机二级office学习之Excel操作题考点整理_计算机二级考试excel操作题
- 3【24届数字IC秋招总结】提前批面试经验1——小米、百度昆仑芯、长鑫存储
- 4linux下的shell脚本(基本)
- 5在一个py文件里调用另一个py文件,使调用的py文件后台运行_在.py里面运行另外一个.py
- 6详解 async/await :应用场景,示例代码,注意事项
- 7kafka监控工具Kafka-eagle安装_kafka 监控工具
- 8亚信安慧AntDB:开启数据洞察的新视野
- 9Mysql各种特殊时间段查询方法_mysql 时间段查询
- 10某东员工面试被问自动化测试,11:00进去的,11:10就出来······
【机器学习技术系列】FM系列算法详解(FM、FFM、DeepFM)
赞
踩
综述
- CTR(click-through-rate)即点击通过率
- FM算法(Factorization Machines)即因子分解机,是CTR的重要模型之一,自2010年被提出后,得到了大规模的应该,也是美团和头条做推荐和CTR预估的方法之一。
- FFM算法(Field-aware Factorization Machine)即域分解机模型,是FM算法的升级版。
- DeepFM ()
FM算法
对因子分解机的理解需要对逻辑回归LR(logistic Rgeression) 和矩阵分解MF(Matrix Factorization)
1. 逻辑回归
下图显示了,在传统的推荐系统中,逻辑回归衍生出来经典的模型和算法,常见的因子分解机FM 以及升级版的FFM模型。Facebook提出的GBDT+LR组合的模型。阿里巴巴曾经主流的LS-PLM(MLR)。
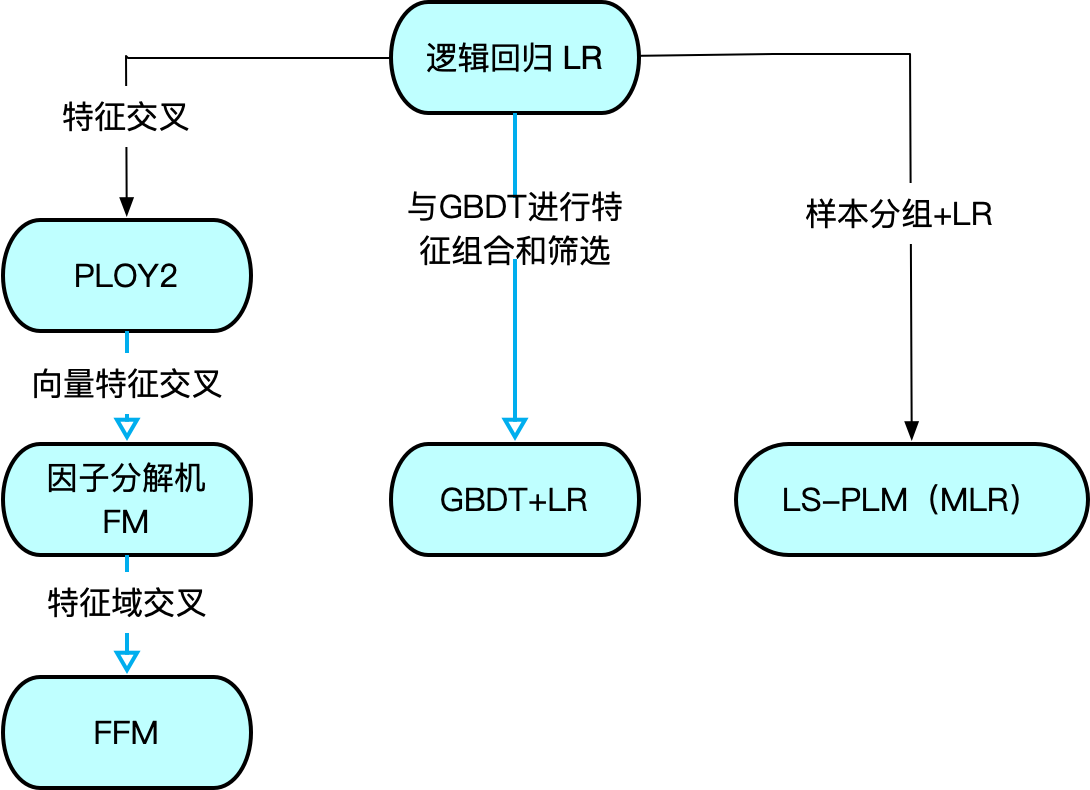
机器学习算法中的监督学习分为两类:分类和回归。分类就是判断目标变量的所属类别,目标变量是离散值。而回归则是预测,目标变量是连续型的数值。
逻辑回归是在数据服从伯努利分布的假设下,通过极大似然的方法,运用梯度下降法来求解参数,从而达到将数据二分类的目的。
逻辑回归是分类的问题,其中回归体现在:通过模型预测得到结果在0-1之间的连续数值,代表可能性而不是概率。通过"可能性" 排序推荐给用户,或者给可能性设立一个阈值,判断用户 点击 或者 不点击,喜欢 或者 不喜欢。所以逻辑回归将 推荐问题转化成了CTR的问题。
逻辑回归是一种广义的线性回归分析模型,属于机器学习中的监督学习。推导过程与计算方法类似于回归的过程,实际上主要来解决二分类问题(也可以解决多分类问题)。通过给定n组数据(训练集)来训练模型,并在训练结束后对给定的一组或者多组数据进行分类。
2. 逻辑回归原理
1. 线性回归(Liner Regression)与逻辑回归(Logistic Regression)
线性回归,比如一元二次方程可以表示身高和体重的线性关系。身高和体重数据是连续的可以表示成一元二次方程。
如果我们的目标数据不是连续的,比如广告投入金额和用户是否购买的关系。购买则为1,不购买则为0,因此数据是离散的点。 这时候就不能用一元二次方程这种确定的线性关系拟合。
这个时候可以加一个限制,z(x) > 0.5 输出1 z(x) < 0.5 输出 0 。 这就相当于线性回归的基础上,套用了一个函数,使他能够具有分类的效果。这种函数是不连续的阶跃函数。
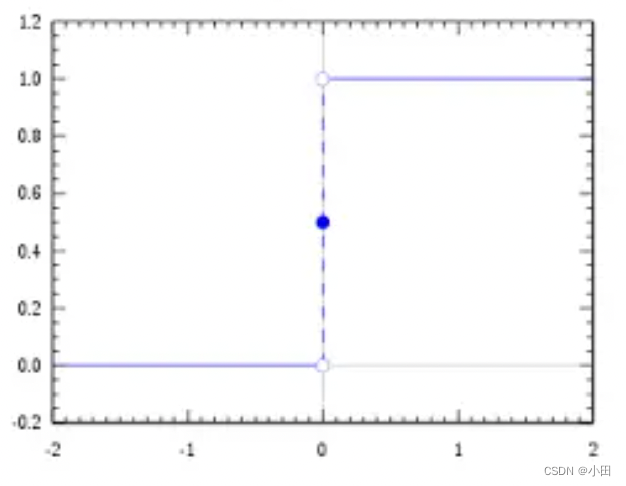
但是工程上求最大值需要函数式连续可导的,这样才可以无限接近于最优解。因此我们用Sigmoid函数来替代阶跃函数
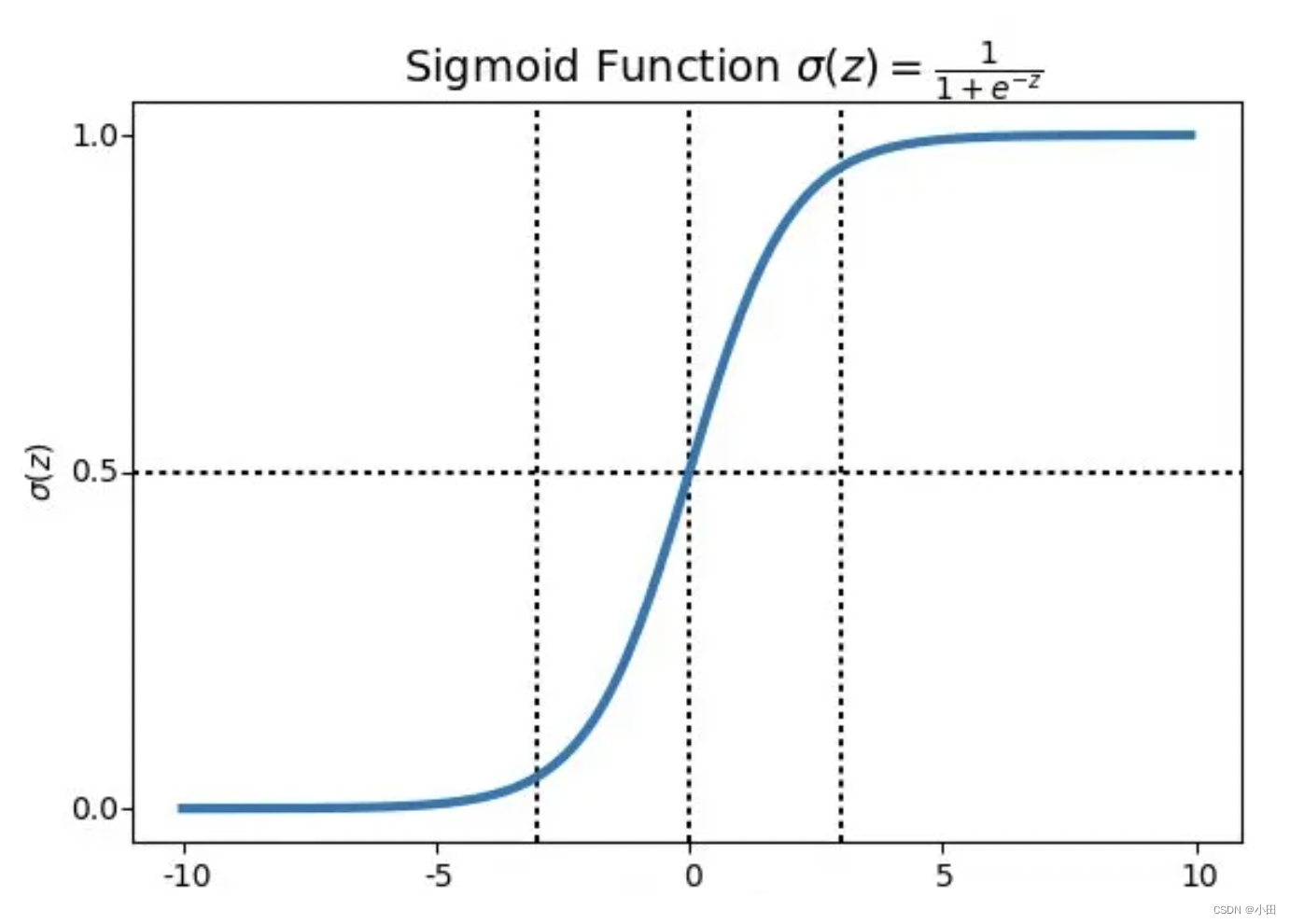
函数公式如下:
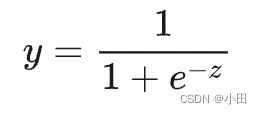
其中y的值在 0-1之间,从拟合图中可以看出 横轴z 接近0的时候 y变的敏感(值变换快),z 远离0时,变得不敏感。
那么函数 y 和sigmoid 函数,就构成了我们的逻辑回归模型。这也就解释了为什么逻辑回归不叫逻辑分类而叫逻辑回归,同时他又是一个分类函数。逻辑回归的本质就是用线性回归带入simoid函数,得到的值位于0-1之间,代表着“可能性”,也就是用回归的思想解决了分类的问题。
一元线性回归方程可以用 y = βx +b 表示,而推广到多元函数,则可以写成矩阵的形式 Y = Xβ ,β 也是向量形式,表示各个特征相应的权重。
因此,令预测为正样本的概率 P(Y=1), 逻辑回归的数学形式为:
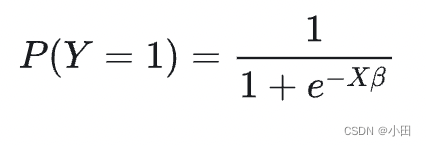
那么,有了逻辑回归的数学形式,我们就需要优化参数 β,β也就是特征向量相应的权重向量。
2. 极大似然估计
极大似然估计是数理统计中参数估计的一种重要方法,其思想就是一个事件发生了,那么发生这个事件的概率就是最大的。
概率:给定模型参数β后,估计时间X发生的可能性
似然:给定样本变量X后,估计能够使事件发生的参数β的值
最大似然估计:给定样本变量X,参数未知那么我们需要去推断其参数β,使得这件事发生概率P得到最大化。
举例子:
概率:我们已知硬币正反两面是公平的,因此参数 β为0.5。 那么我们抛1次硬币,得到“数字”朝上的概率 P 就为50%,我们抛10次,出现5次“数字”朝上的概率 P 就为:从10取5 的组合数概率,然后乘以0.5的10次方
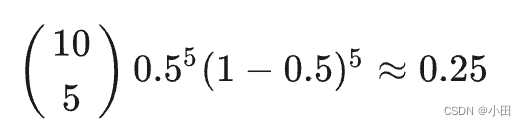
似然:我们不知道硬币的参数β,即不知道硬币是否是正反质量一样(抛掷偏心硬币的问题),需要实验观察来估算硬币的参数。
极大似然:通过观察,假设硬币的参数β,然后计算实验结果的概率P,概率越大,越是我们想要的参数。
3. 逻辑回归模型推导
逻辑回归假设数据服从伯努利分布,通过极大似然函数的方法,运用梯度下降来求解参数,来达到数据二分类的目的。
4. 损失函数 (Loss Function)
损失函数就是用来衡量模型的输出与真实输出的差别。每一个样本经过模型后都会得到一个预测值,然后得到的预测值和真实值的差值就成为了损失(损失值越小,证明模型越是成功)
- 损失函数使用的位置
在机器学习中,我们知道输入的feature(或称为x)需要通过模型(model)预测出y,此过程称为向前传播(forward pass),而要将预测与真实值的差值减小需要更新模型中的参数,这个过程称为向后传播(backward pass),其中我们损失函数(lossfunction)就基于这两种传播之间,起到一种有点像承上启下的作用,承上指:接収模型的预测值,启下指:计算预测值和真实值的差值,为下面反向传播提供输入数据。
- 常用的损失函数
a. L1Loss函数
b. MSELoss函数
c. CrossEntropyLoss函数(交叉熵函数)
5. 梯度下降求解
梯度下降(Gradient Descent GD)简单来说就是一种寻找目标函数最小化的方法,它利用梯度信息,通过不断迭代调整参数来寻找合适的目标值。
什么是梯度 ?
梯度的引入可以分为四个概念: 导数 -> 偏导数 -> 方向导数 -> 梯度。
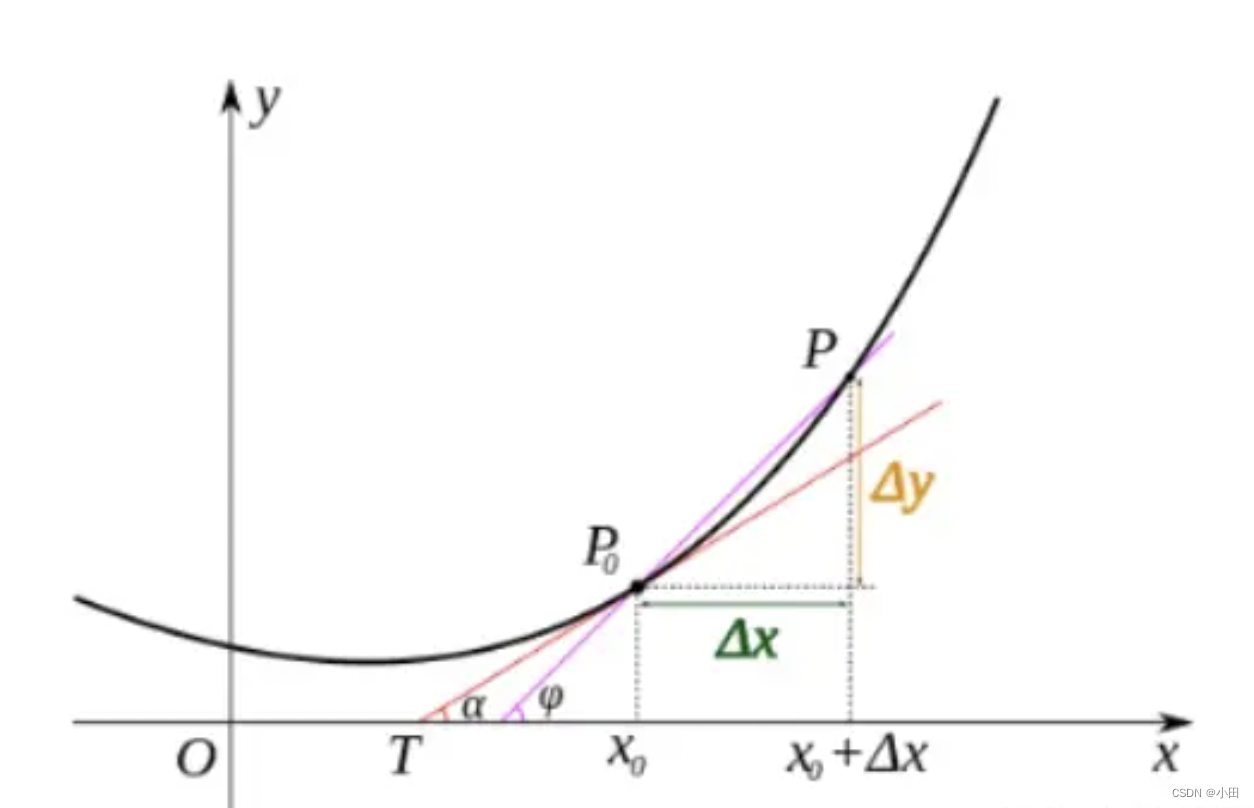
- 导数:当函数定义域和取值都在实数域中的时候,导数可以表示函数曲线上的切线斜率
- 偏导数:偏导数其实就是多元函数,一个多变量的函数的偏导数是它关于其中一个变量的导数,而保持其他变量恒定,因为曲面上的每一点都有无穷多条切线,描述这种函数的导数相当困难。偏导数就是选择其中一条切线,并求出它的斜率。
- 方向导数:某个方向的导数,本质就是函数在A点上无数个切线的斜率的定义,每个切线都代表一个方向,每个方向都是有方向导数的。
- 梯度:梯度是一个矢量,在其方向上的方向导数最大,也就是函数在该点处沿着梯度方向变化最快,变化率最大。
什么是梯度 下降?
举个常见的例子:你站在山上某处,想要尽快下山,于是决定走一步算一步,也就是每走到一个位置时,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走,这样一直走下去,很可能走不到山脚,而是某个局部的山峰最低处。如下图所示:
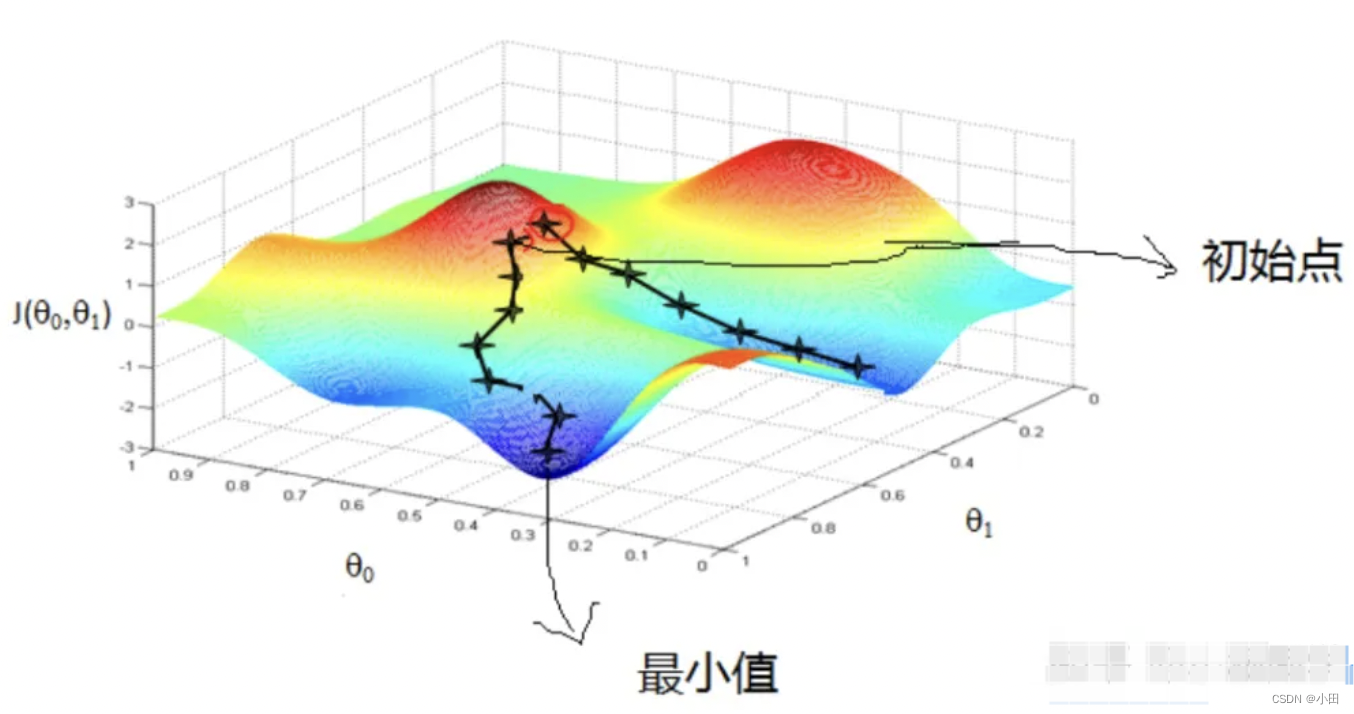
以上,我们可以总结一下:梯度下降法就是沿着梯度下降的方向求解极小值,沿着梯度上升的方向可以求得最大值,这种方法叫梯度上升。
从上图可以看到:受到起始点和目标函数特性的影响,梯度下降不一定找到的是全局最优解,可能只是局部最优解,那么什么时候能找到全局最优解呢?这个与损失函数有关,当损失函数是凸函数的话,可以找到全局最优。
5. 总结
逻辑回归的优势:
- 可解释性强。
- 形式简单,训练速度快。
逻辑回归的缺点:
- 表达能力有限
- 只在处理二分类问题上优势明显
6. QA
Q1: 为啥FM的输入X 必须要拉直为一维向量
FM的 base model是LR模型,没办法处理二维矩阵
Q2: 如何理解FM的输入特征X?n代表什么,x代表什么?
FM论文中公式只展示了一个样本的训练细节及数学公式。所以n表示的不是样本数目,而是一个样本的输入特征向量X的长度。
比如 x = 100,01 这是一个样本的全部特征展平后(丢失了每个特征自身的结构性)的特征向量。
而实际上只要模型可以处理,输入到模型的特征形状可以任意:n-dim feature vector(处理方便, 而且LR/FC/RNN只能接受 向量输入),或者是mxn的Feature Martrix (保留结构信息,CNN可以处理)。
Q3: 如何理解特征交叉?为什么需要它?具体的实现方式举例?
显式的特征交叉包括 人工计算两个单特征的统计特征作为新的单特征:共现、互斥;隐式的特征交叉是将特征输入到网络中,让模型自动学习对优化目标有益的特征组合。组合特征能补充单个特征无法建模的某种模式。
以显示的特征组合来举例说,输入单特征集合={年龄,性别,……} 待预测对象为对每个商品的CTR。最简单的特征交叉:将年龄和性别 组合成一个新特征,它某种程度上刻画了 购买力 + 消费喜好 这种模式。这样的好处显而易见,「年龄=18~30 + 性别为女」在统计意义上偏好购买性价比高的化妆品,「年龄=40~50 + 性别为男」在统计意义上偏好购买偏昂贵的手表古玩等。
3 FM算法
FM(Factorization Machine)是由Konstanz大学Steffen Rendle 于 2010年最早提出的,旨在解决稀疏数据下的特征组合问题
示例引入FM模型
| Clicked? | Country | Day | Ad_type |
|---|---|---|---|
| 1 | USA | 26/11/15 | Movie |
| 0 | China | 1/7/14 | Game |
| 1 | China | 19/2/15 | Game |
“Clicked?“是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。
| Clicked? | Country=USA | Country=China | Day=26/11/15 | Day=1/7/14 | Day=19/2/15 | Ad_type=Movie | Ad_type=Game |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
由上表可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。上面的样例中,每个样本有7维特征,但平均仅有3维特征具有非零值。实际上,这种情况并不是此例独有的,在真实应用场景中这种情况普遍存在。
例如,CTR/CVR预测时,用户的性别、职业、教育水平、品类偏好,商品的品类等,经过One-Hot编码转换后都会导致样本数据的稀疏性。特别是商品品类这种类型的特征,如商品的末级品类约有550个,采用One-Hot编码生成550个数值特征,但每个样本的这550个特征,有且仅有一个是有效的(非零)。由此可见,数据稀疏性是实际问题中不可避免的挑战。
One-Hot编码的另一个特点就是导致特征空间大。例如,商品品类有550维特征,一个categorical特征转换为550维数值特征,特征空间剧增。
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
多项式模型是包含特征组合的最直观的模型。在多项式模型中,特征 xi和 xj的组合采用 xixj表示,即 xi和 xj都非零时,组合特征 xixj才有意义。从对比的角度,本文只讨论二阶多项式模型。模型的表达式如下
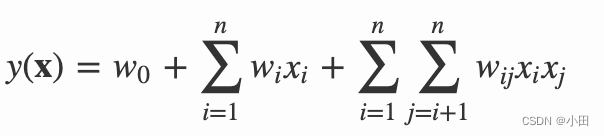 (1)
(1)
其中,n代表样本的特征数量,xi是第 i个特征的值,w0、wi、wij是模型参数。
从公式(1)可以看出,组合特征的参数一共有 n(n−1)/2个,任意两个参数都是独立的。然而,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是,每个参数 wij 的训练需要大量 xi 和 xj 都非零的样本;由于样本数据本来就比较稀疏,满足“xi 和 xj 都非零”的样本将会非常少。训练样本的不足,很容易导致参数 wij 不准确,最终将严重影响模型的性能。
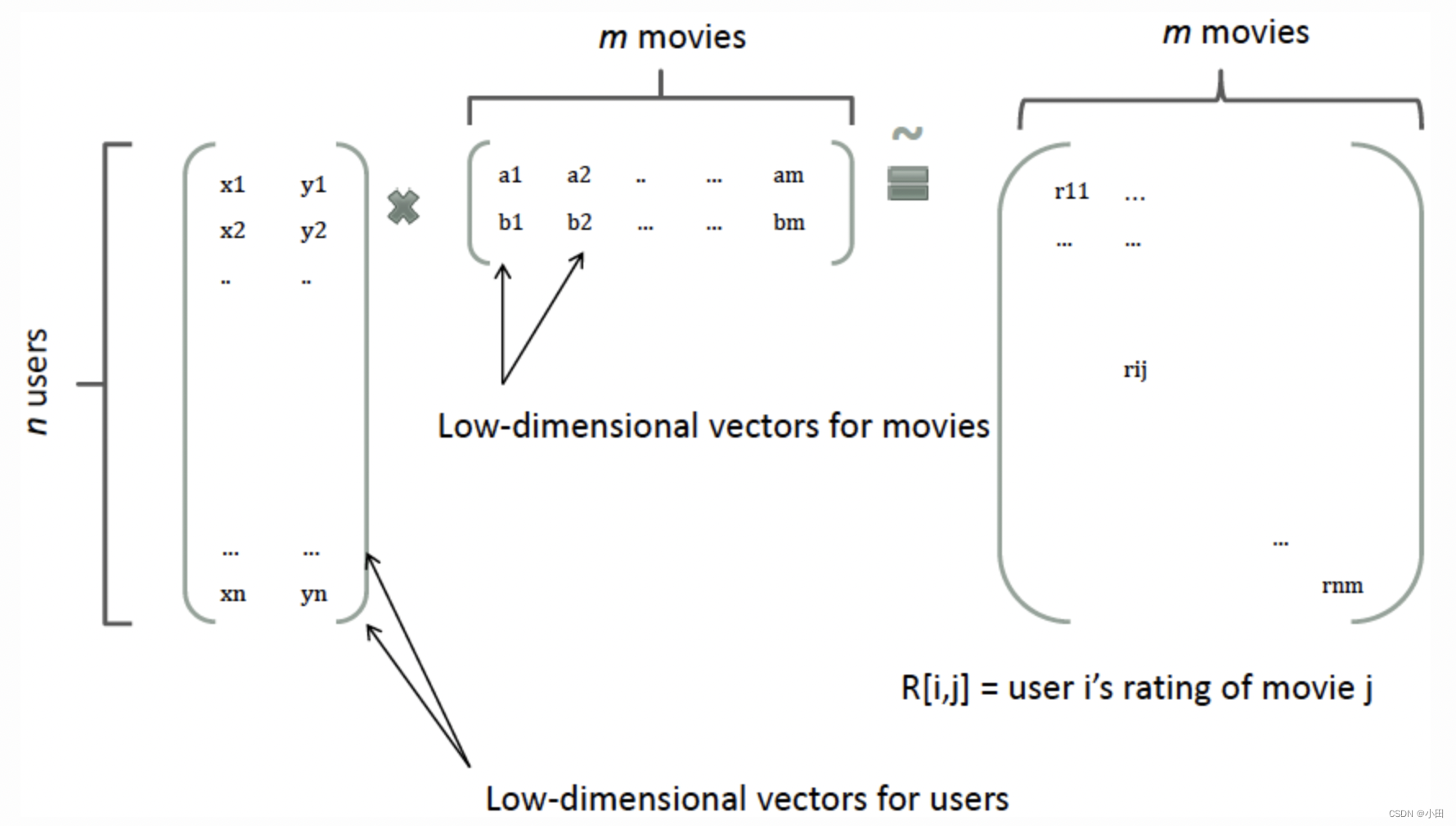
那么,如何解决二次项参数的训练问题呢?矩阵分解提供了一种解决思路。在model-based的协同过滤中,一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以采用一个隐向量表示。比如在下图中的例子中,我们把每个user表示成一个二维向量,同时把每个item表示成一个二维向量,两个向量的点积就是矩阵中user对item的打分。
类似地,所有二次项参数 wij 可以组成一个对称阵 W(为了方便说明FM的由来,对角元素可以设置为正实数),那么这个矩阵就可以分解为 W=VTV,V 的第 j 列便是第 j 维特征的隐向量。换句话说,每个参数 wij=⟨vi,vj⟩,这就是FM模型的核心思想。因此,FM的模型方程为(本文不讨论FM的高阶形式)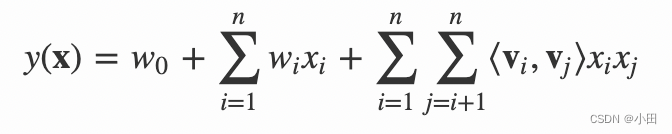 (2)
(2)
其中,vi是第 i 维特征的隐向量,⟨⋅,⋅⟩ 代表向量点积。隐向量的长度为 k(k<<n),包含 k 个描述特征的因子。根据公式(2)
,二次项的参数数量减少为 kn个,远少于多项式模型的参数数量。另外,参数因子化使得 xhxi 的参数和 xixj 的参数不再是相互独立的,因此我们可以在样本稀疏的情况下相对合理地估计FM的二次项参数。具体来说,xhxi 和 xixj 的系数分别为 ⟨vh,vi⟩ 和 ⟨vi,vj⟩
,它们之间有共同项 vi。也就是说,所有包含“xi 的非零组合特征”(存在某个 j≠i,使得 xixj≠0)的样本都可以用来学习隐向量 vi
,这很大程度上避免了数据稀疏性造成的影响。而在多项式模型中,whi 和 wij 是相互独立的。
显而易见,公式(2)是一个通用的拟合方程,可以采用不同的损失函数用于解决回归、二元分类等问题,比如可以采用MSE(Mean Square Error)损失函数来求解回归问题,也可以采用Hinge/Cross-Entropy损失来求解分类问题。当然,在进行二元分类时,FM的输出需要经过sigmoid变换,这与Logistic回归是一样的。直观上看,FM的复杂度是 O(kn²)。但是,通过公式(3)的等式,FM的二次项可以化简,其复杂度可以优化到 O(kn)。由此可见,FM可以在线性时间对新样本作出预测。
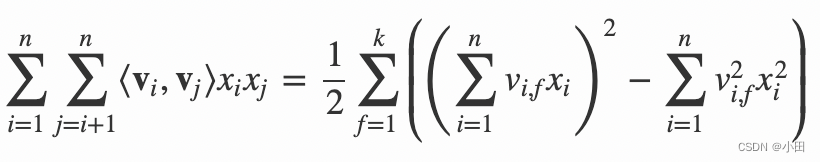
我们再来看一下FM的训练复杂度,利用SGD(Stochastic Gradient Descent)训练模型。模型各个参数的梯度如下
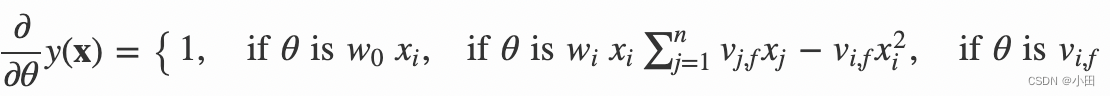
其中,vj,f 是隐向量 vj 的第 f 个元素。由于 ∑nj=1vj,fxj 只与 f 有关,而与 i 无关,在每次迭代过程中,只需计算一次所有 f 的 ∑nj=1vj,fxj,就能够方便地得到所有 vi,f 的梯度。显然,计算所有 f 的 ∑nj=1vj,fxj 的复杂度是 O(kn);已知 ∑nj=1vj,fxj 时,计算每个参数梯度的复杂度是 O(1);得到梯度后,更新每个参数的复杂度是 O(1);模型参数一共有 nk+n+1 个。因此,FM参数训练的复杂度也是 O(kn)。综上可知,FM可以在线性时间训练和预测,是一种非常高效的模型。
FFM算法
FFM算法是基于FM算法,引入了域(field)的概念,使特征的交叉组合更加符合真实场景,更有效提升模型的表达能力。一个特征在跟不同特征交互时,会发挥不同的作用,因此应该具有不同的向量表示。
FFM(Field-aware Factorization Machine)最初的概念来自Yu-Chin Juan(阮毓钦,毕业于中国台湾大学,现在美国Criteo工作)与其比赛队员,是他们借鉴了来自Michael Jahrer的论文[14]中的field概念提出了FM的升级版模型。通过引入field的概念,FFM把相同性质的特征归于同一个field。以上面的广告分类为例,“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中。同理,商品的末级品类编码生成了550个特征,这550个特征都是说明商品所属的品类,因此它们也可以放到同一个field中。简单来说,同一个categorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户性别、职业、品类偏好等。在FFM中,每一维特征 xi,针对其它特征的每一种field fj,都会学习一个隐向量 vi,fj。因此,隐向量不仅与特征相关,也与field相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type”特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是FFM中“field-aware”的由来。
假设样本的 n 个特征属于 f 个field,那么FFM的二次项有 nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。根据FFM的field敏感特性,可以导出其模型方程。
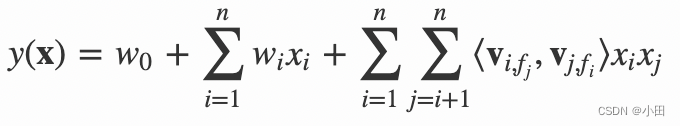 (4)
(4)
其中,fj 是第 j 个特征所属的field。如果隐向量的长度为 k,那么FFM的二次参数有 nfk 个,远多于FM模型的 nk 个。此外,由于隐向量与field相关,FFM二次项并不能够化简,其预测复杂度是 O(kn2)。下面以一个例子简单说明FFM的特征组合方式。输入记录如下
| User | Movie | Genre | Price |
|---|---|---|---|
| YuChin | 3Idiots | Comedy, Drama | $9.99 |
这条记录可以编码成5个特征,其中“Genre=Comedy”和“Genre=Drama”属于同一个field,“Price”是数值型,不用One-Hot编码转换。为了方便说明FFM的样本格式,我们将所有的特征和对应的field映射成整数编号。
| Field name | Field index | Feature name | Feature index |
|---|---|---|---|
| User | 1 | User=YuChin | 1 |
| Movie | 2 | Movie=3Idiots | 2 |
| Genre | 3 | Genre=Comedy | 3 |
| Price | 4 | Genre=Drama | 4 |
| Price | 5 |
那么,FFM的组合特征有10项,如下图所示。
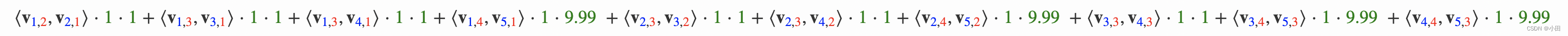
其中,红色是field编号,蓝色是特征编号,绿色是此样本的特征取值。二次项的系数是通过与特征field相关的隐向量点积得到的,二次项共有 n(n−1)/2个。Yu-Chin Juan实现了一个C++版的FFM模型,源码可从Github下载。这个版本的FFM省略了常数项和一次项,模型方程如下。
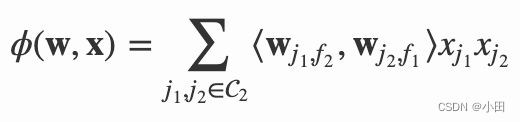
其中,C2 是非零特征的二元组合,j1 是特征,属于field f1,wj1,f2 是特征 j1 对field f2 的隐向量。此FFM模型采用logistic loss作为损失函数,和L2惩罚项,因此只能用于二元分类问题。
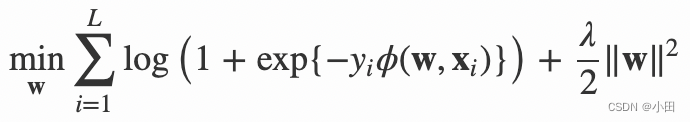
其中,yi∈{−1,1} 是第 i 个样本的label,L 是训练样本数量,λ 是惩罚项系数。模型采用SGD优化,优化流程如下。
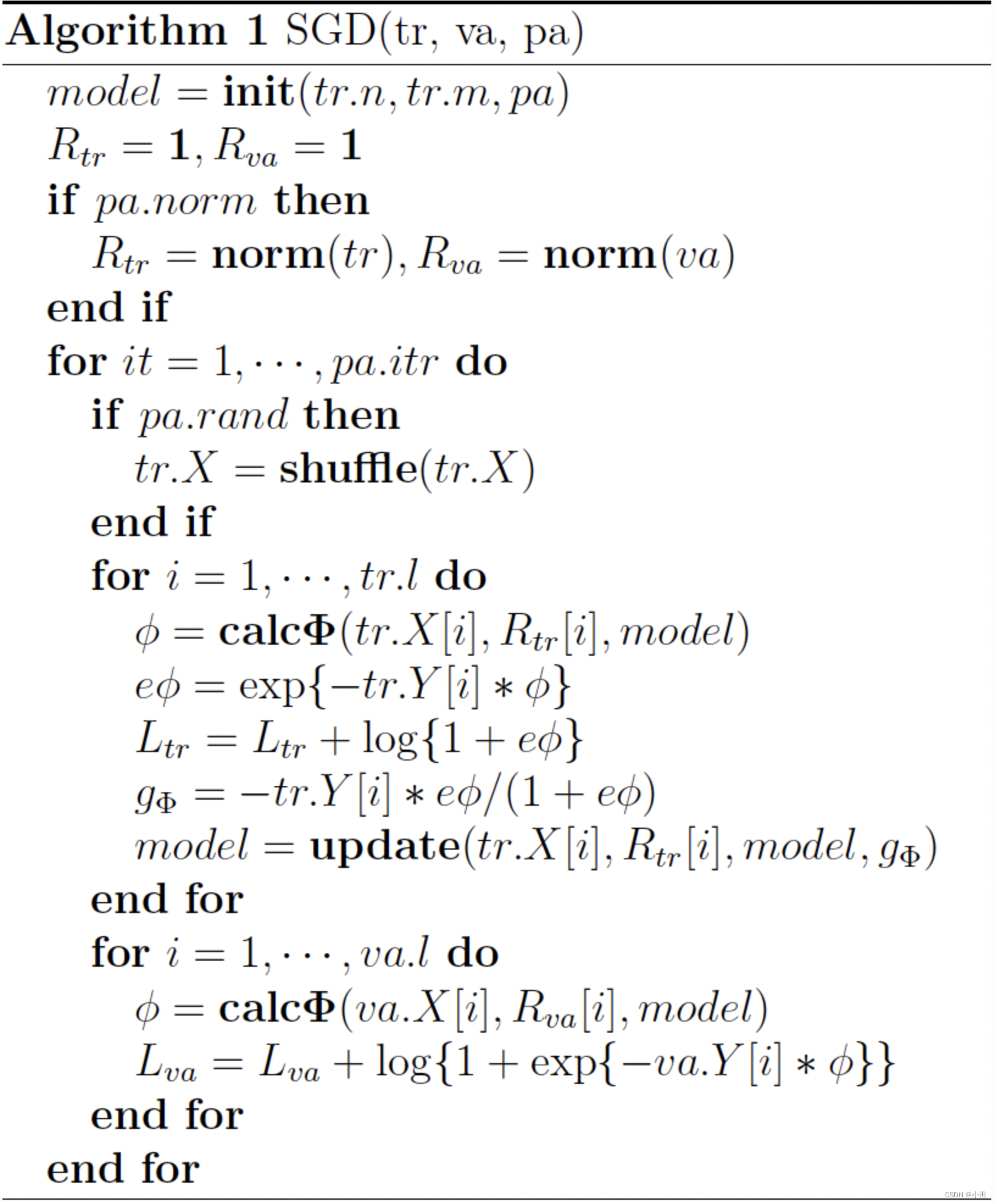
参考 Algorithm1, 下面简单解释一下FFM的SGD优化过程。 算法的输入 tr、va、pa分别是训练样本集、验证样本集和训练参数设置。
- 根据样本特征数量(tr.n)、field的个数(tr.m)和训练参数(pa),生成初始化模型,即随机生成模型的参数;
- 如果归一化参数 pa.norm
为真,计算训练和验证样本的归一化系数,样本 i的归一化系数为
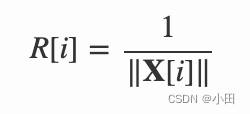
- 对每一轮迭代,如果随机更新参数 pa.rand为真,随机打乱训练样本的顺序;
- 对每一个训练样本,执行如下操作
- 计算每一个样本的FFM项,即公式(5)中的输出 ϕ;
- 计算每一个样本的训练误差,如算法所示,这里采用的是交叉熵损失函数 log(1+eϕ);
- 利用单个样本的损失函数计算梯度 gΦ,再根据梯度更新模型参数;
- 对每一个验证样本,计算样本的FFM输出,计算验证误差;
- 重复步骤3~5,直到迭代结束或验证误差达到最小。
在SGD寻优时,代码采用了一些小技巧,对于提升计算效率是非常有效的。
第一,梯度分步计算。采用SGD训练FFM模型时,只采用单个样本的损失函数来计算模型参数的梯度。
第二,自适应学习率。此版本的FFM实现没有采用常用的指数递减的学习率更新策略,而是利用 nfk 个浮点数的临时空间,自适应地更新学习率。
第三,OpenMP多核并行计算。OpenMP是用于共享内存并行系统的多处理器程序设计的编译方案,便于移植和多核扩展[12]。FFM的源码采用了OpenMP的API,对参数训练过程SGD进行了多线程扩展,支持多线程编译。因此,OpenMP技术极大地提高了FFM的训练效率和多核CPU的利用率。在训练模型时,输入的训练参数ns_threads指定了线程数量,一般设定为CPU的核心数,便于完全利用CPU资源。
第四,SSE3指令并行编程。SSE3全称为数据流单指令多数据扩展指令集3,是CPU对数据层并行的关键指令,主要用于多媒体和游戏的应用程序中[13]。SSE3指令采用128位的寄存器,同时操作4个单精度浮点数或整数。SSE3指令的功能非常类似于向量运算。例如,a 和 b 采用SSE3指令相加(a 和 b 分别包含4个数据),其功能是 a 中的4个元素与 b 中4个元素对应相加,得到4个相加后的值。采用SSE3指令后,向量运算的速度更加快捷,这对包含大量向量运算的FFM模型是非常有利的。
FFM模型训练注意事项
在训练FFM的过程中,有许多小细节值得特别关注。
第一,样本归一化。FFM默认是进行样本数据的归一化,即 pa.norm 为真;若此参数设置为假,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。
第二,特征归一化。CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。例如,一条用户-商品记录,用户为“男”性,商品的销量是5000个(假设其它特征的值为零),那么归一化后特征“sex=male”(性别为男)的值略小于0.0002,而“volume”(销量)的值近似为1。特征“sex=male”在这个样本中的作用几乎可以忽略不计,这是相当不合理的。因此,将源数值型特征的值归一化到 [0,1] 是非常必要的。
第三,省略零值特征。从FFM模型的表达式(4)可以看出,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
引用文章:
[1] 深入FFM原理与实践
[2] FM论文
[3] 传统CTR预估模型


