
- 1最拼命最努力的时候(转)
- 2Mac上Angular的环境搭建_mac angular
- 3看懂这篇文章,前后端分离再和面试官扯皮就没问题了_前后端需要两个端口吗
- 4自学编程80余年,这些私藏的实用工具&学习网站陪我走到了现在,必须收藏,学习效率翻倍 - 网站篇_03024百万文字综合论坛
- 5org.apache.hadoop.hbase.PleaseHoldException: Master is initializing(解決方案汇总+自己摸索)
- 6linux网络编程-很全的_linux下的网络编程
- 7python 将文件夹里多个json文件合并成一个_python合并json文件
- 8Git使用记录_fatal: unable to access目标地址
- 9笔记:ubuntu22.04重启后无法启动网络_stopping systemd-networkd.service
- 10Kafka常用操作命令_查看kafka某个主题
#05【chatglm】lora微调几条数据,硬是重复输出几分钟?那里问题?-已解决_chatglm模型微调存在重复数据?
赞
踩
公众号每天更新5条大模型问题及解决方案
今天,在【NLP学习群】中,今天最后一个问题,还是选这位dylan同学的问题,因为他遇到的问题实在是太典型了,只给了几条的数据,chatglm重复输出了十分钟。
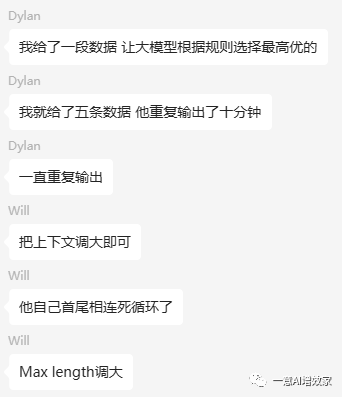
01 报错信息分析:
其实这个问题,这位同学得到其他同学的帮助,调整上下文长度之后,的确把问题解决了。
调整上下文的长度可能会解决重复输出的问题,这是因为上下文的长度直接影响了模型对输入文本的理解和生成输出的方式。让我们来详细解释为什么调整上下文长度可以有助于解决这个问题:
-
上下文长度影响信息量:模型的上下文长度是指模型在生成回复时可以看到的之前的输入文本的长度。如果上下文长度过短,模型可能没有足够的信息来正确地理解输入的含义,从而导致生成不连贯或重复的回复。
-
避免短期记忆问题:在对话生成任务中,特别是当上下文长度很短时,模型可能会过度依赖于最近的输入,而忽略了之前更长期的上下文。这种短期记忆问题可能导致模型在输出中不断重复之前的内容。
-
提供更多背景信息:增加上下文长度可以提供更多的背景信息,使得模型能够更全面地理解对话上下文,并生成更合理、多样化的回复。
-
缓解过拟合:调整上下文长度可以有效地缓解模型的过拟合问题。较长的上下文有助于模型更好地泛化,并减少在微调数据中出现的重复模式。
02 解决方案
大部分的情况,是需要更多处理的!这里给出更多方案,以便大家处理!
-
增加微调数据:尽量提供更多的微调数据,以帮助模型学习更广泛和多样化的文本模式,从而减少过拟合的风险。
-
添加多样性:在微调数据中包含更多多样化的对话和主题,以确保模型可以在不同情况下表现良好。
-
调整模型参数:通过调整模型的超参数,例如学习速率、批次大小等,可以减轻模型的过拟合倾向。
-
早停(Early Stopping)策略:监控模型在验证集上的性能,并在性能停止改善时停止微调,以避免继续训练模型过拟合。
-
数据增强(Data Augmentation):尝试在微调数据上应用一些简单的数据增强技术,如随机删除或替换一些词语,以增加数据的多样性。
至此!问题解决!
因为设备、目标不同,如果你的问题还没解决,可以公众号后台回复“问答3000条”进群,有更多同学帮你,也可以点公众号里的有偿1对1!

一意AI增效家
AI领域学习伴侣、大模型训练搭档、企服AI产品安全认证、专家培训咨询、企服知识图谱、数字人搭建
公众号
目前一意AI提供的价值主要在四个方面!
#1 高质量数据集
我搭建了一个数据共享交换平台,目前已收录中文对话、金融、医疗、教育、儿童故事五个领域优质数据集,还可以通过会员之间共享,工众后台:“数据集”下载。
#2 报错或问题解决
你可能像我们NLP学习群中的同学一样,遇到各种报错或问题,我每天挑选5条比较有代表性的问题及解决方法贴出来,供大家避坑;每天更新,工众后台:“问答3000条”获清单汇总。
#3 运算加速
还有同学是几年前的老爷机/笔记本,或者希望大幅提升部署/微调模型的速度,我们应用了动态技术框架,大幅提升其运算效率(约40%),节省显存资源(最低无显卡2g内存也能提升),工众后台:“加速框架”;
#4 微调训练教程
如果你还不知道该怎么微调训练模型,我系统更新了训练和微调的实战知识库,跟着一步步做,你也能把大模型的知识真正应用到实处,产生价值。

